




Pull vs. Push
Producer : Producer通过主动Push的方式将消息发布到Broker
Consumer : Consumer通过Pull从Broker消费数据
Push
优势 延时低
劣势 可能造成Consumer来不及处理消息;网络拥塞
Pull
优势 Consumer按实际处理能力获取相应量的数据;Broker实现简单
劣势 如果处理不好,实时性相对不足( Kafka使用long polling)
High Level Consumer
1.很多应用场景下,客户程序只是希望从Kafka顺序读取并处理数据,而不太关心具体的offset。
2.同时也希望提供一些语义,例如同一条消息只被某一个Consumer消费(单播)或被所有Consumer消费(广播)
3.Kafka High Level API提供了一个从Kafka消费数据的高层抽象,从而屏蔽掉其中的细节,并提供丰富的语义。
Consumer Group
1.High Level Consumer将从某个Partition读取的最后一条消息的offset存于Zookeeper中(从0.8.2开始同时支持将offset存于Zookeeper中和专用的Kafka Topic中)。
2.这个offset基于客户程序提供给Kafka的名字来保存,这个名字被称为Consumer Group。
3.Consumer Group是整个Kafka集群全局唯一的,而非针对某个Topic的。
4.每个High Level Consumer实例都属于一个Consumer Group,若不指定则属于默认的Group 。
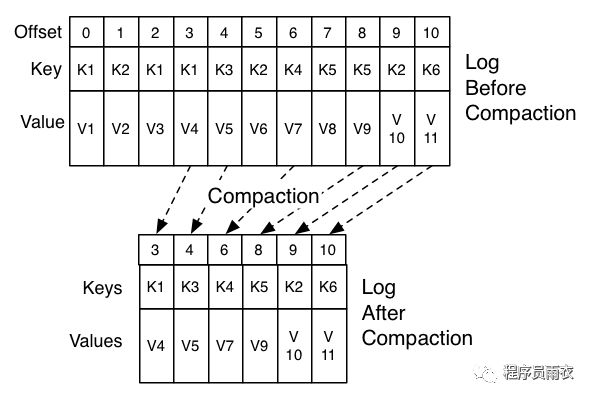
5.消息被消费后,并不会被删除,只是相应的offset加一
6.对于每条消息,在同一个Consumer Group里只会被一个Consumer消费
7.不同Consumer Group可消费同一条消息
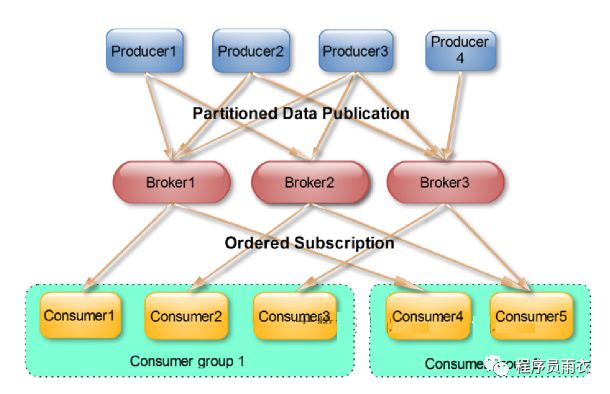
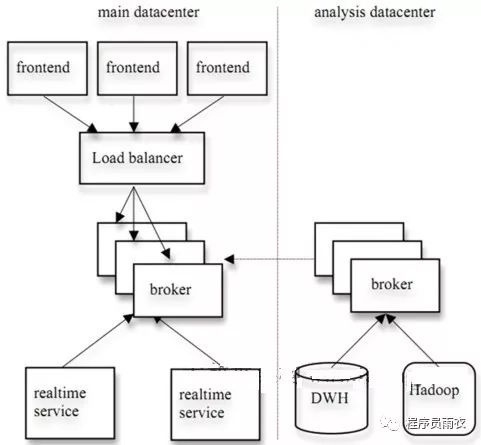
8.Kafka的设计理念之一就是同时提供对离线批处理和在线流处理的支持。
9.可同时使用Hadoop系统进行离线批处理, Storm或其它流处理系统进行流处理。
10.可使用Kafka的Mirror Maker将消息从一个数据中心镜像到另一个数据中心。
High Level Consumer Rebalance
Consumer启动及Rebalance流程
1.High Level Consumer启动时将其ID注册到其Consumer Group下,在Zookeeper上的路径为/consumers/[consumer group]/ids/[consumer id]
2.在/consumers/[consumer group]/ids上注册Watch
3.在/brokers/ids上注册Watch
4.如果Consumer通过Topic Filter创建消息流,则它会同时在/brokers/topics上也创建Watch
5.强制自己在其Consumer Group内启动Rebalance流程
Consumer Rebalance算法
1.将目标Topic下的所有Partirtion排序,存于PT
2.对某Consumer Group下所有Consumer排序,存于CG, 第i个Consumer记为Ci
3.N=size(PT)/size(CG) , 向上取整
4.解除Ci对原来分配的Partition的消费权( i从0开始)
5.将第 i∗N 到( i+1) ∗N-1个Partition分配给Ci
Consumer Rebalance算法缺陷及改进
1.Herd Effect 任何Broker或者Consumer的增减都会触发所有的Consumer的Rebalance
2.Split Brain 每个Consumer分别单独通过Zookeeper判断哪些Broker和Consumer宕机,同时Consumer在同一时刻从Zookeeper“看”到的View可能不完全一样, 这是由Zookeeper的特性决定的。
3.调整结果不可控 所有Consumer分别进行Rebalance,彼此不知道对应的Rebalance是否成功
Low Level Consumer
使用Low Level Consumer (Simple Consumer)的主要原因是,用户希望比Consumer Group更好的控制数据的消费,如
1.同一条消息读多次,方便Replay
2.只消费某个Topic的部分Partition
3.管理事务,从而确保每条消息被处理一次( Exactly once)
与High Level Consumer相对, Low Level Consumer要求用户做大量的额外工作
1.在应用程序中跟踪处理offset,并决定下一条消费哪条消息
2.获知每个Partition的Leader
3.处理Leader的变化
4.处理多Consumer的协作
