




latch free
1.ORACLE使用锁存器来保护SGA中的内存结构,即,锁存器只保护临时的内存对象,不应用于数据库对象,ORALCE中锁存器的存在是为了保护SGA中的各种内存结构不会由于并发访问而产生潜在的破坏,执行对SGA中共享数据结构的排它性访问。锁存器是按不会受到死锁的方式实现。
2.ORACLE9i中latch free代表所有的等待锁存器的事件。ORACLE10g开始,常见的锁存器被单独取出。
3.锁存器是简单的锁设备,是由3个部分组成的内存元素:PID(进程ID)、内存地址、长度。
4.锁存器分为三种类型:父锁存器(v$latch_parent)、子锁存器(v$latch_children)、单独锁存器(在v$latch视图中包含所有锁存)
v$latch_parent(latch#是关键字)
v$latch_child(latch#与child#是组合关键字)
v$latch(latch#是关键字)
SELECT s.latch#,
t.child#, s.NAME parent_name, s.IMMEDIATE_GETS,
s.IMMEDIATE_MISSES, s.GETS, s.MISSES, s.SLEEPS
FROM v$latch s
LEFT JOIN v$latch_children t ON (s.latch# = t.latch#)
order by s.LATCH#, t.CHILD#
5.可以通过两种模式请求锁存:愿意等待和不等待(立即)模式。
>> 不等待模式只用于少数锁存器,通常用于带有多个子锁存器的锁存器,进程第一次尝试获得一个子锁存器,如果无法获得,它以不等待模式再次请求下一个子锁存,当所有的子锁存器均无法获得后,只是对最近的子锁存器采用愿意等待模式。以不等待模式获取的锁存器在immediate_gets和immediate_misses列中有统计数据。
>> 以愿意等待模式(短期等待和长期等待)获得的锁存器,在gets和misses列有统计数据。在愿意等待模式中,如果锁存器可用,在修改受保护的数据结构之前,进程将恢复信息写入到锁存器的恢复区域中,从而让PMON知道当持有锁存器的进程死亡时需要清除什么;如果锁存器不可用,那么进程会在CPU上自旋(spin)一小段时间,重新尝试获取该锁存器。参数_SPIN_COUNT决定自旋次数,缺省为20000.如果自旋_SPIN_COUNT次数后,仍然不能获得锁存,进程则在视图(v$session_wait)中提交latch free等待事件,让出CPU,然后睡眠。在睡眠周期结束后,进程醒来并重新尝试该锁存器,尝试次数为另一个_SPIN_COUNT次数,直到获得该锁存器。(如果多次请求、睡眠、唤醒仍无法获取,该进程将向PMON提交,以期PMON查明持有锁存的进程是否死亡,如果持有该锁存的进程已经死亡,那么PMON将清除并释放该锁存。)
6.从ORACLE9.2开始锁存器开始分类。每个类可以具有不同的_SPIN_COUNT值(缺省锁存器无类别)。如果某锁存器具有高SLEEPS值,并且当前的CPU资源充分,我们可以提高"该锁存器的所属类"的_SPIN_COUNT,这样虽然会增加CPU的利用率,但使MISSES和SLEEPS的数量减少。
-- 查询各个类别缺省设定
select indx as "类别", spin, yield, waittime from x$ksllclass
注:X$KSLLCLASS视图中每一行对应于一个_LATCH_CLASS_n初始化参数,这个参数允许你改变_SPIN_COUNT、YIELD、WAITTIME的值。
-- 修改相应类别的_SPIN_COUNT方法:
select latch#,name from v$latchname where name = 'cache buffers chains'; -- 获得LATCH#
在初始化参数文件init.ora中加入:
_latch_class_1="10000" -- 重设第一类的_SPIN_COUNT=10000
_latch_classes="97:1" -- 将latch#=97的锁存器归于第1类中即可
-- 查询重设的锁存器当前所属类别
SELECT a.kslldnam,
b.kslltnum, b.class_ksllt
FROM x$kslld a, x$ksllt b
WHERE a.kslldadr = b.addr
AND b.class_ksllt > 0
7.视图字段说明:
>> SLEEPS字段:睡眠次数,只有在进程获得锁存器才被更新。
>> LEVEL#字段:级别号,级别是用来防止锁存器死锁的。每个锁存器都和一个从0-13不等的级别号关联(版本差异可能关联也不相同),单独的锁存器所在的级别在ORACLE内核代码中指定。子锁存器继承父锁存器的级别,在实例启动时创建。
8.锁存器的类型:
>> v$latch_parent:父锁存器
>> v$latch_children:子锁存器
>> v$latch:单独的锁存器,同时也包含父锁存器和它们的子锁存器的合计统计。
9.锁存器与队列性质相仿,但不同于队列的是,请求锁存器的进程不需要在队列中等待。如果获取锁存器的请求失败,则进程仅仅等待一小段时间(自旋)就可以再次请求锁存器。
10.v$system_event视图中的latch free等待事件中的total_waits字段统计进程以愿意等待模式无法获得一个锁存器的次数。按道理total_waits字段的值应该等于v$latch视图中sleeps字段值的总和,然而,很多时候total_waits大于sleeps的总和,这是因为sleeps的统计只有在获得锁存器时才被更新,而不是在每次尝试时就更新。
SELECT a.total_waits, b.sum_of_sleeps
FROM (SELECT s.total_waits
FROM v$system_event s
WHERE s.event = 'latch free') a,
(SELECT SUM(sleeps) sum_of_sleeps FROM v$latch) b
V$LATCH视图中的SLEEPS字段是一个关键性的字段,由该字段可以获知进程竞争的热点锁存器:
SELECT s.latch#,
s.NAME,
s.gets,
s.misses,
s.immediate_gets,
s.immediate_misses,
s.sleeps
FROM v$latch s
ORDER BY s.sleeps DESC
通过以下查询可知:各个会话在latch free事件上的等待百分比。
select a.sid,
a.event,
a.time_waited,
round(a.time_waited/c.sum_time_waited*100 , 2)
|| '%' pct_wait_time,
round((sysdate - b.LOGON_TIME) * 24) hours_connected
from v$session_event a,
v$session b,
(select sid, sum(time_waited) sum_time_waited
from v$session_event
where event not in ('null event', 'SQL*Net message to client',
'pmon timer', 'pipe get', 'smon timer', 'jobq slave wait',
'rdbms ipc
message', 'rdbms ipc
reply', 'PX Deq: Join
ACK',
'PX Deq: Signal ACK')
having sum(time_waited) > 0 -- 对group by 产生结果的挑选
group by sid) c
where a.sid =
b.sid
and a.sid = c.sid
and a.TIME_WAITED > 0
and a.EVENT = 'latch free'
order by hours_connected desc, pct_wait_time
11.以下查询可以看出,锁存器在哪里丢失的!
SELECT s.location,
s.parent_name,
s.wtr_slp_count,
s.sleep_count,
s.longhold_count
FROM v$latch_misses s
WHERE s.sleep_count > 0
ORDER BY s.wtr_slp_count, s.location
12.参数说明:
事件号:3
事件名:latch free
参数一:进程待待的锁存器地址
参数二:锁存器号,同v$latchname.latch#
参数三:尝试次数
查找锁存器名 select * from v$latchname where latch = <P2的值>
13.常见的锁存器有:
cache buffers chains(高速缓存缓冲区链)
cache buffers Iru chain
row cache objects
library cache(数据字典库高速缓存)
shared pool(共享池)
14.shared pool锁存(LATCH#=154) - 在为新的SQL语句(硬解析)、PLSQL过程、函数、包、触发器分配共享缓冲区空间时采用该锁存器;在老化或释放共享缓冲区空间时,为新解析的SQL留出空位时也使用shared pool锁存器。
>> 共享池主要存在三种结构:字典高速缓存、SQL区域、库高速缓存。通过v$sgastat视图可以查询到。
>> 在ORACLE9I之前,共享池内存结构由单独的SHARED POOL锁存器保护,ORALCE9I开始,有多达7个子SHARED POOL锁存器可用于保护共享池结构(缺省只使用一个)。ORACLE9I可以将共享池化分为多个子池,子池的数量可以通过_KGHDSIDX_COUNT初始参数手动调整。如果手动增加了子池的数量,就应该增加SHARED_POOL_SIZE,因为每个子池都具有自己的结构、LRU列表、shared pool锁存器。否则,该实例由于错误ORA-04031而无法启动。
查询子池的数量:
SELECT a.ksppinm,
b.ksppstvl
FROM x$ksppi a, x$ksppsv b
WHERE a.indx = b.indx
AND a.ksppinm = '_kghdsidx_count'
查看共享缓冲池中的LRU队列情况:
select s.* from x$kghlu s
查看shared pool锁存的使用情况:
SELECT s.addr,
s.NAME, s.gets, s.misses,
s.waiters_woken
FROM v$latch_children s
WHERE s.NAME = 'shared pool'
>> 在ORACLE9I之前,可能会因共享缓冲区过大造成,shared pool锁存器的争用。
>> 可使用dbms_shared_pool.keep过程钉住共享池中可重用的对象,在v$db_object_cache视图中有保存的数据对象的信息。
15.library cache锁存 (LATCH#=155)- ORACLE在库高速缓存中修改、检查、固定、锁定、加载或执行对象时需要library cache锁存器,当对SQL进行硬解析时,需要生成相应的执行计划,必然会取SQL中要用到的相应的数据库对象到库高速缓存,这时就要用到library cache锁存。
>> 查询library cache锁存个数:
SELECT s.addr,
s.NAME, s.gets, s.misses,
s.waiters_woken
FROM v$latch_children s
WHERE s.NAME = 'library cache'
>> 由于带有高版本的语句,也会造成library cache锁存器的争用。ORACLE使用多个子游标来区分一些SQL语句,这些SQL具有相同的字符,但不能被共享,因为它们引用不同的底层对象。例如:不同模式下的相同表名的表。
16.造成shared pool锁存器和library cache锁存器的争用,主要是由于硬解析造成的。
>> 系统中硬解析的数量:
SELECT a.*, SYSDATE -
b.startup_time days_old
FROM v$sysstat a, v$instance b
WHERE a.NAME LIKE 'parse%'
>> 发现当前会话中的硬解析
SELECT a.sid,
c.username,
c.program,
b.NAME,
a.VALUE,
round((SYSDATE - c.logon_time) * 24) hours_connected
FROM v$sesstat a, v$statname b, v$session c
WHERE c.sid = a.sid
AND a.statistic# = b.statistic#
AND a.VALUE > 0
AND b.NAME = 'parse
count (hard)'
>> 查找未绑定变量SQL语句
SELECT hash_value,
substr(sql_text, 1, 80)
FROM v$sqlarea
WHERE substr(sql_text, 1, 40) IN
(SELECT substr(sql_text, 1, 40)
FROM v$sqlarea
HAVING COUNT(*) > 4
GROUP BY substr(sql_text, 1, 40))
>> alter session set session_cached_cursors = <数量(大于0)> 可以减少shared pool和library cache锁存的使用数量。
17.cache buffers chains锁存器
>> cache buffers chains包含很多子锁存器,例如出租车中就有1024个,也称为"散列锁存器或CBC锁存器",当缓冲区存储器大小小于1GB时,这个默认值是1024.
>> 当将数据块读入SGA时,它们的缓冲区头被放置在悬挂存储桶的散列链中,每个cache buffer chains锁存器用来控制多个存储桶,以保证存储桶中的散列链的完整性。在散列链上添加、删除、搜索、检查、读取、修改块的进程必须要先获得CBC锁。
>> 从ORACLE9开始,CBC锁存器可以只读共享。
>> cache buffers chains锁存器、存储桶、散列链的比率是:
<ORALCE8: 1:1:1
>=ORALCE8: 1:m:1(以避免长链的产生)
>> 示意图:
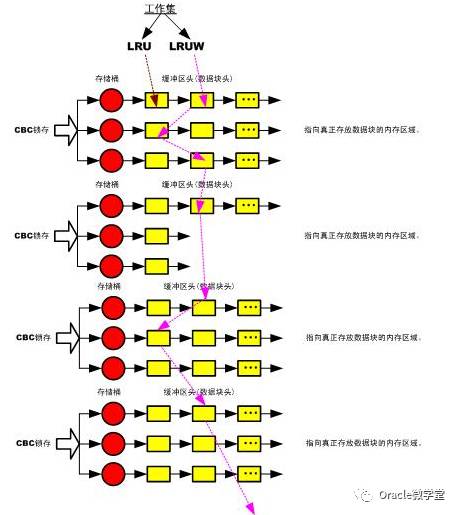
>>> 数据块放于哪个桶内是由计算公式MOD(数据块地址DBA,初始化参数_DB_BLOCK_HASH_BUCKETS)而得。
>>> 缓冲区中缓冲区头的内容显示在v$bh视图中。
>> 查询cache buffers chains锁存器的数量:
第一种方法:
SELECT s.* FROM v$latch_children s WHERE s.NAME = 'cache buffers chains'
第二种方法:
SELECT COUNT(DISTINCT hladdr) FROM x$bh
注:通过初始化参数_DB_BLOCK_HASH_LATCHES调整CBC锁存器的数量。
>> 存储桶的数 = 散列链的数 = 2*db_block_buffers
在ORACLE10g中存储桶数量的计算发生变化.
>> 逻辑处理规则:
每个逻辑读需要一个latch get操作和一个CPU;
latch get的目标就是要获得锁存器;
在任意一个时刻,只有一个进程可以有cache buffers链。
>> cache buffers chains锁存器的争用原因一:低效率的SQL语甸
在某些环境中,应用程序打开执行相同的低效率SQL语句的多个并发会话,这些SQL语句都设法得到相同的数据集。较小的逻辑读意味着较少的latch get操作,从而减少锁存器争用并改善性能。
每次执行都带有高 BUFFER_GETS(逻辑读取)的SQL语句是主要的原因。
>> cache buffers chains锁存器的争用原因二:热块
当多个会话重复访问一个或多个由同一个子cache buffers chains锁存器保护的块时,热块就会产生。当多个会话争用cache buffers chains锁存器时,找出是否有热块的最好的方法是检查latch free等待事件的P1RAW参数值。
SELECT s.EVENT,
s.sid, s.p1raw, s.p2, s.p3, s.seconds_in_wait, s.wait_time, s.state
FROM v$session_wait s
WHERE s.event = 'latch free'
如果P1RAW是相同的锁存器地址,则表明有热块出现。用以下语句查出热块所属数据库对象。
SELECT a.hladdr,
a.file#, a.dbablk, a.tch,
a.obj, b.object_name
FROM x$bh a, dba_objects b
WHERE (a.obj = b.object_id OR a.obj = b.data_object_id)
AND a.hladdr = '锁存器地址(P1RAW)'
union
select hladdr, file#
热块通常具有高TCH(touch count:接触次数),但需注意的是,块从LRU列表的冷端移到到热端时,值TCH就被重新设置为0,所以TCH值为0的块并不一定是冷块。
解决方法:
尽可能地展开块,即,让块包含的记录少一点。这样产生热点块的机率就低一些。
>> cache buffers chains锁存器的争用原因三:长散列链
18.cache buffers lru chain锁存器:
>> 除了散列表之外,缓冲区头也被链接到其他的列表,例如:LRU、LRUW、CPKT-Q,LRU列表包含各种状态的缓冲区,而LRUW列表只包含脏缓冲区。LRU和LRUW列表是相互排斥的。一对LRU+LRUW称为一个工作集(working set)。每个工作集由一个cache buffers lru chain锁存器保护(即:一个工作集有一个cache buffers lru chain锁存)。
>> 由上得知:缓冲存储器中的工作集数据由cache buffers lru chain锁存器数据决定。
select t.NAME,
s.set_id, s.set_latch
from x$kcbwds s left join v$latch_children t on (s.set_latch = t.ADDR)
注:x$kcbwds(内核高速缓存缓冲区工作集描述符)
>>> 查询cache buffers lru chain锁存器数量:
SELECT *
FROM v$latch_children s
WHERE s.NAME LIKE 'cache buffers lru chain'
>> 前台进程在寻找空闲的缓冲区时访问LRU列表。
>> 后台DBWR后台进程访问LRU列表,将脏缓冲区移入LRUW列表,从LRUW中移除清洁的缓冲区。
>> 在一个工作集上执行任何种类的操作之前,所有进程必段获取cahce buffers lru chain锁存器。
>> cache buffers lru chain锁存器的默认数量:
DB_WRITER_PROCESSES <= 4 锁存数 = 4*CPU数
DB_WRITER_PROCESSES >4 锁存数 = db_writer_processes数*CPU数
注:可以通过初始化参数_DB_BLOCK_LRU_LATCHES来向上调整cahce buffers lru chain锁存器的数量。
19.row cache objects锁存器(LATCH#=145):用来保护ORACLE数据字典(或行高速缓存,因为信息被存储为行而不是块),从ORACLE7开始,数据字典变成共享池的一部分,在每个字典对象前有一个分离的DC_*初始参数。
>> 进程必须在加载、引用或释放字典中的条目时获得这种锁存器。ORACLE9I以前,该锁存器只有一个,ORACLE9I引入在共享池中建立子池后,存在多个rowcache objects锁存器的多个副本。
>> ORACLE10g中分离出latch:row cache objects锁存。
>> v$rowcache视图具有每个数据字典对象的统计,可发现最热的对象。
SELECT t.cache#,
t.TYPE, t.parameter, t.gets,
t.getmisses, t.modifications
FROM v$rowcache t
ORDER BY t.gets
>> row cache objects调整非常有限,常见的方法只是简单地增加shared_pool_size.
扫描二维码关注我的微学堂
搜索刘老师微信号:Rman-2014,备注“Oracle学习与咨询”,即可添加好友;或者扫描下面二维码,关注我的“微学堂”公众号,了解最新OCP认证动态、题库及答案解析、培训机构及讲师介绍、课堂授课内容等。每天还有一篇技术文章发布哦!

