作者 | teddxu(徐进)
导读
互联网的蓬勃发展,业务驱动技术不断升级,系统越来越庞大,技术越来越复杂,应用部署集群化,所有压力全部指向数据库,数据量巨大,数据库优化也到极限了,数据库的运维难以为继,在这种情况下,分布式似乎成为唯一的解决方案。为了解决传统数据库的分布式化这个技术难题,各种数据库中间件应运而生。
1.分库分表产生背景
让我们先来回顾一下一般系统架构的发展
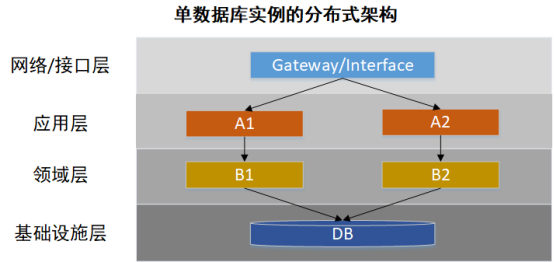
往往我们刚上线的系统都采用了单数据库实例的分布式服务架构(如下图所示),上线初期,随着业务量的快速发展,系统的瓶颈主要在于上层应用的计算能力不足,我们可以简单的通过水平扩展来解决这个问题。
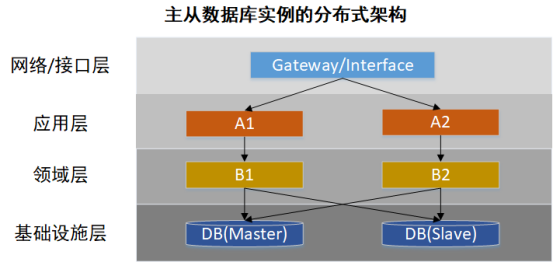
在上层应用的不断水平扩展的同时,系统的压力开始逐渐下移,单机DB的压力越来越大,这个矛盾逐渐转变为主要矛盾,因此我们采用了读写分离的主从DB分布式服务架构(如下图所示)。让非重要的读操作直接访问从库,从而减轻主库的压力。
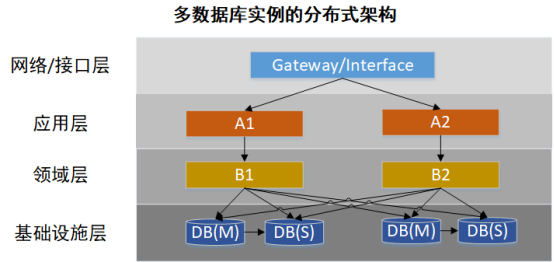
但由于主从延迟的存在,能够直接访问从库读操作并不多,并且写操作还是全量作用于主库。当业务量量级再次增高时,写已经变成刻不容缓的待处理瓶颈。这时候,分库分表(本文中的分库分表特指水平分库分表)方案出现了,即分库分表的分布式服务架构(如下图所示):
分库分表做到极致基本能支撑 TPS 在万级甚至更高的访问量了。分库分表理论上在DB层是可以无限水平扩展的,那是什么制约了分库分表的支撑量呢?又该如何解决呢?大家有兴趣的话可以自行思考下。
小结:分库分表解决的最大痛点是数据库单点瓶颈,这个瓶颈的产生是由现代二进制数据存储体系决定的(即 I/O 速度)。
中国互联网技术圈广为流传着这么一个说法:当单表行数超过 500 万行或者单表容量超过 2GB,推荐进行分库分表。当单表行数超过 2000 万行或者单表容量超过 8GB时,性能会明显下降。
当然,具体的数值是与MySQL 的配置以及机器的硬件密切相关的
那乐信DBA所推荐的分库分库数值是多少呢:单表行数尽量保持在 800 万行左右,单表超过1000万行,性能就会开始下降。
(补充:如果预计三年后的数据量根本达不到这个级别,请不要在创建表时就分库分表)
2.如何实现分库分表
既然知道了分库分表的原因,那么业内都是如何实现分库分库的呢?
分布式数据库中间件的目标是管理数据库。分布式数据库中间件不负责最终的最底层存储,而是在数据库的上一层将数据库管理起来。至于终端存储是什么类型的数据库,分布式数据库中间件并不关注。因此,数据库中间层能够以管理者的视角去管理这些多元异构数据,并在他们之上增量的负责处理分片、扩容、治理、高可用、脱敏、审计、融合等能力。
分库分表的技术方案总体上来讲分为两大类:应用层依赖类中间件、中间层代理类中间件。
应用层依赖类中间件
这类分库分表中间件的特点就是和应用强耦合,需要应用显示依赖相应的jar包(以Java为例),比如知名的TDDL、当当开源的sharding-jdbc、蘑菇街的TSharding、携程开源的Ctrip-DAL等。我们以sharding-jdbc为例,其架构图如下所示:
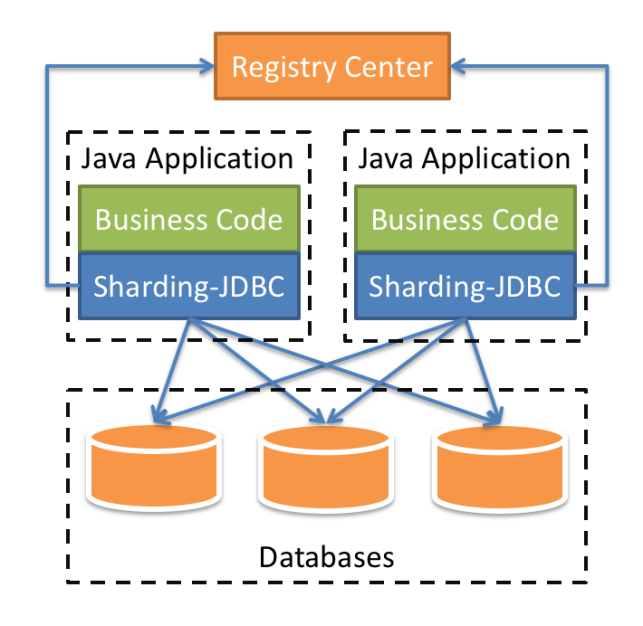
此类中间件的基本思路,就是重新实现JDBC的API,通过重新实现DataSource、PrepareStatement等操作数据库的接口,让应用层在基本不改变业务代码(需业务自行定义路由规则)的情况下透明地实现分库分表的能力。
中间件给上层应用提供熟悉的JDBC API,内部通过一系列的准备工作获取真正可执行的sql,然后底层再按照传统的方法(比如数据库连接池)获取物理连接来执行sql,最后把数据结果合并处理成ResultSet返回给应用层。
优点
无需额外部署,性能损耗低,无中心化
缺点
不支持异构语言,与应用强耦合,SQL支持能力较弱(受应用影响),连接消耗数高
中间层代理类中间件
这类分库分表中间件的核心原理是在应用和数据库的连接之间搭起一个代理层,上层应用以标准的MySQL协议来连接代理层,然后代理层负责转发请求到底层的MySQL物理实例,这种方式对应用只有一个要求,就是只要用MySQL协议来通信即可,所以用MySQL Workbench这种纯的客户端都可以直接连接你的分布式数据库,自然也天然支持所有的编程语言。比较有代表性的产品有开创性质的Amoeba、阿里开源的Cobar、Mycat 、当当开源的sharding-proxy,奇虎360开源的Atlas等。我们以sharding-proxy为例,其架构图如下所示:
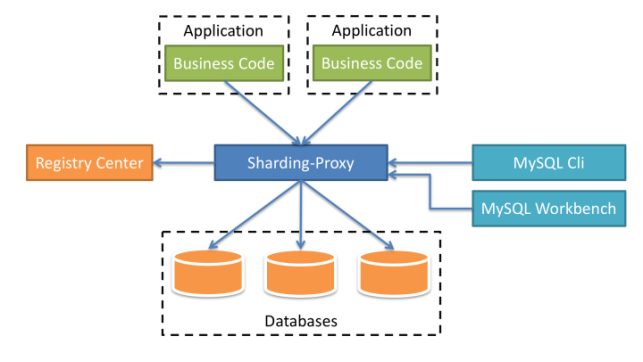
优点
支持异构语言,与应用完全解耦,SQL支持能力较强,连接消耗数低
缺点
需连接消耗数,性能损耗略高,存在中心化
无论应用层依赖类中间件还是中间层代理类中间件,其核心流程都是相同的,即:SQL解析->SQL路由->SQL重写->SQL执行->结果处理(排序,聚合,合并)。除了分库分表功能之外,分布式数据库中间件还可以集成分布式自增主键,数据库治理,分布式事务等功能。
SQL解析是整个分布式数据库中间件的核心,SQL解析和程序代码解析类似,它按照SQL语法对SQL文本进行解析,识别出文本中各个部分然后以抽象语法树(AST)的形式输出。开源产品使用的SQL解析引擎各不相同。不同的解析引擎偏重的能力有所不同,有的更注重解析SQL的性能,有的更注重支持SQL的能力,还有的更注重扩展性和兼容性。使用比较多的有JSQLParser,Druid,ANTLR等。
小结:应用层依赖类中间件采用无中心化架构,适用于Java开发的高性能的轻量级OLTP应用;中间层代理类中间件提供静态入口以及异构语言的支持,适用于OLAP应用以及对分片数据库进行管理和运维的场景。
OLTP与OLAP的介绍
数据处理大致可以分成两大类:联机事务处理OLTP(Online Transactional Processing)、联机分析处理OLAP(Online Analytical Processing)。OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
3.未来的发展
混合架构 OR TIDB
随着以TIDB为代表的分布式数据库的兴起,分布式数据库中间件是否很快就要退出历史的舞台了呢?
TiDB介绍
TiDB 是 PingCAP 公司设计的开源分布式 HTAP (Hybrid Transactional and Analytical Processing) 数据库,结合了传统的 RDBMS 和 NoSQL 的最佳特性。TiDB 兼容 MySQL,支持无限的水平扩展,具备强一致性和高可用性。TiDB 的目标是为 OLTP (Online Transactional Processing) 和 OLAP (Online Analytical Processing) 场景提供一站式的解决方案。
知名论文<What’s Really New with NewSQL?>,文中明确的描述了NewSQL的三种类型:新架构、透明化分片中间件和云数据库,即BaaS。因此,数据库中间件是NewSQL的一种。它只是以与新架构和BaaS不同的角度去实现NewSQL的功能。
小结:采用什么样的数据库,取决于业务本身,如果单机数据库已经能满足你当前的业务需求并且也能满足可预期的未来一段时间的业务需求,那就没必要用分布式数据库。所以分布式数据库只是额外提供了一种选择,而不是对原有数据体系的完全颠覆。
参考文献:
shardingsphere官网:https://shardingsphere.apache.org/document/current/cn/overview/
mycat官网:http://mycat.bcu.ac.uk/
TIDB官网:https://pingcap.com/
end