





作者 | fixlei & jianhuichen
导读
缓存是开发中经常会用到的技术,但是怎么用好却不那么简单。本文简要介绍了缓存的使用场景以及分类,并给出了高并发、大数量场景的解决方案。最重要的是,这个解决方案的多级缓存组件已经内部开源,可以方便接入。
(1) 高效的缓存淘汰算法
缓存淘汰算法的作用是在有限的资源内,尽可能识别出哪些数据在短时间会被重复利用,从而提高缓存的命中率。常用的缓存淘汰算法有LRU、LFU、FIFO等。
LRU(Least Recently Used)算法认为最近访问过的数据将来被访问的几率也更高。LRU通常使用链表来实现,如果数据添加或者被访问到则把数据移动到链表的头部,链表的头部为热数据,链表的尾部如冷数据,当数据满时,淘汰尾部的数据。实现比较简单,但是存在一些问题,如:当存在数据遍历时,会导致LRU命中率急剧下降,缓存污染情况比较严重。LRU算法也并非一无是处,其在突发流量下表现良好。
LFU(Least Frequently Used)算法根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”。根据LFU的思想,如果想要实现这个算法,需要额外的一套存储用来存每个元素的访问次数,会造成内存资源的浪费。
FIFO(First In First Out)算法按缓存先进先出的顺序淘汰,正好符合队列的特性,实现起来复杂度较低,但是命中率很低,因为命中率太低,实际应用中基本上不会采用。
目前缓存框架采用是W-TinyLFU算法,这个是由前Google工程师发明的一种现代的缓存淘汰算法, 这种算法采用了一种结合LRU、LFU优点的,其特点:高命中率、低内存占用。这种算法还解决LFU算法造成内存资源浪费的问题,并且还解决了在突然流量暴涨的的场景中,一些短暂的重复流量就不会被长期保留的问题。
下面详细介绍W-TinyLFU算法是如何解决其他淘汰算法的缺陷。
Ⅰ. 如何避免维护频率信息的高开销
W-TinyLFU借助了Count-Min Sketch技术(其实就是一个计数型的布隆过滤器),显然这是解决这个问题的有效手段,它可以用小得多的空间存放频率信息,而保证很低的误判率
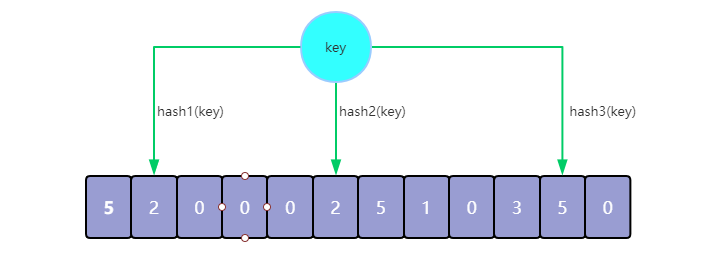
获取缓存元素对应频率
如下图所示,获取到3个hash位置上的计数值:{2, 2, 5},取所有值中的最小值返回
新增缓存元素访问频率
在元素到达后,获取到已有的3个计数值{2, 2, 5},Add操作仅增加两个较小的计数值,来避免针对最大值的不必要的增加
Ⅱ. 数据访问流量频率随时间有变,如何使Sketch中的数据尽可能最新
LFU算法的频率信息无法随之变化,因此早先频繁访问的记录可能会占据缓存,而后期访问较多的记录则无法被命中。
W-TinyLFU采用了一种基于滑动窗口的时间衰减设计机制,借助于一种简易的reset操作:每次添加一条记录到Sketch的时候都会给一个计数器上加1,当计数器达到一个尺寸W的时候,把有记录的Sketch数值都除以2(可以使用高效的寄存器位移来实现),该reset操作可以起到衰减的作用。已论文验证Reset机制的正确性,Reset在固定的频率分布下完全正确,且可以应对流量频率的变化。
Ⅲ. 如何应对突发流量因无法在给定时间内积累到足够高的频率被淘汰,以及如何避免长尾流量浪费计数器空间
在一些数目很少但突发访问量很大的场景下,LFU将无法保存这类元素,因为它们无法在给定时间内积累到足够高的频率。因此W-TinyLFU就是结合LFU和LRU,前者用来应对大多数场景,而LRU用来处理突发流量。
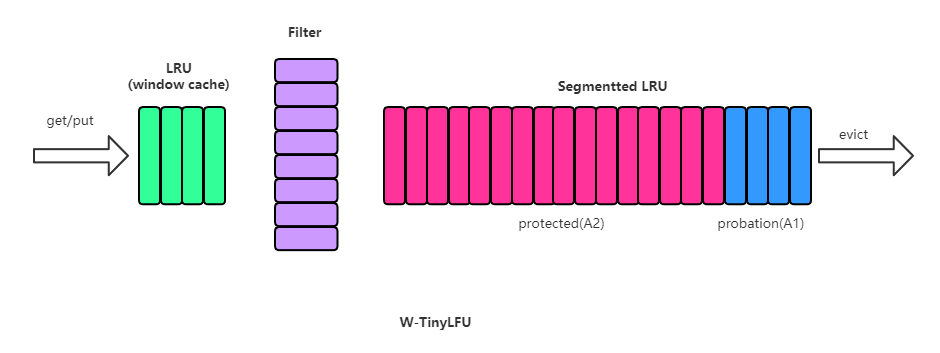
前端是一个小的LRU(window cache);window cache淘汰后,会送到Filter过滤;过滤通过后,元素存储到一个大的Segmented LRU缓存里。Window LRU,它的容量只占据1%的总空间,它的目的就是用来存放短期突发访问记录。存放主要元素的Segmented LRU(SLRU)是一种LRU的改进,主要把在一个时间窗口内命中至少2次的记录和命中1次的单独存放,这样就可以把短期内较频繁的缓存元素区分开来。具体做法上,SLRU包含2个固定尺寸的LRU,一个叫Probation段A1,一个叫Protection段A2。新记录总是插入到A1中,当A1的记录被再次访问,就把它移到A2,当A2满了需要驱逐记录时,会把驱逐记录插入到A1中。W-TinyLFU中,SLRU有80%空间被分配给A2段。
(2) 缓存惰性异步刷新
惰性刷新
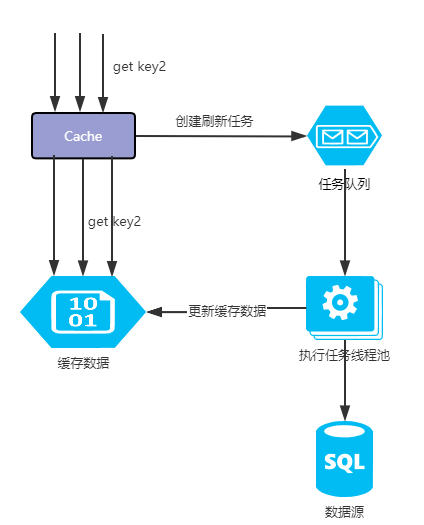
只有在缓存被访问的时候才会判断是否需要刷新,这样不仅可以减少系统资源的消耗,也可以提高热点数据的缓存有效性和实时性。
异步刷新
当缓存在访问时判断需要被刷新时. 会创建一个刷新任务异步去刷新,不会阻塞当前线程获取缓存的操作。
无锁化并发刷新
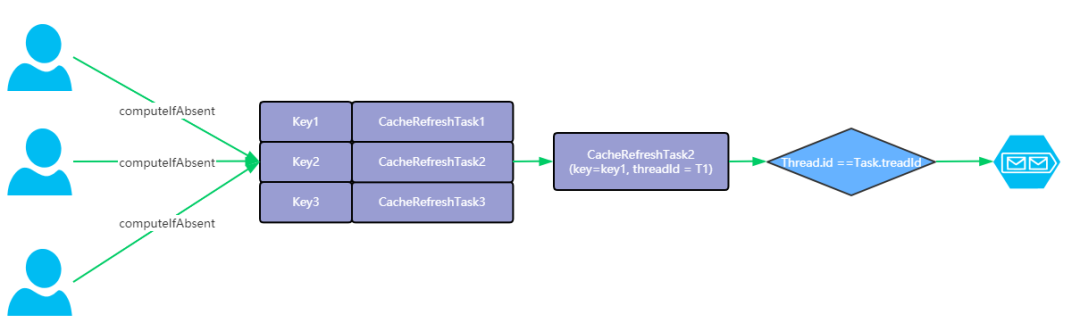
当一个缓存同时被多个线程并发访问都判断需要被刷新时, 框架内部只会创建一个缓存异步刷新任务. 这个过程是在采用CAS机制控制并发重复刷新。
(3) 多节点缓存数据同步机制
当分布式应用对各节点缓存数据时效性要求较高,但又不要求数据分区的强一致性,只要保证缓存各个节点的缓存数据最终一致性,不能出现差异现象时,就可以考虑启用多节点缓存数据同步策略。因为如果只是依赖缓存的过期和更新策略,就会造成各个节点的缓存存在长时间不一致的情况。
因此,多节点缓存同步机制在遇到缓存节点存数据变更时会实时同步给其他节点,同步过程中存在一定的时延,目前已经实现了基于Redis、Zookeeper、Apollo的同步策略,这里主要利用了Redis、Zookeeper、Apollo的发布订阅功能,并不是用ZK来保证强一致性。
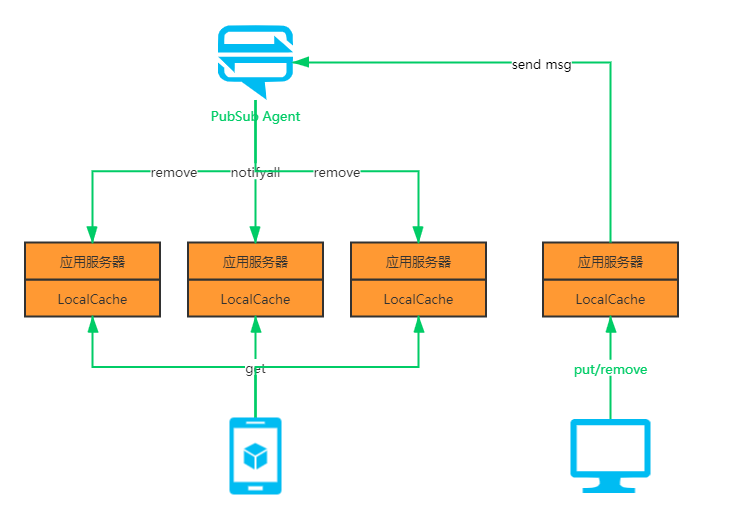
这里介绍一下Zookeeper的同步策略实现逻辑,Redis也是类似:
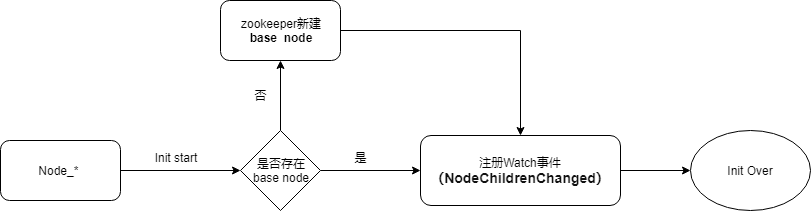
每个应用节点在启动初始化时会判断当前是否需要创建base Node ,并为其注册EventType.NodeChildrenChanged 事件的Watcher,各节点利用Watch 事件机制,用于监听同步命令。流程图如下:
接下来,各缓存节点就可以进行Command同步,当有节点的缓存数据更新成功时,会发出publish sync Command命令至Zookeeper,此时会触发NodeChildrenChanged Watch事件。其他节点监听到事件触发,可接收到sync Command,整体同步流程图如下:

可以看出,当有节点需要更新缓存数据时,必须等待同步命令发送至Zookeeper之后等待响应完成,才能返回更新结果给客户端,如此一来单节点的缓存数据更新操作就存在调用链路过长的问题,极大的影响了性能;同时,考虑到每个节点的每次缓存更新操作都要去通知Zookeeper创建临时节点,当各节点缓存数据更新频率较高时对Zoookeeper的压力就会非常大了。
至此,总结到当前方案存在两个比较大的问题,一是多节点缓存同步命令容易形成消息风暴 ,二是单节点数据更新与发送数据同步命令操作偶合过重,所以在多节点缓存数据同步策略的实现中我们使用了异步蓄池操作方案,通过开源的Disruptor环形队列异步处理框架对当前节点的数据更新操作与发送缓存同步命令进行操作异步处理,同时对要发出的缓存同步命令消息进行蓄池批量发送,引入Disruptor之后最终的缓存数据节点同步操作。时序图如下:
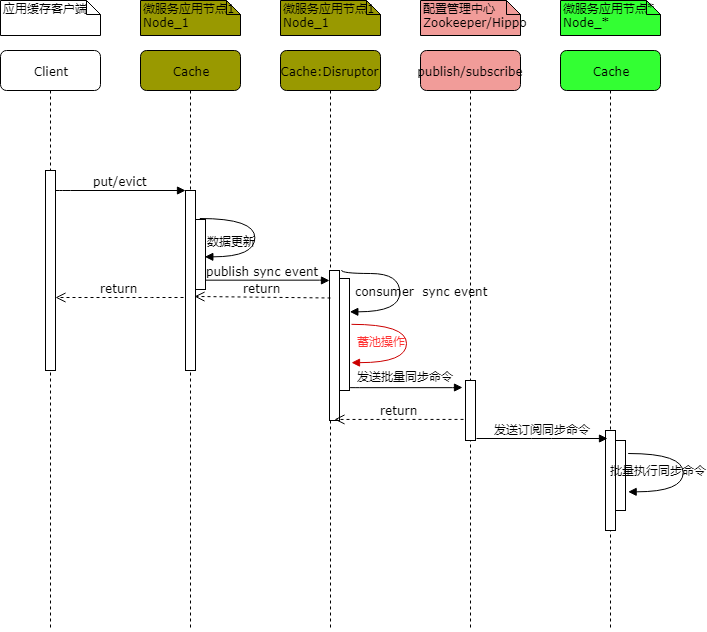
当缓存节点执行完本地缓存数据更新命令并发布同步事件至Disruptor环形队列之后就可以异步返回响应成功结果给Client端,无需关注后续的同步事件命令发送情况。
针对Disruptor的消费端线程,默认支持发布事件蓄池操作,当前支持按发布同步事件数量和发布事件前后最大间隔时间蓄池,如果两个都配置了,当前满足任意一个配置阈值都将发送出批量同步命令消息至Zookeeper。
Disruptor环形缓存队列的缓存大小必须是2的N次方,支持使用端自定义配置,默认为1024*1024;选用Disruptor环形队列是用来保证异步处理同步命令的高性能,相比较JDK传统的缓存队列其具有一定的性能优势。
如下是Disruptor环形队列与java.util.concurrent.ArrayBlockingQueue 的性能测试对比数据:(数据来源Disruptor github)
Nehalem 2.8Ghz – Windows 7 SP1 64-bit
Comparative throughput (in ops per sec)
| Array Blocking Queue | Disruptor |
|---|---|---|
| Unicast: 1P – 1C | 5,339,256 | 25,998,336 |
| Pipeline: 1P – 3C | 2,128,918 | 16,806,157 |
| Sequencer: 3P – 1C | 5,539,531 | 13,403,268 |
| Multicast: 1P – 3C | 1,077,384 | 9,377,871 |
| Diamond: 1P – 3C | 2,113,941 | 16,143,613 |
Sandy Bridge 2.2Ghz – Linux 2.6.38 64-bit
Comparative throughput (in ops per sec)
| Array Blocking Queue | Disruptor |
|---|---|---|
| Unicast: 1P – 1C | 4,057,453 | 22,381,378 |
| Pipeline: 1P – 3C | 2,006,903 | 15,857,913 |
| Sequencer: 3P – 1C | 2,056,118 | 14,540,519 |
| Multicast: 1P – 3C | 260,733 | 10,860,121 |
| Diamond: 1P – 3C | 2,082,725 | 15,295,197 |
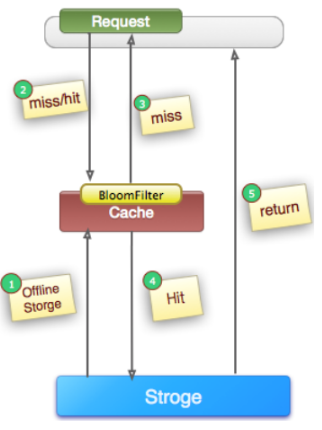
(4) 使用布隆过滤器解决缓存穿透问题
在高并发场景下,如果某一个key被高并发访问,没有被命中,出于对容错性考虑,会尝试去从后端数据库中获取,从而导致了大量请求达到数据库,而当该key对应的数据本身就是空的情况下,这就导致数据库中并发的去执行了很多不必要的查询操作,从而导致巨大冲击和压力。通常一般是通过以下的方法来避免缓存穿透问题:
缓存空对象
对查询结果为空的对象也进行缓存,如果是集合,可以缓存一个空的集合(非null),如果是缓存单个对象,可以通过字段标识来区分。这样避免请求穿透到后端数据库。同时,也需要保证缓存数据的时效性。这种方式实现起来成本较低,比较适合命中不高,但可能被频繁更新的数据。
但是上面解决方式,会浪费大量的内存空间,而且如果用大量无效key访问,还是会穿透到数据库,无法根本解决问题,目前我们缓存组件可以采用布隆过滤器来解决这个问题,布隆过滤器能用小空间来判断key是否存在,避免无效的key请求到数据库。
提供统一数据看板,对于远端remoteCache redis,中间件通过redis-rdb-tools分析工具,能够获取下面的信息。在数据看板提供明细数据查看维度如下,并支持通过key维度搜索数据。
数据库ID
数据类型
key
内存使用量(Byte)
编码
key中的value的个数
key中的value的长度
expiry过期时间
同时基于以上明细数据,中间件可分析出技术人员比较关注的多维度key统计数据供运维和研发实时监控应用缓存使用情况,如内存占用最高1000的key排行表、未设置过期时间且内存占用最高的1000排行表、value个数1000以上的list、大于1KB的大key列表排行表、大于1kb的大key的趋势图、没设置ttl数量的趋势图,key数量趋势图、每个分组key的数量及内存使用量趋势图。(是否大于指定的key数量时才展示)等一系列统计指标。
多级缓存中间件着重解决了以下4个关键问题:
1、数据一致性:前置在应用层的本地缓存,保障与分布式远端缓存及数据源db的数据一致性。
2、热点探测:快速且准确的发现热点访问 key。
3、效果验证:让应用层查看本地缓存命中率、热点 key 等数据,验证多级缓存效果。
4、透明接入:中间件减少对应用系统的入侵,做到应用快速平滑接入。
当遇到类似场景时,可以选用多级缓存中间件来轻松解决这类问题。TDP开源项目中可以查找到本项目的详细信息,本公众号菜单中也可以进行查询。
上篇传送门:多级缓存组件性能的解密(上)
end

