




Apache Hadoop 2.9.0
原文:
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/ViewFs.html
(如果转发,请标明出处)
简介:
View File System (ViewFs)提供了一种管理多个Hadoop文件系统命名空间(或者命名空间卷)的方法。它对于在HDFS联邦中具有多个namenodes并因此具有多个名称空间的集群特别有用。在HDFS联邦中,ViewFs 类似于某些Unix Linux系统中的客户端挂载表。ViewFs 可用于创建个性化命名空间视图以及每个集群的通用视图。
本指南是在具有多个集群的Hadoop系统的环境中提供的,每个集群可以联合成多个名称空间。它还描述了在HDFS联邦中如何使用ViewFs 来提供每个集群的全局命名空间,以便应用程序可以以类似于联合前的方式运行。
旧世界(联邦之前)
单一Namenode的集群
在HDFS联邦之前,每个集群只有一个NameNode来为集群提供一个文件系统的命名空间。当有多个集群时,每个集群的文件系统命名空间必须是完全相对独立并且没有交集。此外,物理存储也不在集群中间共享(例如Datanodes 不在集群中间共享)。
每个集群的core-site.xml中都有一个配置变量来设置默认的文件系统为该集群的namenode节点:
<property>
<name>fs.default.name</name>
<value>hdfs://namenodeOfClusterX:port</value>
</property>
这样的配置属性允许使用斜杠相对路径的方式来解析集群namenode的路径。例如,上面的配置下,目录/foo/bar等同于hdfs://namenodeOfClusterX:port/foo/bar 。
此配置属性设置在集群的每个网关上,也设置在集群的关键服务上(例如JobTracker和Oozie)。
路径名使用模式
因此,在如上所述设置 core-site.xml的集群X上,典型的路径名为
(1) /foo/bar
和上面描述的一样,等同于 hdfs://namenodeOfClusterX:port/foo/bar。
(2) hdfs://namenodeOfClusterX:port/foo/bar
虽然这是一个有效的路径名,但是最好使用/foo/bar,因为它允许应用程序及其数据在需要时透明地移动到另一个集群。
(3) hdfs://namenodeOfClusterY:port/foo/bar
这是一个引用其他集群(例如Cluster Y)目录的URI。一个特殊的例子,将文件从集群Y移动到集群Z的命令:
distcp hdfs://namenodeClusterY:port/pathSrc hdfs://namenodeClusterZ:port/pathDest
(4) webhdfs://namenodeClusterX:http_port/foo/bar 和 hftp://namenodeClusterX:http_port/foo/bar
它们分别是用于通过WebHDFS文件系统和HFTP文件系统访问文件的URIs。请注意,WebHDFS和HFTP使用的是namenode 的HTTP端口,而不是RPC端口。
(5) http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和 http://proxyClusterX:http_port/foo/bar
这两个网址分别是用于通过 WebHDFS REST API和 HDFS proxy来访问文件。
路径名使用最佳做法
当在一个集群中时,建议使用上面(1)的路径名,而不是使用(2)中的完全路径的URI。完全的URI路径类似于地址,不允许应用程序随着数据移动。
新世界 - 联邦和ViewFs
集群看起来是什么样子
假设有多个集群,每个集群有一个或者多个namenodes,每个namenode都有自己的命名空间,并且每个namenode都只属于一个集群,在同一个集群中的namenodes之间共享集群的物理存储,跨集群的命名空间和以前一样相互独立。
操作员根据存储需要来决定集群内每个namenode上存储的内容。例如,可以将用户数据(/user/<username>)放到一个namenode,将所有馈送数据(feed-data)( data )放到另一个namenode,所有项目( projects )放到另一个namenode。
使用ViewFs的每个集群的全局命名空间
为了提供非联邦集群的透明度,ViewFs文件系统(即客户端挂载表)用于为每个集群创建独立的集群命名空间视图,这与旧世界中的命名空间类似。客户端挂载表(类似Unix挂载表)使用旧的命名约定挂载新的命名空间卷。下图显示了挂载四个命名空间卷: /user, /data, /projects, 和/tmp的挂载表:
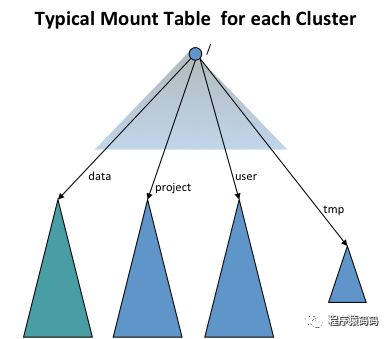
ViewFs就像HDFS和本地文件系统一样,实现了Hadoop文件系统接口。从只允许链接到其他文件系统的意义上讲,它是一个普通的文件系统。因为ViewFs实现了Hadoop文件系统接口,所以它可以透明的使用。例如,所有shell命令可以与使用HDFS和本地文件系统一样的来使用ViewFs 。
挂载表的挂载点在标准Hadoop配置文件中指定。在每个集群的配置中,默认文件系统设置为该集群的挂载表,如下所示(请与单个namenode集群中的配置进行比较)。
<property>
<name>fs.defaultFS</name>
<value>viewfs://clusterX</value>
</property>
URI中viewfs:// 后面的字符串是挂载表名称,建议使用集群名称命名集群的挂载表,Hadoop系统将在Hadoop配置文件中查找名为“clusterX”的挂载表。操作将所有网关和服务机器安排为包含所有集群的挂载表,这样,对于每个集群,默认文件系统都设置为该集群的ViewFs挂载表。
目录名使用模式
core-site.xml被设置为默认挂载表的集群Cluster X中,典型的目录名如下:
(1) /foo/bar
等同于 viewfs://clusterX/foo/bar。如果在旧的非联邦系统中使用这样的路径名,则可以透明的过渡到联邦系统。
(2) viewfs://clusterX/foo/bar
虽然是个合法的目录名,但是最好是使用 /foo/bar,因为 /foo/bar在需要时可以允许应用程序和它的数据透明的移动到另一个集群。
(3) viewfs://clusterY/foo/bar
这是一个引用其他集群(例如Cluster Y)的URI。一个典型的例子,使用命令从cluster Y 拷贝文件到Cluster Z:
distcp viewfs://clusterY/pathSrc viewfs://clusterZ/pathDest
(4) viewfs://clusterX-webhdfs/foo/bar 和 viewfs://clusterX-hftp/foo/bar
这2个是通过WebHDFS 文件系统和HFTP 文件系统来访问文件的URIs。
(5) http://namenodeClusterX:http_port/webhdfs/v1/foo/bar 和http://proxyClusterX:http_port/foo/bar
这2个是通过 WebHDFS REST API和HDFS proxy来访问文件的HTTP URLs。需要注意的是,这2个和联邦之前一样。
路径名使用最佳做法
在一个集群内,建议使用上面(1)中的目录名,而不是使用完全的上面(2)中的URI。此外,应用程序不应使用挂载点的目录,也不应使用hdfs://namenodeContainingUserDirs:port/joe/foo/bar这样的目录来引用特定namenode中的文件,而应使用/user/joe/foo/bar来代替。
跨命名空间重命名目录
在非联邦的集群中,不能跨namenodes 或者集群来重命名文件或目录。在联邦系统中也是如此,但是有个例外,例如,非联邦集群中,可以执行下面的命令:
rename /user/joe/myStuff /data/foo/bar
在联邦系统中,如果/user 和/data 存储在集群中的不同namenode上,那么这条命令就不能执行成功。
FAQ
① 当我从非联邦集群移动到联邦集群时,我必须跟踪不同卷的Namenode,我可以这样做吗?
不,你不会的。请查看上面的例子 -- 你或者是使用相对名字并利用默认的文件系统,或者将路径从hdfs://namenodeCLusterX/foo/bar更改为 viewfs://clusterX/foo/bar。
② 在一个集群中,如果操作是将一些文件从一个namenode移动到其他namenode时,会发生什么事情?
操作可以将文件从一个名称节点移动到另一个名称节点,以便处理存储容量问题。这样做是为了避免应用程序中断。让我们举几个例子。
例子1:/user 和 /data在同一个namenode,后续为了存储容量问题,需要将他们移动到不同的namenode上。实际上,操作为/user 和 /data创建单独的挂载点。在更改之前,/user 和 /data的挂载会指向相同的namenode,例如namenodeContainingUserAndData。操作更改装载表,以便将装载点分别变更为namenodeContaingUser 和namenodeContainingData。
例子2:所有的项目都在一个namenode,后续会需要2个或多个namenode。ViewFs 允许像 /project/foo 和/project/bar一样的挂在,这就允许更新挂载表来指向对应的namenode。
③ 挂载表是在每个core-site.xml 中还是它自己的一个单独文件?
计划是将挂载表保存到单独的文件,并core-site.xml 中来引用(xincluding)装载表。虽然可以保存这些文件到每台机器本地,但最好是使用HTTP从一个中心位置来访问这些文件。
④ 配置需要为一个集群或者多个集群保存挂载表定义吗?
配置应具有所有集群的挂载定义,因为需要访问其他群集(如distcp )中的数据。
⑤ 如果操作随着时间的推移可能需要更改挂载表,那么挂载表实际读取时间是什么时候?
当作业提交给集群的时候,挂载表就会被读取。在作业提交时间,core-site.xml中的XInclude 就会被扩展。这就意味着当挂载表已经改变时,作业需要被重新提交。因为这个原因,我们需要实现 merge-mount,这样就能大大的减少更改挂载表的需要。此外,我们希望将来通过在作业开始时初始化的另一种机制读取挂载表。
⑥ JobTracker (或者 Yarn’s Resource Manager)本身是否使用ViewFs?
不,他们不需要。NodeManager也不需要。
⑦ ViewFs 是否只允许挂载到最顶层目录?
不,它很普遍的使用。例如,可以挂载到/user/joe 和/user/jane。在这种情况下,将在挂载表中为/user创建一个内部的只读目录,所有的 /user的操作都是合法的,但/user为只读操作除外。
⑧ 一个应用在跨集群的环境中工作并且需要持久化存储文件路径,那么这个应用需要存储哪些路径?
您应该存储 viewfs://cluster/path类型路径名称,与运行应用程序时使用的名称相同。只要操作以透明的方式执行移动,就可以避免数据在群集内namenodes间的移动。如果数据从一个集群移动到另一个集群,则不会隔离用户;旧的(联盟前)世界并未保护用户免受跨群集的此类数据移动的影响。
⑨ delegation tokens?
提交作业的delegation tokens(包括该集群挂载表的所有挂载卷)以及map-reduce 任务输入和输出路径的delegation tokens(包括通过指定输入和输出路径的挂载表挂载的所有卷)都将自动处理。此外,还有一种方法可以在特殊情况下向基本集群配置添加其他delegation tokens。
Appendix:一个挂载表配置举例
通常,用户不必定义挂载表或 core-site.xml来使用挂载表。这是通过操作来完成的,正确的配置是在正确的网关计算机上设置的,就像现在对 core-site.xml所做的那样。
挂载表可以在 core-site.xml中进行描述,最好是在 core-site.xml中指向一个单独的配置文件 mountTable.xml。添加下面的配置到 core-site.xml来引用mountTable.xml:
<configuration xmlns:xi="http://www.w3.org/2001/XInclude">
<xi:include href="mountTable.xml" />
</configuration>
在文件mountTable.xml中,这里有个“ClusterX”挂载表,定位为由3个namenode管理的3个命名空间卷的HDFS联盟。
nn1-clusterx.example.com:8020,
nn2-clusterx.example.com:8020, and
nn3-clusterx.example.com:8020.
这里/home 和 /tmp在Namenode nn1-clusterx.example.com:8020管理的命名空间中,projects /foo 和/bar是联邦集群中其他namenodes管理的。集群的home目录设置为 /home,这样每个用户就可以通过使用 FileSystem/FileContext中定义的getHomeDirectory()来访问home目录:
<configuration>
<property>
<name>fs.viewfs.mounttable.ClusterX.homedir</name>
<value>/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./home</name>
<value>hdfs://nn1-clusterx.example.com:8020/home</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./tmp</name>
<value>hdfs://nn1-clusterx.example.com:8020/tmp</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/foo</name>
<value>hdfs://nn2-clusterx.example.com:8020/projects/foo</value>
</property>
<property>
<name>fs.viewfs.mounttable.ClusterX.link./projects/bar</name>
<value>hdfs://nn3-clusterx.example.com:8020/projects/bar</value>
</property>
</configuration>
--------------------全文完 -----------------------------------
备注:
旧世界:联邦之前
挂载表:mount table
