目录:
1. Datanode概述
2. Datanode磁盘管理
3. Datanode异构存储
4. HDFS Balancer
说明:本篇文章主要基于hadoop2.7.2版本进行整理。
一. Datanode概述
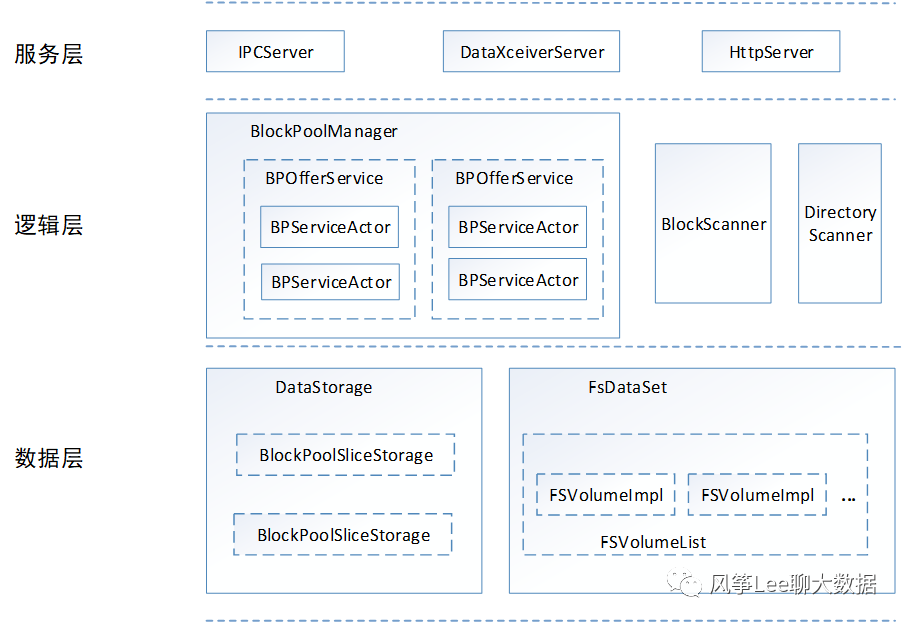
首先简单介绍下datanode逻辑结构、磁盘存储结构,逻辑结构主要分三层:服务层、逻辑层、数据层,如下图所示,
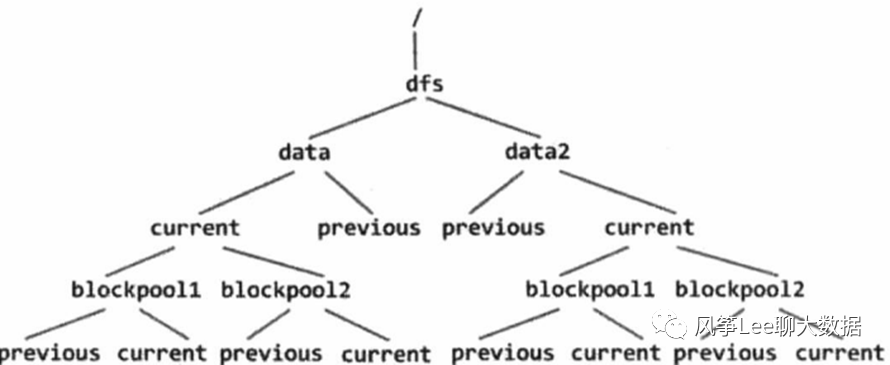
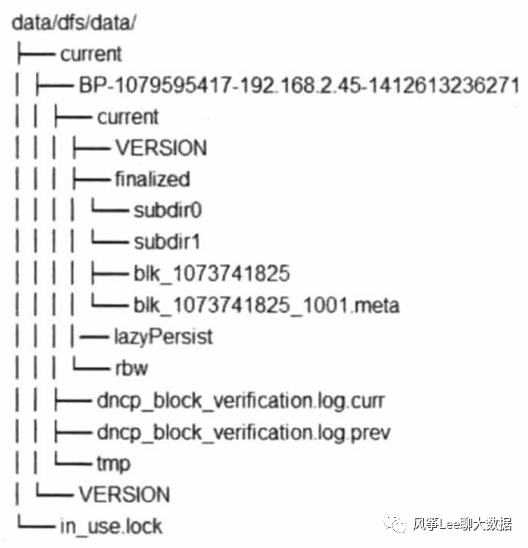
Datanode目录 存储结构如下两个图所示:
二. Datanode 磁盘管理
Datanode节点如何保障数据存储的安全可靠性?
工作机制:
HDFS的一个核心假设是,硬件故障是常态,而不是例外。当磁盘发生故障时,块文件和元文件中的一个或两个都可能损坏。HDFS具有识别和处理这些问题的机制:
DiskChecker: 磁盘检查器
DirectoryScanner:目录扫描器
BlockScanner: 数据块扫描器
DiskChecker:
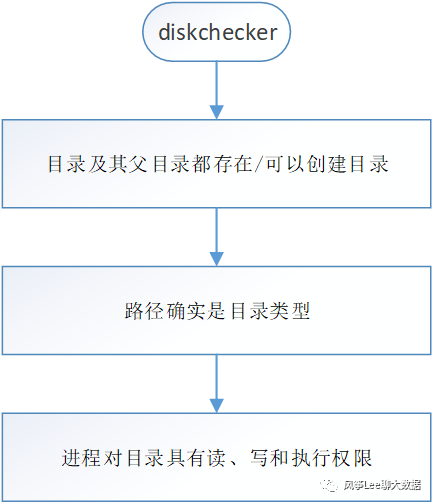
坏盘检测服务。检测的级别是每个磁盘,检测的对象是FsVolume,FsVolume对应一个存储数据的磁盘。通过检测文件目录的访问权限以及目录是否可创建来判断目录所属磁盘的好坏,如果是坏盘,则此块盘将会被移除,上面的所有块都将被重新复制;
Why DiskChecker?
1.如果在卷级别出现错误,HDFS应该检测到错误,并停止写入该卷。
删除一个volume并不简单(影响很大),因为它将使该卷上的所有块都不可访问,而且HDFS必须处理由于删除而导致的所有replica不足的块。因此,磁盘检查器执行最基本的检查,使用非常保守的逻辑来考虑故障。
2. 在DataNode的启动过程中的磁盘健康检测,是为了保证节点本身数据可用性的一个重要指标,如果DataNode在磁盘检测中发现坏盘的个数超出了可容忍阈值的情况下,会直接让DataNode启动失败,并抛出异常。
hdfs-site.xml中dfs.datanode.failed.volumes.tolerated
When DiskChecker?
磁盘检查器只按需运行,而磁盘检查器线程是惰性创建的。具体地说,磁盘检查器只在常规I/O操作(例如关闭块或元数据文件、目录扫描器报告错误等)期间捕捉到DataNode上的IOException时才运行。磁盘检查器执行间隔:5s。
具体实现:
按顺序检查DataNode上的以下目录(finalizedDir: 递归遍历目录树,检查所有子目录):“finalized” 、 “tmp” 、 “rbw”
后续优化(社区方案):
// Throttle DiskChecker#checkDirs() speed.https://issues.apache.org/jira/browse/HDFS-8617// DiskChecker should perform some disk IOhttps://issues.apache.org/jira/browse/HADOOP-13738
DirectoryScanner:
DirectoryScanner:目录扫描服务,定期扫描磁盘上的数据块,检查磁盘上的数据块信息是否与FsDatasetImpl中保存的数据块信息一致,如果不一致则对FsDatasetImpl中的信息进行更新,执行流程如下图。
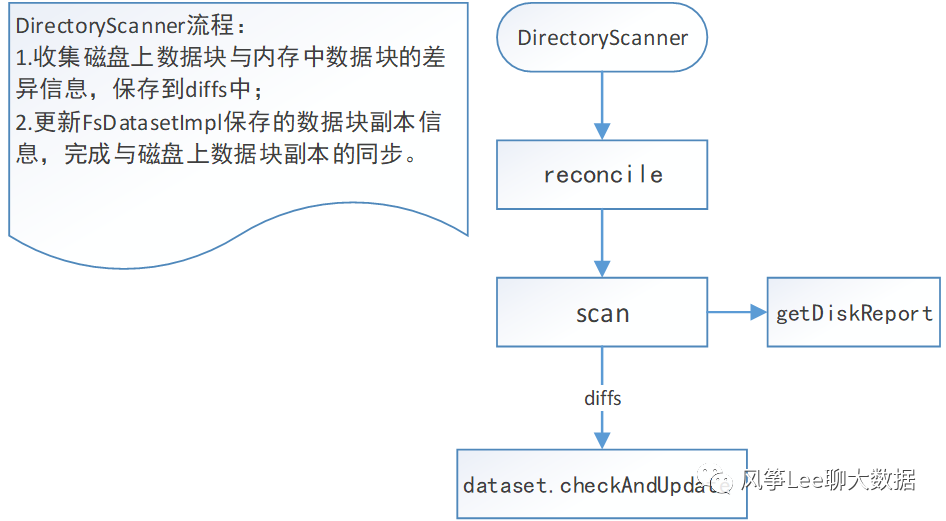
注意,DirectoryScanner只会检查内存和磁盘上的FINALIZED状态的数据块是否一致。
Scan only the "finalized blocks" lists of both disk and memory.
默认间隔21600s执行一次(配置项:dfs.datanode.directoryscan.interval:)。
后续优化:
Allow the directoryScanner to be rate-limitedhttps://issues.apache.org/jira/browse/HDFS-8873
BlockScanner:
磁盘或者是网络上的I/O操作可能会对正在读写的数据处理不慎而出现错误,HDFS提供了下面两种数据检验方式,以此来保证数据的完整性,而且这两种检验方式在DataNode节点上是同时工作的:
一.校验和 :检测损坏数据的常用方法是在进行一次操作时计算数据的校验和,在通道传输过程中,如果新生成的校验和不完全匹配原始的校验和,那么数据就会被认为是被损坏的。
二.数据块检测程序(BlockScanner)在DataNode节点上开启一个后台线程,来定期验证存储在它上所有块,这个是防止物理介质出现损减情况而造成的数据损坏。
数据块扫描器:
每个datanode都会初始化一个数据块扫描器周期性地验证Datanode上存储的所有数据块的正确性(数据块校验),并把发现的损坏数据块报告给Namenode. 执行流程如下图。
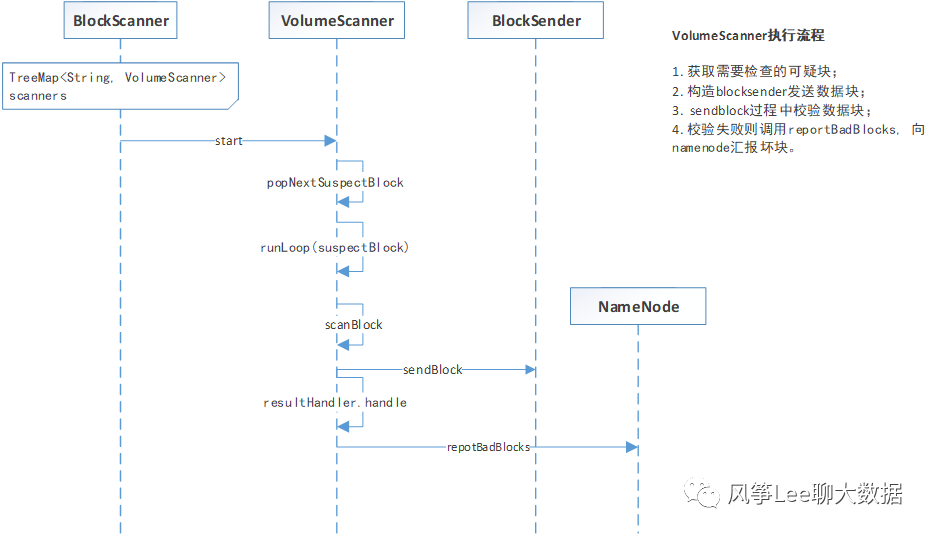
默认执行间隔21 * 24h扫描一次(配置项:dfs.datanode.scan.period.hours)。
生产环境:洛阳集群168h
可以通过查看datanodeIP :50075/blockScannerReport 查看datanode的DataBlockScanner的信息。
三. Datanode 异构存储
Hadoop在2.6.0版本中引入了一个新特性异构存储.
异构存储可以根据各个存储介质读写特性的不同发挥各自的优势.
一个很适用的场景就是上冷热数据的存储.针对冷数据,采用容量大的,读写性能不高的存储介质存储,比如最普通的Disk磁盘.而对于热数据而言,可以采用SSD的方式进行存储,这样就能保证高效的读性能,在速率上甚至能做到十倍于或百倍于普通磁盘读写的速度.换句话说,HDFS的异构存储特性的出现使得我们不需要搭建2套独立的集群来存放冷热2类数据,在一套集群内就能完成.
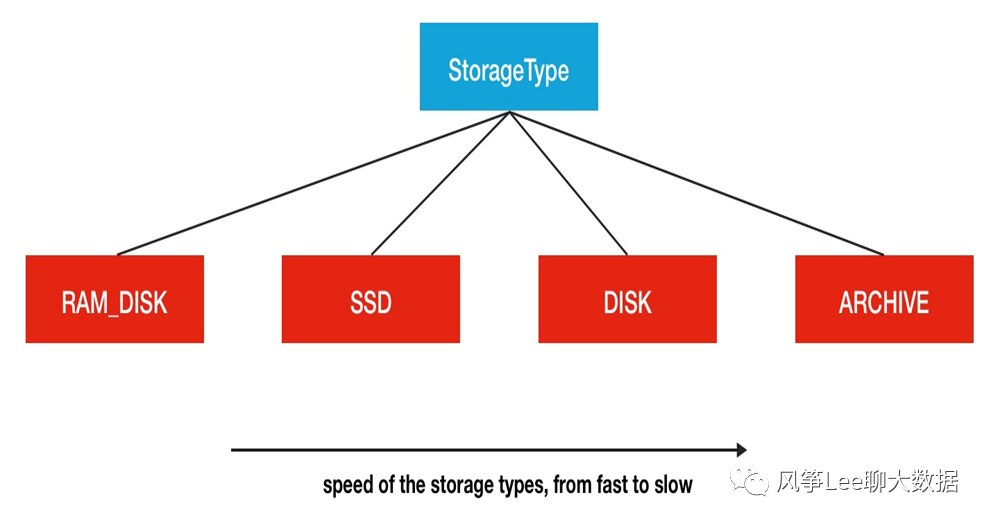
HDFS中存储介质分类(StoragType类中有相关定义)RAM_DISK(内存)SSD(固态硬盘)DISK(普通硬盘,在HDFS中,如果没有主动声明数据目录存储类型默认都是DISK)ARCHIVE(没有特指哪种存储介质,主要的指的是计算能力比较弱而存储密度比较高的存储介质,用来解决数据量的容量扩增的问题)
存储介质类型需要再配置中主动声明,HDFS可没有做自动检测识别的功能
例如 Hdfs-site.xml配置:[SSD]file:///grid/dn/ssd0
异构存储实现原理如下图:
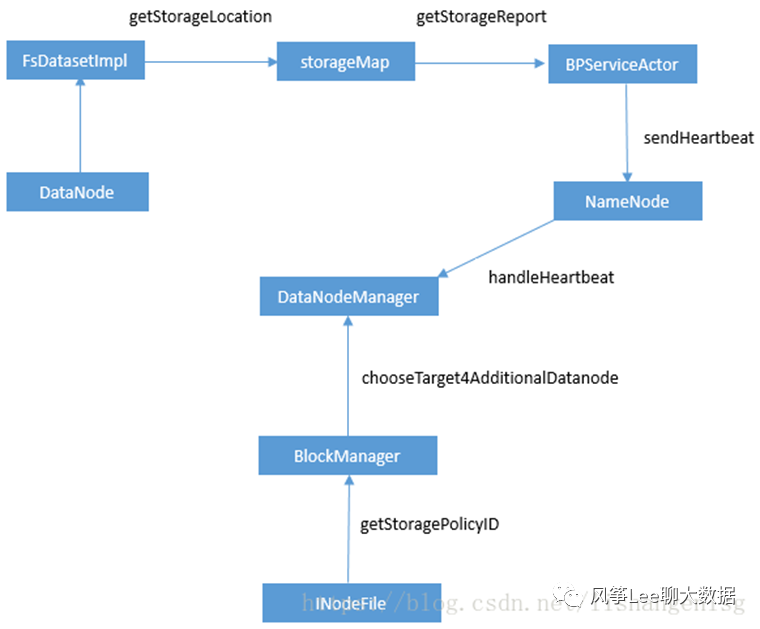
1.DataNode通过心跳汇报自身数据存储目录的StorageType给NameNode(数据存储目录的解析/心跳汇报过程)
2.随后NameNode进行汇总并更新集群内各个节点的存储类型情况
3.待存储文件根据自身设定的存储策略信息向NameNode请求拥有此类型存储介质的DataNode作为候选节点
存储策略种类
Lazy_persist:一个副本保存在内存RAM_DISK中,其余副本保存在磁盘中ALL_SSD:所有副本都保存在SSD中One_SSD:一个副本保存在SSD中,其余副本保存在磁盘中Hot:所有副本保存在磁盘中,这也是默认的存储策略Warm:一个副本保存在磁盘上,其余副本保存在归档存储上Cold:所有副本都保存在归档存储上
存储策略相关shell命令:
// 创建文件或目录时,其存储策略未指定,可以使用该命令指定存储策略。hdfs dfsadmin -setStoragePolicy// xx为指定路径(数据存储目录)设置指定的存储策略hdfs storagepolicies -setStoragePolicy -path xxx -policy x// xxx获取指定路径(数据存储目录或文件)的存储策略hdfs storagepolicies -getStoragePolicy -path// xxx取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是HOThdfs storagepolicies -unsetStoragePolicy -path
最简单的使用方法是事先划分好冷热数据存储目录,设置好对应的Storage Policy,然后后续相应的程序在对应分类目录下写数据,自动继承父目录的存储策略;
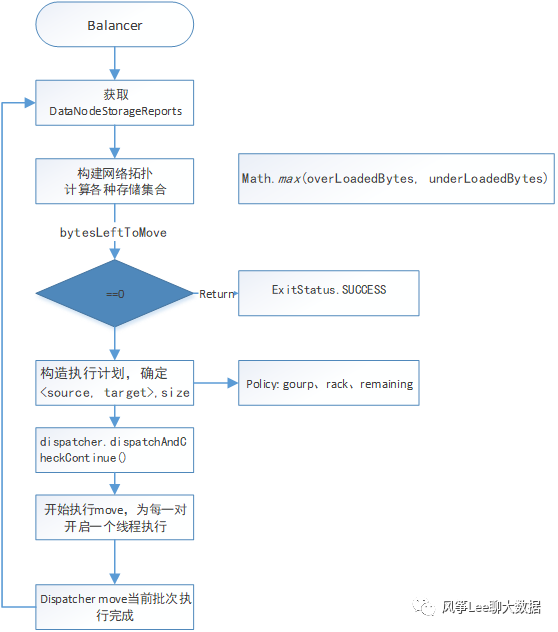
四. HDFS Balancer
hdfs集群经常会出现磁盘数据不均衡问题,如下图
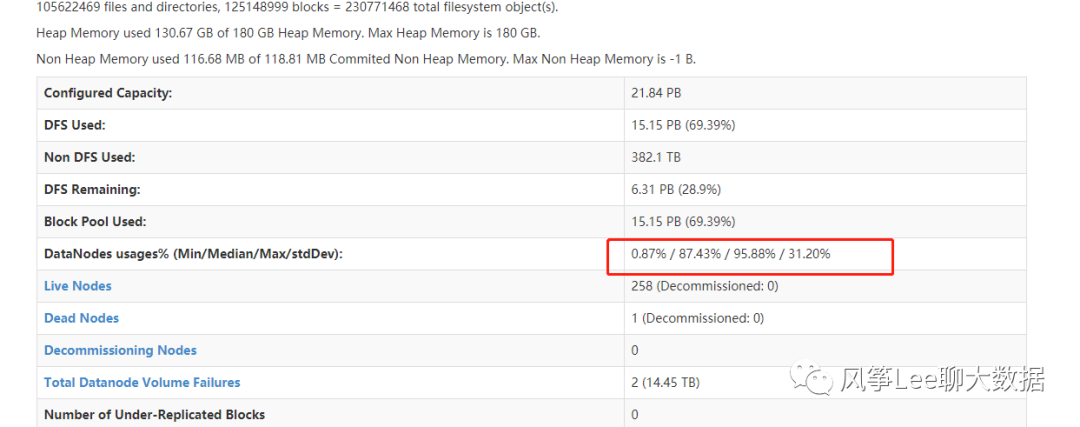
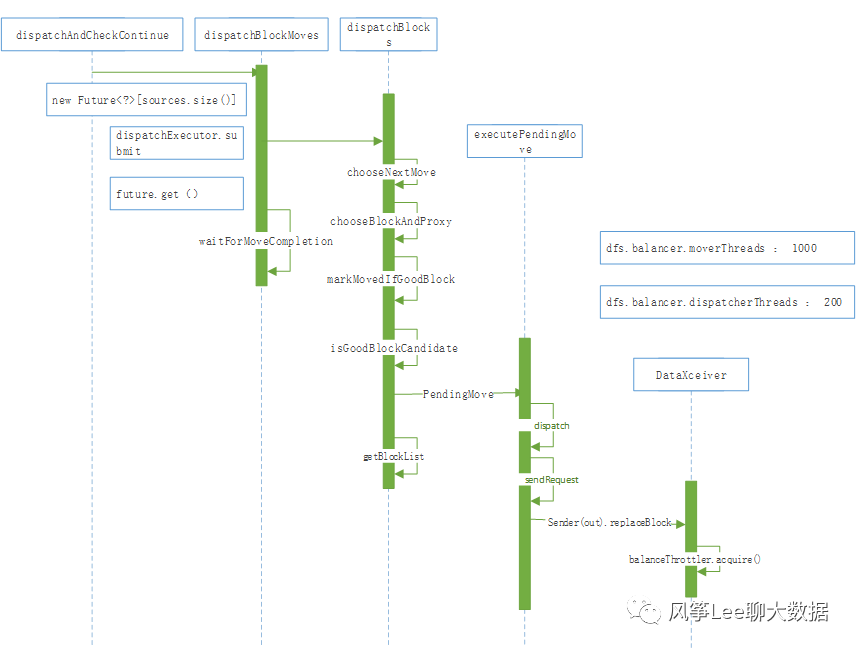
HDFS Balancer机制可以使各个datanode数据节点间进行数据balance,执行流程如下图: