介绍
Sqoop是一个用来将Hadoop和关系型数据库中的数据相互转移的工具,可以将一个关系型数据库(例如 :MySQL ,Oracle ,Postgres等)中的数据导入到Hadoop的HDFS或HBase中,也可以将HDFS的数据导入到关系型数据库中。
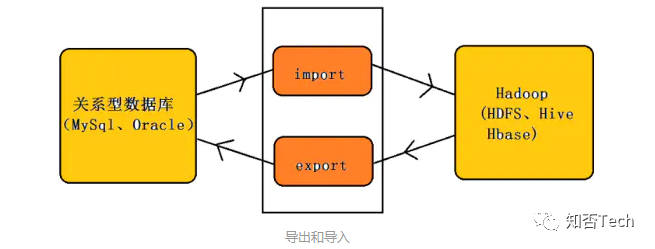
sqoop是连接关系型数据库和hadoop的桥梁,主要有两个方面(导入和导出):
A. 将关系型数据库的数据导入到Hadoop 及其相关的系统中,如 Hive和HBase
B. 将数据从Hadoop 系统里抽取并导出到关系型数据库
Sqoop的优点:
A. 可以高效、可控的利用资源,可以通过调整任务数来控制任务的并发度。
B. 可以自动的完成数据映射和转换。由于导入数据库是有类型的,它可以自动根据数据库中的类型转换到Hadoop 中,当然用户也可以自定义它们之间的映射关系
C.支持多种数据库,如mysql,orcale等数据库
4. sqoop工作的机制:
将导入或导出命令翻译成MapReduce程序来实现在翻译出的,MapReduce 中主要是对InputFormat和OutputFormat进行定制
5. sqoop版本介绍:sqoop1和sqoop2
A. sqoop的版本sqoop1和sqoop2是两个不同的版本,它们是完全不兼容的
B. 版本划分方式: apache1.4.X之后的版本是1,1.99.0之上的版本是2
C. Sqoop2相比sqoop1的优势有:
1) 它引入的sqoop Server,便于集中化的管理Connector或者其它的第三方插件;
2) 多种访问方式:CLI、Web UI、REST API;
3) 它引入了基于角色的安全机制,管理员可以在sqoop Server上配置不同的角色。
架构
sqoop1的架构图:
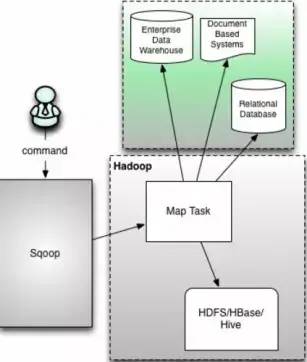
版本号:1.4.X以后的sqoop1
在架构上:sqoop1使用sqoop客户端直接提交代码方式
访问方式:CLI命令行控制台方式访问
安全性:命令或者脚本指定用户数据库名和密码
原理:Sqoop工具接收到客户端的shell命令或者Java api命令后,通过Sqoop中的任务翻译器(Task Translator)将命令转换为对应的MapReduce任务,而后将关系型数据库和Hadoop中的数据进行相互转移,进而完成数据的拷贝
sqoop2架构图:
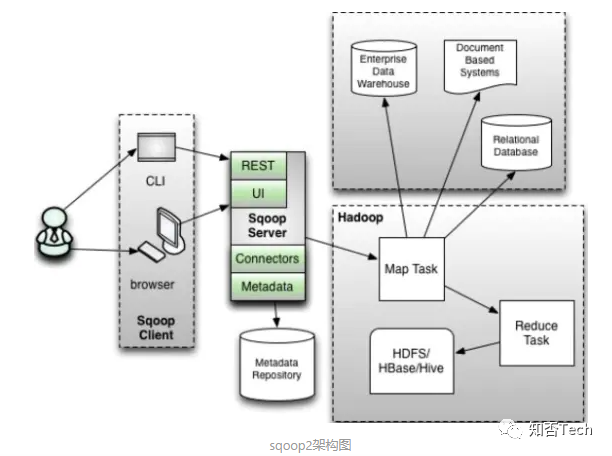
版本号:1.99.X以上的版本sqoop2
在架构上:sqoop2引入了 sqoop server,对对connector实现了集中的管理访问方式:REST API、 JAVA API、 WEB UI以及CLI控制台方式进行访问
CLI方式访问,会通过交互过程界面,输入的密码信息会被看到,同时Sqoop2引入基亍角色的安全机制,Sqoop2比Sqoop多了一个Server端。
Sqoop1和sqoop2优缺点:
sqoop1优点:架构部署简单
sqoop1缺点:命令行方式容易出错,格式紧耦合,无法支持所有数据类型,安全机制不够完善,例如密码暴漏,安装需要root权限,connector必须符合JDBC模型
sqoop2优点:多种交互方式,命令行,web UI,rest API,conncetor集中化管理,所有的链接安装在sqoop server上,完善权限管理机制,connector规范化,仅仅负责数据的读写
sqoop2缺点:sqoop2的缺点,架构稍复杂,配置部署更繁琐
以下针对CM管理的CDH sqoop,进行 RDBMS2HDFS/Hive/HBase & Hive2RDBMS案例实战;本次sqoop版本为sqoop-1.4.7+cdh6.3.2。
#使用sqoop校验RDBMS中的数据库列表情况
[root@dn58 mariadb-10.1.46-linux-systemd-x86_64]# sqoop list-databases --connect jdbc:mysql://10.172.54.58:3306/hive --username hive --password hive_2020Warning: opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.SLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]20/10/27 20:08:50 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7-cdh6.3.220/10/27 20:08:50 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.20/10/27 20:08:50 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.hiveinformation_schema
import
#创建mariadb的表并初始化数据
MariaDB [(none)]> create database company;Query OK, 1 row affected (0.00 sec)MariaDB [(none)]> create table company.staff(id int(4) primary key not null auto_increment,name varchar(255),sex varchar(255));Query OK, 0 rows affected (0.01 sec)MariaDB [(none)]> use company;Reading table information for completion of table and column namesYou can turn off this feature to get a quicker startup with -ADatabase changedMariaDB [company]> insert into company.staff(name,sex) values('guow','male');Query OK, 1 row affected (0.00 sec)MariaDB [company]> insert into company.staff(name,sex) values('wuwu','famale');Query OK, 1 row affected (0.00 sec)MariaDB [company]> select * from staff;+----+------+--------+| id | name | sex |+----+------+--------+| 1 | guow | male || 2 | wuwu | famale |+----+------+--------+2 rows in set (0.00 sec)
#使用hdfs用户导入数据
sudo -u hdfs sqoop import --connect jdbc:mysql://10.172.54.58:3306/company --username root --password Admin@2020 --table staff --target-dir user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t"
#此问题是由于sqoop用户与root用户的jdk版本不一致导致
#此问题是由于sqoop用户与root用户的jdk版本不一致导致[root@dn58 ~]# sudo -u hdfs sqoop import --connect jdbc:mysql://10.172.54.58:3306/company --username root --password Admin@2020 --table staff --target-dir user/company --delete-target-dir >Warning: opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/bin/../lib/sqoop/../accumulo does not exist! Accumulo imports will fail.Please set $ACCUMULO_HOME to the root of your Accumulo installation.SLF4J: Class path contains multiple SLF4J bindings.SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/slf4j-log4j12-1.7.25.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-6.3.2-1.cdh6.3.2.p0.1605554/jars/log4j-slf4j-impl-2.8.2.jar!/org/slf4j/impl/StaticLoggerBinder.class]SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]20/10/27 20:52:39 INFO sqoop.Sqoop: Running Sqoop version: 1.4.7-cdh6.3.220/10/27 20:52:39 WARN tool.BaseSqoopTool: Setting your password on the command-line is insecure. Consider using -P instead.20/10/27 20:52:39 INFO manager.MySQLManager: Preparing to use a MySQL streaming resultset.20/10/27 20:52:39 INFO tool.CodeGenTool: Beginning code generation20/10/27 20:52:39 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `staff` AS t LIMIT 120/10/27 20:52:39 INFO manager.SqlManager: Executing SQL statement: SELECT t.* FROM `staff` AS t LIMIT 120/10/27 20:52:39 INFO orm.CompilationManager: HADOOP_MAPRED_HOME is opt/cloudera/parcels/CDH/lib/hadoop-mapreduce20/10/27 20:52:39 ERROR orm.CompilationManager: It seems as though you are running sqoop with a JRE.20/10/27 20:52:39 ERROR orm.CompilationManager: Sqoop requires a JDK that can compile Java code.20/10/27 20:52:39 ERROR orm.CompilationManager: Please install a JDK and set $JAVA_HOME to use it.20/10/27 20:52:39 ERROR tool.ImportTool: Import failed: java.io.IOException: Could not start Java compiler.at org.apache.sqoop.orm.CompilationManager.compile(CompilationManager.java:196)at org.apache.sqoop.tool.CodeGenTool.generateORM(CodeGenTool.java:107)at org.apache.sqoop.tool.ImportTool.importTable(ImportTool.java:515)at org.apache.sqoop.tool.ImportTool.run(ImportTool.java:633)at org.apache.sqoop.Sqoop.run(Sqoop.java:146)at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:76)at org.apache.sqoop.Sqoop.runSqoop(Sqoop.java:182)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:233)at org.apache.sqoop.Sqoop.runTool(Sqoop.java:242)at org.apache.sqoop.Sqoop.main(Sqoop.java:251)

#此处使用解决方案是增大/user目录权限的方法跳过root用户无访问权限的问题(应统一各用户的jdk环境版本)
#全部导入
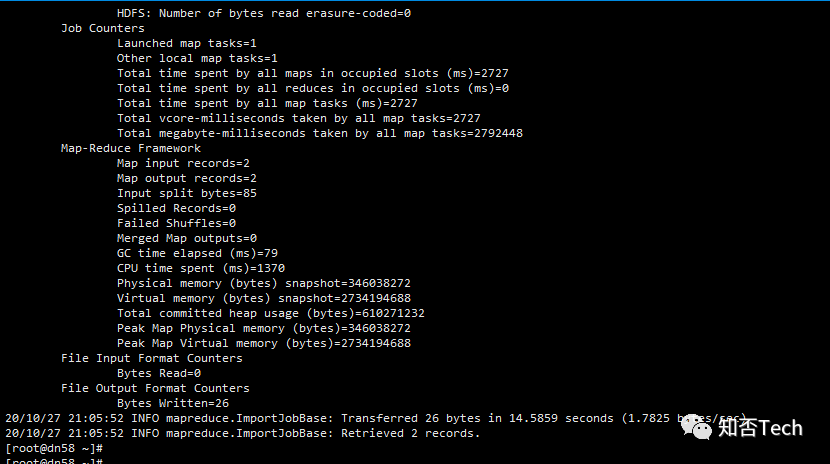
[root@dn58 ~]# sqoop import --connect jdbc:mysql://10.172.54.58:3306/company --username root --password Admin@2020 --table staff --target-dir user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t"
[root@dn58 ~]# sudo -u hdfs hadoop fs -cat /user/company/part-m-000001 guow male2 wuwu famale
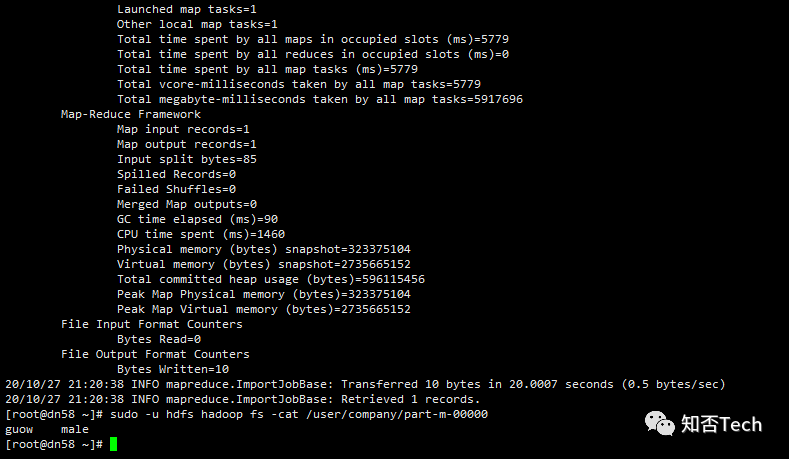
#查询导入,其中$CONDITIONS保证写入顺序
sqoop import --connect jdbc:mysql://10.172.54.58:3306/company --username root --password Admin@2020 --target-dir user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t" --query 'select name,sex from staff where id<=1 and $CONDITIONS;'
#注意:如果使用sql语句为双引号,需要加转义\
sqoop import --connect jdbc:mysql://10.172.54.58:3306/company --username root --password Admin@2020 --target-dir user/company --delete-target-dir --num-mappers 1 --fields-terminated-by "\t" --query "select name,sex from staff where id<=1 and \$CONDITIONS;"
#按列导入
sqoop import \--connect jdbc:mysql://10.172.54.58:3306/company \--username root \--password Admin@2020 \--table staff \--target-dir user/company \--delete-target-dir \--num-mappers 1 \--columns id,sex \--fields-terminated-by "\t"

#按列查询导入
sqoop import \--connect jdbc:mysql://10.172.54.58:3306/company \--username root \--password Admin@2020 \--table staff \--target-dir user/company \--delete-target-dir \--num-mappers 1 \--columns id,sex \--where "id = 1"--fields-terminated-by "\t"

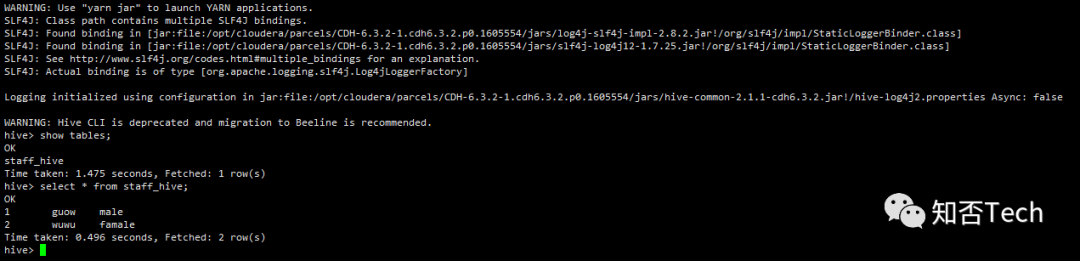
sqoop导入hive
#其实分两步,1、导入hdfs,2、load hivesqoop import \--connect jdbc:mysql://10.172.54.58:3306/company \--username root \--password Admin@2020 \--table staff \--num-mappers 1 \--hive-import \--fields-terminated-by "\t" \--hive-overwrite \--hive-table staff_hive
校验hive是否导入
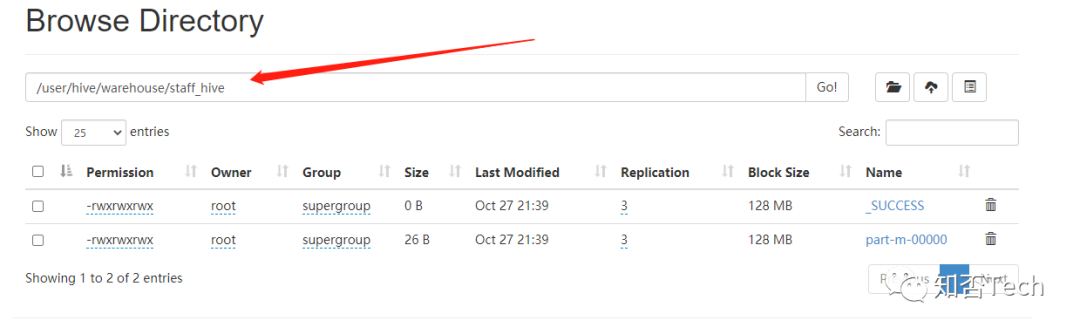
sqoop导入hbase
sqoop import \--connect jdbc:mysql://10.172.54.58:3306/company \--username root \--password Admin@2020 \--table staff \--columns "id,name,sex" \--column-family "info" \--hbase-create-table \--hbase-row-key "id" \--hbase-table "hbase_staff" \--num-mappers 1 \--split-by id
验证
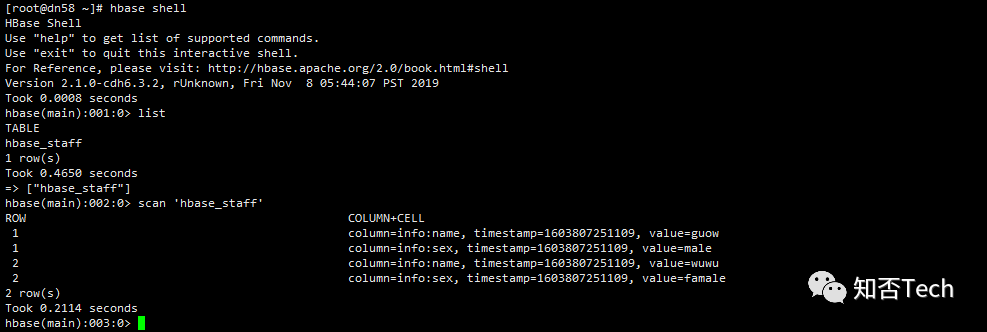
export
hive/hdfs导出到rdms
#此处记得清空表
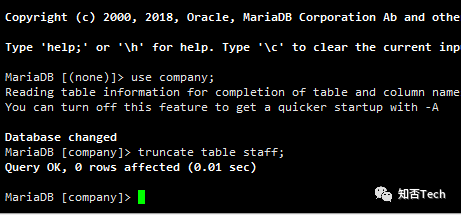
sqoop export \--connect jdbc:mysql://10.172.54.58:3306/company \--username root \--password Admin@2020 \--table staff \--num-mappers 1 \--export-dir user/hive/warehouse/staff_hive \--input-fields-terminated-by "\t"
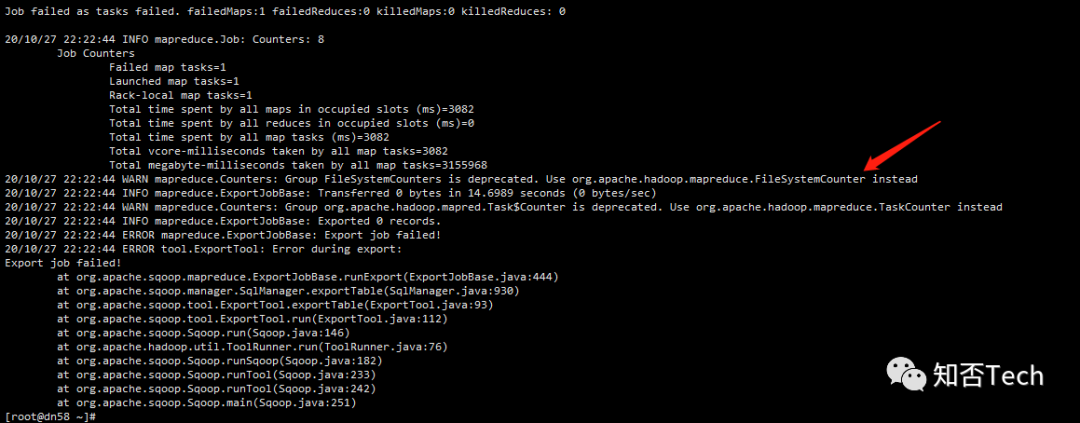
查看yarn任务日志,发现把整行数据当做一个数据转换给数字类型报错。
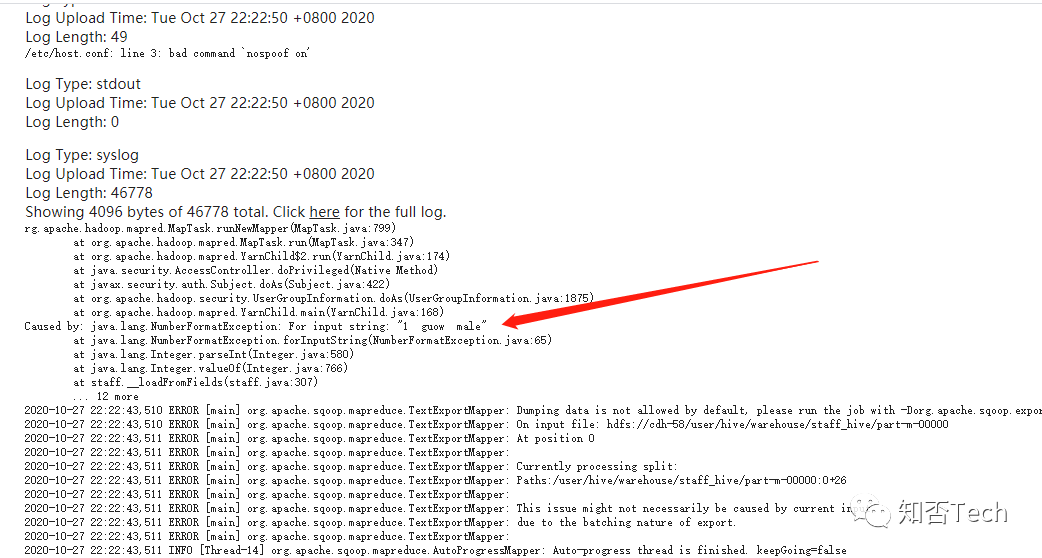
#原因是之前sql导入hive时指定分隔符有问题导致,重新mysql导入hive表,再清空mysql表后,hive导出到mysql,问题解决;
脚本执行sqoop任务
以hdfs导出到 RDBMS(mariadb)为例
[root@dn58 sqoop]# mkdir opt[root@dn58 sqoop]# vim opt/hdfs2mariadb.optexport--connectjdbc:mysql://10.172.54.58:3306/company--usernameroot--passwordAdmin@2020--tablestaff--num-mappers1--export-dir/user/hive/warehouse/staff_hive--input-fields-terminated-by"\t"
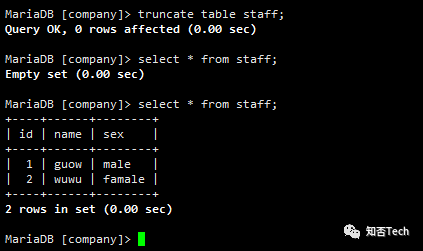
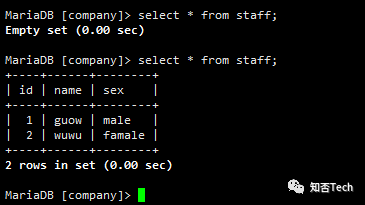
执行脚本(提前清空mariadb staff表),脚本执行可以添加至crond或oozie调度;
#执行脚本命令[root@dn58 sqoop]# sqoop --options-file opt/hdfs2mariadb.opt#校验mariadb导入情况MariaDB [company]> truncate table staff;Query OK, 0 rows affected (0.00 sec)MariaDB [company]> select * from staff;Empty set (0.00 sec)MariaDB [company]> select * from staff;+----+------+--------+| id | name | sex |+----+------+--------+| 1 | guow | male || 2 | wuwu | famale |+----+------+--------+2 rows in set (0.00 sec)