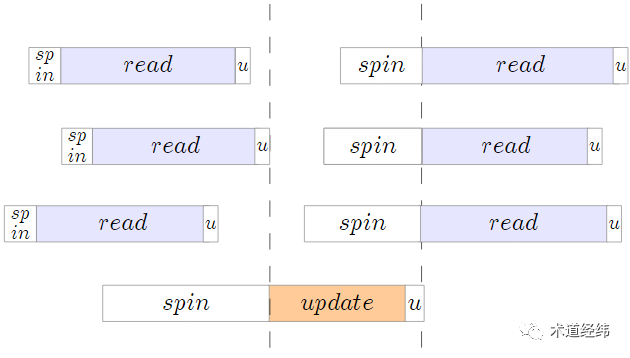
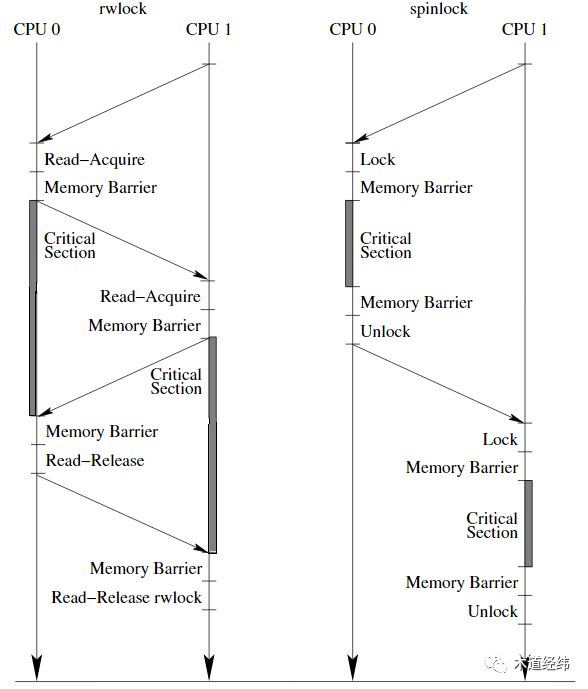
rwlock和seqlock都是基于前面介绍的spinlock衍生出来的,它们在Linux内核中的使用频率比不上spinlock,但是理解rwlock和seqlock,是进一步理解下文将要介绍的RCU机制的关键。rwlock的全称是"reader-writer spin lock",和普通的spinlock不同,它对"read"和"write"的操作进行了区分。如果当前没有writer,那么多个reader可以同时获取这个rwlock。如果当前没有任何的reader,那么一个writer可以获取这个rwlock。rwlock限定了reader与writer之间,以及writer与writer之间的互斥,但它没有限定reader与reader之间的互斥。比如多个CPU对某一链表的操作大部分时候都是遍历和查找,而不需要添加、删除或者移动时,就可以使用rwlock。对于reader,依靠read_lock()和read_unlock()来限定读取一侧的临界区。read_lock(); // --> queued_read_lock()read_unlock(); // --> queued_read_unlock()
每当一个reader进入临界区,就需要将读取一侧的reference count加1,退出则减1。只有当这个reference count的值为0,writer才可以执行自己的临界区代码。#define _QR_BIAS (1U << 9)
void queued_read_lock_slowpath(struct qrwlock *lock){
...
atomic_add(_QR_BIAS, &lock->cnts);
...
对于writer,依靠write_lock()和write_unlock()来限定写入一侧的临界区。write_lock(); // --> queued_write_lock()write_unlock(); // --> queued_write_unlock()
不同reader的临界区可以并行,但一个writer的临界区不能和其他的writer/reader的临界区并行。看起来rwlock比原生的spinlock控制更加精细,应用起来应该更加高效对不对?但rwlock存在一个问题,如果现在有多个reader在使用某个rwlock,那么writer需要等到所有的reader都释放了这个rwlock,才可以获取到,这容易造成writer执行的延迟,俗称饥饿(starve)。而且,在writer等待期间,reader还可以不断地加入进来执行,这对writer来说实在是太不公平了。即便writer的优先级更高,也不能先于优先级更低的reader执行,身份(是reader还是writer)决定一切。现在的内核开发已经不建议再使用rwlock了,之前的Linux代码中使用到的rwlock也在逐渐被移除,或者替换为普通的spinlock或者RCU。seqlock是由Stephen Hemminger负责开发,自Linux 2.6版本引入的,其全称是"sequential lock"。相比起rwlock,它进一步解除了reader与writer之间的互斥,只保留了writer与writer之间的互斥。只要没有其他的writer持有这个seqlock(即便当前存在reader持有该seqlock),那么第一个试图获取该seqlock的writer就可以成功地持有。那如果在reader读取共享变量期间,writer对变量进行了修改,岂不是会造成读取数据的不一致?先来看下seqlock的结构体定义(代码位于/include/linux/seqlock.h):typedef struct {
struct seqcount seqcount;
spinlock_t lock;
可见,就是在普通spinlock的基础上加了一个"seqcount",而seqlock正是依靠这个名为"seqcount"的sequence number,来保证了数据的一致性。每当有writter持有seqlock之后,sequence number的值就会加1:static inline void write_seqlock(seqlock_t *sl){
spin_lock(&sl->lock);
s->sequence++;
当writer释放seqlock之前,sequence number的值会再次加1:static inline void write_sequnlock(seqlock_t *sl){
s->sequence++;
spin_unlock(&sl->lock);
sequence number的初始值是一个偶数(even),因而当writer持有spinlock时,sequence number的值将是一个奇数(odd),释放后则又变成偶数。reader在读取一个共享变量之前,需要先读取一下sequence number的值,如果为奇数,说明现在有writer正在修改这个变量,需要等待,直到sequence number变为偶数,才可以开始读取变量。static inline unsigned __read_seqcount_begin(const seqcount_t *s){
unsigned ret;
repeat:
ret = READ_ONCE(s->sequence);
if (unlikely(ret & 1)) {
cpu_relax();
goto repeat;
}
return ret;
读取变量之后,reader需要再次读取一下sequence number的值,并和读取之前的sequence number的值进行比较,看是否相等,相等则说明在此期间没有writer的操作。static inline int __read_seqcount_retry(const seqcount_t *s, unsigned start){
return unlikely(s->sequence != start);
理论上,reader可以随时读(相当于在读取一侧没有加锁)。在这一过程中,writer不会受到什么影响,但reader可能就需要多读几次。一个writer只会被其他writer造成starve,而不再会被reader造成starve。显然,其设计策略是倾向于writer的。它适用于reader数量较多,而writer数量较少的场景。其在Linux中的一个重要应用就是表示时间的jiffies(jiffies记录了系统启动后的时钟节拍的数目)。do {
seq = read_seqbegin(&jiffies_lock);
ret = jiffies_64;} while (read_seqretry(&jiffies_lock, seq));
从spinlock的“一读或一写”,到rwlock的“多读或一写”,再到seqlock的“多读和一写”,下一步是不是就可以实现“多读和多写”了?详情请看下文分解。