【A-A死锁】
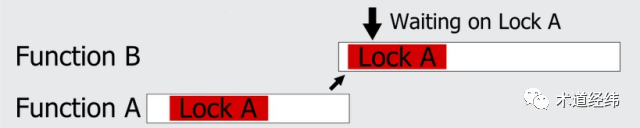
Linux内核在设计上是不允许同一个锁(spinlock/mutex)的递归使用的(并非所有的操作系统都如此),如果一个线程在持有同一个spinlock后,又再次试图获取这个spinlock,那么将导致死锁的发生。
可能你会觉得,在一段代码中连续调用两次使用同一参数的spin_lock()还是比较容易发现的,可如果是子函数调用呢?
比如一个线程在执行函数A的时候获得了一个spinlock,释放之前又进入了子函数B,而子函数B也试图获取这个spinlock,那么同样会导致死锁。尤其当函数调用层次比较多的时候,就更难追踪了。
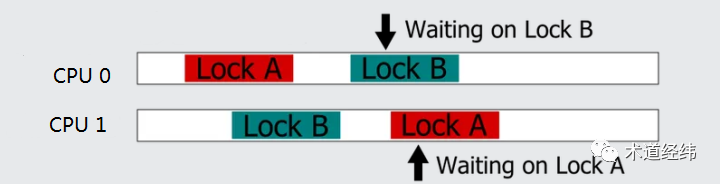
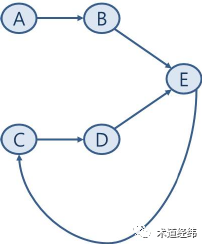
此外,如果使用了回调(callback)函数,也是一种非常隐蔽的场景。这些死锁同上文介绍的hardirq/softirq与线程共享变量造成的死锁一样,都是同一个线程/CPU试图重复获取同一个spinlock引起的,属于「A-A死锁」(也叫recursive deadlock)。与之相对的,就是接下来要介绍的,两个不同的CPU针对两个不同的spinlock的获取引起的「AB-BA死锁」(也叫inversion deadlock)。在一个CPU上的线程成功获取一个spinlock(设为lock A)后,另一个CPU上的线程也成功获取了另一个spinlock(设为lock B)。接下来,CPU 0试图获取lock B,显然将获取不到,进入busy wait,等待CPU 1释放lock B。好巧不巧,此时CPU 1又试图获取lock A,自然也是获取不到,进入busy wait,等待CPU 0释放lock A。此刻,两个CPU狭路相逢了,都盯着对方手里的那个spinlock,希望据为己有,狭路相逢勇者胜,然而它们谁也不能把对方干掉,也不会主动地把自己占有的spinlock让给对方。这种暂时让出spinlock的策略才是以退为进,利己利人的正确之道,那为什么它们不这么做呢,仅仅是因为目光短浅么?别忘了它们现在正在spin啊,spin的时候脑子里只有一根筋,就是获取目标的spinlock,为此心无旁骛(关闭调度,甚至关闭中断),哪还有机会去做释放锁的操作。然后,两个CPU就只能一直这样等下去,等下去……然后就死锁了,这种死锁被形象地称之为deadly brace(抱死在一块儿)。举个Linux中实际的例子,比如一个hash表,其中的每个entry由一个链表和一个串行化链表操作的spinlock组成。当CPU 0试图将其中一个链表(A)的某个元素移动到另一个链表(B)上时,它需要同时持有链表A和链表B的spinlock,才可以将元素从链表A上取出,放到链表B上。假设现在CPU 1正好做相反方向的操作,即将元素从链表B移动到链表A,那么就会出现上述的情况。应该说,出现这种特殊场景的概率是很低的,也许只有百万分之一,但计算机的高速运行,可能让一个代码路径用不了多久就会执行上百万次。内核提供了"CONFIG_DEBUG_SPINLOCK"的配置选项,使能后,spinlock结构体的定义会增加三个部分:代表持有spinlock的线程的"owner",持有spinlock的CPU的"owner_cpu"和区分spinlock和其他锁的"magic"(代码位于/include/linux/spinlock_types.h)。typedef struct raw_spinlock {
arch_spinlock_t raw_lock;#ifdef CONFIG_DEBUG_SPINLOCK
unsigned int magic, owner_cpu;
void *owner;
"owner"和"owner_cpu"的初始值都为-1。当获取spinlock时,前后都增加了一些debug信息。void do_raw_spin_lock(raw_spinlock_t *lock){
debug_spin_lock_before(lock);
arch_spin_lock(&lock->raw_lock);
debug_spin_lock_after(lock);
获取之前主要是检验该spinlock是否已经被当前线程或者当前CPU持有,如果是则会报错。static inline void debug_spin_lock_before(raw_spinlock_t *lock){
SPIN_BUG_ON(lock->magic != SPINLOCK_MAGIC, lock, "bad magic");
SPIN_BUG_ON(lock->owner == current, lock, "recursion");
SPIN_BUG_ON(lock->owner_cpu == raw_smp_processor_id(), lock, "cpu recursion");
获取之后则是将"owner"和"owner_cpu"分别设置为当前持有spinlock的线程和CPU。static inline void debug_spin_lock_after(raw_spinlock_t *lock){
lock->owner_cpu = raw_smp_processor_id();
lock->owner = current;
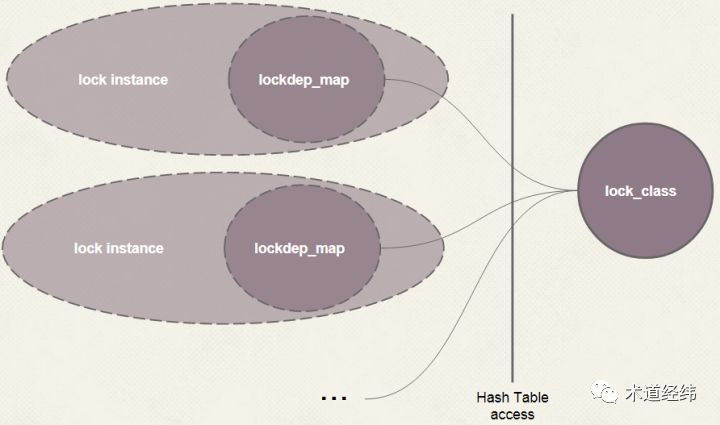
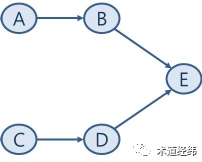
spinlock是一个高频操作,这样无疑会大大增加每次lock和unlock的开销,因而只适合debug的时候使用。前面介绍spinlock实现的文章讲过,为了提高spinlock的执行效率,内核开发者做了极致的优化,这也是Linux内核不支持spinlock的嵌套使用的原因,因为如果支持,那么每次加锁的时候,都需要进行owner的判断,效率就会受到影响。为了防止AB-BA死锁的出现,就需要解决不同spinlock之间的依赖问题。而一个系统中spinlock的数目繁多,根据分而治之的原则,Linux内核将spinlock分成了若干个lock class,比如在代表文件的inode结构体中的spinlock就属于同一class,其中的每个spinlock是这个class的一个实例。在系统运行过程中,内核会追踪每个lock class的使用状态,和各个lock class之间的依赖关系,并在出现异常时报错。「使用状态」包括一个lock是如何被使用的,以及所处的context,而这里「依赖关系」可简单地理解为是加锁的顺序,比如"L1 -> L2"就表示一个线程在持有L1的时候试图获取L2。这样的一套检测机制被称为"lockdep"。lock class之间的依赖可用如下的图表来表示,其中每个节点代表一个具体的lock class,箭头代表依赖关系。每当lockdep检测到有新的依赖关系产生时,它就会在图表中添加对应的箭头指向,比如这里的"E -> C"。可以看到,这里C, D和E形成了循环依赖,这就是deadlock可能发生的场景。