




接没有写完的上文。
SMMU支持stage 1的GVA->GPA(按ARM的叫法则是VA->IPA)的转换,也支持stage 2的GPA->HPA(IPA->PA)的转换,你可以选择只进行stage 1的转换,不进行stage 2的转换,也可以绕过stage 1的转换,只用stage 2的转换,还可以stage 1和stage 2的转换都用。stage 1和stage 2的转换都不用……那就没SMMU什么事了。
就像你可以选择周六来加班,或者周天来加班,或者周六周天都来加班。周六周天都不来加班……一点问题也没有,反正只要来加班既有double的工资(这个不太恰当的类比源自我过去一段真实的工作经历,那么自由的时间安排和报酬的合理支付,以至于让我有次细数以前的加班经历时,竟然把这一段漏掉了,让你加了班还让你感觉到好像没有加过,这恐怕是加班的最高境界了吧)。
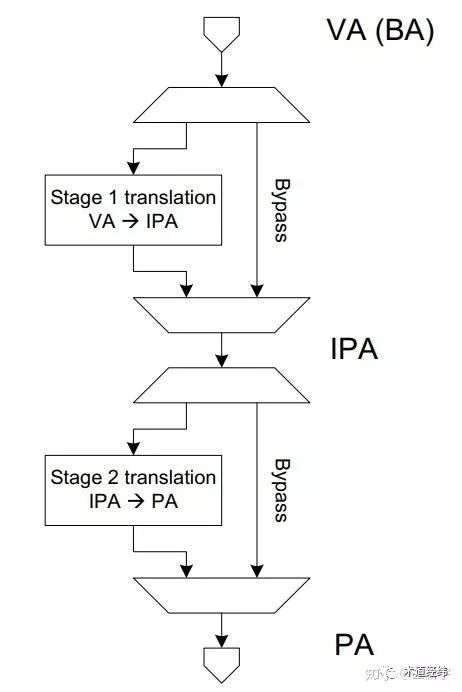
linux内核中关于SMMU的实现形式,也就是上面提到的这四种情况:
enum arm_smmu_domain_stage {
ARM_SMMU_DOMAIN_S1 = 0,
ARM_SMMU_DOMAIN_S2,
ARM_SMMU_DOMAIN_NESTED,
ARM_SMMU_DOMAIN_BYPASS,
}
x86的IOMMU
再来看看友商的IOMMU技术。其实原理都是差不多的,只是构造和名称上有些许差别。相对于SMMU,Intel早期的IOMMU跟PCI(e)的联系更加紧密。它是用PCI(e)中的BDF号(Bus/Device/Function,也叫Requester ID)来标识设备。
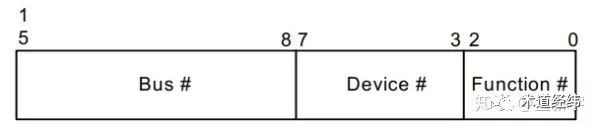
BDF号被分为了两个部分,第一部分Bus占8个bits,作为Root Table的索引;第二部分Device和Function分别各占5个bits和3个bis,作为Context Table的索引。这里Root Table和Context Table分别类似于SMMU中Stream table的第一级和第二级,而BFD的作用就等同于SMMU中的StreamID。
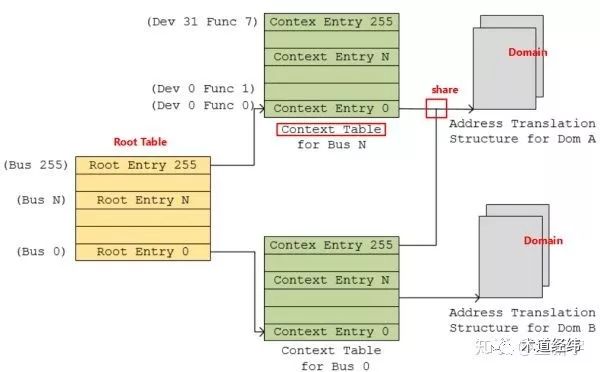
I/O页表
前面的文章还留了一个问题:为什么IOMMU要使用专门的I/O页表?以AMD的IOMMU为例,它和内置在一个CPU内的MMU(以下称作CPU MMU,ARM的CoreLink MMU,还有前面介绍的EPT/NPT,都属于CPU MMU)是存在一些区别的:
64位的x86_64系列的CPU MMU只支持4KB, 2MB和1GB的页大小(参考这篇文章),而AMD的IOMMU除了支持这些默认的页大小,还支持8KB, 16KB, 1MB, 4MB, 4GB的页大小。
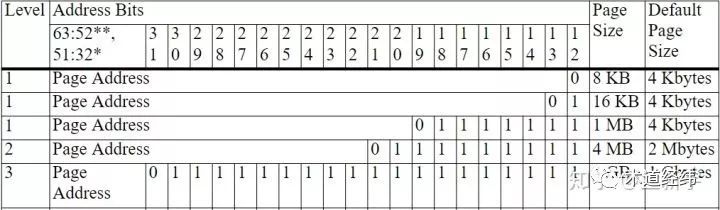
CPU MMU需要按照页表结构一级一级的遍历,而当虚拟地址包含一长串的0的时候,AMD的IOMMU在查找时可以跳过其中的一级页表。
正因为有了IOMMU设计上的这些差异,使用专门的I/O页表可以获得更快的查找速度。如果非要用普通的页表也不是不可以,但需要舍弃IOMMU的一些特性,以适配普通页表的查找规则。然而,ARM的SMMU的设计就不是这样的,它使用普通的页表依然可以工作的很好,不需要专门的I/O页表。
参考:
《Intel Virtualization Technology for Directed I/O Architecture Specification, Rev. 3.1》
《AMD I/O Virtualization Technology (IOMMU) Specification, Rev. 3.0.0》
