




同这篇文章介绍的page write back一样,内存回收操作可被强制触发或定时触发,具体可分为以下几种情况:
调用alloc_pages()分配内存时发现空闲内存不够。
进入休眠(hibernation)之前,需要把内存里的运行数据保存到磁盘上(suspend to disk),以便之后恢复。
周期性的回收,这主要是由内核线程kswapd完成的。
前两种情况都属于direct reclaim,调用的是try_to_free_pages。由于direct reclaim是在内存分配时进行的,如果这时才发现空闲内存不够,再去进行回收操作,无论是anonymous page的swap out,还是dirty page cache的write back,都要进行慢速的磁盘I/O操作,甚至可能阻塞,这无疑会增加内存分配的同步等待时间,影响系统性能。在某些场景下(比如在interrupt context或持有spinlock时),内存分配根本就是不能等待的。
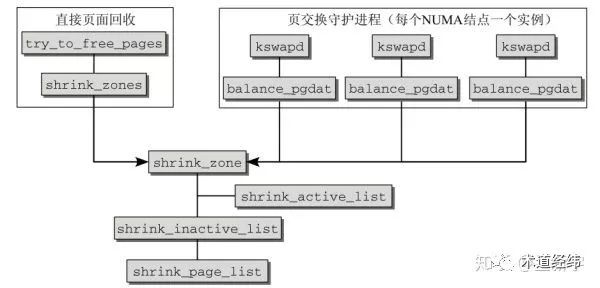
所以,direct reclaim的触发是应该被尽力避免的,为此,我们需要一个和周期性地page write back类似的机制,可以异步地定期回收内存(这里的异步是指同内存分配的操作异步)。在NUMA系统中,每个node(对应数据结构pglist_data,参考这篇文章)会有一个kswapd,负责周期性的扫描内存并回收(background reclaim)。kswapd虽然名字中含有"swap",但它不光处理anonymous page的swap out回收,同样处理page cache的回收,而且它还肩负着平衡active list和inactive list的重任,所以被它调用的函数叫做balance_pgdat。balance_pgdat()会根据node中各个zones的watermark判断是否需要回收,这将在以后的文章后详细介绍。如果需要回收,那么kswpad将调用shrink_node(以前是shrink_zone)--> shrink_list 启动回收操作。
static unsigned long shrink_list(enum lru_list lru, unsigned long nr_to_scan,
struct lruvec *lruvec, struct scan_control *sc)
{
if (is_active_lru(lru)) {
if (inactive_list_is_low(lruvec, is_file_lru(lru), sc, true))
shrink_active_list(nr_to_scan, lruvec, sc, lru);
return 0;
}
return shrink_inactive_list(nr_to_scan, lruvec, sc, lru);
}
当inactive list中的页面比较少时,shrink_active_list()会从active list尾端转移一部分页面到active list中。这里的“少”是相对的,通常物理内存越大,inactive list的页面占比可以越小(页面总数还是增加的),因为inactive list的长度是用来减少短时间内refault的(参考上篇文章)。
shrink_inactive_list --> shrink_page_list 将从inactive list尾端移除选定数目的页面,进行释放。
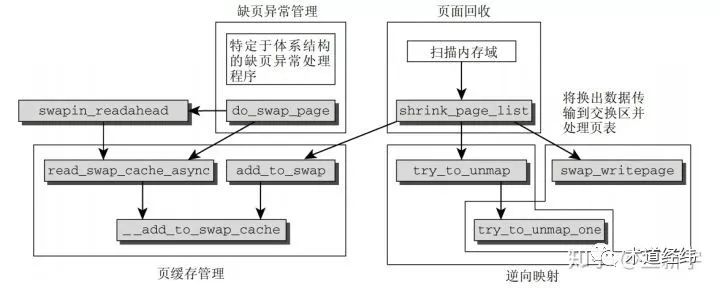
回收一个页面之前,如果该页面当前是被映射的(根据struct page的_mapcount域判断),需要调用try_to_unmap(),通过reserve mapping更改所有指向这个页面的PTEs。对于anonymous page,还需要在swap space中分配slot,并且将这个page标记为dirty的。anonymous page是没有backing store的,从dirty的角度,它可以算是一直dirty的。前面提到过,不是所有的页面都可以回收的,如果检测到页面的flag是PG_locked或者是PG_reserved的,则只能跳过。对于正在回写的(flag是PG_writeback的),通常也是放弃回收,有这功夫去等待回写完成,还不如去找链表上其他的clean page。
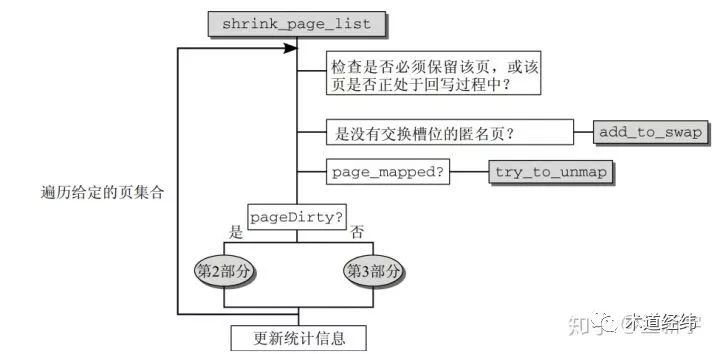
之后,对于flag是PG_dirty的页面,启动pageout()将这些页面备份(对于anonymous page)或者同步(对于page cache)到外部磁盘。
免死金牌
内存回收算法是根据过去的情况预测未来,而且作为工程应用,融入了很多经验的元素,有可能存在一个进程的页面不断被回收,而这个进程因为需要继续运行又不断申请内存页面的情况,这将会使大部分的时间耗费在访问磁盘上,而进程无法实质性地运行下去。这种情况虽然少见,但还是有一定发生的几率,为了保证执行完成,进程可以用申请swap token,拥有了swap token,就可以被内存回收算法暂时豁免(相当于免死金牌),除非,内存实在已经紧张的不行了。
swap token机制是从linux内核2.6.9版本引入的,整个系统只有一个,用swap_token_mm表示,swap_token_mm指向当前持有swap token的进程的mm_struct。为了保证公平性,每个进程持有swap token的时间是有限的,持有时间由一个定时器控制,定时器timeout后,swap token就会转移给下一个进程。之后2.6.20版本引入了更合理的swap token抢占机制,如果一个进程在一段时间内换入的页面较多,说明它可能受到页面换出的影响较大,则这样的进程可以获得在swap token抢占中更高的优先级。随着linux虚拟内存模型的不断演进,swap token机制并不能很好的和cgoups以及NUMA placement融合,因而在3.4版本中被移除了,详情请参考这个patch。
壮士断腕
尽管kswapd是很努力的,但它毕竟是周期性进行的,难免出现某个时刻系统中剩余的内存极少,少到可能连回收内存操作本身需要的内存都不够了,这时候只能使出终极武器了,那就是OOM killer,做法是选择一个进程(out_of_memory --> select_bad_process),然后kill掉(oom_kill_process中发送SIGKILL信号),把它占用的内存释放出来,牺牲了这个进程,保全了整个系统。虽然OOM killer有时候可能导致严重的损失,但总比系统完全崩溃要好。这个无辜的bad process(其实应该是victim啦)可不是随便挑的,应该优先选择这些:
占有page frames比较多的,占有的多释放的才多,kill掉才有意义。
静态优先级比较低的。
而不能选择这些:
内核线程,因为内核线程往往执行的都是比较关键的任务。
进程号为1的init进程。如果父进程退出,而它的一个或多个子进程还在运行,那么这些子进程将被init进程托管,如果init进程都挂了,那就……所以kill掉init进程是内核不允许的行为。
直接访问硬件设备的进程,如果强行终结这样的进程,可能将硬件置于一个不确定的状态。
