




高速缓存(cache)中有2个重要的概念,一个是index,一个是tag。
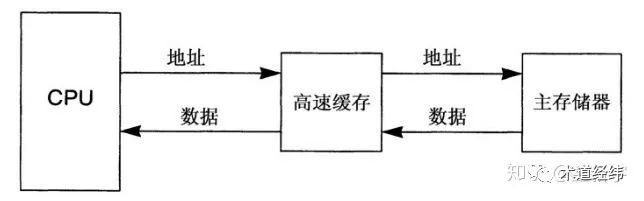
因为cache中的内容只是主存储器中内容的一个子集,所以需要有几种方式来确定存储器的哪些部分当前驻留在cache中,我们称存储器的那些部分被“缓存”了。这一点是通过将cache中的数据用它们对应的主存储器地址进行标记(tagging)来做到的。当CPU请求一个它想要获取的主存储器地址时,这个地址就被发送给cache,然后硬件就开始搜索cache来寻找相应的数据。
为了搜索一个cache,来自 CPU 的地址经hash处理生成一个索引(index),这个index指向cache中的一个或者多个位置【1】。和许多hash算法一样,不同的地址可能产生相同的索引值,于是必须用这些位置上的tag和CPU所提供的地址进行比较。如果这个tag与来自CPU的地址相吻合,那么就称为一次cache hit,否则为cache miss。
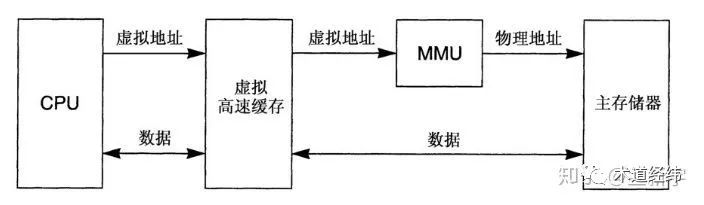
以被缓存的数据的虚拟地址来做index和tag的被称为虚拟高速缓存(即VIVT - Virtually Indexed, Virtually Tagged),其主要优点是,CPU不需要在每次读取或者写入操作的时候把虚拟地址转换为物理地址就能够存取cache,只有在发生cache miss或者需要和主存储器上的数据同步时,才需要MMU的参与。但是,这在多进程的运行环境下会带来问题,因为不同的进程可以使用相同的虚拟地址,被一个进程缓存的数据可能被错误地当作属于另一个进程的数据。
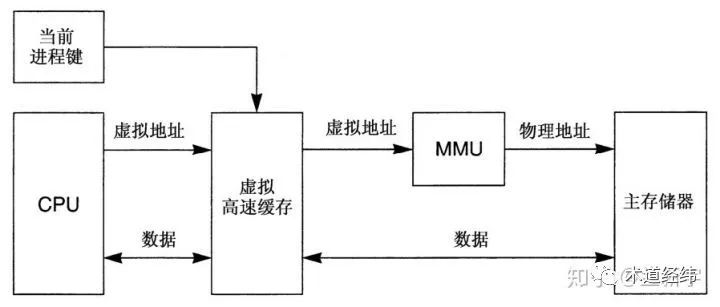
一个看似最简单的解决办法是在每个cache line的标记字段(tag field)里都加入一个进程键(process key),这个键唯一地确定cache中的某一行属于某个特定的进程。
但如果系统中进程数目较多,为了保证process key对每个进程来说是唯一的,在tag filed需要占用的bit位较多,会增加cache实现的难度和为管理键而增加的开销。一个被更为广泛采用的方法是使用物理地址来做tag,即VIPT(Virtually Indexed, Physically Tagged)。
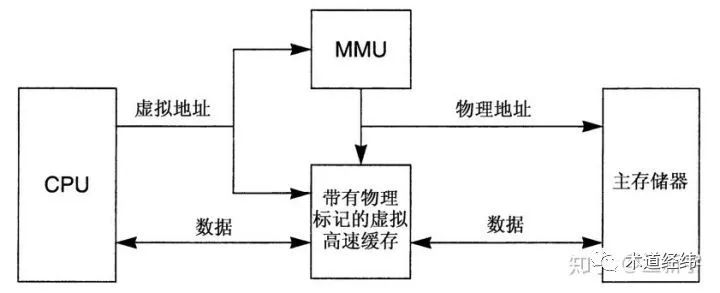
来自CPU的虚拟地址被同时发送到cache和MMU。这样一来,地址转换和存取cache在时间上就交叠在一起。在MMU转换地址的同时,cache也通过hash算法从虚拟地址得到index来开始它的查找操作。接着,cache能够读取被索引到的cache line的内容,为接下来的tag比较做好准备。一旦MMU转换好了地址,就把物理地址发送给cahce。随后,cacche把这个地址和选出cache line中tag里保存的地址进行比较,以判断是否发生了命中或者缺失。
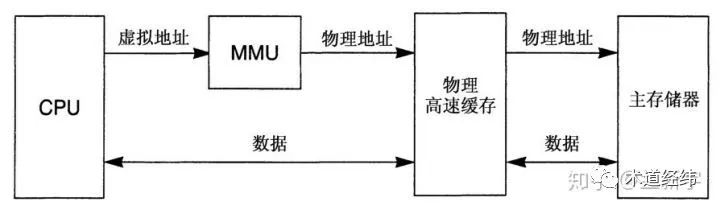
当然,index和tag都用物理地址的物理高速缓存(即PIPT - Physically Indexed, Physically Tagged)也是广泛存在的,其缺点是cache查找操作的速度受限于MMU所需的转换时间,好处则是对于有共享数据的进程,在发生context switch时,可以不用进行cache flush操作,因而通常被数据cache(D-cache)采用。而指令cache(I-cache)是只读的,不存在cache flush的问题,因而通常采用上面提到的VIPT cache。
注【1】:一个位置的情况就是使用直接映射(direct mapped)或者叫单路组相联(one-way set associative)的cache,多个位置的情况就是使用n路组相联(n-way set associative)的cache。当n的值增加到等于cache内的全部行数,则为全相联(fully associative)的cache。n的值越大,cache实现难度越大,通常只有TLB才会设计成fully associative的。
说明:本文主要摘选并改编自《现代体系结构上的UNIX系统:内核程序员的对称多处理和缓存技术(修订版)》。
