




Spark的RDD是Spark的内核,如果没有对RDD的深入理解,是很难写好spark程序的,但是网上对RDD的解释一般都属于人云亦云、鹦鹉学舌,基本都没有加入自己的理解。本文基于Spark原创作者的论文,对Spark的核心概念RDD做一个初步的探讨,希望能帮助初学者快速入门。
《Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing》这篇论文是Spark最为准确最为经典的描述,大家可以在543190166这个qq群的群文件中找到。从论文题目我们可以看到RDD的英文是:Resilient Distributed Datasets,我们从者三个单词入手来解释RDD。
Resilient. 中文解释是“能复原的;弹回的,有弹性的;”,在我们的生活中,一个东西有弹性,就说明这个东西不易损坏,例如皮球、轮胎,而苹果公司在给苹果手机申请的一个专利,正是在手机的四个角加入了类似橡皮筋材质的东西,来增加手机跌落时的抗摔性。Spark的核心数据结构有弹性,能复原,说明spark在设计之初就考虑把spark应用在大规模的分布式集群中,因为这种大规模集群,任何一台服务器是随时都可能出故障的,如果正在进行计算的子任务所在的服务器出故障,那么这个子任务自然在这台服务器无法继续执行,这时RDD所具有的“弹性”就派上了用场,它可以使这个失败的子任务在集群内进行迁移,从而保证整体任务对故障机器的平滑过渡。可能有些同学有疑问了,难道还有系统不具有弹性,而是硬邦邦的?还真有,比如很多的即系查询系统,例如presto或者impala,因为在其上运行的查询,都是秒级的时延,所以如果子任务失败,直接把查询重跑一遍即可。而spark处理的任务,可能时常要运行小时级别,如果任务重跑的代价非常大,所以spark的数据结构一定要有“弹性”,能自动容错,保证任务只跑一遍。
Distributed。这个英文单词的中文意思不用多解释了,就是指的“分布式”。那么到底spark的数据结构怎么个分布式法呢?这就涉及到了spark中分区(partition)的概念,也就是数据的切分规则,根据一些特定的规则切分后的数据子集,就可以在独立的task中进行处理,而这些task又是分散在集中多个服务器上并行的同时的执行,这就是spark中Distributed的含义。spark源码中RDD是个表示数据的基类,在这个基类之上衍生了很多的子RDD,不同的子RDD具有不同的功能,但是他们都要具备的能力就是能够被partition,比如如果从HDFS读取数据,那么会有hadoopRDD,这个hadoopRDD的切分规则就是一个HDFS Block一个partition,spark会为这个Block生成一个task去处理这个Block的数据;如果数据在入库时是随机的,但是在处理时又需要根据数据的key进行分组(group),那么就需要根据这个数据源的key对数据在集群中进行分发,把相同key的数据“归类”到一起,如果把所有key放到同一个partition里,那么就只能有一个task来进行归类处理,性能会很差,所以这个过程的并行化,就是靠把key进行切分,来实现的归类过程并行化。
Datasets。看到这个词,很多人会错误的以为RDD是spark的数据存储结构,其实并非如此,RDD中的Datasets并非真正的“集合”,更不是java中的collection,而是表示spark中数据处理的逻辑。怎么理解呢?这需要结合两个概念来理解,第一是spark中RDD 的transform操作,另一个是spark中得pipeline。首先看RDD的transform,来看论文中的一个transform图:
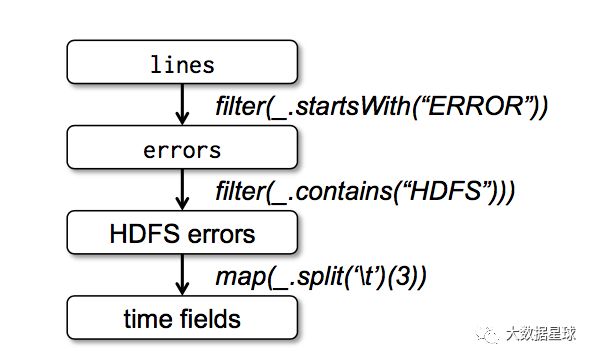
图中每个长方形都是一个RDD,但是他们表示的数据结构不同,注意,这里用的是”表示“,而不是”存储“,例如lines这个RDD,就是最原始的文本行,而errors这个RDD,则只表示以”ERROR“开头的文本行,而HDFSerrors这个RDD则表示包含了”HDFS“关键字的文本行。这就是一个RDD的”变形“过程。好了,我们回到上边纠结的”表示“和”存储“两个字眼上,看看用不同的字眼表达会有什么不同的结果。如果我们用”存储“,那么上一个RDD经过transform后,需要存储下来,等到积攒一批后交给下一个处理逻辑(类似我们以前用迅雷下载电影,要先下载才能观看,两个过程是串行的)。那么问题来了,在一批数据达到之前,下一个处理逻辑必须要等待一段时间,这其实是没有必要的。所以在上一个处理逻辑处理完一条数据后,如果立马交给下一个处理逻辑,这样就没有等待的过程,整体系统性能会有极大的提升,而这正是用”表示“这个词来表达的效果(类似后来的流媒体,不需要先下载电影,可以边下载边观看),这也就是是spark中的pipeline(流水线)处理方式。
RDD的三个单词分析完了,大家可能也有一个疑问,那就是对于pipeline的处理方式,感觉各个处理逻辑的数据都是”悬在空中“,没有落磁盘那么踏实。确实,如果是这种方式的话,spark怎么来保证这种”悬在空中“的流式数据在服务器故障后,能做到”可恢复“呢?这就引出了spark中另外一个重要的概念:lineage(血统)。一个RDD的血统,就是如上图那样的一系列处理逻辑,spark会为每个RDD记录其血统,借用范伟的经典小品的桥段,spark知道每个RDD的子集是”怎么没的“(变形)以及这个子集是 ”怎么来的“,那么当数据子集丢失后,spark就会根据lineage,复原出这个丢失的数据子集,从而保证Datasets的弹性。(当然如果RDD被cache和做了checkpoint就另说了,这属于后续优化要讲解的内容)
