




本文主要介绍数据仓库的起源:决策支持系统。
决策支持系统(DSS),不是大数据时代的产物,在计算机发展初期,就有它的踪迹。称之为数据仓库的起源,是因为如果没有数据需求,也就没有数据处理,更不会有数据仓库的存在。
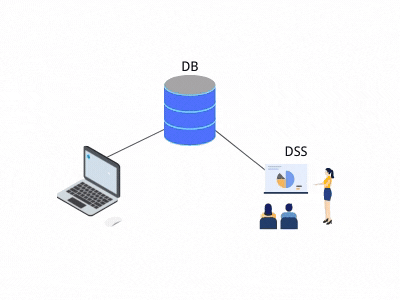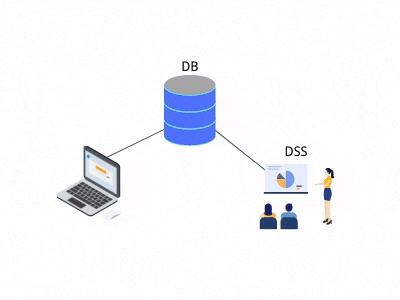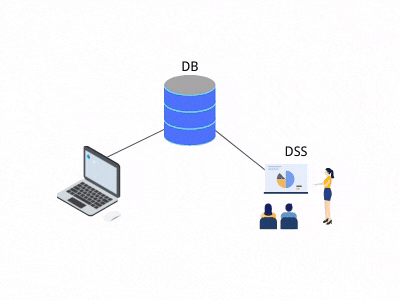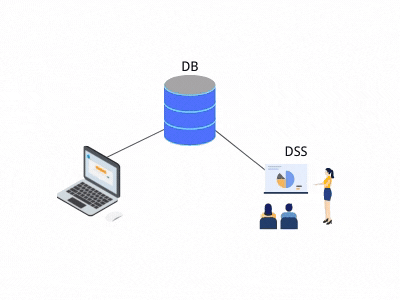
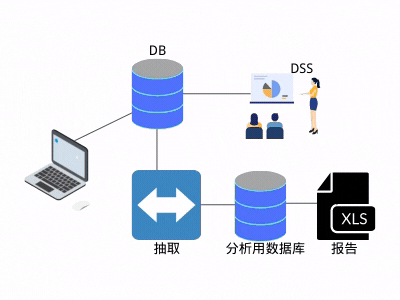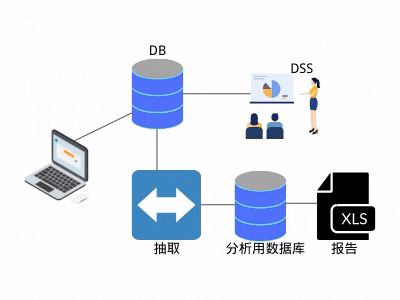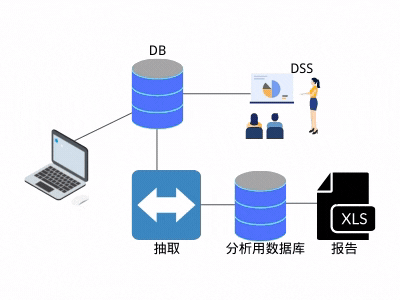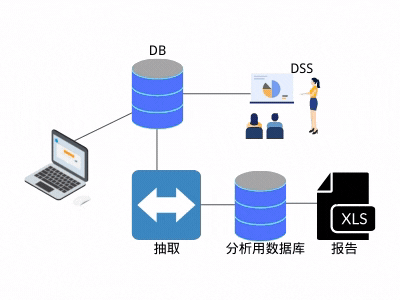
这种处理逻辑有两个好处:
1. 后续的分析,不影响线上业务。
2. 抽取之后,数据就归"自己"所有。
由于种种优势,抽取逻辑流行起来,慢慢变得无处不在。同时,也产生了新的问题:抽取程序变得越来越多,同一份数据被多人抽取,抽取的数据也被别人再次抽取,逐渐形成了网状结构(见图3)
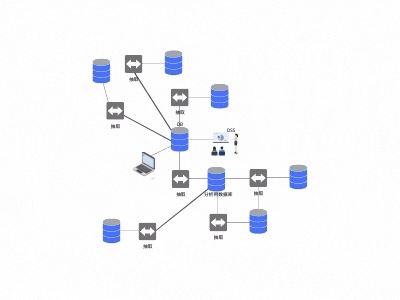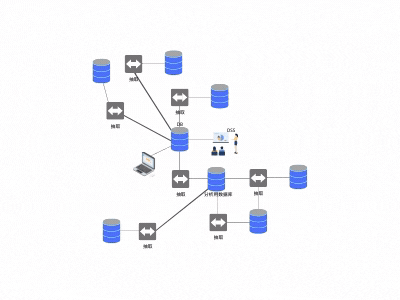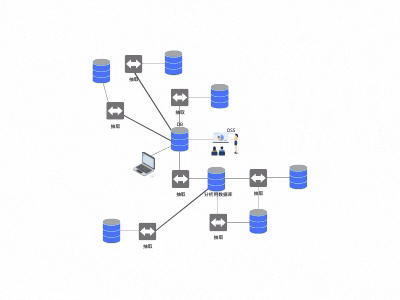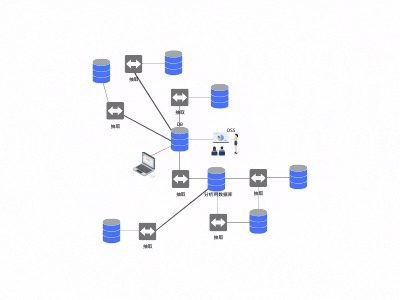
1. 数据可信度差。
2. 效率低。
3. 加大数据理解难度。
分别来说一下
1. 数据可信度差
在同一张网上,不同的两个部门,对同一个指标得到的结果往往大相径庭,A部门说公司业绩上涨10%,B部门说公司业绩下降10%,作为领导拿到这两份报告,只能增加疑惑,无法进行有效的决策。造成这种差异的原因是各个部门都有自己的抽取程序以及抽取方法,互相不知道对方的存在以及逻辑,对于各种定义没有一个统一的认知,得到不同结论也是正常。
2. 效率低
第一,增加沟通成本。
第二,要写的程序很多,并且都是定制的。
第三,程序覆盖公司所有技术。
业务使用什么技术,抽取程序就要与之对应,才能获取数据。
3. 加大数据理解难度。
在蛛网中,每一个抽取程序都有自己的数据处理逻辑,随着处理路径增加,数据差异越来越大,数据之间使用成本也随之增加,无法与其它数据交叉使用。
文章转载自攻城锤的数据仓库,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
