




1. 问题描述
最近发现Ceph的一个纯SSD池偶发慢请求告警,遂在一个测试环境进行复现排查并解决,以下为具体过程。
2. 排查过程
2.1 异常延迟
通过“ceph osd perf”命令可以看到纯ssd池osd会出现秒级别的commit_latency(这里显示的apply_latency和commit_latency都对应bluestore的commit延迟)。
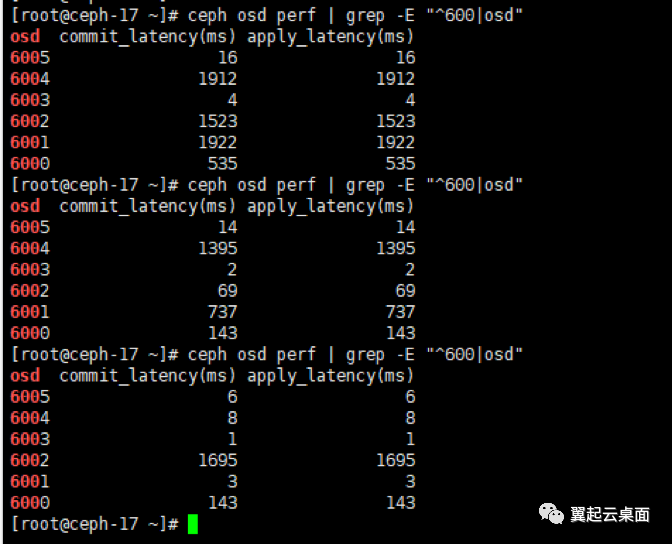
通过“ceph daemonperf osd.6004”查看实时统计,发现k_l、s_l和c_l很大。
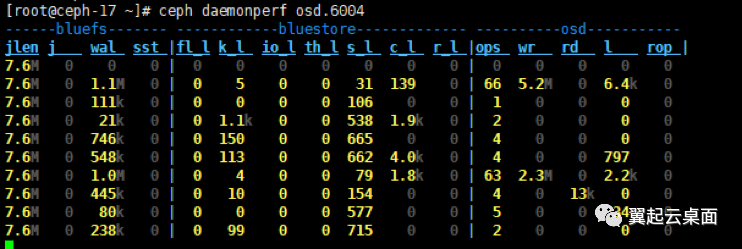
通过查看代码,这几个延迟的具体含义如下:
k_l:Average kv_thread sync latency,kv线程开始处理事务上下文(txc)到kv提交到db之间的时间差。
s_l:Average submit latency,进入bluestore到aio提交完成之间的时间差。
c_l:Average commit latency,txc创建到kv commit到db之间的时间差。
2.2 事务上下文状态机
STATE_PREPARE
txc创建时为STATE_PREPARE状态,如果有对齐的写,则通过bdev->aio_submit提交至内核,完成后的回调会将txc状态切换至STATE_AIO_WAIT状态,否则直接进入STATE_AIO_WAIT状态。aio提交后,会统计从进入bluestore到aio提交的延迟,即sumbit延迟。STATE_AIO_WAIT
将txc的状态切换至STATE_IO_DONE,由于aio的执行是由内核调度,之前的提交的可能还没完成,因此只要保序器中的前一个txc的状态 < STATE_IO_DONE,直接结束状态切换;若前一个txc状态 > STATE_IO_DONE,则说明前面的txc都已经完成了aio,可以进入STATE_IO_DONE状态进行处理;若前一个txc状态是STATE_IO_DONE,按先后进入先后顺序对保序器中的所有STATE_IO_DONE状态的txc进行处理。STATE_IO_DONE
将txc的状态切换至STATE_KV_QUEUED,将需要写入db的kv放入kv_queue,等待kv_sync_thread处理。kv_sync_thread里通过db->submit_transaction(txc->t)将事务提交到db后,将txc的状态切换至STATE_KV_SUBMITTED。STATE_KV_SUBMITTED状态的txc将在_kv_finalize_thread里进行继续进行调度。STATE_KV_SUBMITTED
统计commit延迟,将状态切换至STATE_KV_DONE,然后继续进行调度。STATE_KV_DONE
如果是不需要写WAL的写,将状态切换至STATE_FINISHING;否则加入deferred_queue等待处理。aio完成时,回调_deferred_aio_finish处理,将deferred_queue中的txc切换至STATE_DEFERRED_CLEANUP状态,并加入deferred_done_queue。在kv_sync_thread会对deferred_done_queue里的txc进行处理。STATE_DEFERRED_CLEANUP
统计deferred_cleanup延迟,切换至STATE_FINISHING状态继续处理。STATE_FINISHING
统计finishing延迟,设置状态为STATE_DONE,完成txc处理。
2.3 定位延迟
通过查看代码,kv延迟、commit延迟和submit延迟只有kv延迟会在日志中打印,因此可以从kv延迟开始排查。通过“ceph daemon osd.6004 config set debug_bluestore 20/20”调高日志等级,获取更多日志信息。
通过正则表达式搜索秒级别的kv延迟。

选择第一条往前搜索,发现在1.59秒的kv延迟,大部分发生在_txc_applied_kv到_balance_bluefs_freespace之间。

查看_kv_sync_thread的代码,可疑的地方有两处,一是在_kv_sync_thread中获取txc->osr->qlock锁,二是在_balance_bluefs_freespace打印日志前,调用分配器获取剩余空间,需要获取分配器锁,由于日志中没有更多信息,无法确定具体是哪儿慢。
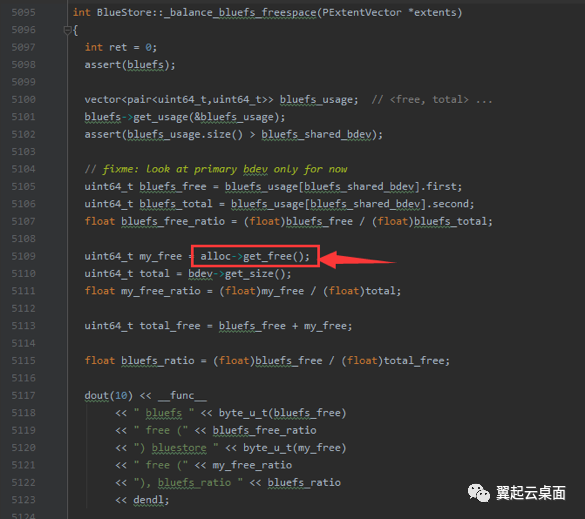
用正则表达式,抽取txc,然后在日志中查找_txc_create和_txc_committed_kv间隔较大的txc。然后根据txc抽取日志,可以发现0x5639df75db80 txc 从_do_alloc_write到_txc_calc_cost就已经出现1.6秒左右的延迟。
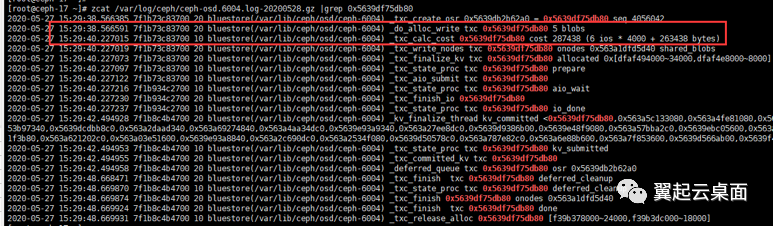
在0x5639df75db80 txc创建之后的日志中,用线程id搜索日志,发现延迟出现在_do_alloc_write和stupidalloc之间。
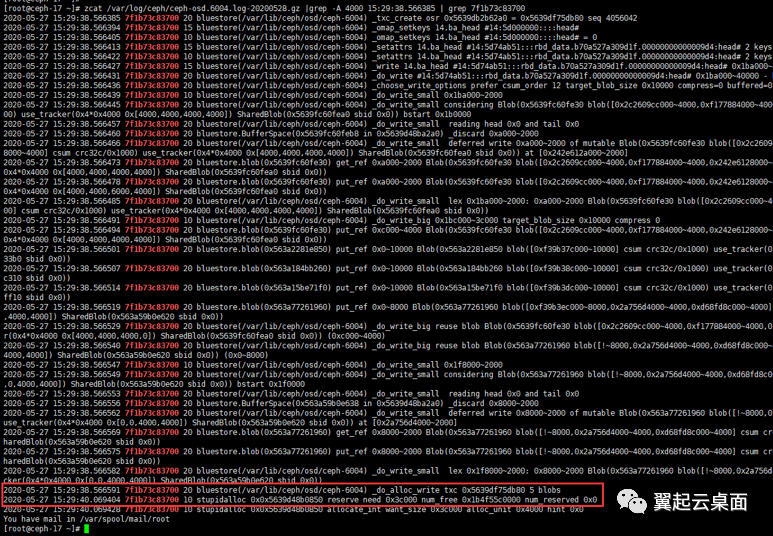
stupidalloc日志由_do_alloc_write调用alloc->reserve预留空间时打印,由于我们的环境没有开启压缩bluestore压缩,中间的代码可以忽略。在打印stupidalloc日志之前唯一可能造成延迟的地方就是获取分配器锁。
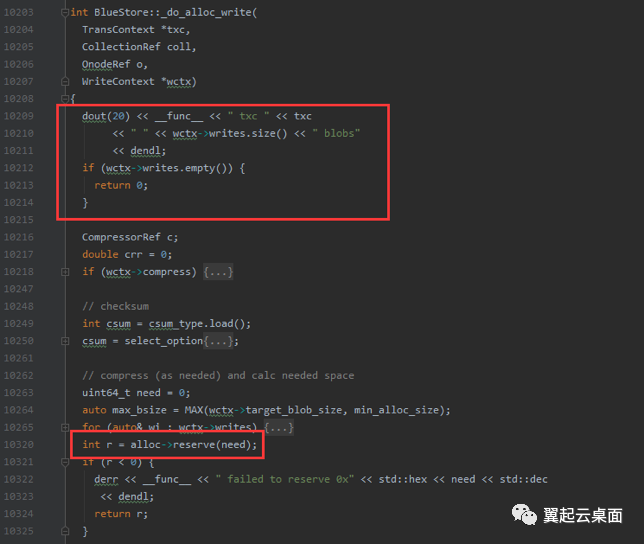
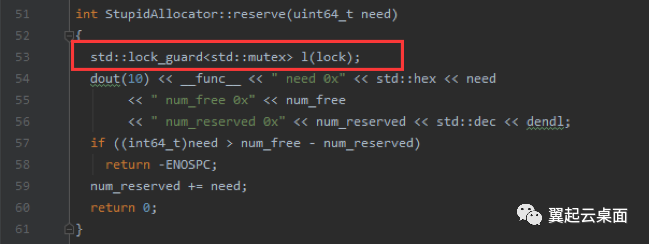
为了查看分配器里面的日志信息,将bluestore debug等级设置为30/30,运行十秒左右,恢复日志等级为4/5。
先获取线程id,一共40个线程,意味着有40个线程在竞争分配器锁。
cat var/log/ceph/ceph-osd.6004.log | grep prealloc | awk ‘{print $3}’ | sort | uniq > tid.txt
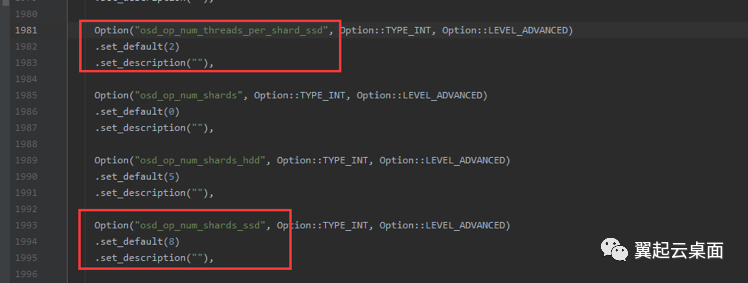
SSD默认的处理线程是16个(2*8),我们的环境配成了40个(5*8),加剧了分配器锁竞争。
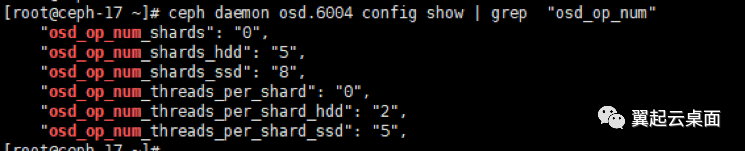

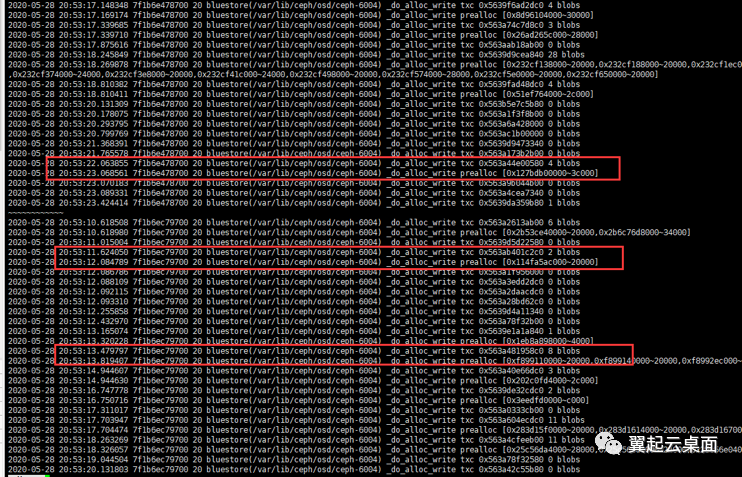
根据线程id查看调用分配器前后的时间差,从下图可以看出,一次分配的时间就可能到达1秒。
for t in cat tid.txt
;do echo “~~~~~~~~”;cat var/log//ceph/ceph-osd.6004.log | grep $t | grep -E “_do_alloc_write txc|prealloc”;done | more
2.4 解决方法
2.4.1 彻底解决方法
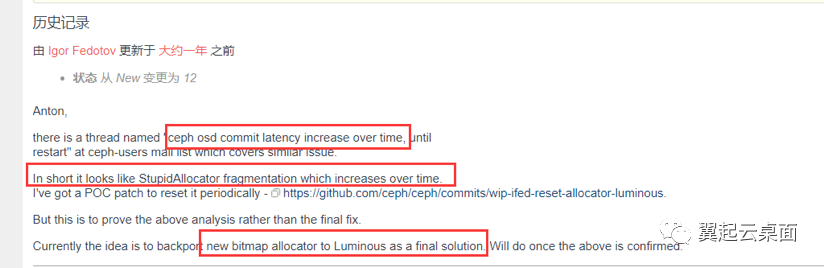
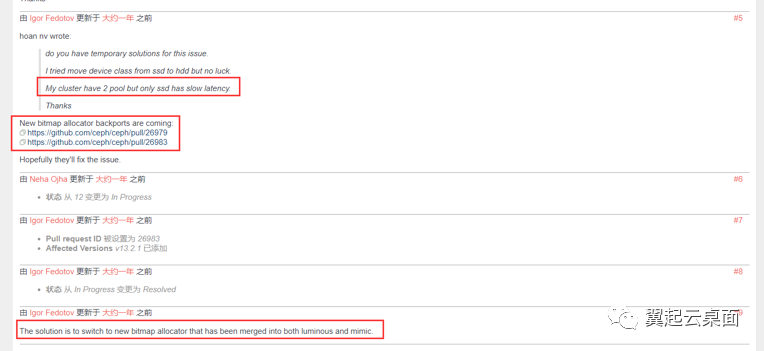
在ceph tracker里可以找到关于在SSD上创建bluestore OSD出现的大延迟问题,分析原因是由于stupid分配器在碎片多的时候效率会很低,SSD默认的最小分配空间是16K,HDD是64K所以SSD的碎片问题比较严重。新的bitmap分配器性能更佳且解决了这个问题。Luminous 12.2.12版本移植了master分支的新bitmap分配器,Luminous 12.2.13版本将默认的分配器修改为bitmap。
https://tracker.ceph.com/issues/38738
SSD默认的处理线程是16个(2*8),我们的环境配成了40个(5*8),加剧了分配器锁竞争。
2.4.2 临时解决方法
在/etc/ceph/ceph.conf文件中删除“osd_op_num_threads_per_shard_ssd = 5”配置,将所有SSD对应的OSD重启一遍后,延迟恢复正常。
3. 问题总结
Ceph纯SSD池的慢请求是由于12.2.11版本使用的stupid分配器在碎片严重的时候效率低下和不合理的处理线程数配置导致,临时解决方法可以通过恢复成默认的处理线程数,重启OSD重置分配器,但运行时间长了依然会出现几十到几百毫秒的延迟,彻底解决需要升级Ceph至12.2.12或12.2.13版本。
