




最近比较忙,许久不更新,大家见谅 : -)
在Ceph的使用场景中,大量读的业务场景非常普遍,然而由于Ceph本身的读写机制设计,Ceph会出现读请求分布不均的问题,导致Ceph集群的OSD磁盘忙闲不均,容易产生慢请求,影响业务的使用。本文将讨论一下Ceph均衡读的问题~
要了解Ceph数据均衡读的问题,需要先从Ceph数据分布说起~
1. Ceph数据分布
1.1 Ceph数据分布过程
Ceph的数据分布式方式用一句话说就是 “算算就好”,客户端文件到集群磁盘的过程如下:
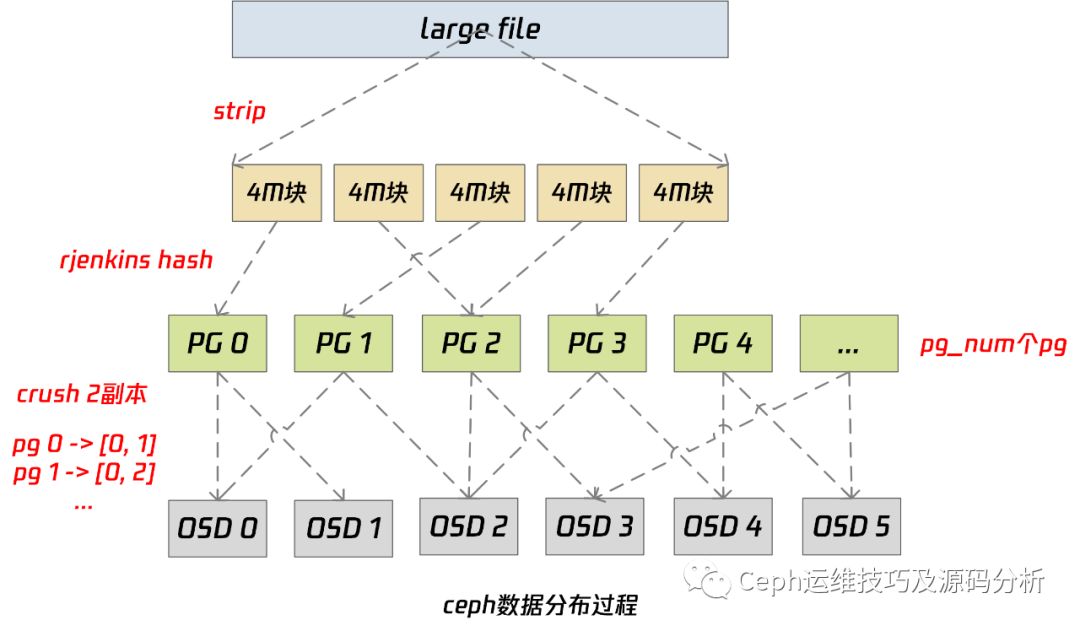
大文件会分片成4M(可配置)大小的对象
4M对象通过hash算法rjenkins(可配置)映射到PG(可理解为对象桶)
PG到OSD磁盘的映射是通过crush算法决定的,在为客户端提供服务前已经全部创建
1.2 Ceph数据分布均衡性
数据分布一般追求一个目标,那就是数据在集群各磁盘上是均衡分布的。
保持磁盘数据均衡的好处:
磁盘数据均衡可提高集群磁盘的使用率,减少磁盘空间损失率,也就是木桶原理,空间使用率高的磁盘限制了整个集群的可用空间
磁盘数据均衡可提高集群的读性能,在相同的数据访问概率下,数据量大的磁盘会更加繁忙,对于机械磁盘本身性能不高,很容易达到性能瓶颈
用户数据最终会转化成对象,对象对PG是通过hash映射,在有足够数据量时,可认为各PG内的数据量是基本一致的。因此,要追求磁盘数据均衡,需要PG在OSD磁盘上是均衡分布的。
如果提高PG在OSD磁盘上分布的均衡性呢?
PG到OSD的映射是通过带权重的hash算法crush,要想hash分布均衡,需要样本要足,这里就是创建更多的PG。
在数据量一定的情况下,更多的PG,使每个PG的承载的数据量减少,这样PG从一个OSD迁移到另一个OSD,对OSD磁盘的使用率影响更小,更多的PG使得集群磁盘数据更加均衡。
PG越多数据越均衡,那可以尽情创建PG?
当然不是
PG太多会导致OSD维护PG更加困难
PG越多会导致数据可靠性降低(多磁盘同时故障时,丢数据的可能性提高)
Ceph官方给出了PG/OSD值为100
在hash样本不足(PG/OSD ≈ 100)的情况下,怎么做到PG分布均衡?
我们需要研究下crush算法
1.3 crush算法
一句话,crush算法是用来给PG寻找归宿的~
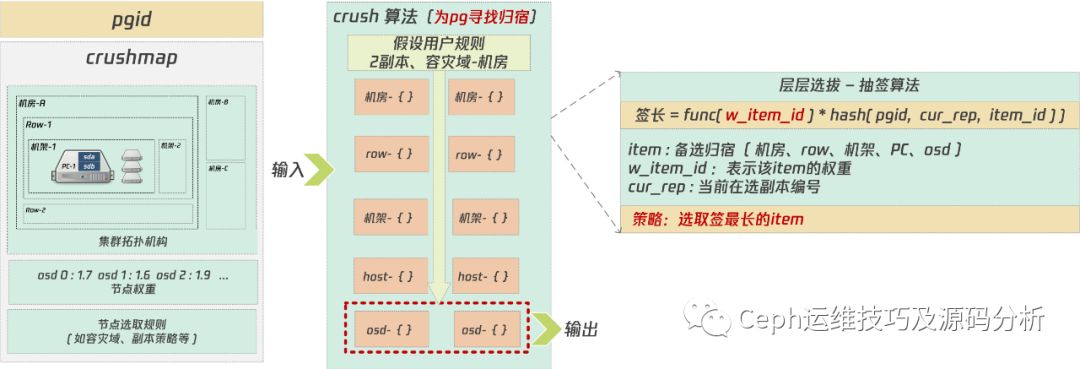
crush算法:[ pgid, crushmap] -> crush -> [osd x, osd y, …]
crushmap包含三部分内容:
集群的拓扑结构
集群各节点的权重
节点的选取规则,如容灾域、副本策略等
crush算法工作流程:
举个例子,crush规则设置容灾域为机房,副本数为2,我们来看crush算法如何为pg 1.21 需要寻找归宿,crush算法会先为该PG的两个副本选取两个机房,然后从这两个机房中依次往下选取row、机架、host、磁盘。
crush是如何从多个机房中选取两个机房的?是如何从机房的多个row中选取一个row的?
每一次的选择可以使用不同的算法,crush默认采用抽签算法,以机房选取为例,抽签算法会计算每个机房的签长:
签长 = func( w_item_id ) * hash( pgid, cur_rep, item_id ) )
我为PG的第 1 个副本选取机房,此时,

由此,我们可以计算出每个机房的签长,选取签长最长的机房作为PG的第 1 个副本的目标机房,同理可以选取PG的第 2 个副本的目标机房。
通过抽签算法逐层往下选择,最终可为PG选取坐落的机房、row、机架、host、磁盘。
虽然磁盘的容量是一致的,可以设置不同的权重,来寻求pg均衡分布在osd磁盘上。
调整后,各OSD上的pg数相对均衡,OSD的磁盘数据量也相对均衡,使用率相差3%以内。
在集群内磁盘数据如此均衡的情况下,大量读时,还会出现磁盘负载不均衡?
2. Ceph读模式
客户端的读请求只会发往PG的Primary副本。。
本节结束。。
3. 大量读均衡问题
对于读请求,只会发往Primary OSD,Primary OSD处理结束后即回复客户端。因此,大量读时,OSD磁盘的负载均衡不仅取决于磁盘的数据是否均衡,还取决于PG的Primary副本在OSD上是否分布均衡。
过一个脚本来看一个数据相对均衡的集群的PG的Primary副本在OSD上是否分布均衡:
root@h235:/# ./check_primary_pg.sh cephfs_data# PRIMARY PGs number per OSD sorted descending:osd.73 PGs number: 124osd.1 PGs number: 123osd.53 PGs number: 122osd.48 PGs number: 122osd.93 PGs number: 121...osd.63 PGs number: 93osd.37 PGs number: 92osd.34 PGs number: 88osd.21 PGs number: 87Primary: Min=87 Max=124 Average=102.6667 Max/Ave=1.20779
从数据来看,承载PG Primary副本最多的OSD承载了124个,最少的OSD承载了87个。在PG分布均衡时,PG的Primary副本分布却不均衡,由于读请求只由PG的Primary副本处理,从而导致大量读时,OSD磁盘负载不均衡。
在应对大量读的业务时,在创建集群时,可以通过调整OSD的权重来调节PG的分布,让PG和PG的primary副本都分布均衡一些。
: -)
