





在上一篇文章:Q2从高可用开始(一):说说如何发送binlog,我们确定了 Binlog 发送的格式,紧接着需要确定 Binlog 数据如何消费。
在技术上,数据消费有两种常见模式:串行和并行。下图是基于 Binlog 的数据同步全景图,我们依照下图来讨论。
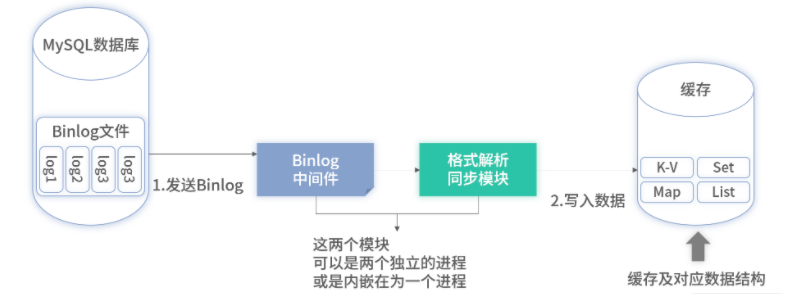
全串行的方式进行消费
以 MySQL 为例,不管是表还是 SQL 维度的数据,都需要将整个实例的所有数据变更写入一个 Binlog 文件,使用 ACK 机制进行串行消费,每消费一条确认一条,然后再消费一条,重复。消费形式如下图所示:
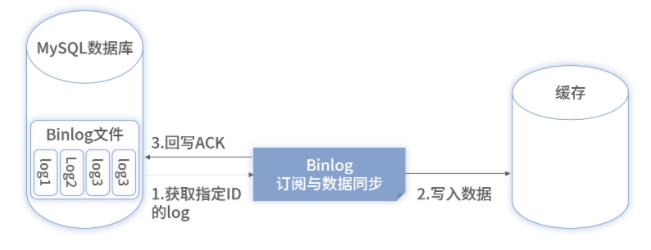
此类模式的消费存在两个问题。
串行消费效率低,延迟大。假设一次同步 20ms 左右,同步 10W 条数据就需要 30min 左右。
单线程无法利用水平扩展,架构有缺陷。当前数据量小,可以满足;但当数据量增大后,此模式无法通过水平扩展来提升性能。
采用并行的方式提升吞吐量及扩展性
通过一些技术手段我们是能够对 Binlog 文件里的不同库、不同表的数据进行并行消费的。
因为不同库之间的数据是不相关的,为了在 Binlog 原有的串行机制下完成按库的并行消费,整体架构需要进行一定升级,具体如下图:
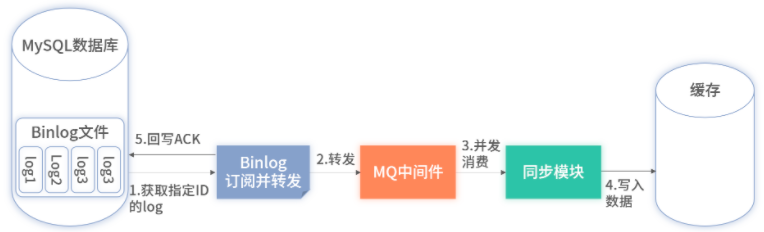
上述架构借用了 MQ 进行拆分。
在 Binlog 处仍然进行串行消费,但只是 ACK 数据。ACK 后数据直接发送到 MQ 的某一个 Topic 里即可。
因为只做 ACK 并转发至 MQ,不涉及业务逻辑,所以性能消耗非常小,大概只有几毫秒或纳秒。
现在大部分的 MQ 中间件都支持数据并行消费,在开发时,上图中的数据转换模块在消费数据时开启并行乱序消费即可。
此时虽然完成了从串行消费到并行消费的升级,提升了吞吐量和扩展性,但也因并行性带来了数据乱序的问题。
比如你对某一条微博连续修改了两次,第一次为 A1,第二次为 A2。如果使用了并行消费,可能因为乱序的原因,先接收到 A2 并写入缓存再接受到 A1。此时,微博中就展示了 A1 的内容,但缓存中的数据 A1 是脏数据,实际数据应该是 A2。因此我们需要继续对升级后的方案进行改造。
有两个解决方案。
加分布式锁实现细粒度的串行
此方案和 Binlog 的串行区别是粒度。
按上述修改微博的例子,在数据同步时,只需要保证对同一条微博的多次修改串行消费即可,而多条微博动态之间在业务上没有关系,仍然可以并行消费。
在实施时,加锁的维度可以根据数据是否需要串行处理而定,它可以是表中的一个字段,也可以是多个字段的组合。
确定加锁的维度后,数据库中的多张表可根据需要使用此维度进行串行消费。虽然可以解决乱序问题,但引入布式锁且需要业务系统自己实现,出错率及复杂度均较高。
依赖 MQ 中间件的串行通道特性进行支持
采用此方案后,整个同步的实现会更加简单。
还是以上述修改微博为例,订阅及转发模块在转发 Binlog 数据前,会按业务规则判断转发的 Binlog 数据是否在并发后仍需要串行消费,比如同一条微博的多次修改就需要串行消费,而多条微博间的修改则可以并行消费,它不存在并发问题。
判断需要串行消费的数据,比如同一条微博数据,都会发送到 MQ 中间件的串行通道内。在同步模块进行同步时,MQ 中间件里的串行通道的数据均会串行执行,而多个串行通道间则可以并发执行。这既解决了乱序问题又保证了吞吐量。
很多开源的 MQ 实现都具备这个功能,如 Kafka 提供的 Partition 功能。
改造后的架构如图所示:

最后,在采用了 MQ 进行纯串行转并行时,将 Binlog 发送到 MQ 可以根据情况进行调整,当数据量很大或者未来很大时,可以将 Binlog 的数据按表维度发送到不同的 Topic。一是能够实现扩展性;二是可以提升性能;三是通过不同表使用不同的 Topic,可以起到隔离的作用,减少表之间的相互影响。
阅读推荐:
