




这篇文章将详细地介绍MySQL的高可用解决方案—— MySQL InnoDB Cluster。
说到高可用性,首先要了解一下什么是高可用性?

高可用性要求的实际上是对可靠性的要求,从本质上来说,是通过技术和工具来提高可靠性,尽可能长时间保持数据的可用和系统的正常运行时间。实现高可用性的原则为排除单点故障、通过冗余实现快速恢复,并且具有容错机制。

上面一页主要介绍了几个关键词汇,以及相关的定义,这些有助于理解可靠性和高可用性。
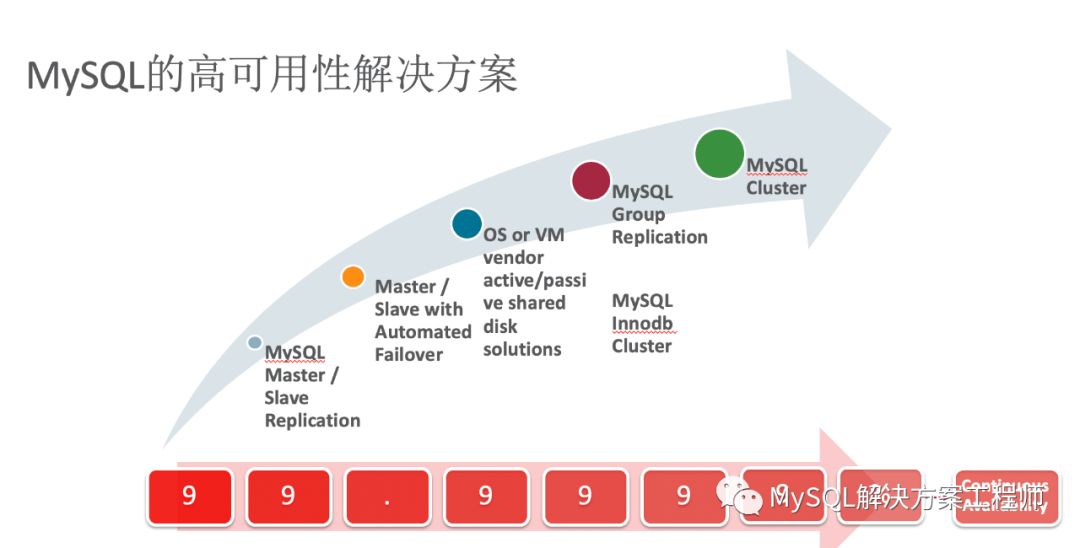
MySQL的高可用性解决方案目前大致分为5种,按照高可用的级别(99.9999%为最高级)排序依次为,主从复制、具有自动故障转移功能的主从复制、利用共享存储、OS或虚拟化软件实现主备架构、MySQL Group Replication 群组复制,以及MySQL NDB Cluster。
MySQL Replication:允许数据从一台实例上复制到一台或多台其它的实例上。
MySQL Group Replication:群组复制提供更好的冗余性、自动恢复以及写入扩展。
MySQL InnoDB Cluster:基于群组复制,提供了易于管理的API、应用故障转移和路由、易于配置,提供比群组复制更高级别的可用性。
MySQL NDB Cluster:容易与MySQL InnoDB Cluster混淆,是另外一款产品,提供更高级别的可用性和冗余性。适用于分布式计算环境,使用内存型的NDB存储引擎。关于这款产品的详细内容将不会在这里介绍。
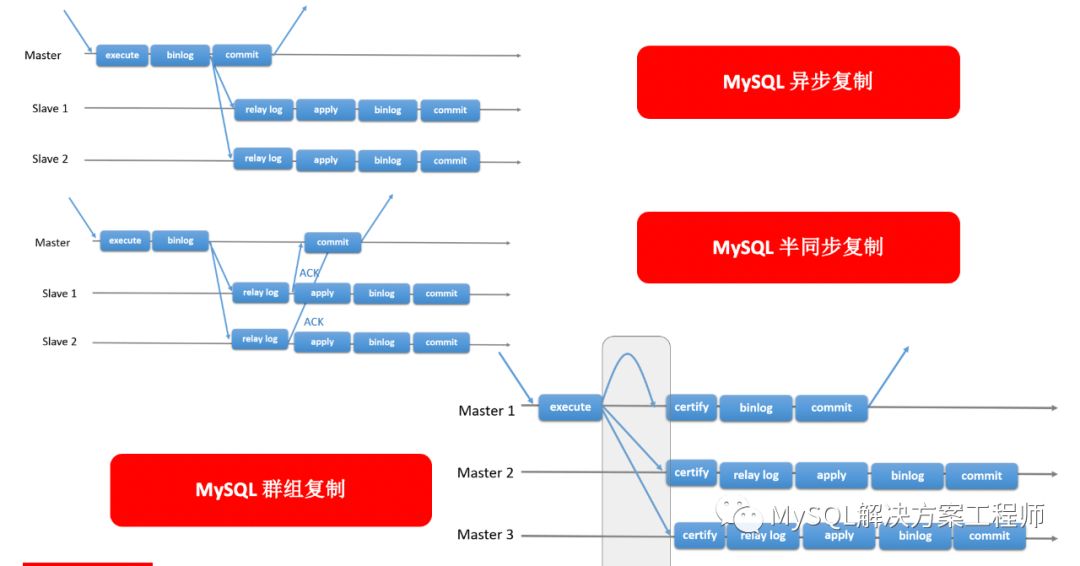
在这里简明介绍一下以复制为基础的三种方案的基本原理。
经典的主从复制是MySQL原生的复制功能,采用异步方式,如图片最上面显示的原理,主服务器执行更改数据的事务后,会产生binlog,之后binlog会被发送到从服务器变成relay log,与此同时,主服务器会对应用提交返回。从服务器接收到relay log后,会通过一个applier的线程对日志里面的内容进行施放,使产生的数据更改写入从服务器,之后产生自己的binlog,进行提交。
采用异步的方式,在发生网络问题和服务器损坏的情况下(从服务器未接收到日志,主服务器已经提交,并且提交后主服务器彻底损坏)会丢失数据,为了防止数据丢失,半同步复制在异步的基础上增加了一个日志确认的环节,在从服务器接收到日志后,返回给主服务器一个应答,之后主服务器才能对应用提交返回。
作为MySQL目前最新的复制方式,群组复制MGR可以通过群组内任意服务器对数据进行更新,而不是像前面两种有主从之分。为此群组复制增加了一个验证步骤,通过验证的事务才能进行提交,提交后群组内其它成员同样对日志进行施放,提交。
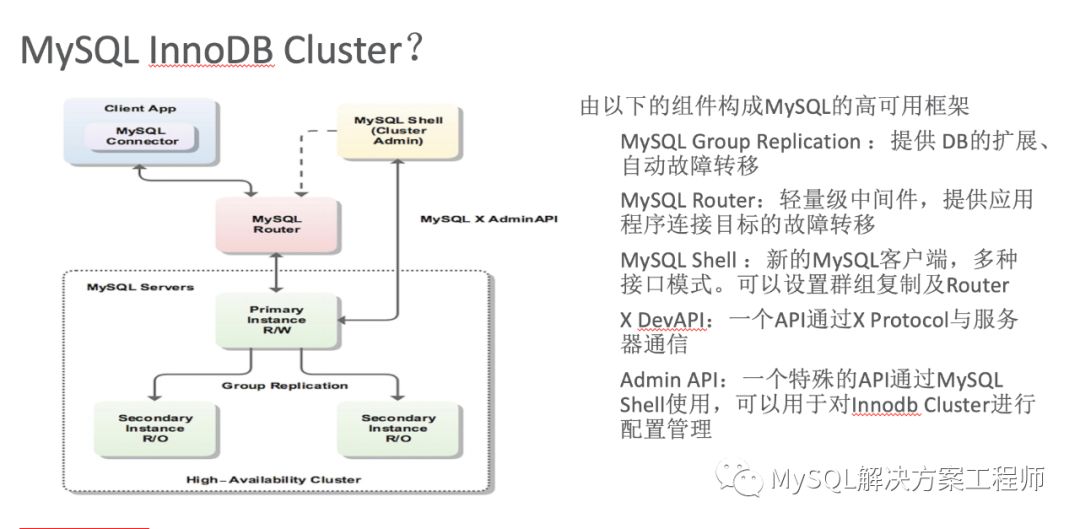
MySQL InnoDB Cluster是一个高可用的框架,它由下面这几个组件构成:
MySQL Group Replication:提供DB的扩展、自动故障转移
MySQL Router:轻量级中间件,提供应用程序连接目标的故障转移
MySQL Shell:新的MySQL客户端,多种接口模式。可以设置群组复制及Router
X DevAPI:一个API通过XProtocol与服务器通信
Admin API:一个特殊的API通过MySQL Shell使用,可以用于对Innodb Cluster进行配置管理
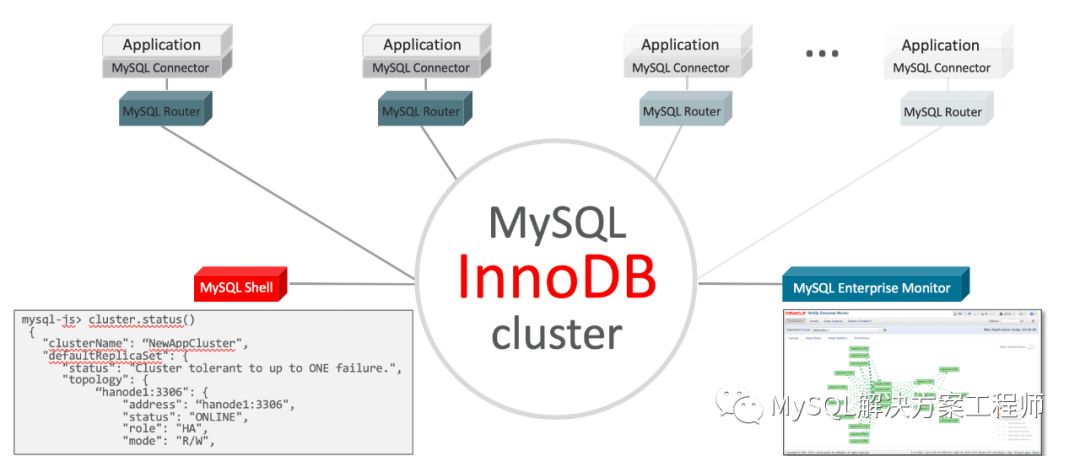
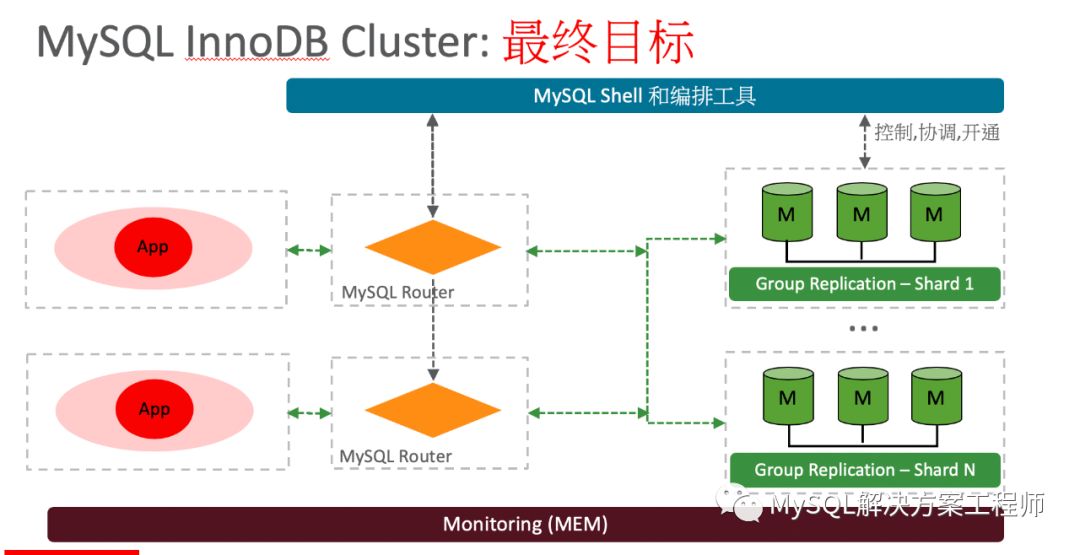
上图显示了InnoDB Cluster的整体架构,MySQL Router推荐部署在应用端,通过MySQL Shell 对其进行管理配置,使用MySQL Enterprise Monitor对整体进行监控。
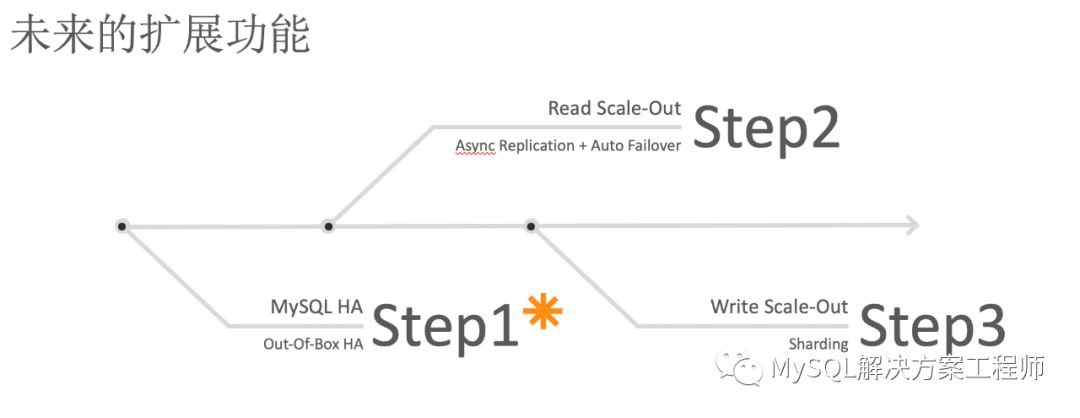
InnoDB Cluster目前已经实现了发展路线图的第一步——高可用性,将来的发展方向为自动读取扩展和自动写入扩展。最终实现如下图的最终目标:
接下来的内容,将详细介绍一下MySQL Group Replication。
MGR实现了 Replicated Database State Machine理论,通信服务基于Paxos实现,为MySQL5.7之后的版本提供同步复制(日志复制同步,数据施放异步),并且支持所有的MySQL平台,包括Linux, Windows,Solaris, OSX, FreeBSD。
MGR提供了高可用分布式MySQL数据库服务,它可以实现服务器自动故障转移,分布式容错能力,支持多主更新的架构,自动重配置(加入/移除节点,崩溃等等)并且可以自动侦测和处理冲突。
MGR适用的场景包括:
弹性复制-复制架构下,服务器的数量动态增加或缩减时,使影响降到最低。
分片的高可用-用户可以利用MGR实现单一分片的高可用,每个分片都具有一个复制组。
主从复制的替代选择-可以使用单主模式避免发生冲突检测,以替代传统的主从复制。
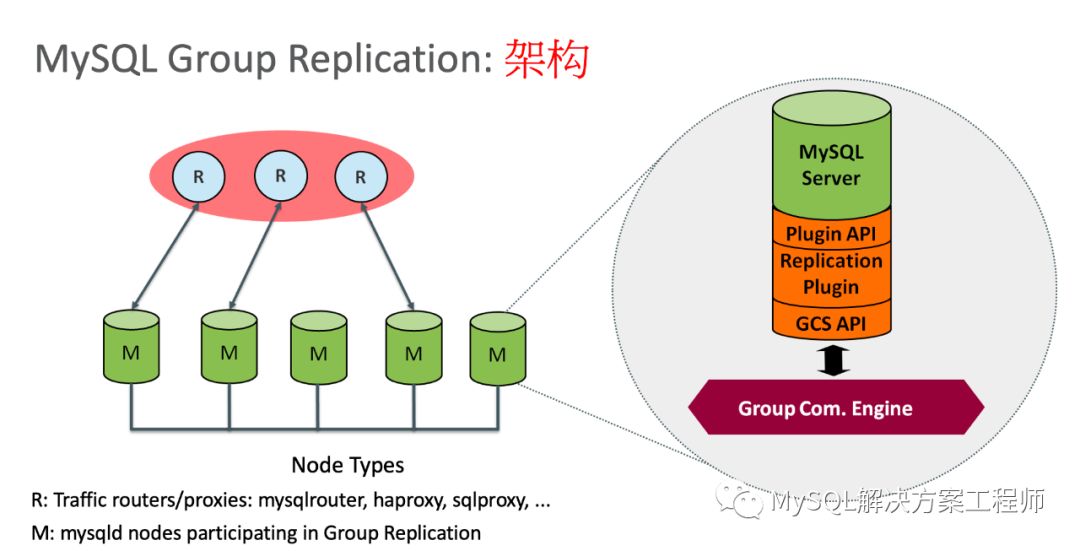
上图是MGR的架构,里面包括:
MySQL Group Replication插件

GR插件负责执行分布式内容,侦测和处理冲突,恢复分布式集群,推送事务给其它的组成员,接收其它成员的事务以及决定事务最终的结果。
GCS群组通信系统
GCS API将通信系统的实现进行抽象化,并管理这个接口。通信引擎是基于Paxos开发的,是实现跨服务器的组件。

MGR在使用时具有两种模式,包括:
单主模式
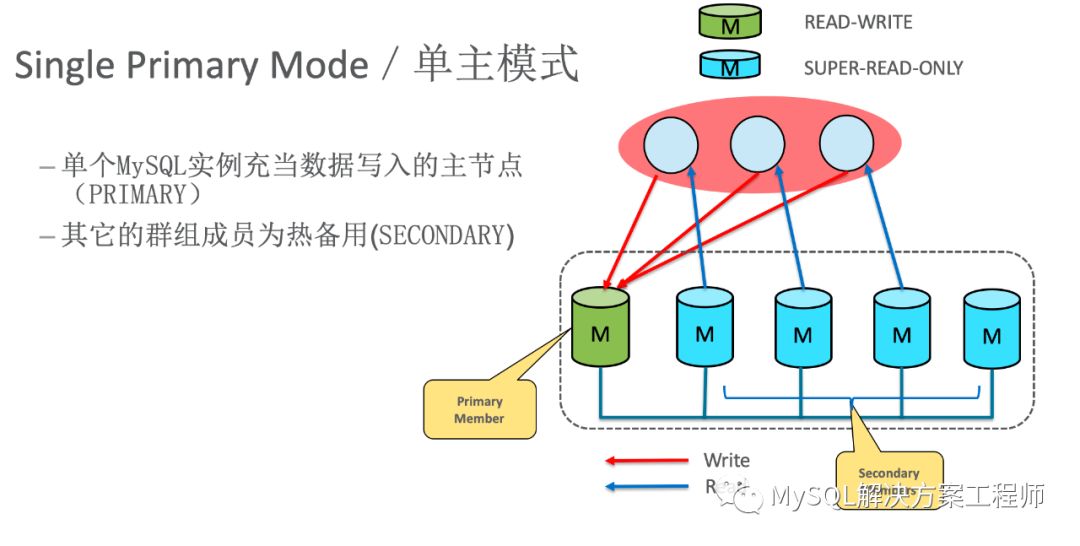
该模式下,单个MySQL实例作为数据写入的主节点,其它的节点用于热备。这个模式与传统的主从模式相似,便于现有系统进行切换。
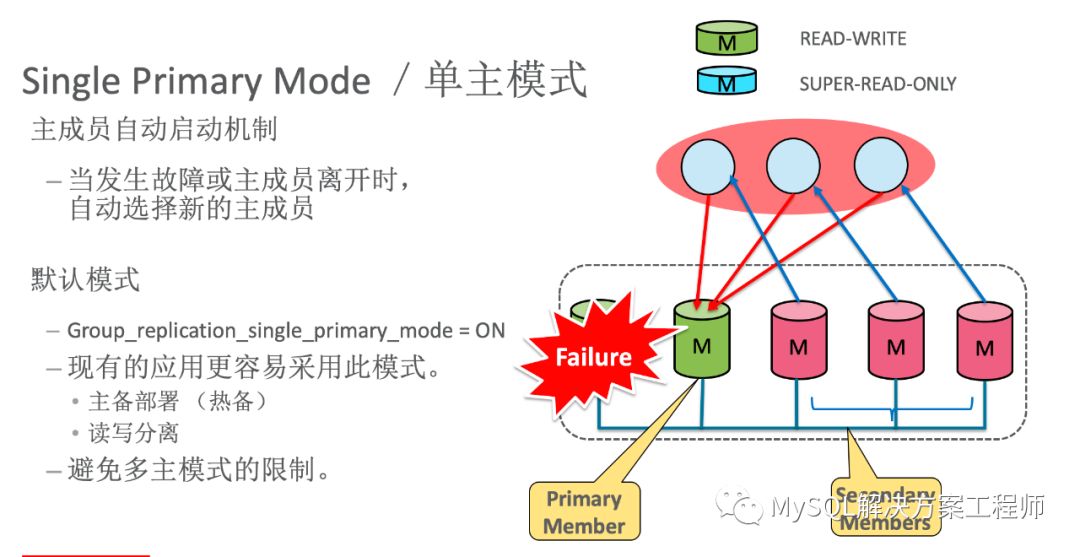
多主模式
除了上面的单主模式,群组复制还具有多主模式,与单主模式的主要区别在于,群组内所有的成员都可以进行数据写入、读取操作。
使用多主模式时,由于数据的写入可以在所有的成员节点上进行,当在不同成员上对同一条记录同时进行更新时,就会产生冲突,此时群组复制会根据成员提交的先后次序(严格来讲是在群组复制的一致性校验阶段,取得校验成功的先后次序)进行判断,后提交事务的执行回滚处理。
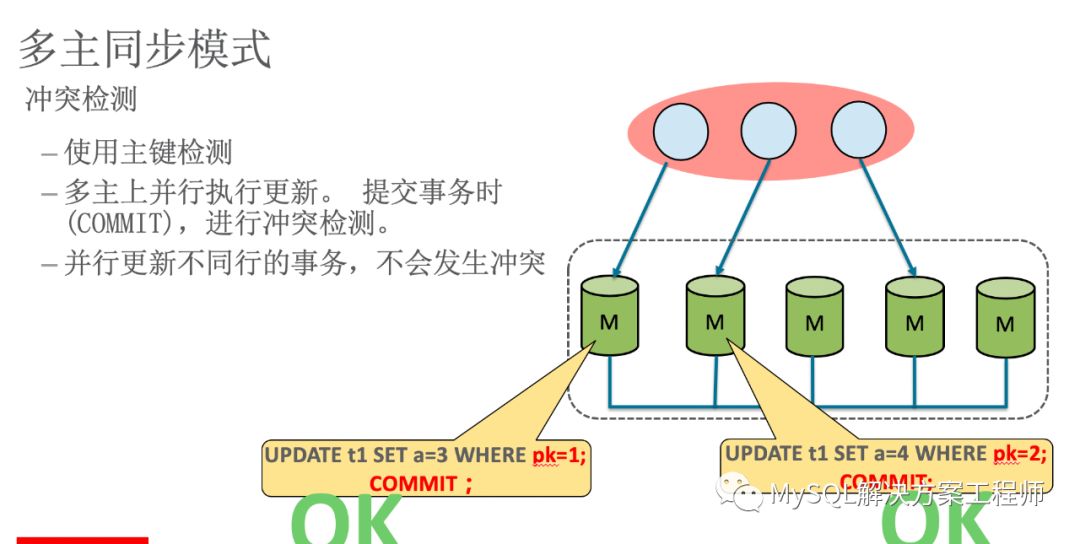
冲突检测需要使用主键。
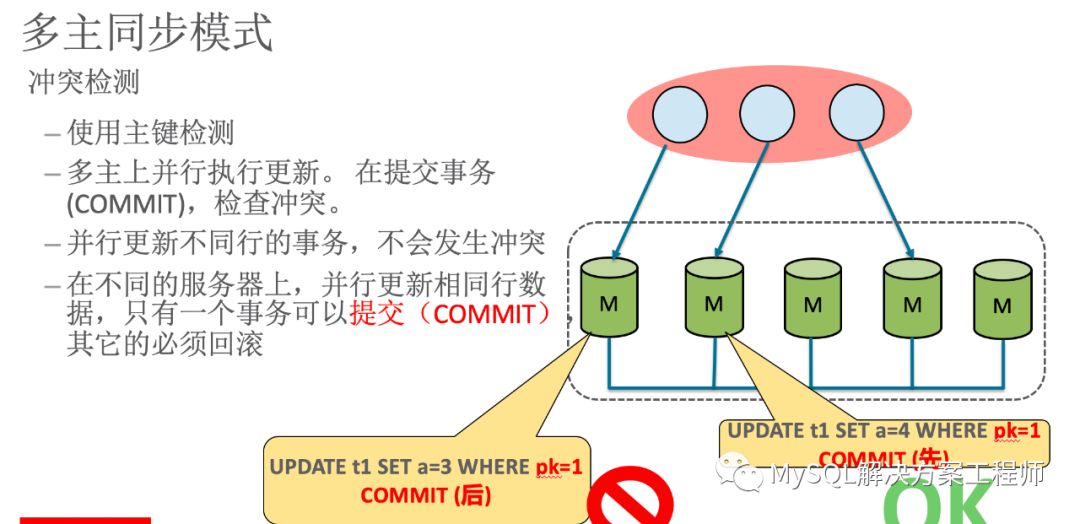
由于多主模式需要确保数据写入的一致性,所以在使用上有如下限制:

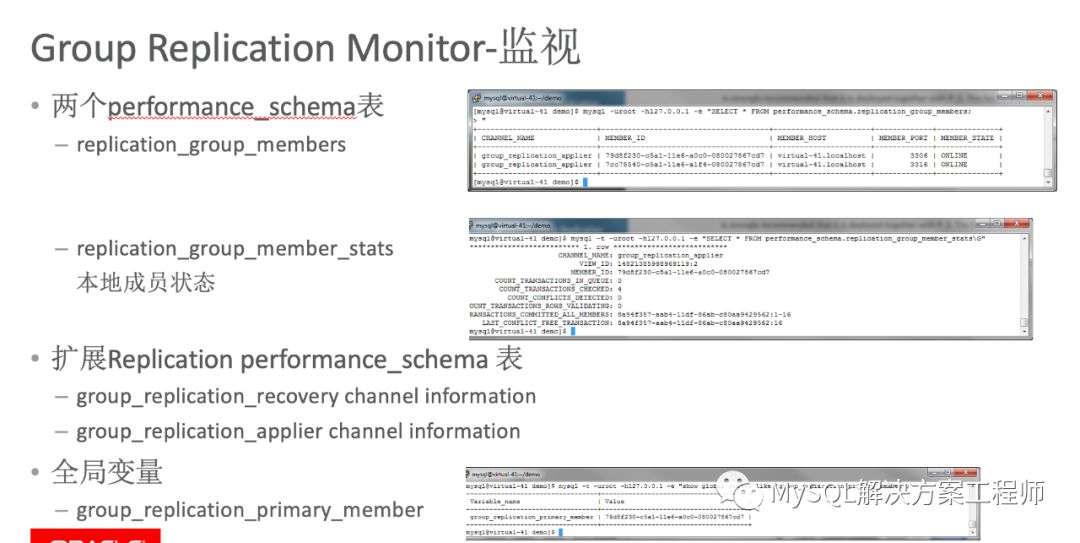
当配置好MGR以后,需要对其进行监视和管理,通过perforamnce_shcema里面的表和全局变量可以确认MGR的成员状态,当前主成员等必要信息。
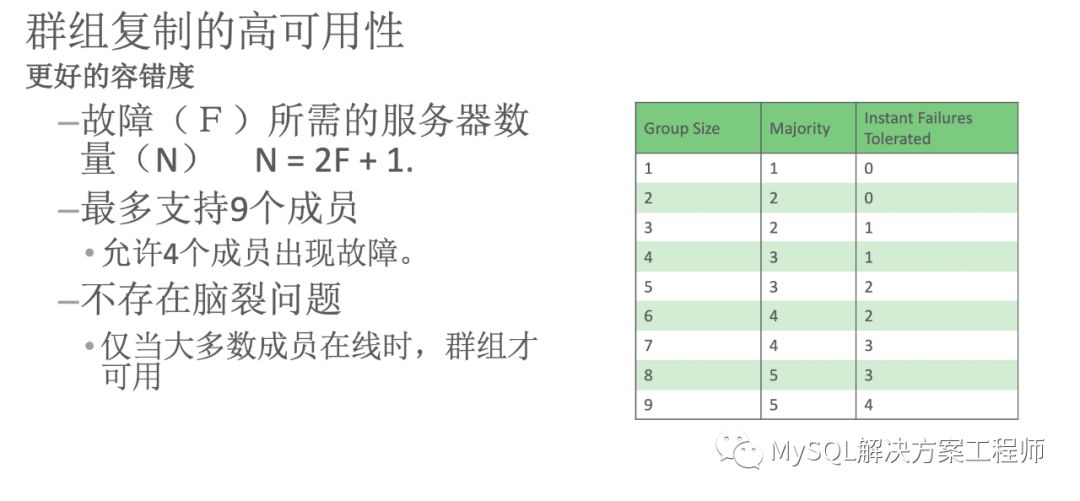
群组复制的特性之一是提供高可用性,具有更好的容错度。每个群组最多具有9个成员(推荐使用不超过7个,最低使用3个。)
故障:(F)所需的服务器数量:(N)
N= 2F + 1
9成员的情况下,最多允许4个成员出现故障。
使用MGR不会出现脑裂问题,MGR会检测网络分区。
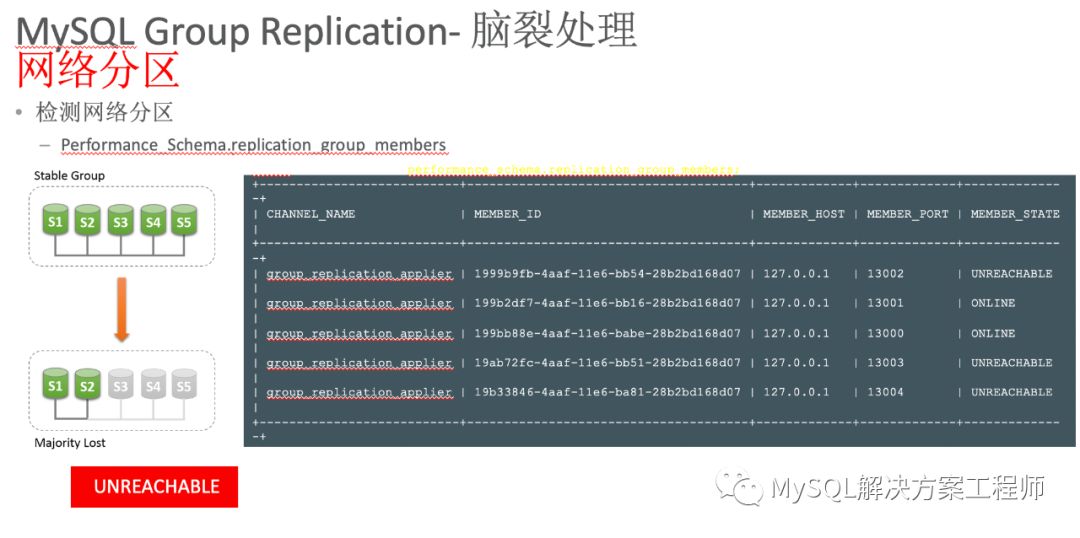
发生网络分区时,如果部分成员检测到大多数成员丢失,连接到这部分成员的数据更新处理将被挡住并等待,Select可以执行。如下图所示,S1 S2与其余三个成员失去联系,对于S1 S2来说他们已经丢失了群组中的大部分成员,因此不能够在它们上面执行数据更新处理(S3 S4 S5上面可以进行数据更新,当网络故障恢复后,S1 S2可以从S3 S4 S5上获取故障期间未更新的数据)

MGR事实上也是一个分布式集群,让我们看一下MGR是如何确保集群范围内的数据一致性。
MGR是通过日志的传播和施放来进行群组内所有成员的数据同步,因此,在某一时间点各个成员上数据是会出现不一致的情况(最终会一致)。在MySQL8.0.14之后,可以通过使用变量 group_replication_consistency 精确地控制每个节点上数据的一致性。
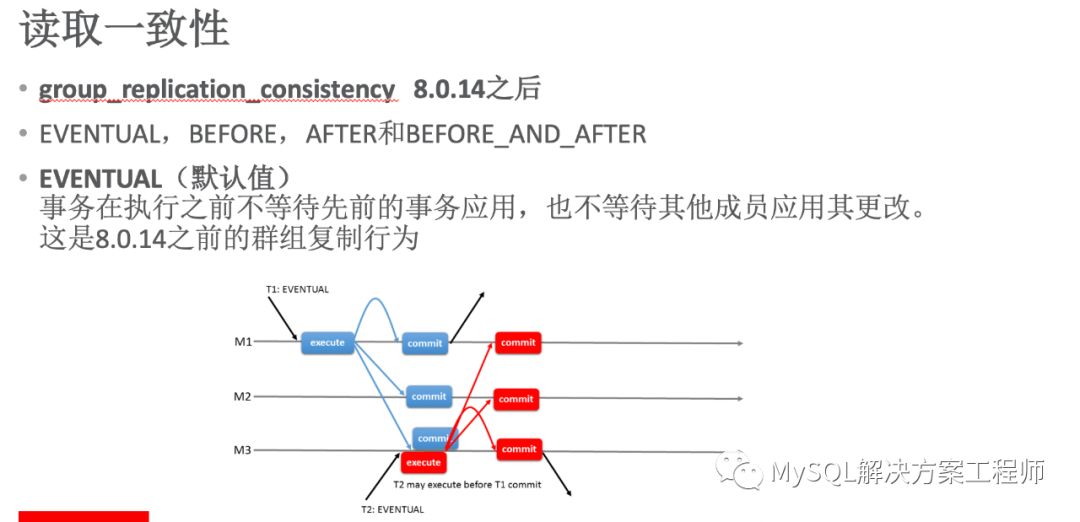
默认的值为 EVENTUAL(最终一致),如上图所示,事务T1开始在M1上执行,之后会将日志传播到M2 M3,并对日志内容进行施放。在日志内容施放到M3之前,T2开始在M3上执行,因此,T2没有在最新的数据快照基础上执行,如果T2与T1执行的数据没有关联,则可以采取该模式。
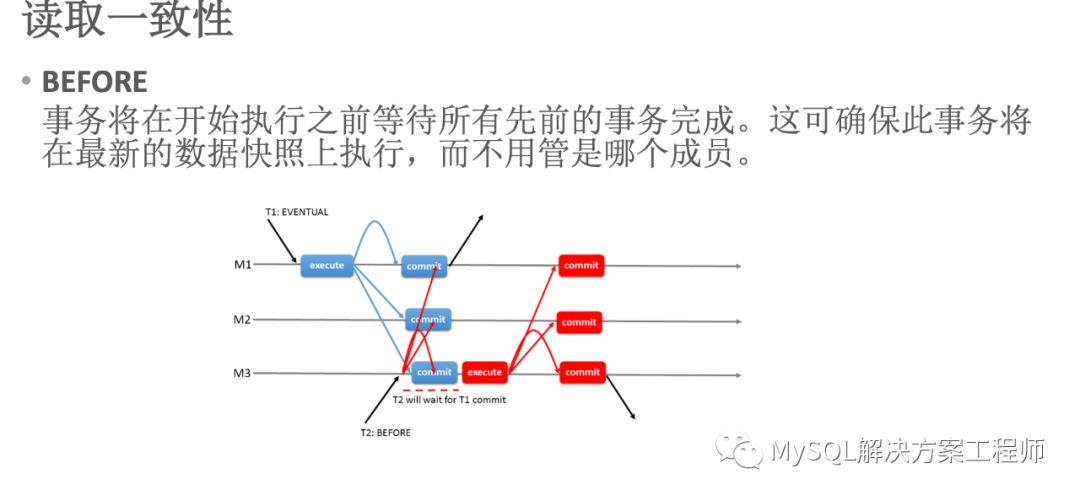
当变量值设置为BEFORE时,上图中 T2使用该值,T2在M3上提交时,需要等待T1在全部成员上执行完毕才可以执行(T2要等待之前的事务BEFORE在全部成员上执行完毕)
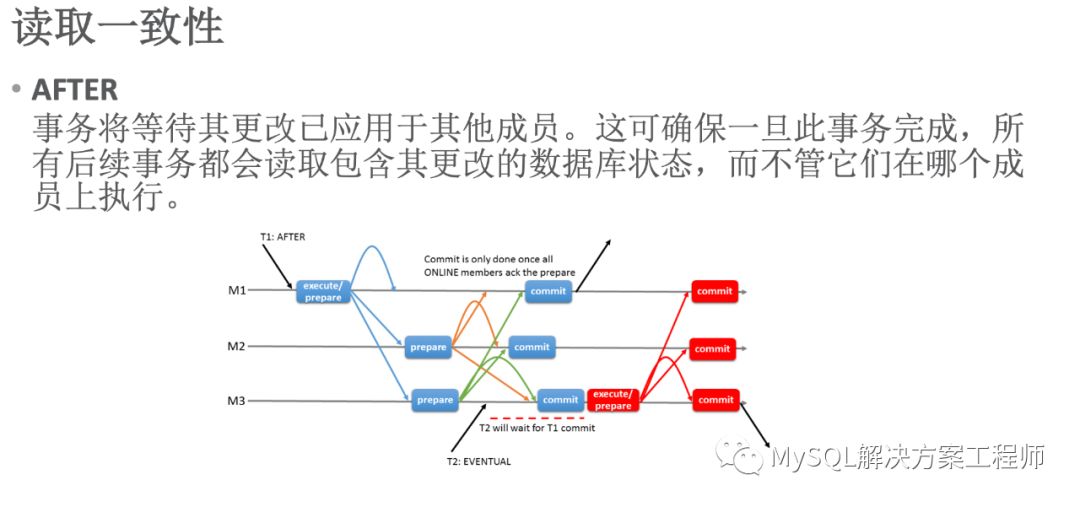
当变量值设置为AFTER时,上图中 T1使用该值,T2在M3上提交时,需要等待T1在全部成员上执行完毕才可以执行(T1事务在全部成员上执行完毕后,后面的事务(AFTER)才可以执行)
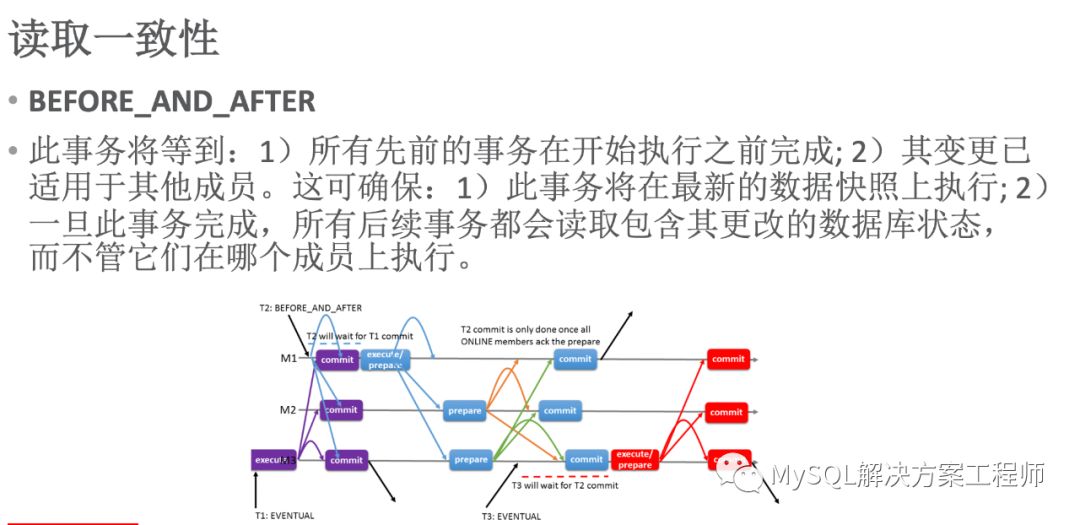
如果事务执行需要确保执行前后都使用最新的数据快照,则可以设置为BEFORE_AND_AFTER。
MySQL Shell

接下来介绍一下MySQL Shell。Shell 是MySQL团队打造的一个统一的客户端,它可以对MySQL执行数据操作和管理。它支持通过JavaScript,Python,SQL对关系型数据模式和文档型数据模式进行操作。使用它可以轻松配置管理 InnoDB Cluster。

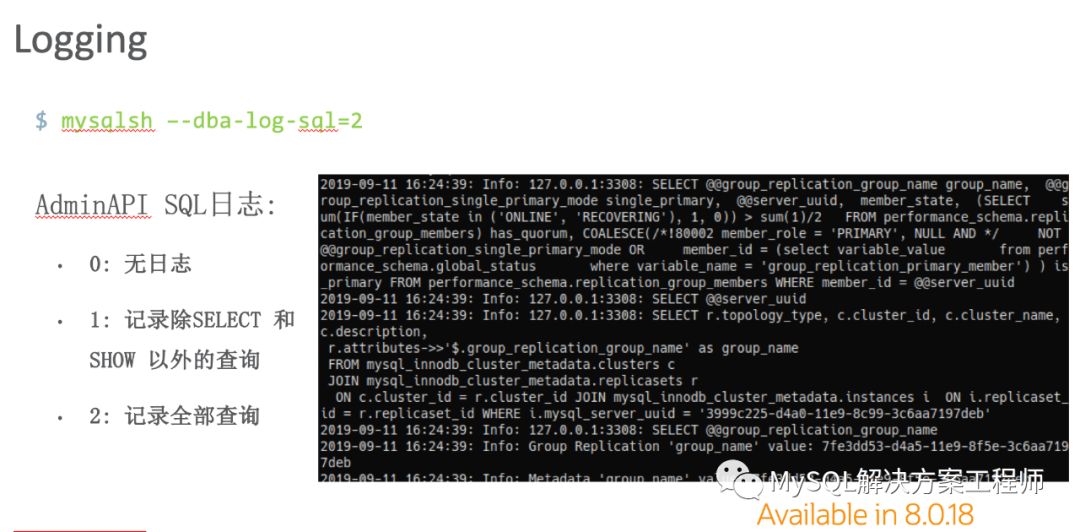
MySQL Shell里集成了一个特殊的管理API,可以通过它执行DBA常见的操作,后面会有一个详细的使用例子介绍给大家。
MySQL Router

MySQL Router是一个轻量级的中间件,可以提供负载均衡和应用连接的故障转移。它是MySQL团队为MGR量身打造的,通过使用Router 和 Shell,用户可以利用MGR实现完整的数据库层的解决方案。如果您在使用MGR,请一定配合使用Router和Shell,您可以理解为它们是为MGR而生的,会配合MySQL的开发路线图发展的工具。
InnoDB Cluster管理
让我们看一下如何对InnoDB Cluster进行管理,我将会通过使用MySQL Shell为您展示相关内容。

使用MySQL Shell创建集群
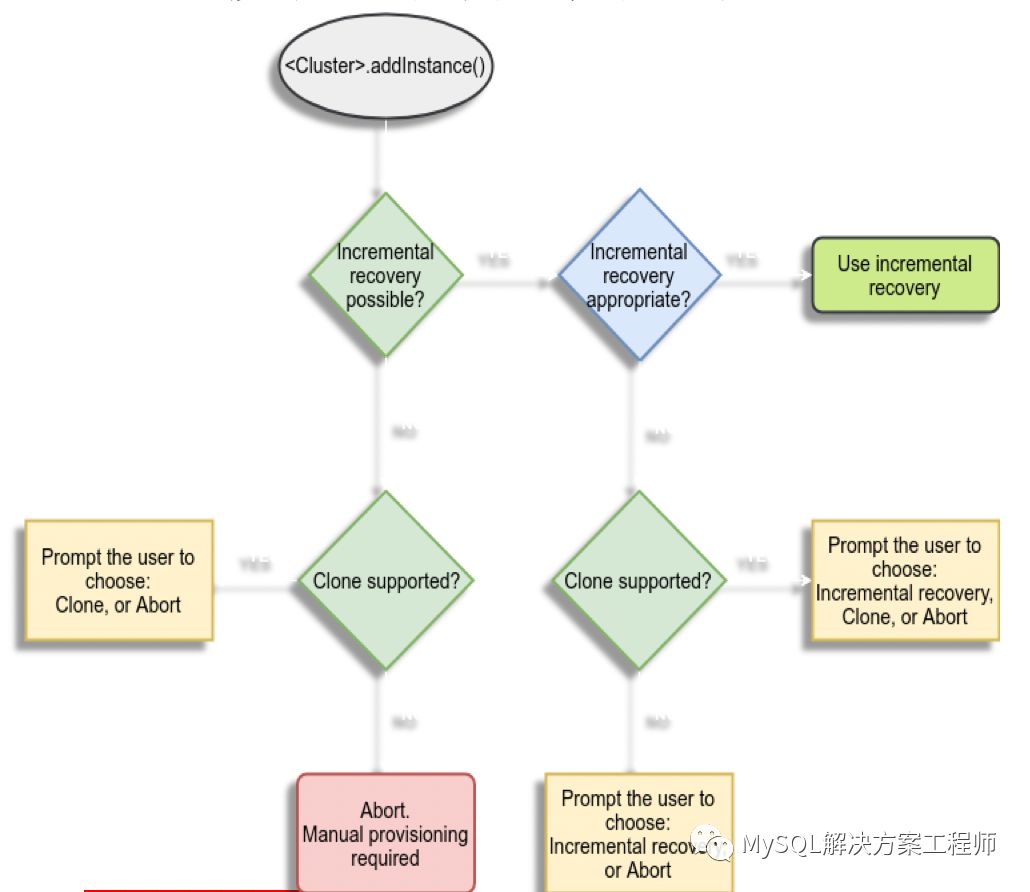
首先执行了配置检查,之后连接到mysql1:3306,然后执行dba.createCluster()就可以创建一个集群,最后执行cluster.addInstance()就可以将其它成员加入到集群。使用起来是不是很简单?接下来是关于集群配置:

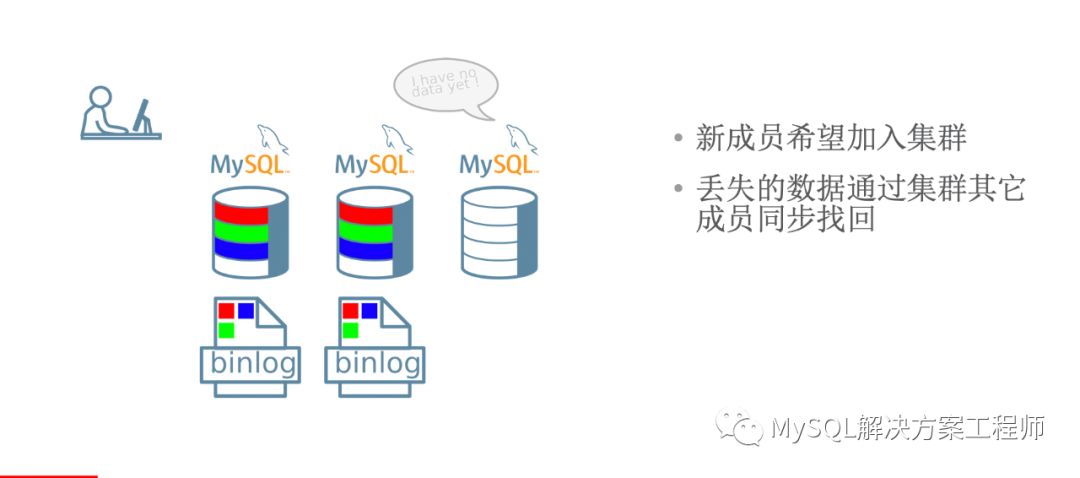
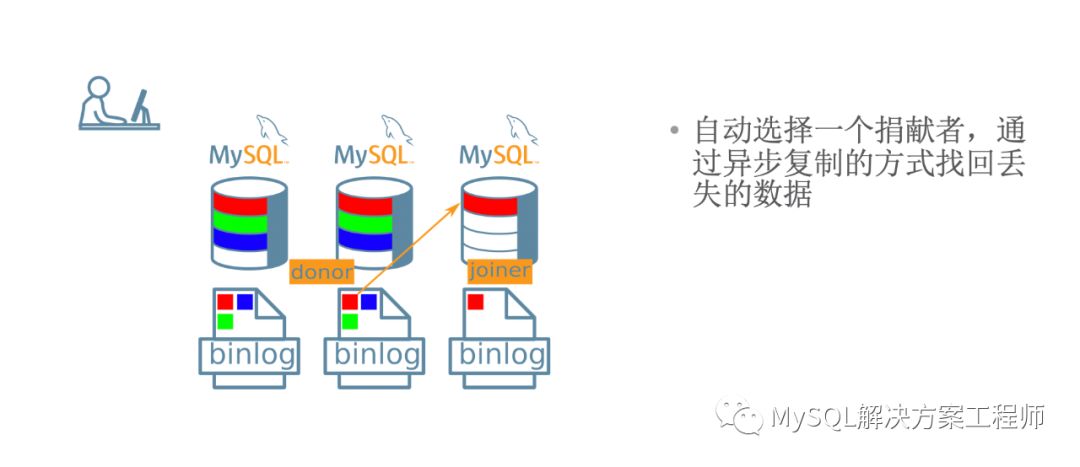
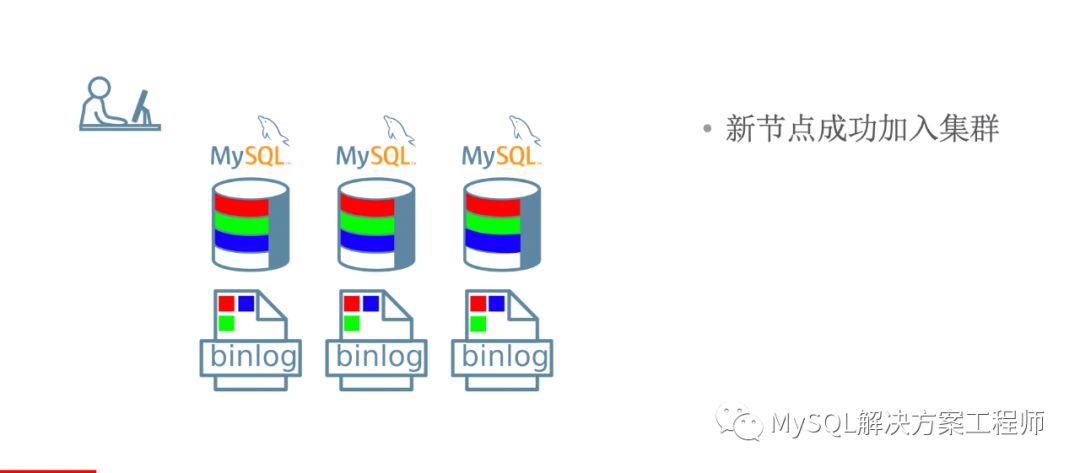
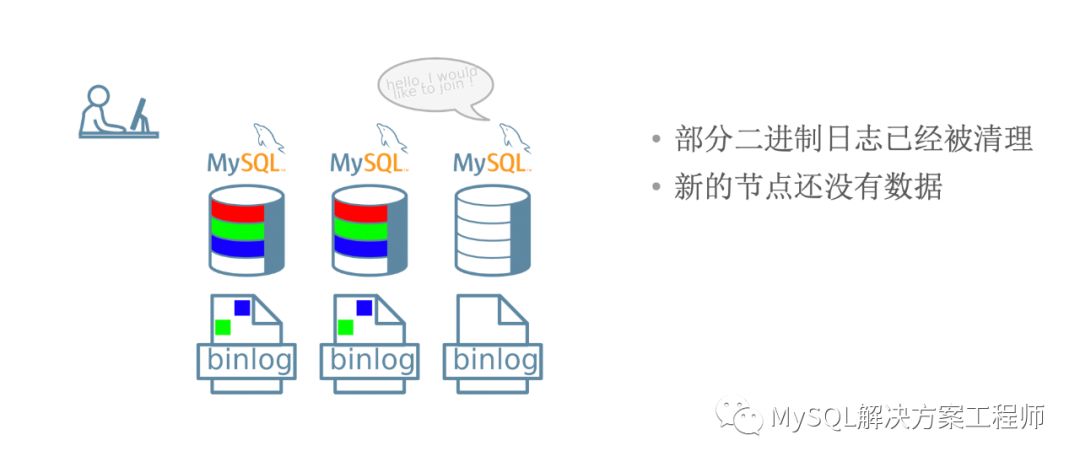
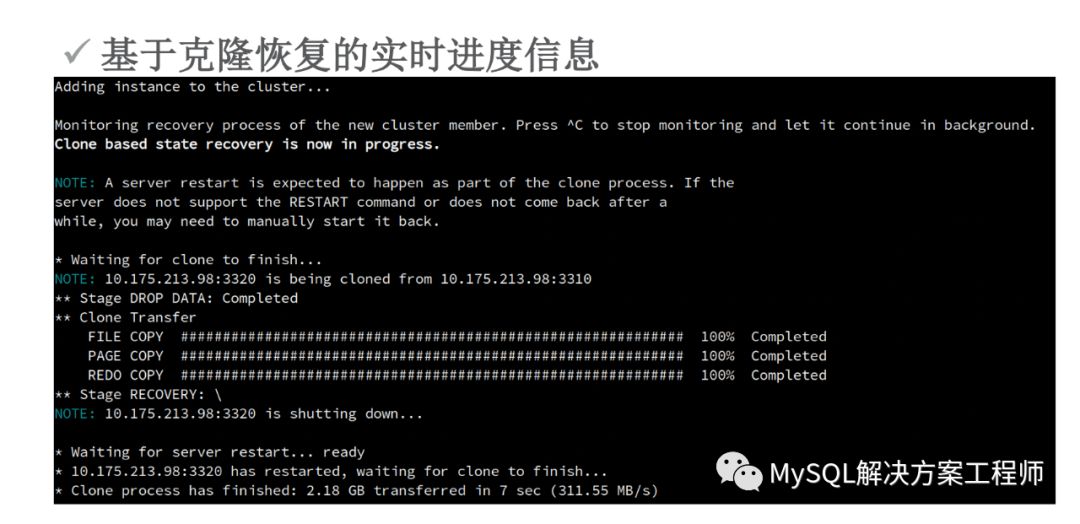
当新成员加入集群时,如果有缺失的事务,将会进行分布式恢复。
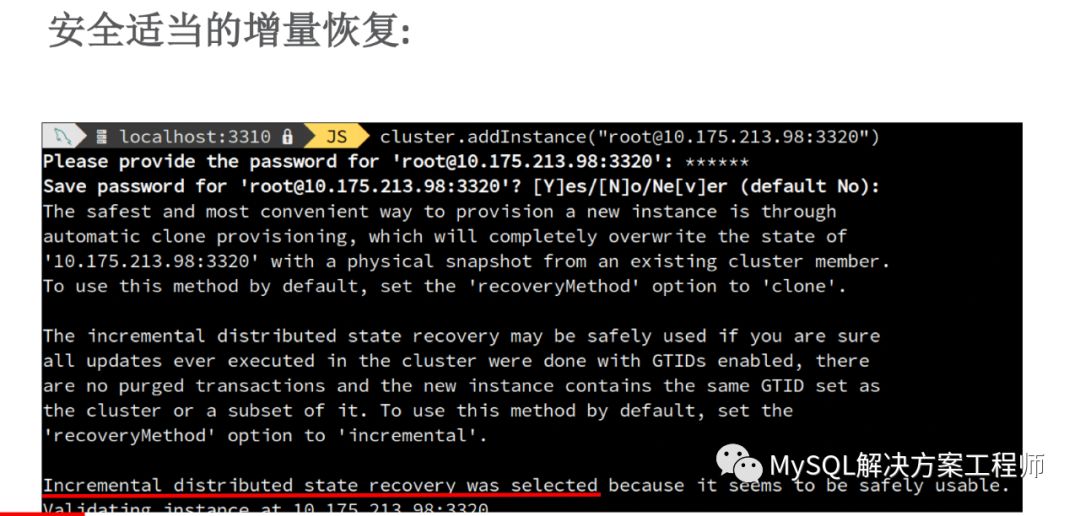
 恢复时,可以采用增量恢复:
恢复时,可以采用增量恢复:




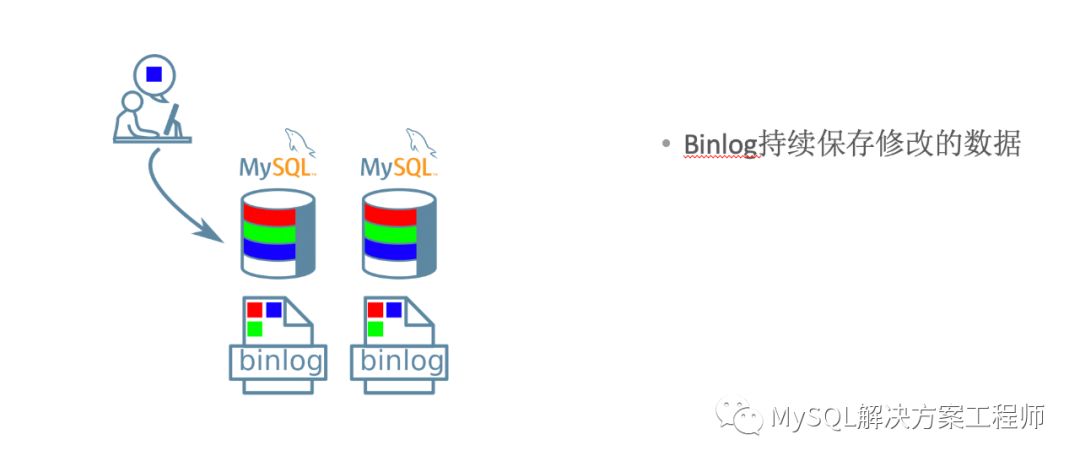
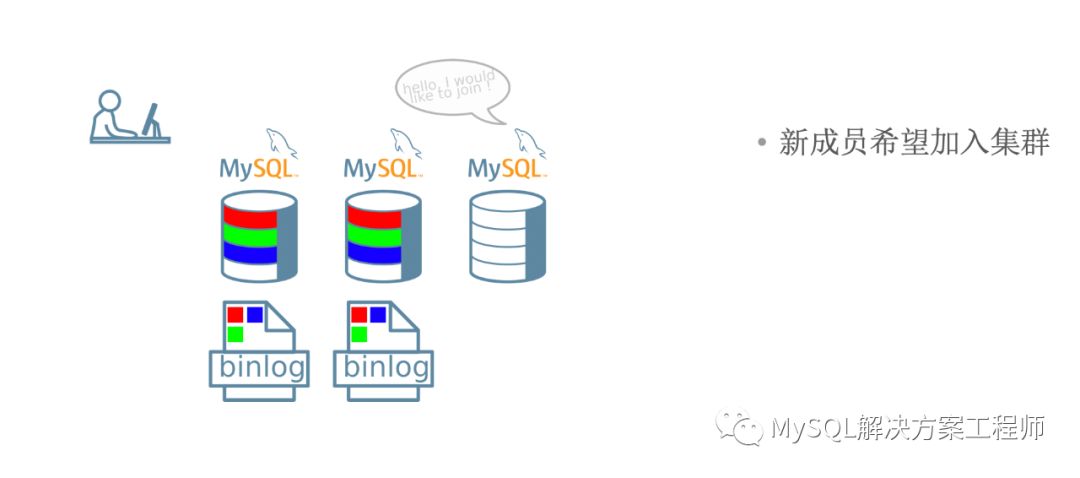
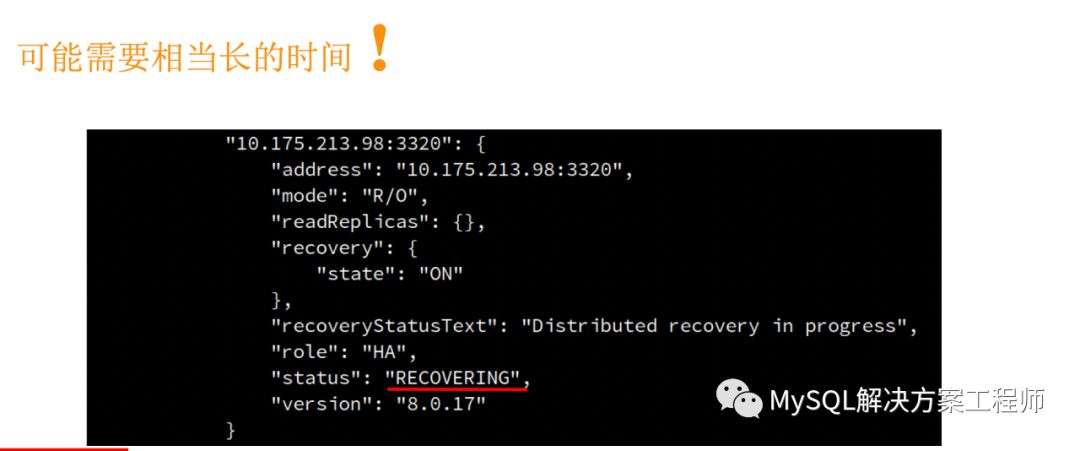
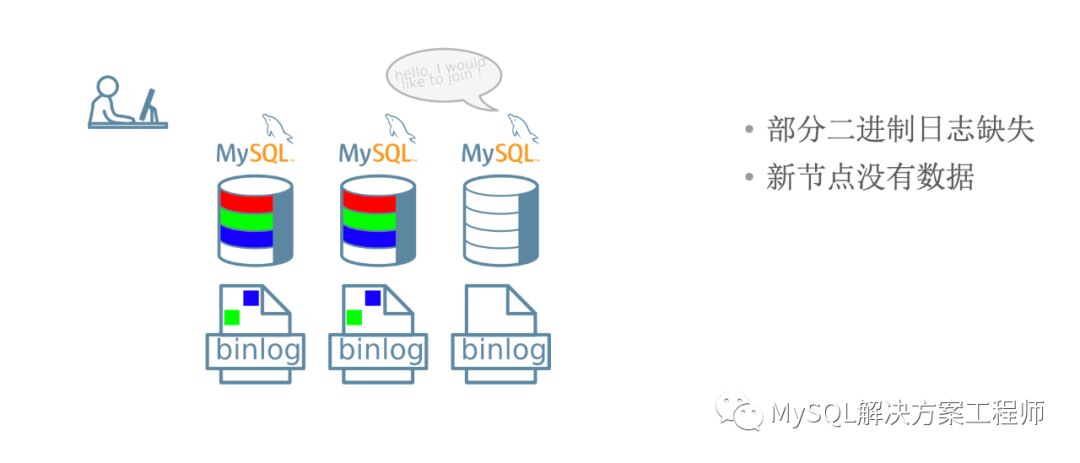
增量恢复可能会需要相当长的时间,并且当群组无法提供全部的binlog时,无法进行恢复。
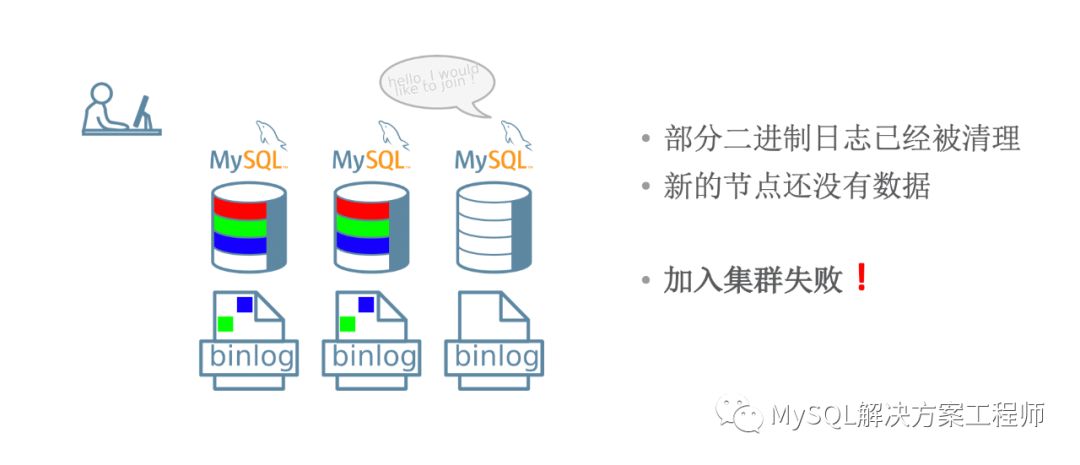
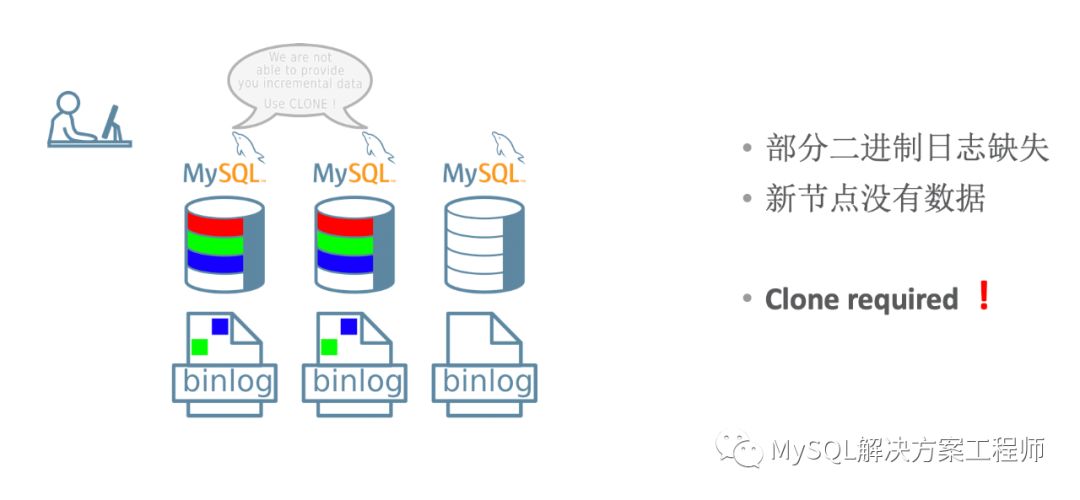
幸好我们有克隆插件!



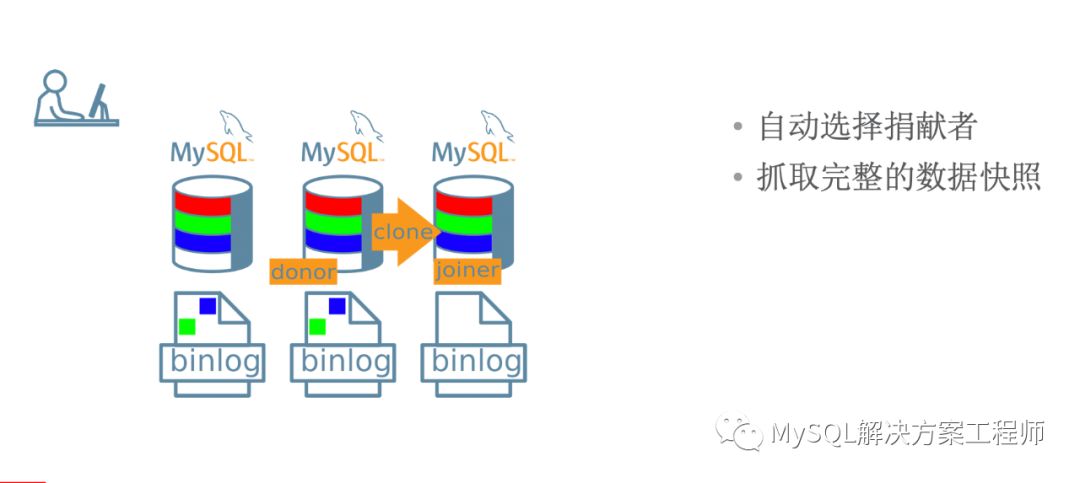
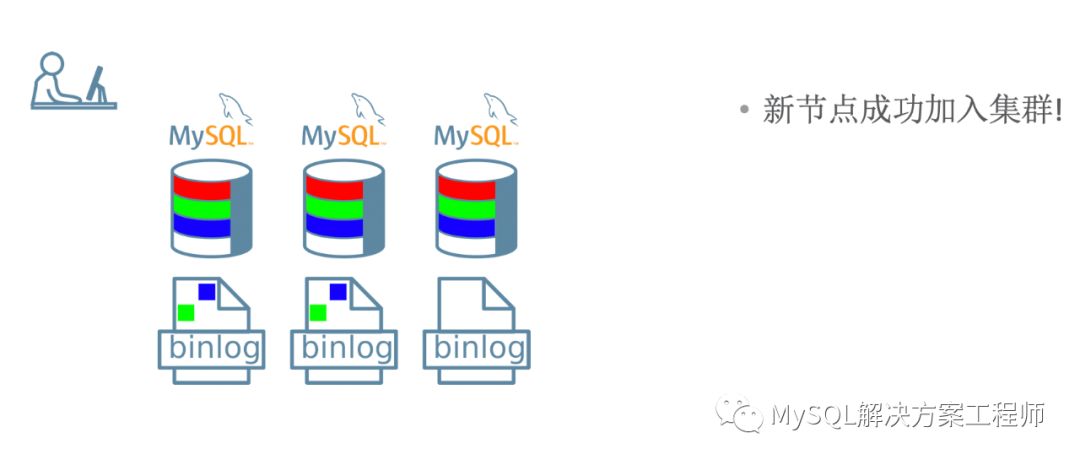
那么应该选择使用哪种方式进行部署呢?
增量恢复:
至少一个成员可以提供给新节点相同的已处理的事务集。
新节点不存在异于集群的事务
增量恢复适用于:
事务未被清理
新节点不包含空的GTID集
启用GTID 和二进制日志



创建配置集群之后,介绍一下监控。

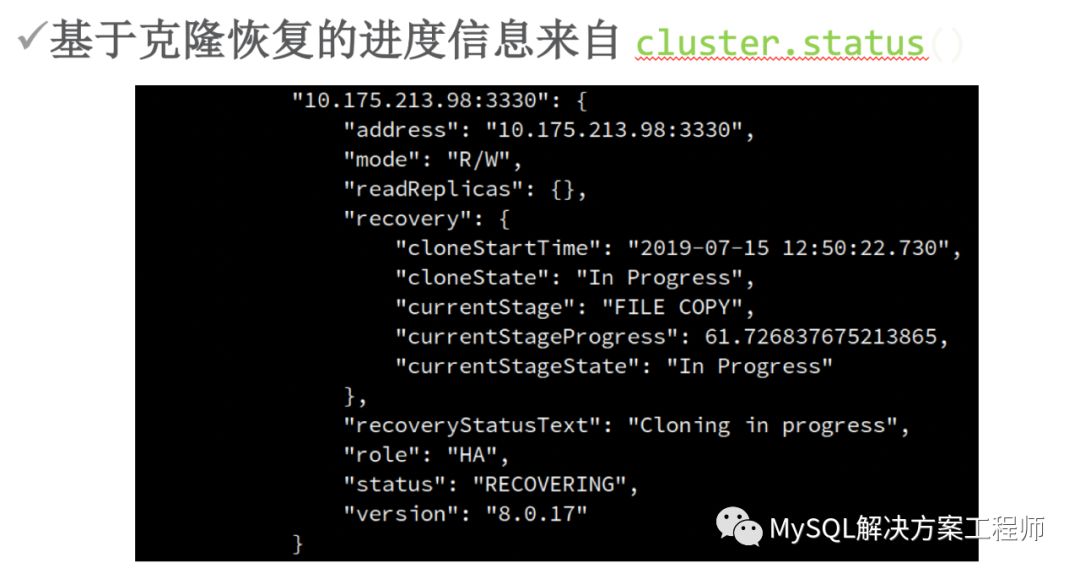
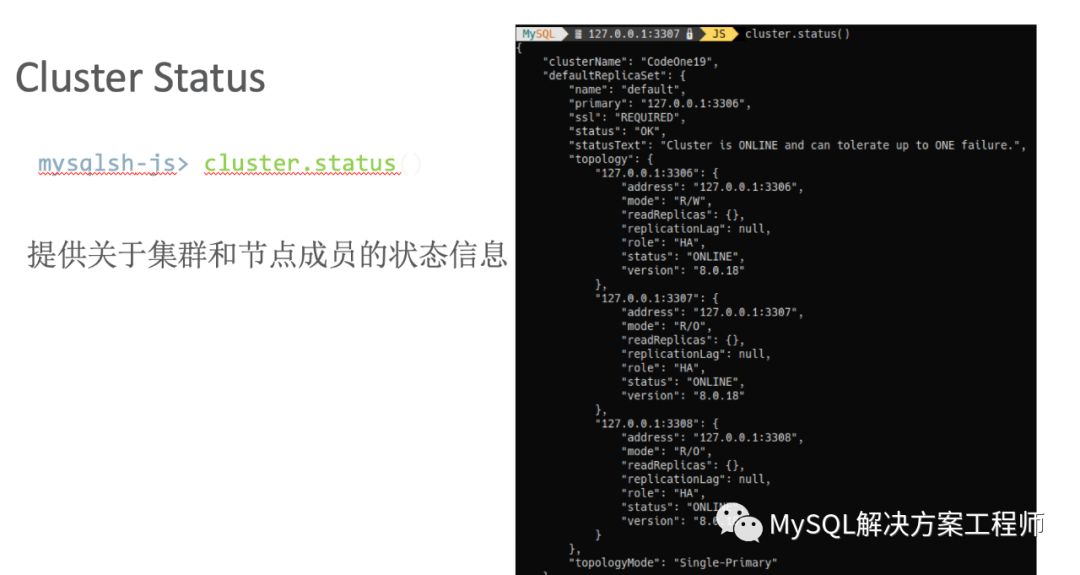
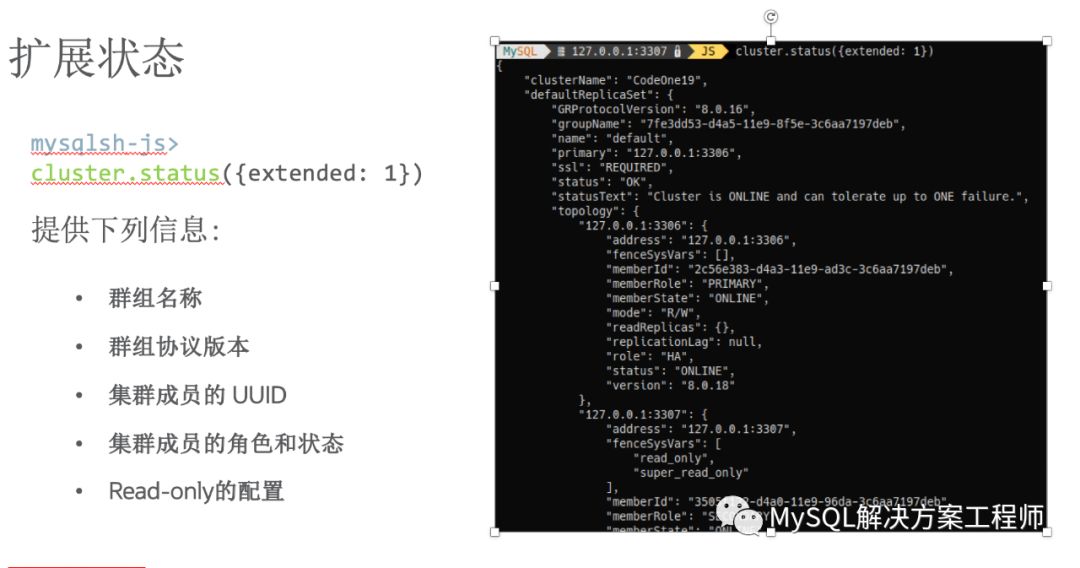
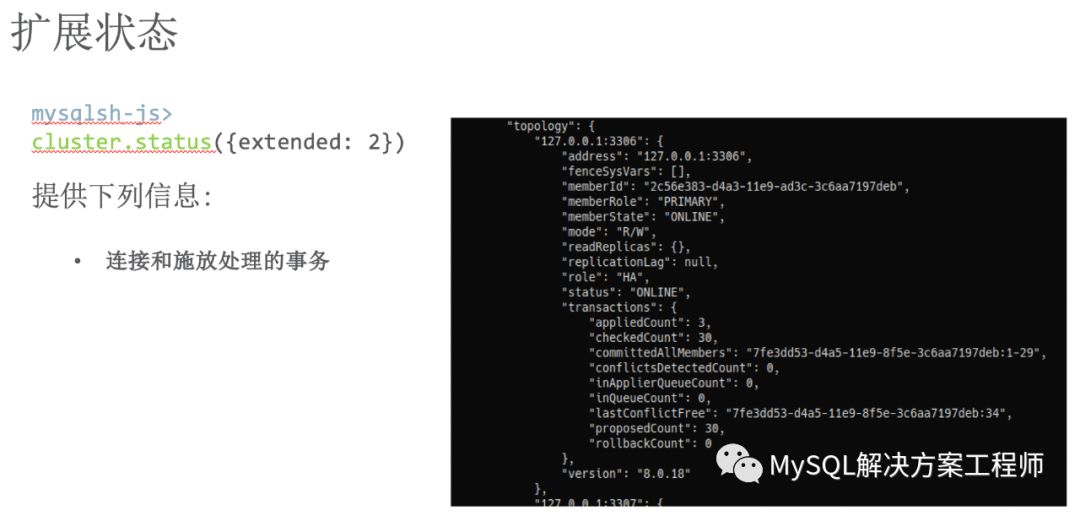

此外,Shell还提供了一个报表框架,并且支持用户自定义报表

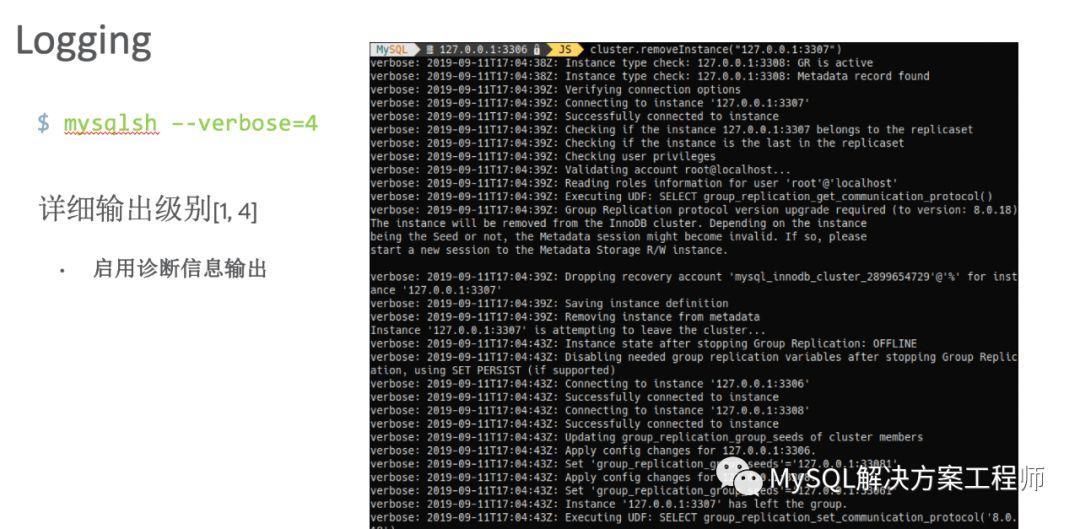
最后,介绍一下集群的维护和故障排除。

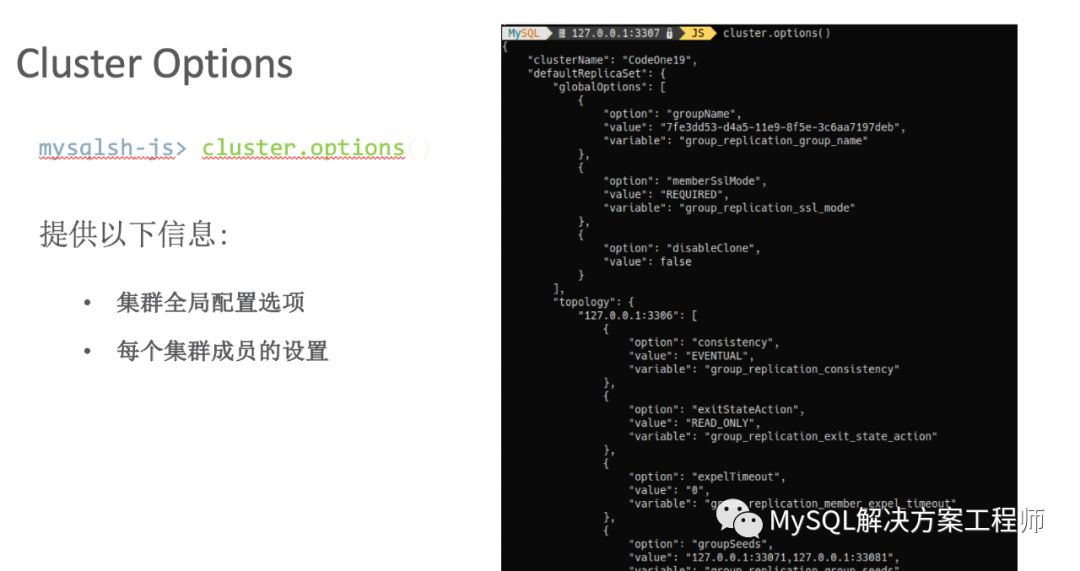



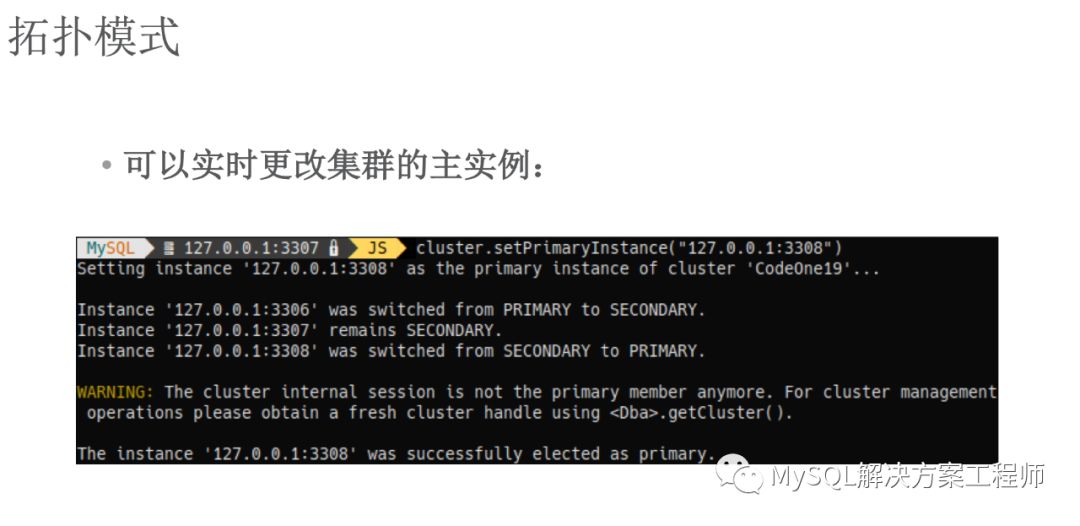

“任何可能出错的地方都会出错。”
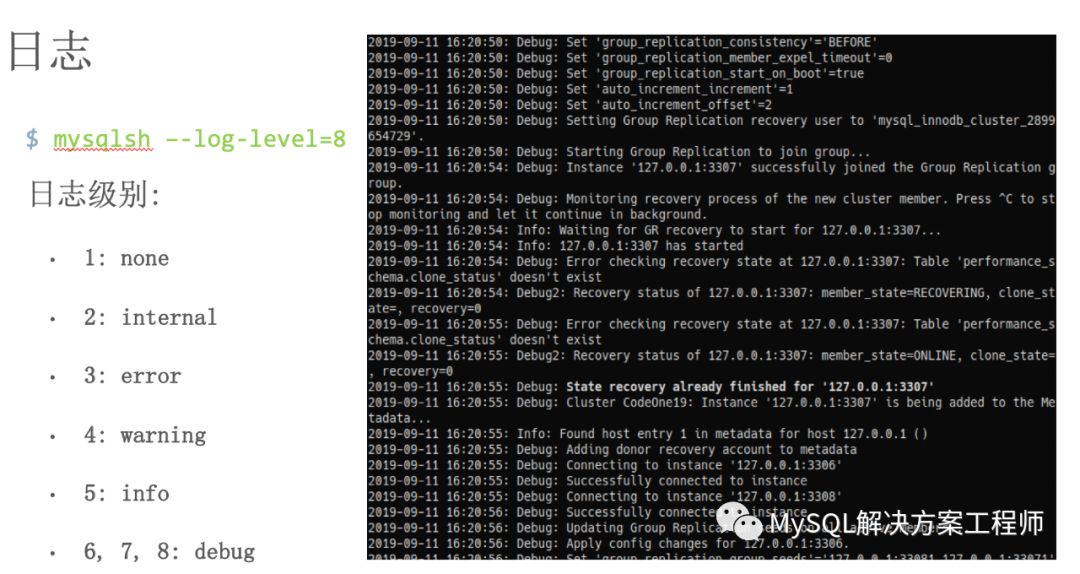
默认情况下,Shell为用户提供了有价值的信息。但是有时需要更多信息来进行故障排除...
总结:
•InnoDB cluster 是MySQL内置的高可用解决方案
•MySQL Clone插件将InnoDB集群的可用性提升到了一个全新的高度!
InnoDB Cluster功能内置了对完整实例配置的支持
•MySQL Shell是开发人员和DBA的统一接口以及InnoDB Cluster的前端管理器
本文比较长,能看完的都是真爱!感谢阅读!
感谢关注MySQL!
