




人工智能取得了前所未有的发展,机器学习、深度学习中算法数量也在不断的增加。但是也带来了很多的问题:
特征分析和变换中,工作量大、性能差、成本高等;
难以处理超高维稀疏数据,超规模参数调优难度很大;
目前业界实现的机器学习平台都有各种各样的问题,例如和Hadoop生态圈衔接较差,无法很好的与其衔接起来。这些问题一直阻碍着开发者的前行,亟需解决。
针对超大规模机器学习的场景,360开源了内部的超大规模机器学习计算框架XDML。
 |
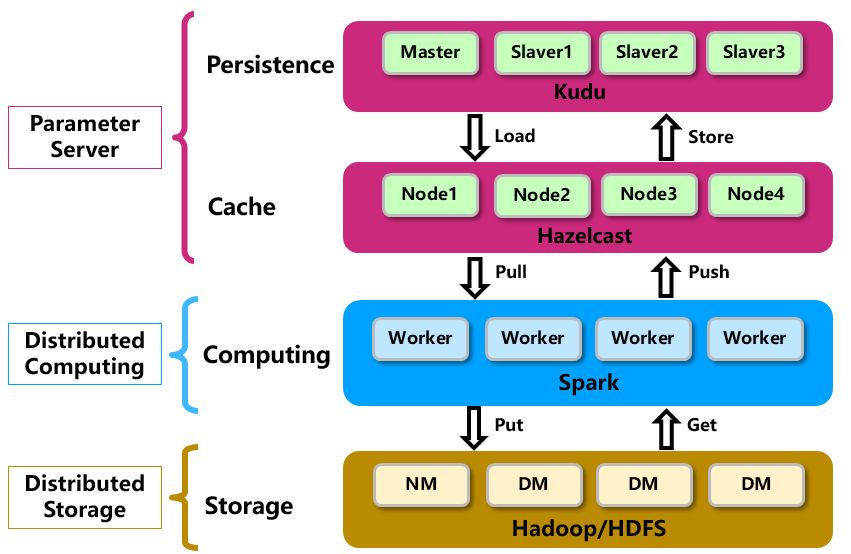
XDML是一款基于参数服务器(Parameter Server),采用专门缓存机制的分布式机器学习平台。它在360内部海量规模数据上进行了测试和调优,在大规模数据量和超高维特征的机器学习任务上,具有良好的稳定性,扩展性和兼容性。
GitHub地址:
https://github.com/Qihoo360/XLearning-XDML
|
|
提供特征分析与变换等功能模块
在现有的机器学习模型的构建中,特征生产与业务和数据高度相关,高度定制,工作量很大。特征分析与变换处理粒度过小,在大数据情形下性能较差,且缺乏一站式的特征分析与变换工具。XDML能够最大程度地挖掘并行度,结合样本并行+特征并行+算子并行/融合/OnePass化,显著提升特征工程的性能,支持TB级数据10min级分析,并且遵循spark标准接口。在包含数千个特征的稠密benchmark上进行特征分析与变换测试,性能较Spark MLlib提升1000多倍;XDML也能很好地适应稀疏数据特征分析。
实现常用的大规模数据量场景下的机器学习算法
超高维度的参数优化,对于开发者算法能力要求较高,而且工作量较大,需要大量的时间和精力进行调参工作。XDML内化学界最新研究成果,引入南京大学李武军老师提出的全新优化算法SCOPE,并重构了准线性模型,在效果保持稳定的同时,大幅加速收敛进程,显著提升模型与算法的性能。在Benchmark上,相比LBFGS性能提升10倍左右,相较于SGD性能提升50多倍。同时,XDML还对接了一些优秀的开源成果和360公司自研成果,站在巨人的肩膀上,博采众长。
充分利用现有的成熟技术,保证整个框架的高效稳定
在互联网领域,技术框架更新迭代十分迅速,XDML可以与业界成熟的技术无缝衔接,整个框架具有高效的稳定性。
完全兼容hadoop生态,和现有的大数据工具实现无缝对接,提升处理海量数据的能力
在XDML设计之初,就将与Hadoop生态无缝衔接作为其设计目标,解决了大规模高维数据的存储。XDML具有与目前Hadoop、Spark等大数据框架无缝对接的能,同时替换Spark原生能力的性能/效果瓶颈,提供更好的大数据框架使用体验,将开发者从繁杂的工作中解脱出来,不必为数据、模型的存储大费周章。
在系统架构和算法层面实现深度的工程优化,在不损失精度的前提下,大幅提高性能
在高维稀疏数据场景中,如何处理千亿级参数训练,百亿乃至千亿级别样本训练中模型的存储、数据如何传输、模型的更新等问题一直是业界急需解决的问题。XDML具有模型的快速存储能力,高效的数据传输,从多个角度提升了高维稀疏数据场景中,提升模型的训练速度提升整体的性能。
结语
“从开源社区来,并回到开源社区去”一直是开源社区的精神。360此次开源的内部超大规模机器学习计算框架XDML,能够为开发者节约学习和操作时间,提高模型训练效率,具有良好的稳定性和兼容性,为开源社区提供了一件利器。
GitHub地址(可点击阅读原文查看):
https://github.com/Qihoo360/XLearning-XDML
QQ交流群:
界世的你当不
只作你的肩膀
无


360官方技术公众号
技术干货|一手资讯|精彩活动
空·
