





架构
一起来看 Kafka 的架构。
先结合架构图来了解 Kafka 中的几个概念。
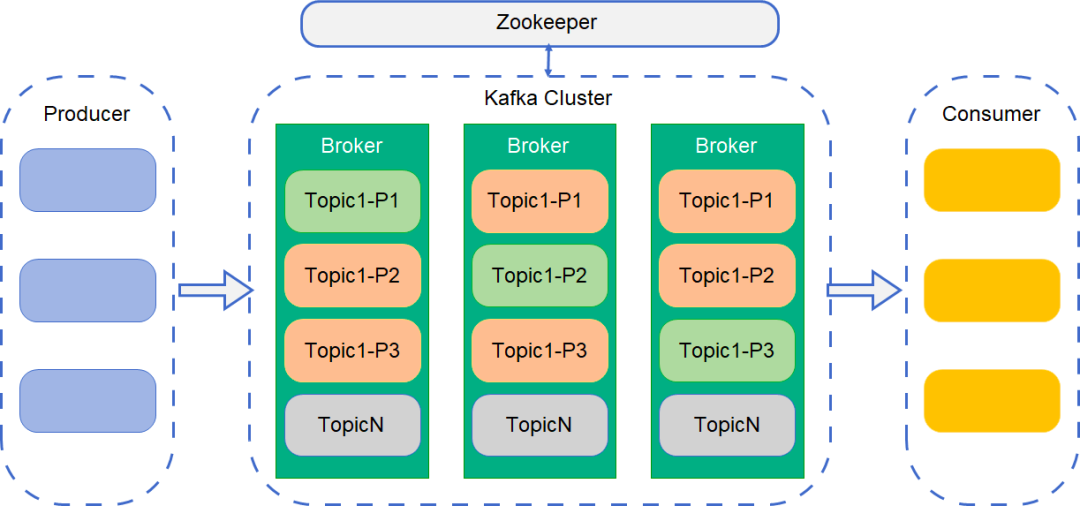
首先 Kafka 消息队列由三个角色组成。
消息的生产方 Producer 中间是 Kafka 集群, Kafka 集群由多台 Kafka server 组成,每个 Server 称为一个 Broker,也就是消息代理 右面的是消息的消费方 Consumer
Kafka 中的消息是按照 Topic 进行划分的,一个 Topic 就是一个 Queue。
在实际应用中,不同业务数据可以设置为不同的 Topic,一个 Topic 可以有多个消费方,当生产方在某个 Topic 发出一条消息后,所有订阅了这个 Topic 的消费方都可以收到这条消息。
为了提高并行能力,Kafka 为每个 Topic 维护了多个 Partition,即分区。每个分区可以看作一份追加类型的日志。每个分区中的消息保证 ID 唯一且有序,新消息不断追加到尾部。
Partition 实际存储数据时,会对按大小进行分段(Segment),来保证总是对较小的文件进行写操作,提高性能,方便管理。
如上图的中间部分,Partition 分布于多个 Broker 上。图中绿色的模块表示 Topic1 被分为了 3 个 Partition,每个 Partition 会被复制多份存在于不同的 Broker 上,如图中红色的模块,这样可以保证主分区出现问题时进行容灾。每个 Broker 可以保存多个 Topic 的多个 Partition。
Kafka 只保证一个分区内的消息有序,不能保证一个 Topic 的不同分区之间的消息有序。
为了保证较高的处理效率,所有的消息读写都是在主 Partition 中进行,其他副本分区只会从主分区复制数据。Kafka 会在 ZooKeeper 上针对每个 Topic 维护一个 ISR(in-sync replica),就是已同步的副本集。如果某个主分区不可用了,Kafka 就会从 ISR 集合中选择一个副本作为新的主分区。
消息发布/消费流程
Kafka 通过对消费方进行分组管理来支持消息一写多读,流程如下图所示。
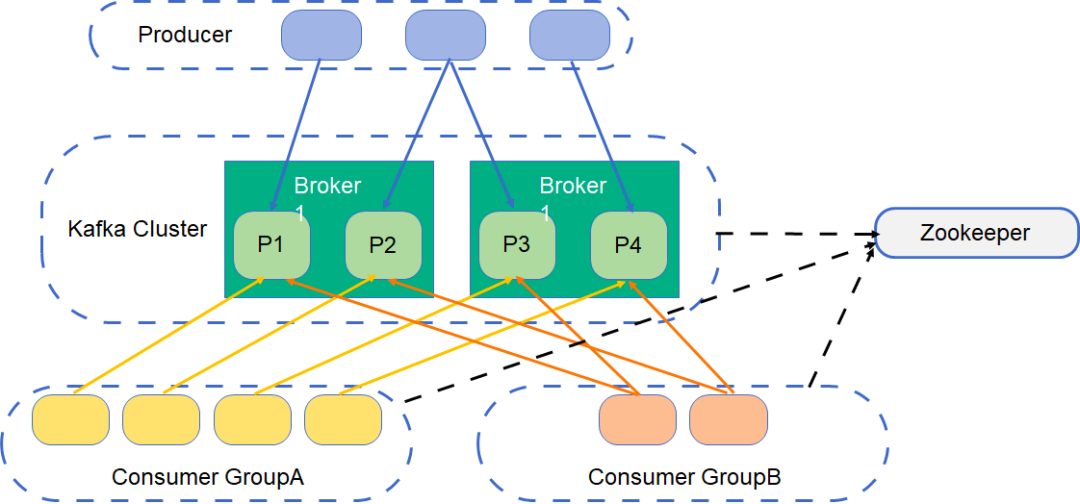
来看图中的例子,这个 Topic 分为 4 个 Partition,就是图中绿色的 P1到 P4。
消息发布
消息的发送有三种方式:同步、异步以及 oneway。
同步模式下后台线程中发送消息时同步获取结果,这也是默认模式。
异步的模式允许生产者批量发送数据,可以极大的提高性能,但是会增加丢失数据的风险。
oneway 模式只发送消息不需要返回发送结果,消息可靠性最低,但是低延迟、高吞吐,适用于对可靠性要求不高的场景。
消息消费
Consumer 按照 Group 来消费消息,Topic 中的每一条消息可以被多个 Consumer Group 消费,如上图中的 GroupA 和 GroupB。
Kafka 确保每个 Partition 在一个 Group 中只能由一个 Consumer 消费,通过 Group Coordinator 来管理 Consumer 实际负责消费哪个 Partition,默认支持 Range 和轮询分配。
Kafka 在 ZK 中保存了每个 Topic 中每个 Partition 在不同 Group 的消费偏移量 offset,通过更新偏移量保证每条消息都被消费。
注意:用多线程来读取消息时,一个线程相当于一个 Consumer 实例。当 Consumer 的数量大于分区的数量的时候,有的 Consumer 线程会读取不到数据。
老哥们,分享、点赞、在看一条龙!
推荐阅读:
关注我

