




Rule Based Attributing, a.k.a RBA,是一种基于简单规则对时序数据变化进行预警和主因追溯的方法。目标是通过代码自动地执行统计学方法检验数据的合理性和对非合理变动进行主要原因的查找。本文将简要介绍RBA方法的原理和实践。
01 阈值设定
通常时间序列都可以表示为基于时间的函数,
那么相邻时间内的差值表示为,
从业务场景上讲,根据其应用领域,可以表示为产品销售额、水库蓄水量、仓库库存、资产规模等等在时间轴上的变化量。
对于给定的一个
以https://www.kaggle.com/kyanyoga/sample-sales-data的销售数据为例,绘制出
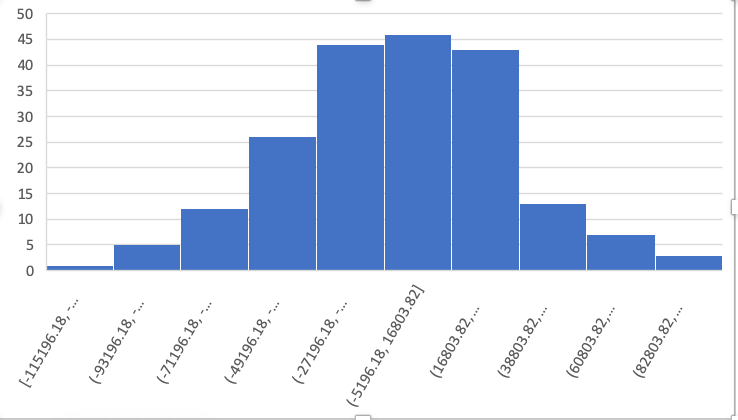
即使在日期不连续的情况下,基本上差值的分布还是在大致钟型曲线的范围内,所以可以尝试使用正态分布的95%边界作为判断异常的阈值:
这里对统计分布方式的判定比较粗糙,科学的方式需要使用假设检验判定此分布是否为真,可参考https://mp.weixin.qq.com/s/B0m4wzGE4Xmi4AbWrCyQtg使用Scipy模块进行数据的分布验证,确定分布方式后再确定小概率的边界值。
若数据的分布不符合正态分布,可以通过增加用于计算平均值的样本(本例中为日期t的范围),或者根据「大数定理」对
02 异常判定
依照第1小节中的2
这个计算在数据量小的情况下,直接在Excel中即可实现。使用AVERAGE
函数计算当天和过去199天的销售额差值的平均值;使用STDEV.S
函数计算当天和过去199天的销售额差值的样本标准差。随后,计算
在Excel中处理还有一个好处是快速绘制销售额差值同上下边界的在时间维度上的折线图,直观的观察数据异常,如下图。
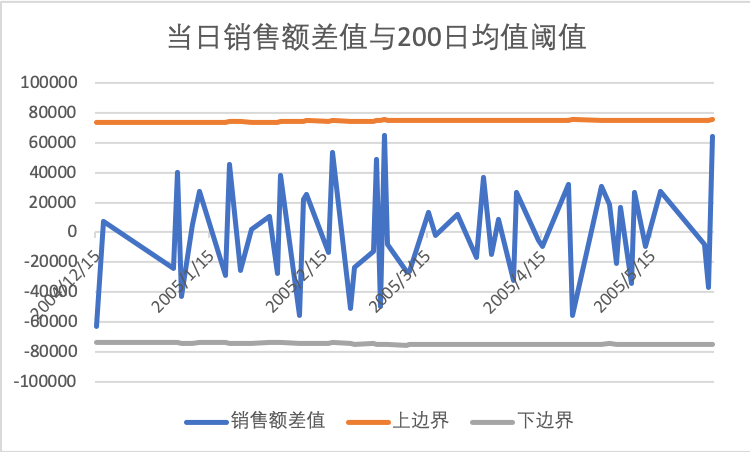
从上图看,在当前的阈值下无异常,如果需要提高阈值的敏感度,减少标准差的乘数即可。比如调节成1.5之后,可以得到超越阈值的多个异常,见下图。
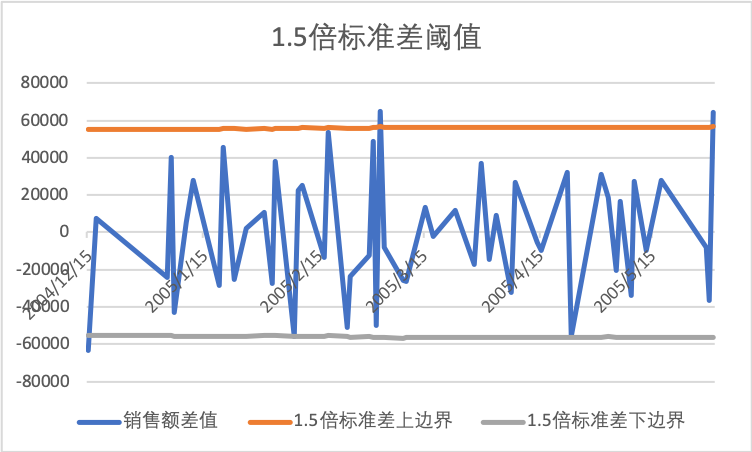
相应的,实际处理过程中,可使用乘数的大小对应不同级别的异常告警级别。
03 异常归因
一旦找到超过阈值的异常点,就可以通过对异常所在点的

在拥有大量维度分组以及分组贡献接近的情况下,使用“肉眼”直观判断的方式就不是那么好用了。此时考虑计算出每一个维度分组值的协方差,某一维度分组值的协方差越大则说明该维度分组值对于总异常的影响更大。此计算过程易于代码实现,方便利用程序实现自动化的主因判断。
不过,实际的判定结果还是要结合具体的业务场景,比如某类产品的销量都是有女性客户贡献,即使该维度下在异常点同样提供最大的协方差,还是需要将该维度原因剔除。因此,除了当日的变动贡献率同时需要考虑单一维度分组在历史上的贡献率。
04 总结
本文提供了一种简化的时序数据的异常检测和归因的方法,并以Kaggle公开数据集为例实践该方法。其拥有以下优势:
便于实现;
易于解释。
但是,对于实际的场景并不能直接套用“最大影响因子即异变原因”的思路,需要考虑特定的业务场景和历史的异常影响因子组成。
