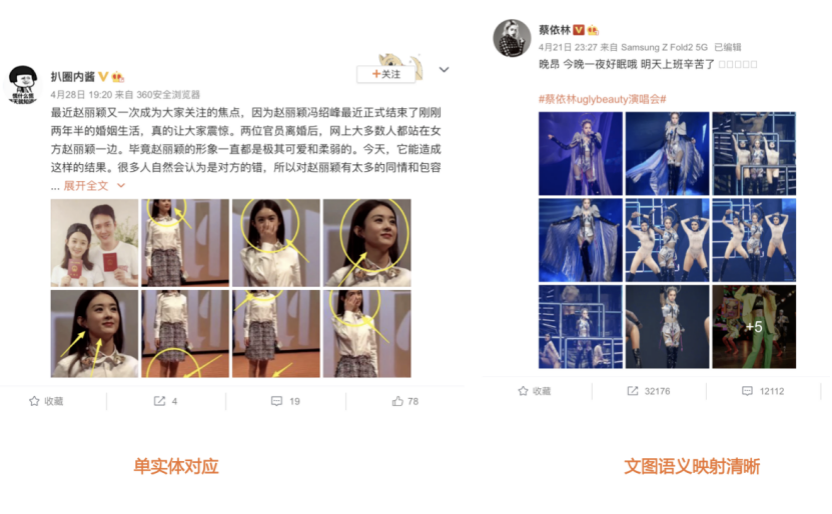
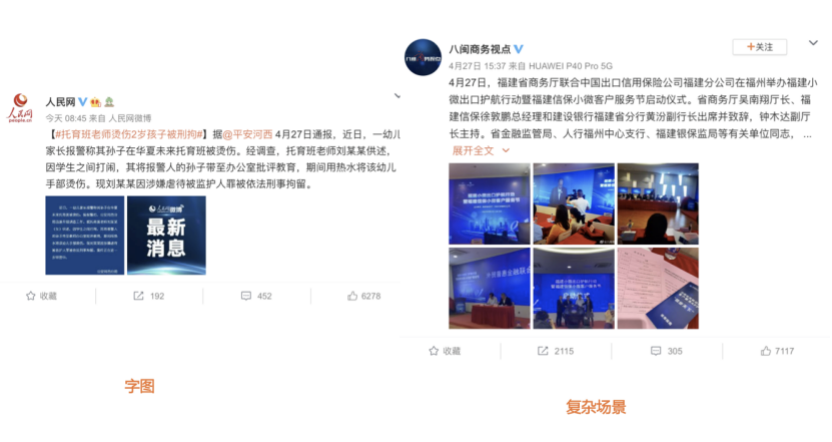
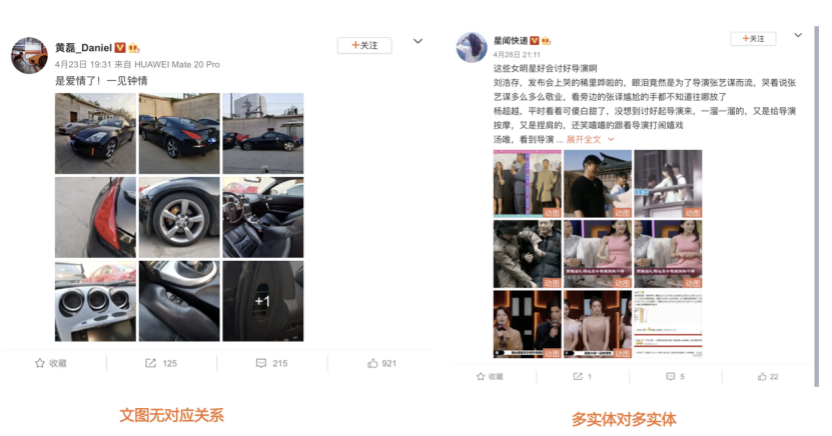
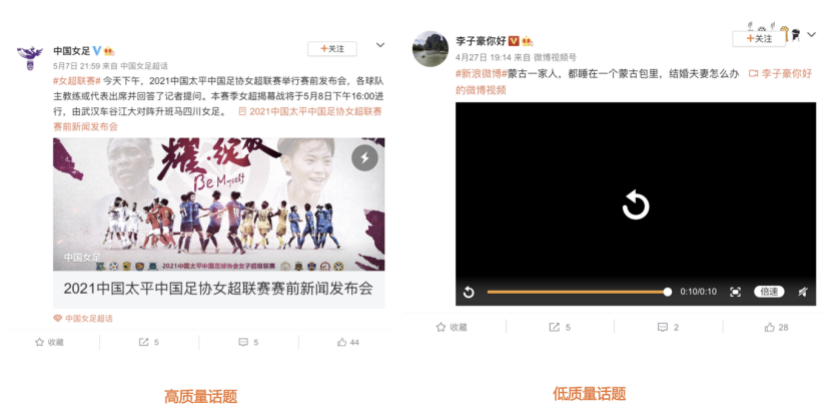
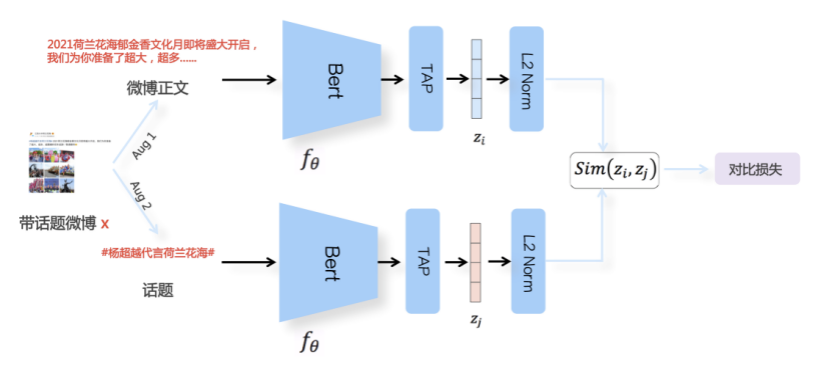
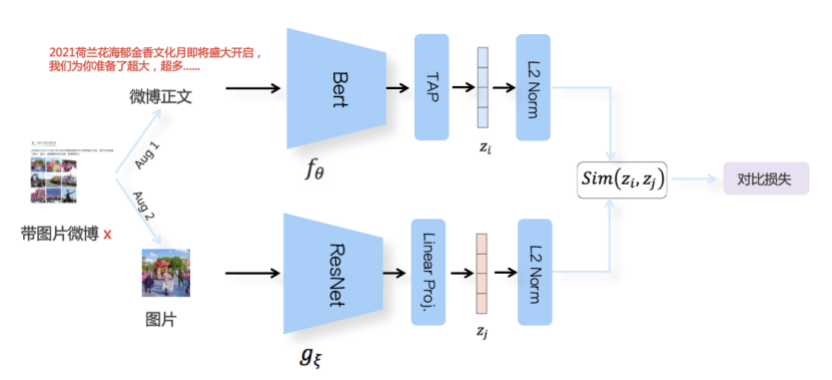
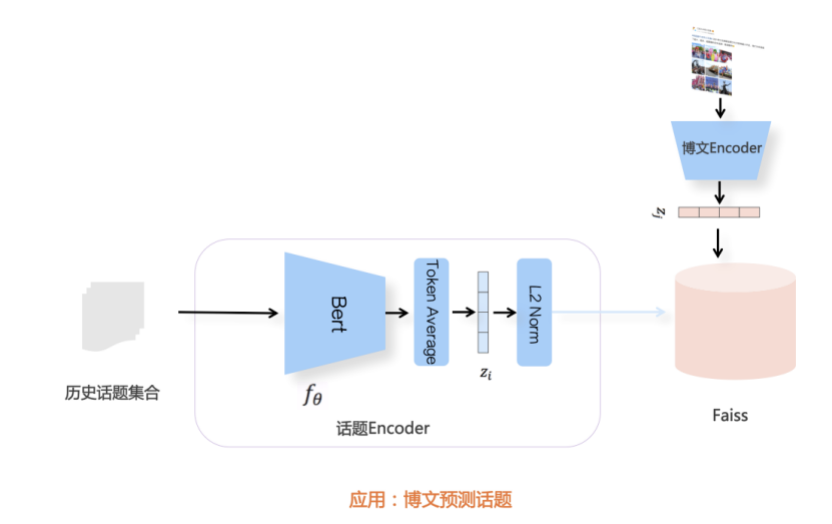
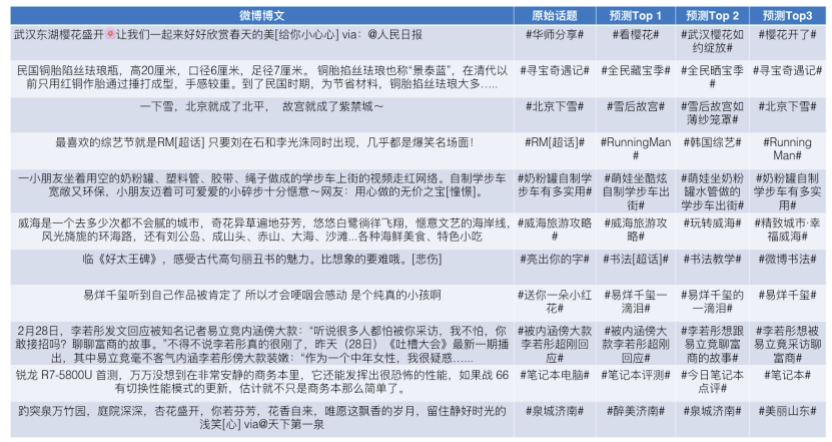
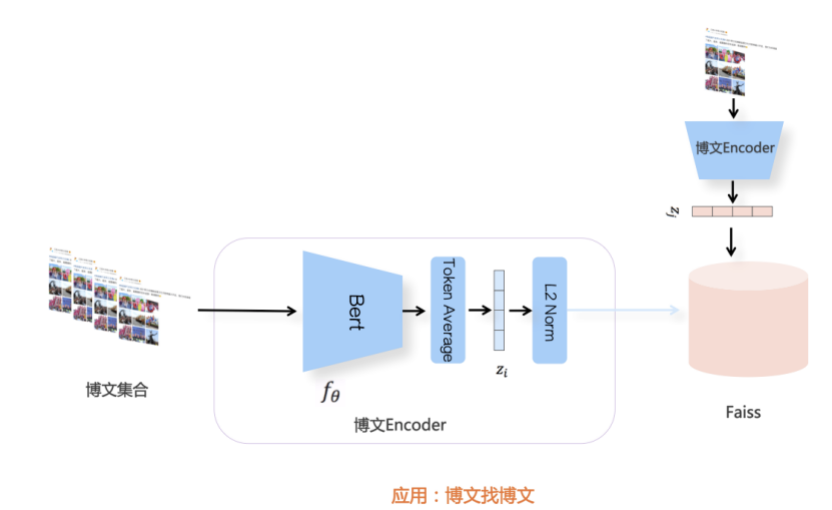
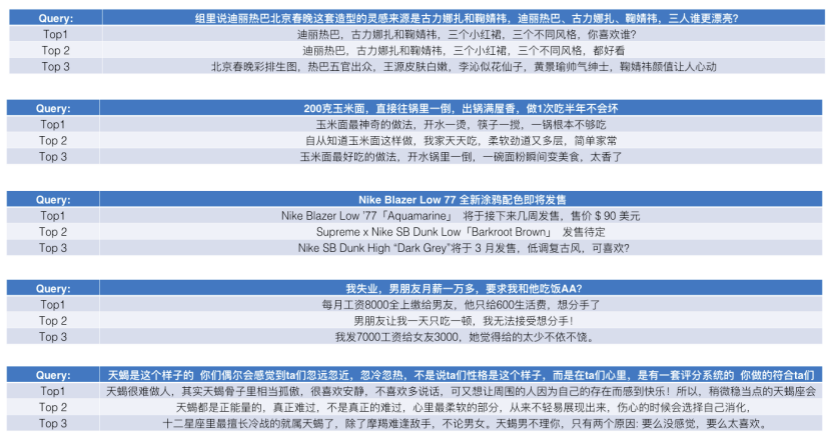
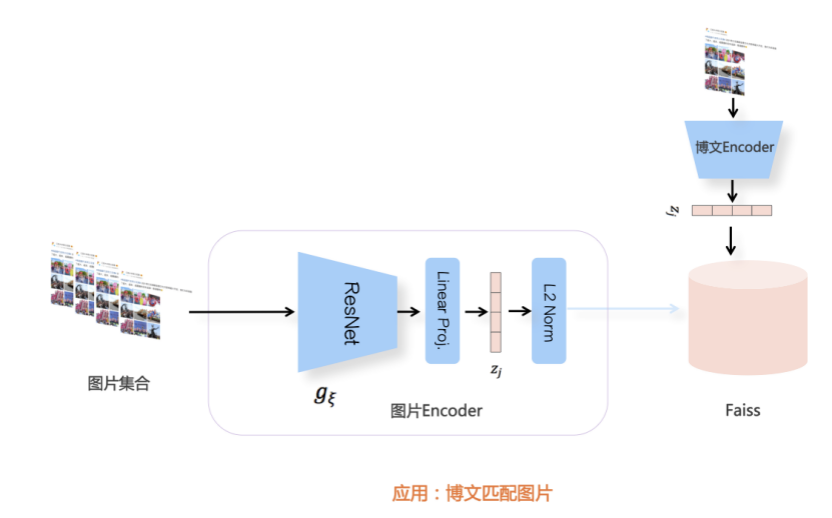
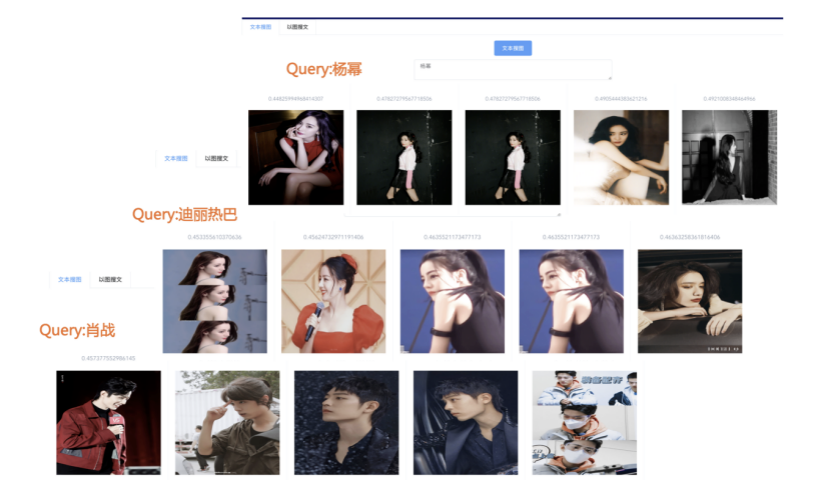
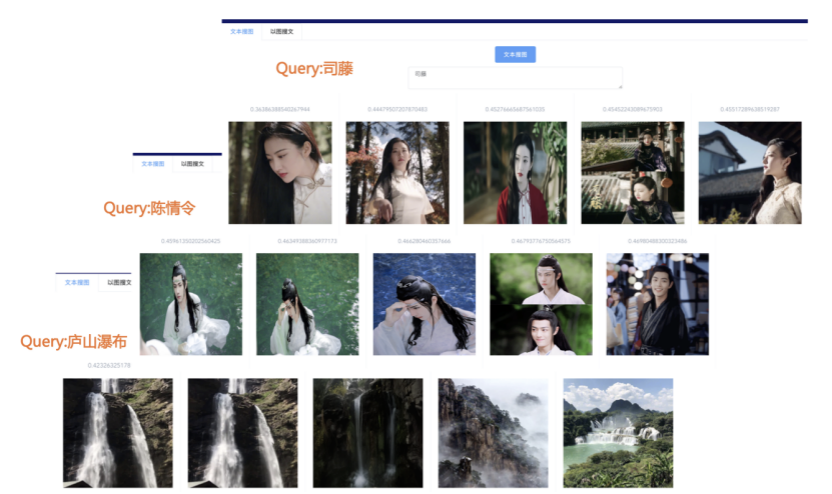
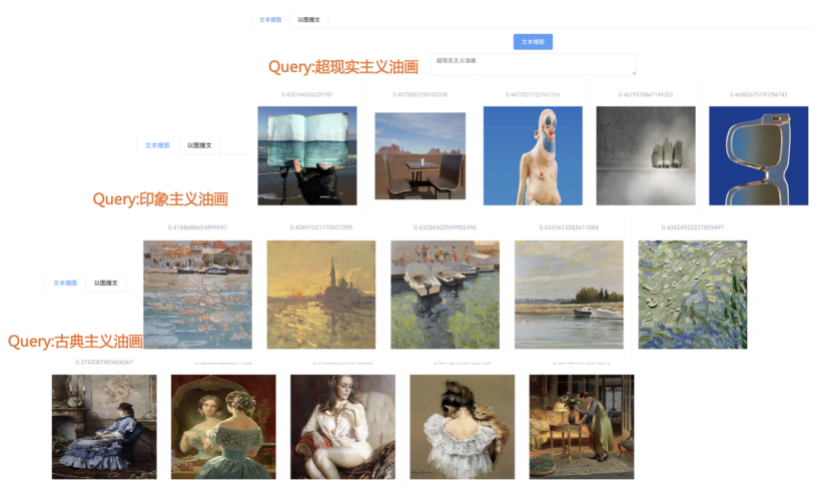
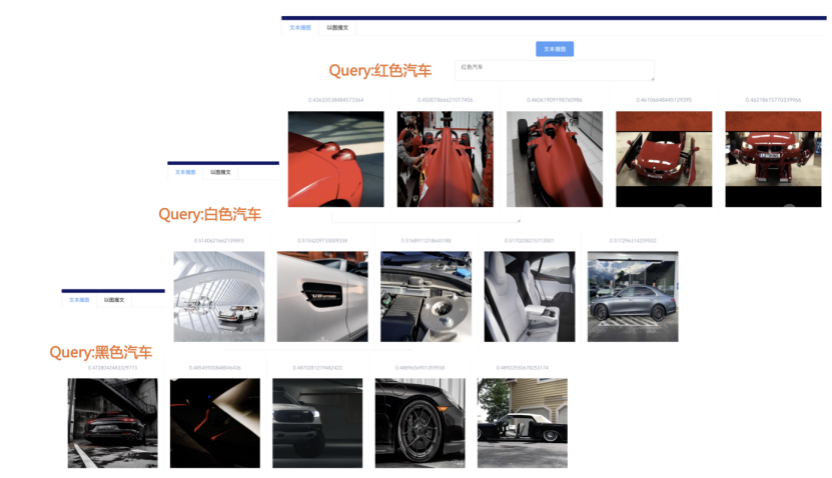
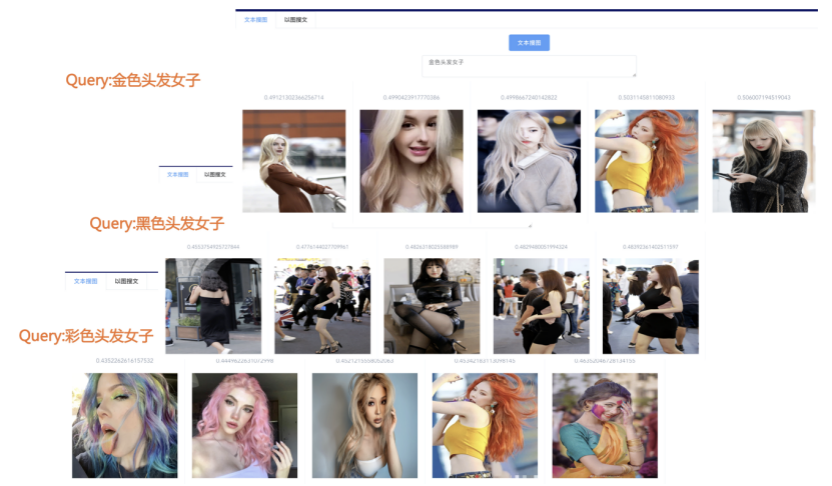
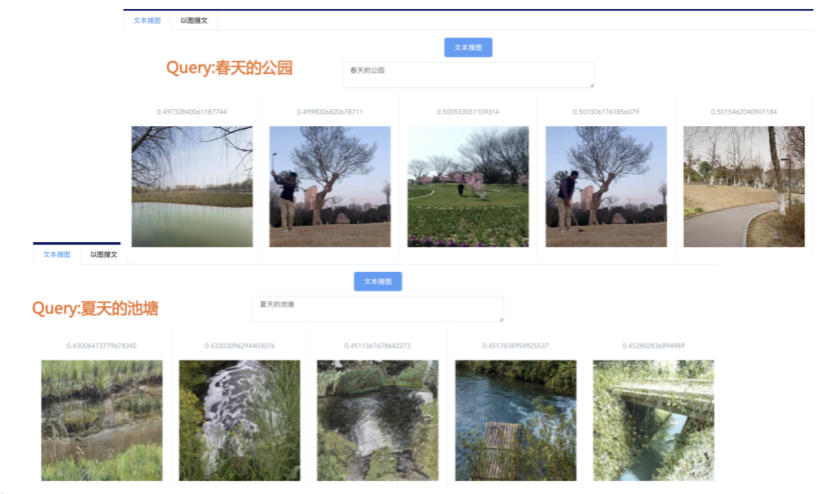
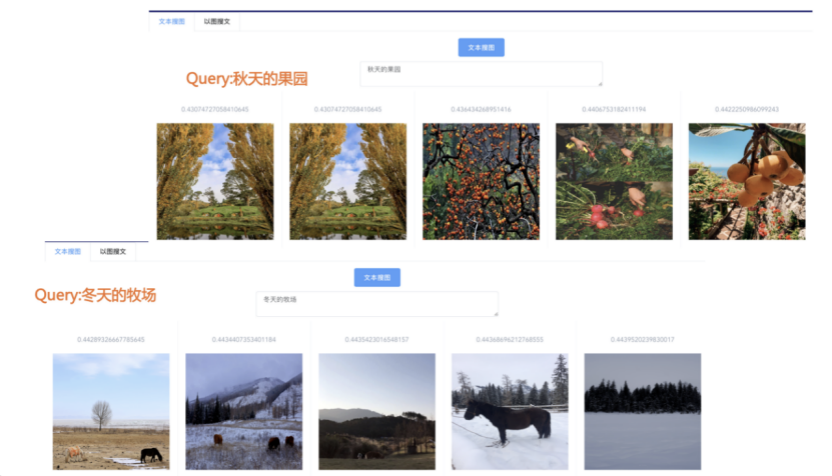
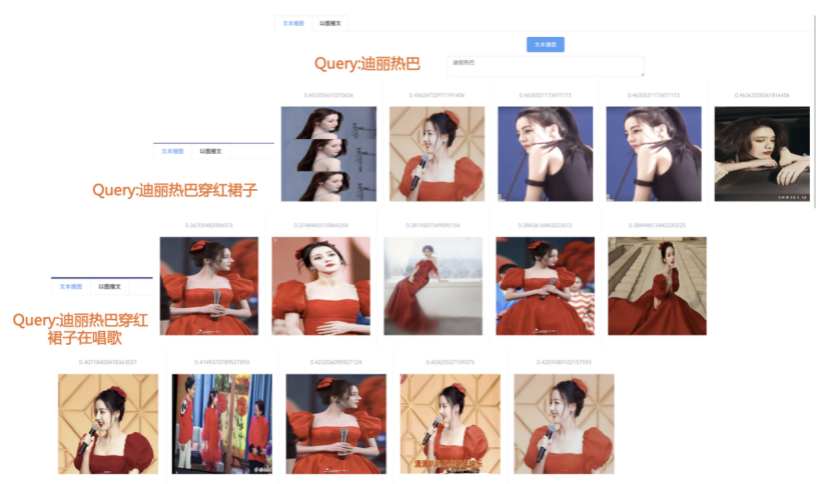
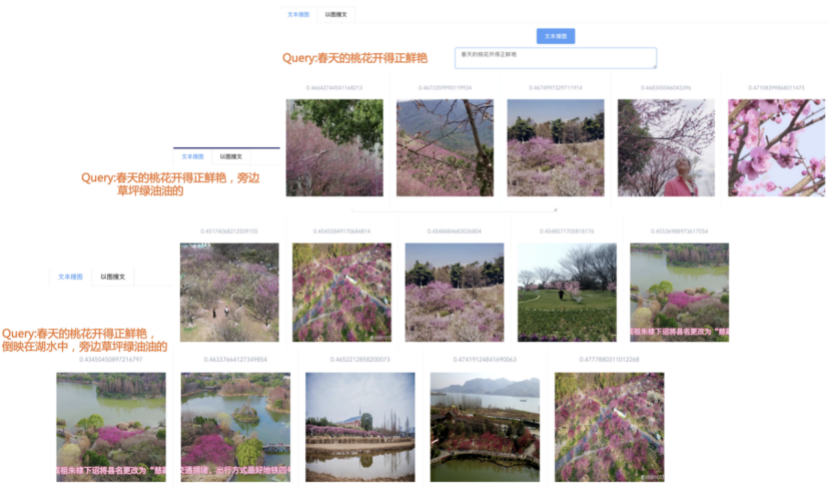
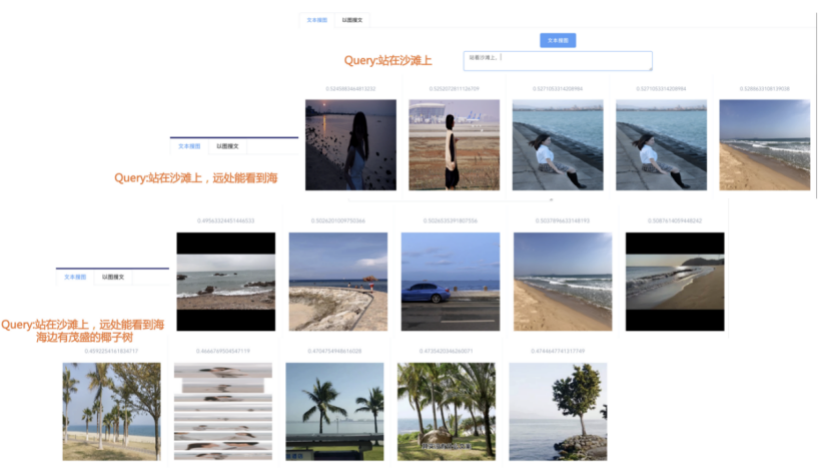
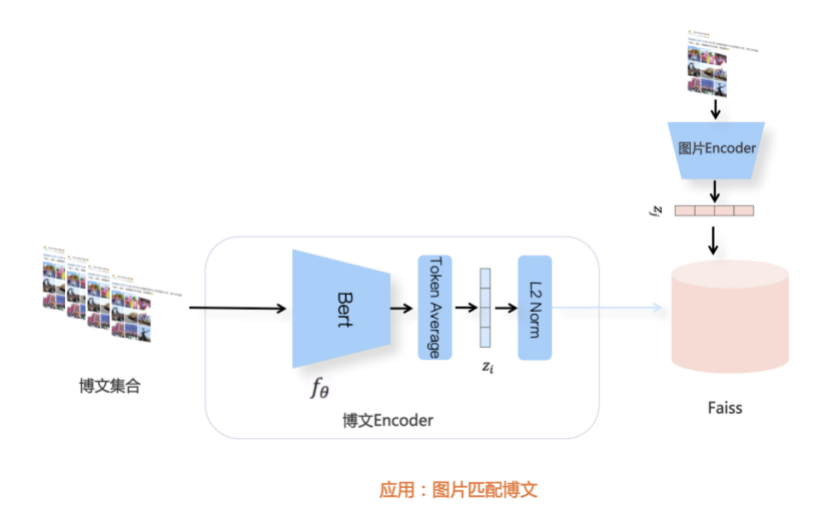
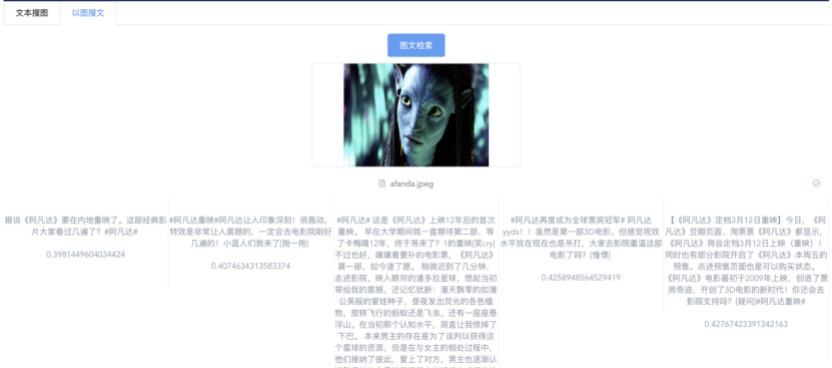
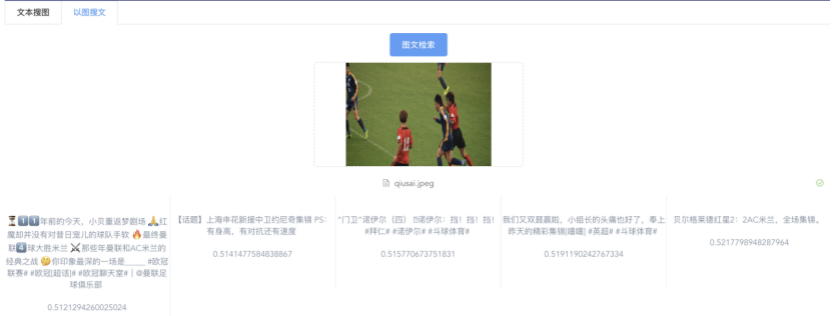
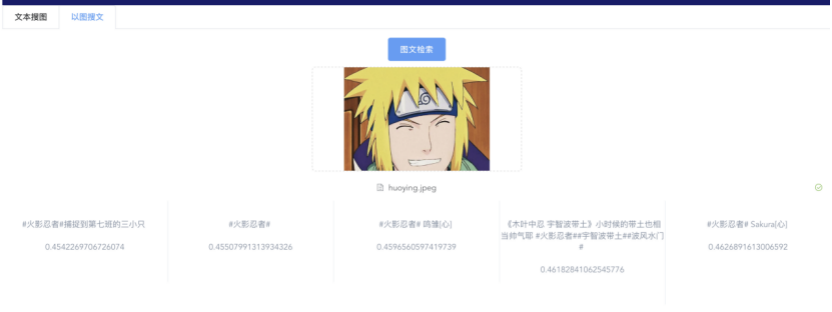
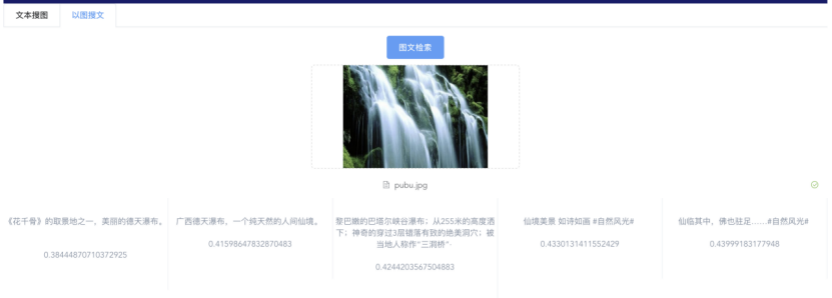
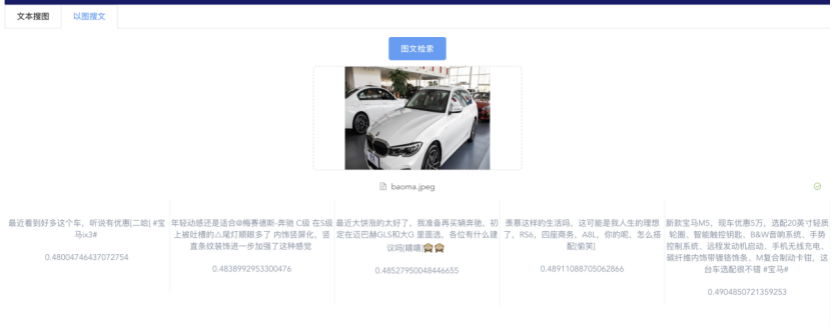
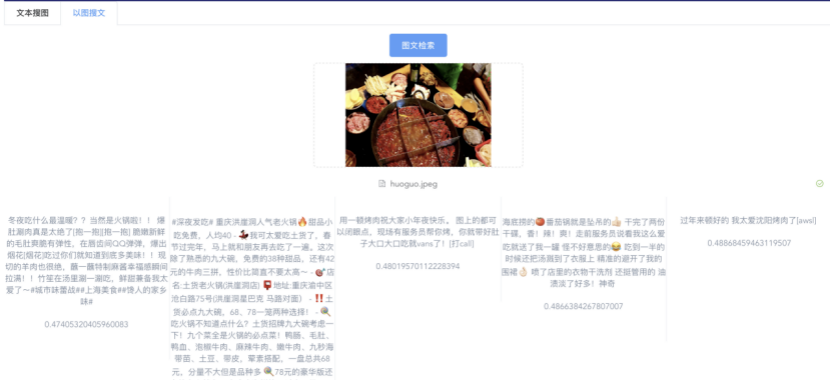
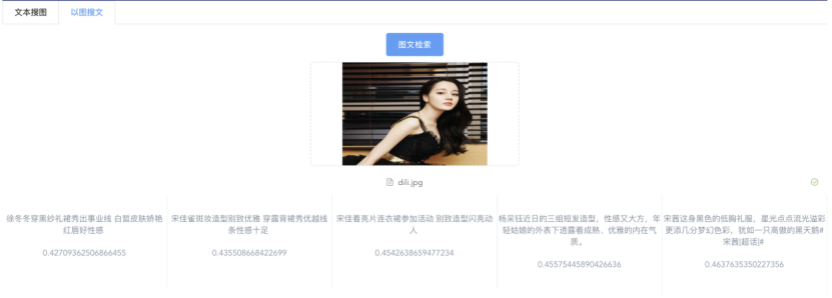
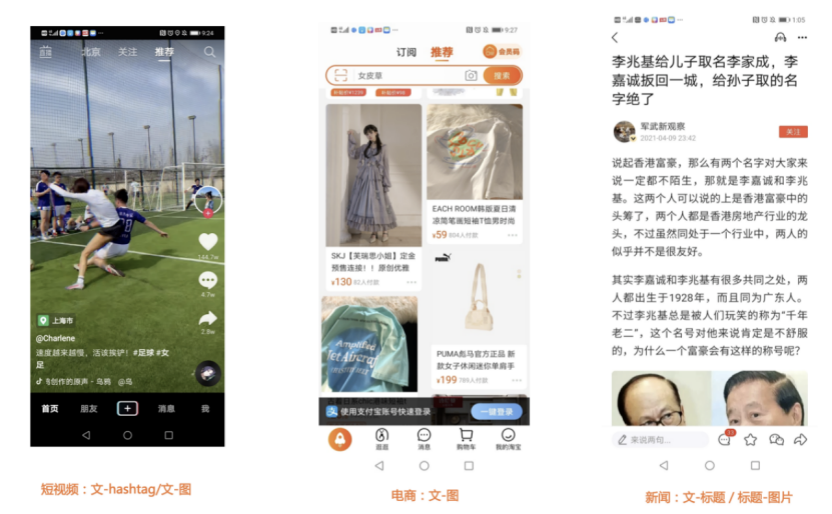
我们先从面向<文档,话题>数据对的对比模型说起。所谓“话题”是什么意思呢?上图给了两个例子,微博中用户打在##符号内的内容,一般在Twitter上管这个叫HashTag,我们内部称之为话题。话题往往是用户使用几个单词组成的,对博文内容进行概括性描述的短语。微博中大约40%的博文是带有用户打上的话题的,但是用户打的话题质量良莠不齐,存在大量蹭热点话题的现象,博文内容和话题不匹配或弱相关的情况较为常见。上图两个例子分别展示了高低质量话题这两种情形。本文说的“文档”,指的是去掉话题的博文内容,后文有时也会称为“微博正文”。也就是说,我们会把微博内容分离成文档和对应的话题两部分。我们希望使用同一微博带有的<文档,话题>数据对作为训练数据,使用对比学习,构造一个表征学习系统,将微博正文和话题映射到同一个语义空间中,在表示空间内,语义相近的正文和话题距离较为接近,而语义不相似的正文和话题距离较远。以此来获得一个针对微博内容的编码器和话题编码器,希望这两个编码器能够给微博内容和话题打出高质量的Embedding。我们称这个利用<文档,话题>数据的对比学习模型为CD-TOM模型(Contrastive Document-TOpic Model),它其实是SimCLR的自然语言处理版本。上图展示了CD-TOM模型的整体结构。仿照SimCLR模型,它由对称的上下两个分枝(Branch)构成,上下两个分枝主体都由Bert模型构成,是基于Bert预训练模型的双塔结构。我们随机从带有话题(#HashTag#)标记的微博训练数据中取N个构成一个Batch,对于Batch内某个微博 来说,在Aug1和Aug2里分别是微博正文和对应的微博话题 ,数据对<, >互为正例,而博文和Aug2里除之外的其它任意N-1个话题都互为负例。同样的,话题和Aug1里除之外的其它任意N-1个微博正文都互为负例。这是CD-TOM模型的正例和负例构造方法,可以看出,采用了典型的Batch内负例。因为上下分枝是对称的,我们仅以博文侧Aug1所经过的上分枝来介绍文本表示映射过程。Aug1内的正文数据,首先经过Bert模型对文本内容编码(这里以函数代表):目前很多研究表明,在做文本表示时,用Bert的[CLS]来表征文本内容效果不佳,所以常常会用Transformer最高层单词对应的Embedding编码(注:如果同时用第一层和最高层单词Embedding效果更好),句中每个单词对应Embedding累加后求均值(TAP, Token Average Pooling),形成博文表示向量。目前对比学习模型研究表明:将原始数据映射到单位超球面,一般这样做效果更好。所以接下来,我们对博文表示向量做L2正则,将其映射到单位超球面上,这样来完成博文的表示映射过程。下分枝的Aug2过程类似,通过相同手段将话题映射到单位超球面上。通过双塔结构,我们期望将博文和话题映射到相同表示空间内。这里,上下分枝Bert采取了共享参数的做法。在模型结构方面,我们曾尝试完全仿照SimCLR,经过Bert表示后,再引入另外一个非线性映射过程,但是实验结果表明第二个非线性结构会导致负向效果,所以在最终结构中,把第二个非线性映射结构拿掉了,我认为这应该是SimCLR和CD-TOM正例构造方法不同导致的模型结构差异。在表示空间内,我们希望正例距离较近,负例距离较远,以此来将表达相同语义的正文和话题映射到一起。我们对博文表示向量和话题表示向量进行点积,以此作为度量函数,来衡量单位超球面上任意两点的距离:而损失函数则采用对比学习常用的InfoNCE,某个例子对应的InfoNCE损失为:其中,<, >代表两个正例相应的表示向量。从InfoNCE可以看出,这个函数的分子部分鼓励正例相似度越高越好,也就是在表示空间内距离越近越好;而分母部分,则鼓励任意负例之间的向量相似度越低越好,也就是距离越远越好。是温度系数超参,用来调节数据在单位超球面上的分布均匀性。这样,在优化过程中,通过InfoNCE损失函数指引,就能训练模型,以达成我们期望的目标,将表达相同语义的微博正文和对应话题映射到空间中接近的地方,和正文表达不同语义的话题在表示空间内尽量推远。上面介绍的是博文-话题的对比学习模型CD-TOM的结构,可以看出,这是一个基于对比学习的,双塔Bert模型Fine-Tuning过程。其实,只要稍加改造,就可以对同一微博内很多不同元素相互之间进行比较与映射,比如我们还可以对博文-图片来进行表示学习。除了正例构造方法和模型小细节外,博文-图片多模态模型的整体结构和CLIP比较接近,所以,我们将这个使用包含大量噪音微博文图数据的多模态模型称为W-CLIP(Weibo-CLIP)。博文-图片对比学习系统W-CLIP的模型结构如上图所示。整体运行机制和CD-TOM模型基本一致,主要区别有两点:首先,构造正例的时候,不再是用同一个微博内包含的<正文,话题>数据对,换成了带图片微博里对应的<博文,图片>数据对,如果一个微博里包含多张图片,则同时构造多个正例。其次,上下分枝由对称结构改为非对称结构。因为图片和博文模态不同,所以下分枝不能使用Bert预训练模型,这里我们采用经过ImageNet预训练的ResNet101模型作为图片的特征抽取器,为了能和文本侧的表示向量进行内积计算,在ResNet最后一层FC之上,套上了一个线性映射层,使得图像表示的维度保持和文本表示维度一致。除此外,整个计算流程和CD-TOM类似。我们经过实验证明,放大Batch Size对于模型效果有较为明显的正向效果,所以通过LAMB优化器,并结合Gradient Checkpointing优化技巧,放大Batch Size到1664。关于大Batch Size技巧可以参考:Training on larger batches with less memory in AllenNLP,这里不赘述了。上面介绍的是表示学习模型在训练时的模型结构,在做具体应用的时候,我们需要的是几个经过预训练的特征抽取器:比如对于<正文,话题>数据对相关应用来说,我们得到了基于Bert的编码器,它既可以对博文进行特征编码,也可以对话题进行特征编码。而对于<博文,图片>数据对,我们得到两个编码器:基于Bert的博文编码器以及基于ResNet的图像编码器。在实际使用的时候,对于新的博文、话题或者图片,只需要使用对应的编码器,将博文、话题、图片,打成对应的Embedding,就可以放在Faiss里相互查找了。我们训练模型用的数据量:话题模型大概3000万左右,多模态模型大约1500万微博左右。在几个应用场景里效果比较好,这其实是超出我预期的,主要在做之前,我不确定这种包含大量噪音的成对数据,是否能训练出高质量的模型。而事实证明:海量包含噪音的数据+对比学习,可以比较充分利用和挖掘这种不完美匹配数据中隐含的复杂语义映射关系。我觉得主要有两个原因:一个是无论Bert还是ResNet,因为模型足够复杂,所以特征抽取器表达能力足够强;另外一个,应该是数据量大。实践表明,当数据量足够大的时候,采用类似上面的对比学习模型,并不需要数据对之间精准对应,对于微博这种两者语义对应关系并不精准的场景下,只要数据量足够大,效果也是有保障的。下面我们对于一些应用场景,给些例子。