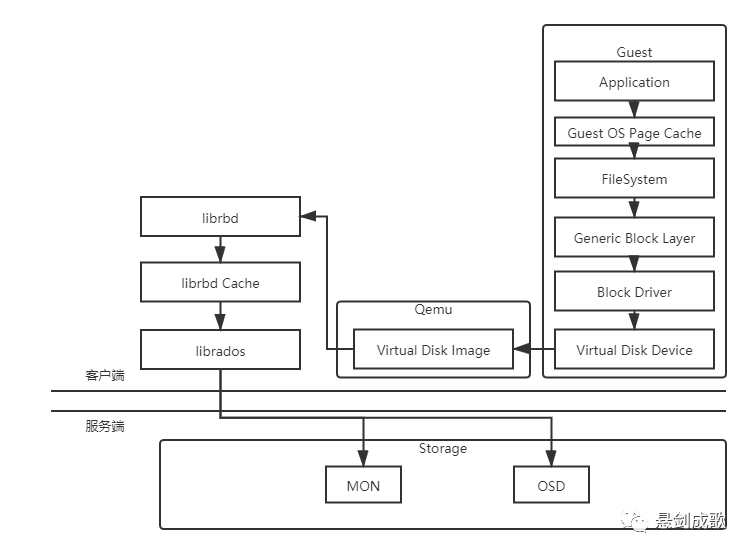
一、Ceph缓存
Cache Tiering是基于存储池的,在缓存层和Storage层之间的数据移动是两个存储池之间的数据移动,缓存层使用多副本模式,Storage层可以使用多副本或纠删码模式;
librbd Cache与Cache Tiering的主要差异在于缓存的位置不同,Cache Tiering是在OSD端进行数据缓存的,无论是块存储、对象存储还是文件存储都可以基于它来提高读写速度,而librbd Cache只是RBD层在客户端的缓存,只支持块设备,librbd Cache可以认为是块设备内部自带的缓存,与传统硬件块设备提供缓存的目的一样,他们都面临掉电后缓存数据丢失的情况。librbd Cache同样也会被fsync等调用触发flush,将数据持久化存储
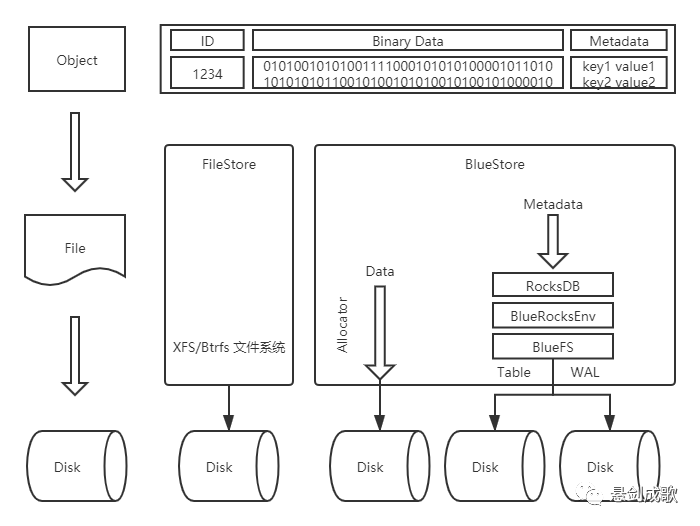
二、Ceph后端存储
FileStore最初知识针对机械盘进行设计的,并没有对固态硬盘的情况进行优化,而且写数据之前先写journal也带来一倍的写放大,BlueStore去掉了journal,通过直接管理裸设备的方式来减少文件系统的部分开销,并且也对固态硬盘进行了单独的优化。
BlueStore不再基于ext4/xfs等本地文件系统,而是直接管理裸设备,为此在用户态实现了BlockDevice,使用Linux AIO直接对裸设备进行I/O操作,并实现了Allocator对裸设备进行空间管理,至于元数据则以Key/Value对的形式保存在KV数据库里(默认为RocksDB)。但是RocksDB并不是基于裸设备进行操作的,而是基于文件系统(RocksDB可以将系统相关的处理抽象成Env,BlueStore实现了一个BlueRocksEnv,来为RocksDB提供底层系统的封装)进行操作的,为此BlueStore实现了一个小的文件系统BlueFS,在将BlueFS挂载到系统中的时候将所有的元数据加载到内存中。
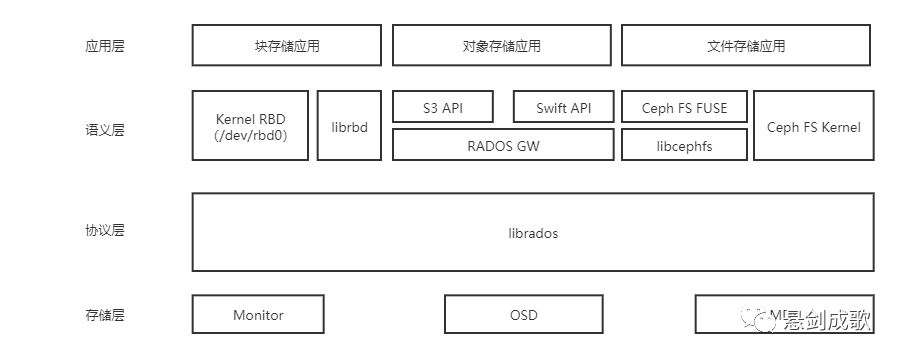
三、Ceph逻辑架构
Ceph存储集群:基于可靠的、自动化的、分布式的对象存储(RADOS)提供了一个可无限扩展的存储集群;
基础库librados:实际上是对RADOS进行抽象和封装,并向上层提供API,以便可以基于RADOS(而不是整个Ceph)进行应用开发。librados API包括C语言和C++语言两种,在物理上,librados和基于其上开发的应用位于同一台机器中,因而也被称为本地API。应用调用本机上的librados API,再由后者通过socket与RADOS集群中的节点通信并完成各种操作;
高层应用接口RADOS GW、RBD和Ceph FS:Ceph对象网关RADOS GW是一个构建在librados库上的对象存储接口,为应用访问Ceph集群提供一个与S3和Swift兼容的RESTful风格的网关;RBD则提供了一个标准的块设备接口,常用于在虚拟化的场景下为虚拟机创建存储卷,Red Hat已经将RBD驱动集成在KVM/QEMU中,以提高虚拟机的访问性能;Ceph FS是一个可移植操作系统接口兼容的分布式存储系统,使用Ceph存储集群来存储数据;
应用层:包含的是在不同场景下对应Ceph各个应用接口的各种应用方式
四、Ceph对象寻址
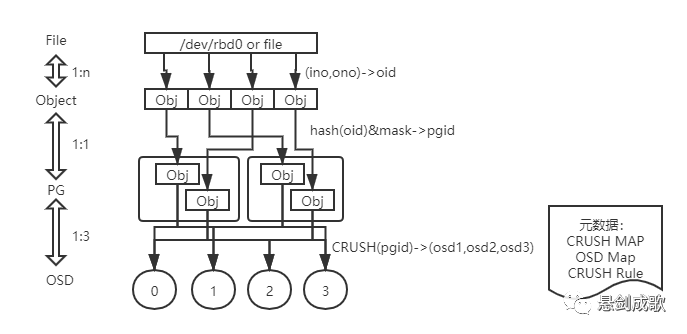
Ceph通过3次映射,完成了从File到Object、Object到PG、PG再到OSD的整个映射过程。从整个过程可以看到,这里没有任何的全局性查表操作需求。至于唯一的全局性数据结构:集群运行图。它的维护和操作都是轻量级的,不会对系统的可扩展性、性能等因素造成影响
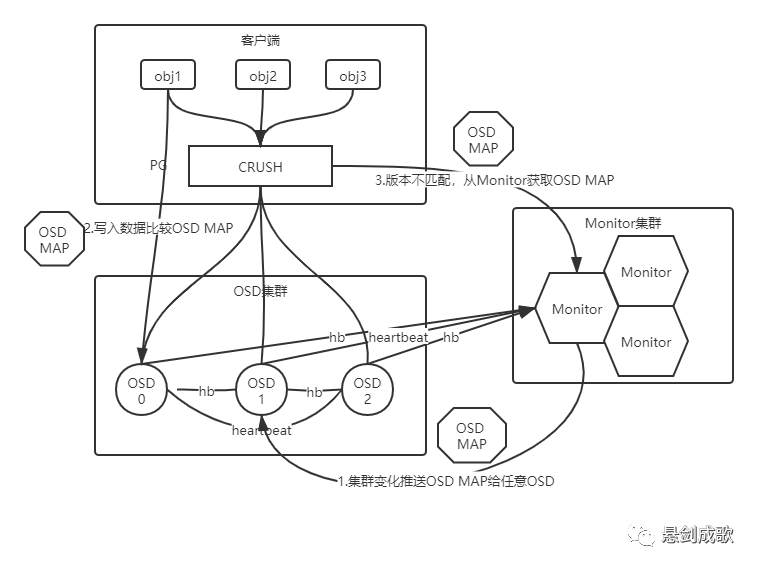
五、Ceph集群信息交互
OSD之间的心跳包:如果集群中的所有OSD都互相发送心跳包,则会对集群性能产生影响,所以Ceph选择Peer OSD发送心跳包,Peer OSD是指该OSD上所有PG的副本所在的OSD。
OSD与Monitor之间的心跳包:这个心跳包可以看作是Peer OSD之间心跳包的补充,如果OSD不能与其他OSD交换心跳包,那么就必须与Monitor按照一定频率进行通信,比如OSD状态时up&out时就需要这种心跳包。
当某个OSD出现故障后,Monitor集群判定某个OSD节点离线,将最新的OSDMap通过消息机制随机分发给一个OSD,客户端和对等OSD处理I/O请求的时候发现自身的OSDMap版本过低,会向Monitor请求最新的OSDMap。经过一段时间的传播,最终整个集群的OSD都会接收到OSDMap的更新。