




一、 Ceph是什么
Ceph最早起源于Sage就读博士期间的工作、成果于2004年发表,并随后贡献给开源社区。经过多年的发展之后,已得到众多云计算和存储厂商的支持,成为应用最广泛的开源分布式存储平台。
Ceph根据场景可分为对象存储、块设备存储和文件存储。Ceph相比其它分布式存储技术,其优势点在于:它不单是存储,同时还充分利用了存储节点上的计算能力,在存储每一个数据时,都会通过计算得出该数据存储的位置,尽量将数据分布均衡。同时,由于采用了CRUSH、HASH等算法,使得它不存在传统的单点故障,且随着规模的扩大,性能并不会受到影响。
二、Ceph的架构
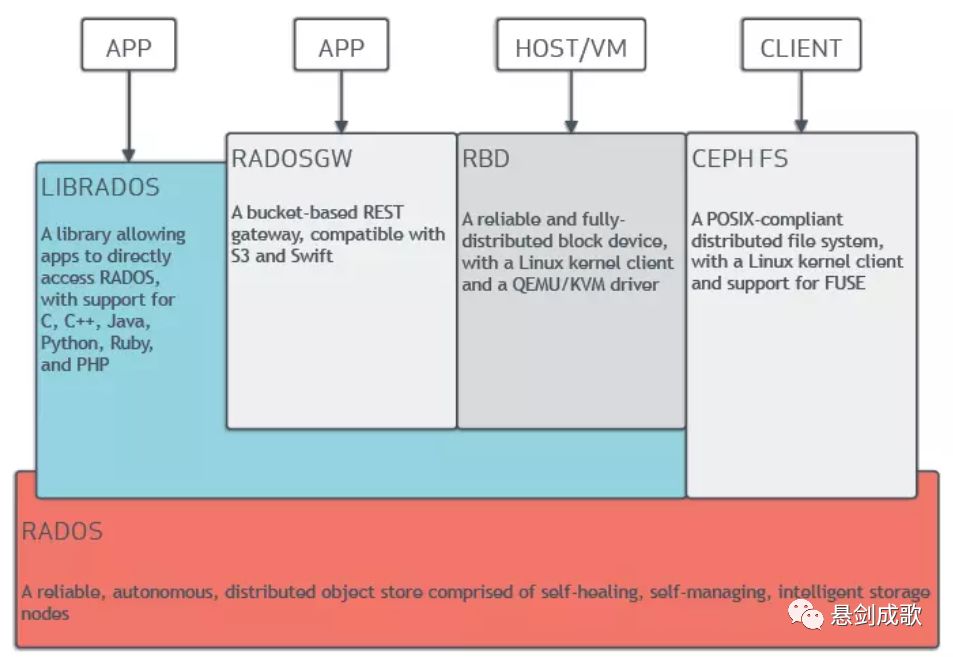
ceph分为两部分:
ceph node:构成 ceph 集群的基础组件。
ceph client:对外提供多种方式使用 ceph 存储的组件。
ceph node
其中包含 OSD、Manager、MDS、Monitor。
OSD(ceph-osd):object storage daemon,对象存储进程。ceph 管理物理硬盘时,引入了OSD概念,每一块盘都会针对的运行一个OSD进程。换句话说,ceph 集群通过管理 OSD 来管理物理硬盘。OSD 一般功能为:存储数据、维护数据副本、数据恢复、数据再平衡以及对ceph monitor组件提供相关监控信息。
Manager(ceph-mgr):用于收集ceph集群状态、运行指标,比如存储利用率、当前性能指标和系统负载。对外提供 ceph dashboard(ceph ui)和 resetful api。Manager组件开启高可用时,至少2个。
MDS(ceph-mds):Metadata server,元数据服务。为ceph 文件系统提供元数据服务(ceph 对象存储和块存储不需要MDS)。为 posix 文件系统用户提供性能良好的基础命令(ls,find等)。
Monitor(ceph-mon):维护集群的状态,包含monitor组件信息,manger 组件信息,osd组件信息,mds组件信息,crush 算法信息。还负责ceph集群的身份验证功能,client在连接ceph集群时通过此组件进行验证。Monitor组件开启高可用时,至少3个。
ceph client
此部分介绍 ceph 对外提供各种功能的组件。
其中包含:Block Device、Object Storage、Filesystem。
Block Device:块存储设备,RBD。
Object Storage:对象存储,RGW。对外可提供 swift 、s3 接口类型的restful api。
Filesystem:文件系统,CephFS。提供一个兼容POSIX的文件系统。
三、Ceph思想
传统架构里,客户端与一个中心化的组件通信(如网关、中间件、 API 、前端等等),它作为一个复杂子系统的唯一入口,它引入单故障点的同时,也限制了性能和伸缩性(就是说如果中心化组件挂了,整个系统就挂了)。
Ceph 消除了集中网关,允许客户端直接和 Ceph OSD 守护进程通讯。Ceph OSD 守护进程自动在其它 Ceph 节点上创建对象副本来确保数据安全和高可用性;为保证高可用性,监视器也实现了集群化。为消除中心节点, Ceph 使用了 CRUSH 算法。
四、CRUSH 简介
Ceph 客户端和 OSD 守护进程都用 CRUSH 算法来计算对象的位置信息,而不是依赖于一个中心化的查询表。与以往方法相比, CRUSH 的数据管理机制更好,它很干脆地把工作分配给集群内的所有客户端和 OSD 来处理,因此具有极大的伸缩性。CRUSH 用智能数据复制确保弹性,更能适应超大规模存储。
1.集群运行图
Ceph 依赖于 Ceph 客户端和 OSD ,因为它们知道集群的拓扑,这个拓扑由 5 张图共同描述,统称为“集群运行图”:
Montior Map:包含集群的 fsid 、位置、名字、地址和端口,也包括当前版本、创建时间、最近修改时间。
OSD Map:包含集群 fsid 、创建时间、最近修改时间、存储池列表、副本数量、归置组数量、 OSD 列表及其状态(如 up 、 in )。
PG Map:包含归置组版本、其时间戳、最新的 OSD 运行图版本、占满率、以及各归置组详情,像归置组 ID 、 up set 、 acting set 、 PG 状态(如 active+clean ),和各存储池的数据使用情况统计。
CRUSH Map:包含存储设备列表、故障域树状结构(如设备、主机、机架、行、房间、等等)、和存储数据时如何利用此树状结构的规则。
MDS Map:包含当前 MDS 图的版本、创建时间、最近修改时间,还包含了存储元数据的存储池、元数据服务器列表、还有哪些元数据服务器是 up 且 in 的。
各运行图维护着各自运营状态的变更, Ceph 监视器维护着一份集群运行图的主拷贝,包括集群成员、状态、变更、以及 Ceph 存储集群的整体健康状况。
2.高可用监视器
Ceph 客户端读或写数据前必须先连接到某个 Ceph 监视器、获得最新的集群运行图副本
3.计算 PG ID
Ceph 客户端绑定到某监视器时,会索取最新的集群运行图副本,有了此图,客户端就能知道集群内的所有监视器、 OSD 、和元数据服务器。然而它对对象的位置一无所知,对象位置是计算出来的。
客户端只需输入对象 ID 和存储池,此事简单:Ceph 把数据存在某存储池(如 liverpool )中。当客户端想要存命名对象(如 john 、 paul 、 george 、 ringo 等等)时,它用对象名,一个哈希值、 存储池中的归置组数、存储池名计算归置组。Ceph 按下列步骤计算 PG ID 。
客户端输入存储池 ID 和对象 ID (如 pool=”liverpool” 和 object-id=”john” );
CRUSH 拿到对象 ID 并哈希它;
CRUSH 用 PG 数(如 58 )对哈希值取模,这就是归置组 ID ;
CRUSH 根据存储池名取得存储池 ID (如liverpool = 4 );
CRUSH 把存储池 ID 加到PG ID(如 4.58 )之前。
计算对象位置远快于查询定位, CRUSH 算法允许客户端计算对象应该存到哪里,并允许客户端连接主 OSD 来存储或检索对象。
4.PG 映射到 OSD
每个存储池都有很多归置组, CRUSH 动态的把它们映射到 OSD 。Ceph 客户端要存对象时, CRUSH 将把各对象映射到某个归置组。归置组在 OSD 和客户端间创建了一个间接层。由于 Ceph 集群必须能增大或缩小、并动态地重均衡。如果让客户端“知道”哪个 OSD 有哪个对象,就会导致客户端和 OSD 紧耦合;相反, CRUSH 算法把对象映射到归置组、然后再把各归置组映射到一或多个 OSD ,这一间接层可以让 Ceph 在 OSD 守护进程和底层设备上线时动态地重均衡。下列图表描述了 CRUSH 如何将对象映射到归置组、再把归置组映射到 OSD 。有了集群运行图副本和 CRUSH 算法,客户端就能精确地计算出到哪个 OSD 读、写某特定对象。
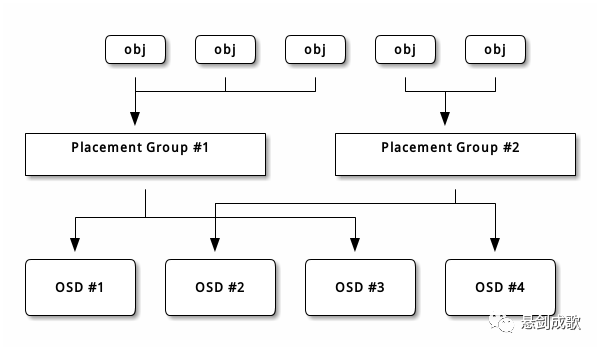
5.写入对象
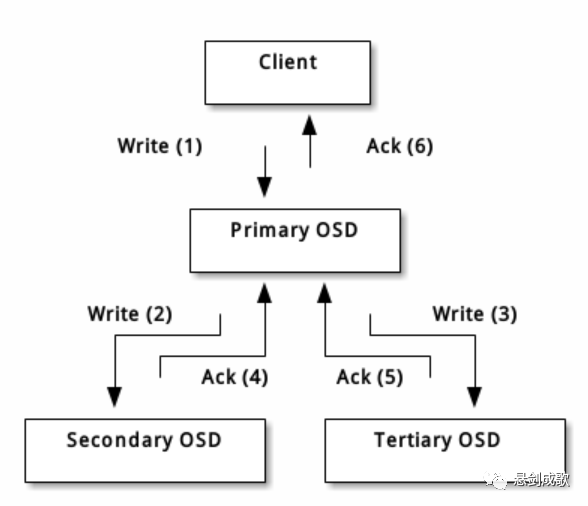
客户端把对象写入目标归置组的主 OSD ,然后这个主 OSD 再用它的 CRUSH 图副本找出用于放对象副本的第二、第三个 OSD ,并把数据复制到适当的归置组所对应的第二、第三 OSD (要多少副本就有多少 OSD ),最终,确认数据成功存储后反馈给客户端。
6.数据映射过程
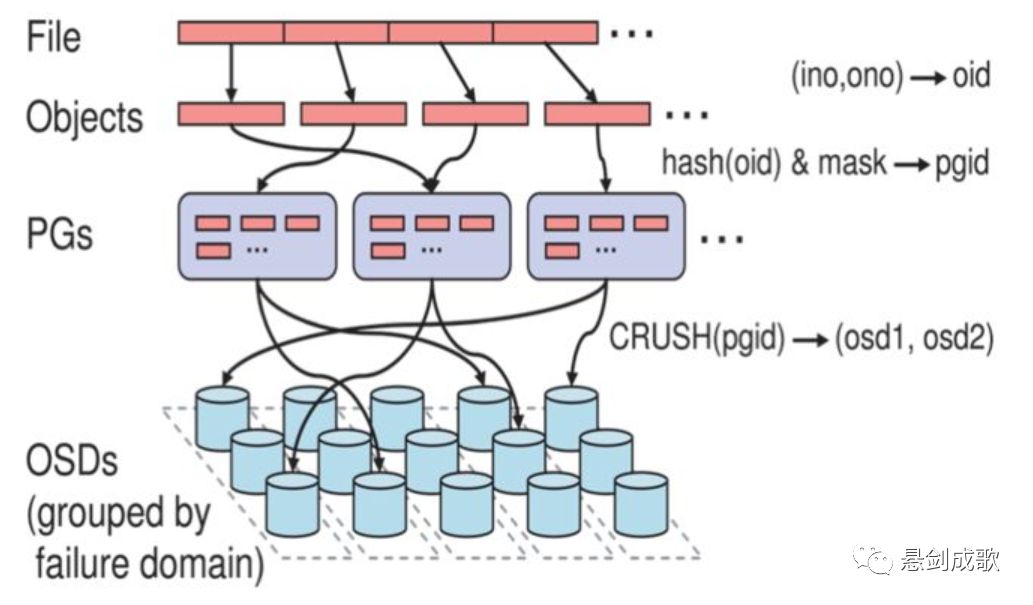
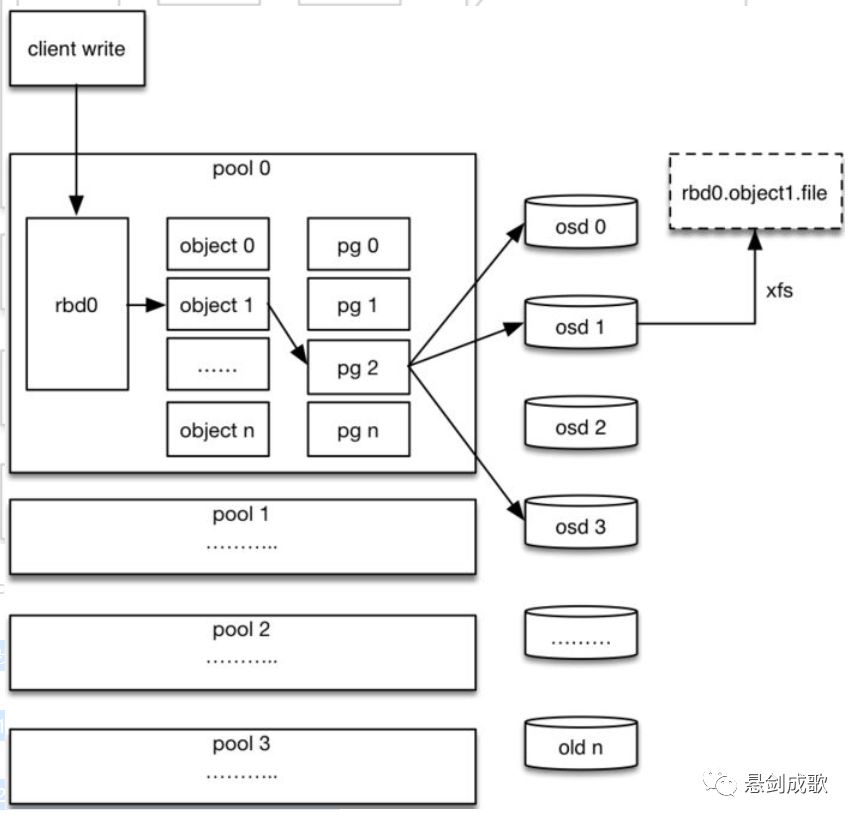
1. File用户需要读写的文件。File->Object映射:
a. ino (File的元数据,File的唯一id)。
2. Object是RADOS需要的对象。Ceph指定一个静态hash函数计算oid的值,将oid映射成一个近似均匀分布的伪随机值,然后和mask按位相与,得到pgid,obj 和 pg 之间的映射由 ceph client 计算得出。Object->PG映射:
a. hash(oid) & mask-> pgid 。
3. PG(Placement Group),用途是对object的存储进行组织和位置映射, (类似于redis cluster里面的slot的概念) 一个PG里面会有很多object。采用CRUSH算法,将pgid代入其中,然后得到一组OSD。PG->OSD映射:
a. CRUSH(pgid)->(osd1,osd2,osd3)
7.数据写入流程
1. 客户端创建一个pool,需要为这个pool指定pg的数量。
2. 创建pool/image rbd设备进行挂载。
3. 用户写入的数据进行切块,每个块的大小默认为4M,并且每个块都有一个名字,名字就是object+序号。
4. 将每个object通过pg进行副本位置的分配。
5. pg根据crush算法会寻找3个osd,把这个object分别保存在这三个osd上。
6. osd上实际是把底层的disk进行了格式化操作,一般部署工具会将它格式化为xfs文件系统。
7. object的存储就变成了存储一个文rbd0.object1.file。
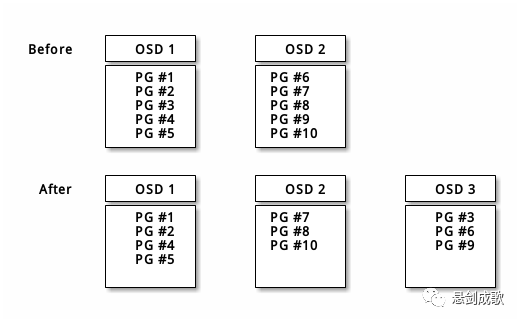
8.重均衡
你向 Ceph 存储集群新增一 OSD 守护进程时,集群运行图就要用新增的 OSD 更新。回想计算 PG ID ,这个动作会更改集群运行图,因此也改变了对象位置,因为计算时的输入条件变了。下面的图描述了重均衡过程,是其中的一些而不是所有 PG 都从已有 OSD ( OSD 1 和 2 )迁移到新 OSD ( OSD 3 )。即使在重均衡中, CRUSH 都是稳定的,很多归置组仍维持最初的配置,且各 OSD 都腾出了些空间,所以重均衡完成后新 OSD 上不会出现负载突增。
9.智能程序支撑超大规模
在很多集群架构中,集群成员的主要目的就是让集中式接口知道它能访问哪些节点,然后此中央接口通过一个两级调度为客户端提供服务,在 PB 到 EB 级系统中这个调度系统必将成为最大的瓶颈。
Ceph 消除了此瓶颈:其 OSD 守护进程和客户端都能感知集群,比如 Ceph 客户端、各 OSD 守护进程都知道集群内其他的 OSD 守护进程,这样 OSD 就能直接和其它 OSD 守护进程和监视器通讯。另外, Ceph 客户端也能直接和 OSD 守护进程交互。
Ceph 客户端、监视器和 OSD 守护进程可以相互直接交互,这意味着 OSD 可以利用本地节点的 CPU 和内存执行那些有可能拖垮中央服务器的任务。这种设计均衡了计算资源,带来几个好处:
OSD 直接服务于客户端:由于任何网络设备都有最大并发连接上限,规模巨大时中央化的系统其物理局限性就暴露了。Ceph 允许客户端直接和 OSD 节点联系,这在消除单故障点的同时,提升了性能和系统总容量。Ceph 客户端可按需维护和某 OSD 的会话,而不是一中央服务器。
OSD 成员和状态:Ceph OSD 加入集群后会持续报告自己的状态。在底层, OSD 状态为 up 或 down ,反映它是否在运行、能否提供服务。如果一 OSD 状态为 down 且 in ,表明 OSD 守护进程可能故障了;如果一 OSD 守护进程没在运行(比如崩溃了),它就不能亲自向监视器报告自己是 down 的。Ceph 监视器能周期性地 ping OSD 守护进程,以确保它们在运行,然而它也授权 OSD 进程去确认邻居 OSD 是否 down 了,并更新集群运行图、报告给监视器。这种机制意味着监视器还是轻量级进程。详情见监控 OSD 和心跳。
数据清洗:作为维护数据一致性和清洁度的一部分, OSD 能清洗归置组内的对象。就是说, Ceph OSD 能比较对象元数据与存储在其他 OSD 上的副本元数据,以捕捉 OSD 缺陷或文件系统错误(每天)。OSD 也能做深度清洗(每周),即按位比较对象中的数据,以找出轻度清洗时未发现的硬盘坏扇区。关于清洗详细配置见`数据清洗`_。
复制:和 Ceph 客户端一样, OSD 也用 CRUSH 算法,但用于计算副本存到哪里(也用于重均衡)。一个典型的写情形是,一客户端用 CRUSH 算法算出对象应存到哪里,并把对象映射到存储池和归置组,然后查找 CRUSH 图来确定此归置组的主 OSD 。
