





Prometheus是由CNCF孵化的下一代监控解决方案,而事实上Prometheus已经成为云原生时代的指标监控利器。与传统监控系统接入不同,Prometheus使用方便灵活的pull方式,只需暴露出http metrics接口即可。在Kubernetes中,通过Service服务发现实现动态接入。
Prometheus生态相对较为成熟,很多基础设施服务都提供exporter或本身提供metrics指标信息。对于内部业务场景或个性化需求,可以使用Prometheus sdk去加一些指标。
指标类型
Prometheus的指标类型包括基本指标类型Counter和Guage及进阶指标类型Historygram和Summary。
Counter:累加指标计数器, 单调递增, 如http请求数。服务重启时才会清零。
Gauge:一个动态的数值指标, 比如CPU使用率, 内存使用率等。
Historygram:Historygram是直方图, 适合需要知道数值分布范围的场景, 比如http请求的响应时长, http请求的响应包体大小等.
Summary:相比Historygram是按百分位聚合好的直方图, 需要知道百分比分布范围的场景,如http请求的响应时长场景,Historygram可以统计响应时长为1ms的有多少个
Histogram和Summary使用的频率较少,两种都是基于采样的方式。另外有一些库对于这两个指标的使用和支持程度不同,有些仅仅实现了部分功能。
官方示例
package mainimport ("flag""log""net/http""github.com/prometheus/client_golang/prometheus/promhttp")var addr = flag.String("listen-address", ":8080", "The address to listen on for HTTP requests.")func main() {flag.Parse()http.Handle("/metrics", promhttp.Handler())log.Fatal(http.ListenAndServe(*addr, nil))}
官方的示例实现了一个go应用中goroutine、thread、gc、堆栈的基本信息。
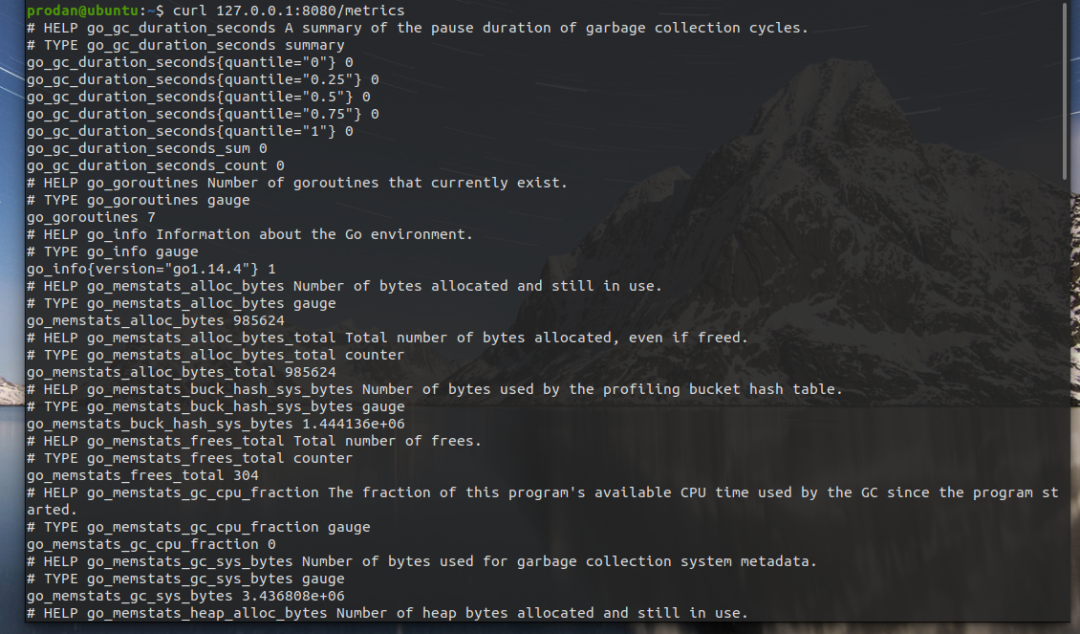
自定义指标
Collector默认都是主动去计数的, 但有的指标无法主动计数, 比如当前TCP连接数,这些指标仅在程序启动时获取,这个时候我们希望每次执行采集的时程序都去自动的抓取指标并将数据通过http的方式传递给Prometheus,那么这个时候就可以使用prometheus.NewCounterFunc
prometheus.NewGaugeFunc
定义Collector接口,用于传递自定义指标的描述符并将收集的数据传递到Channel中,由Prometheus的注册器调用Collect执行pull
type Collector interface {Describe(chan<- *prometheus.Desc)Collect(chan<- prometheus.Metric)}
定义结构体,一个监控pod状态,一个监控cpu负载
type PodManager struct {Tpye stringPodStatus *prometheus.Desc}type SystemManager struct {Tpye stringCPULoad *prometheus.Desc}
实现Collector接口
cpu指标使用Guage类型,pod指标这里演示使用Counter。
// Describe接口,传递结构体中的指标描述符到channel// Describe simply sends the two Descs in the struct to the channel.func (c *PodManager) Describe(ch chan<- *prometheus.Desc) {ch <- c.PodStatus}// Collect接口,抓取最新的数据,传递给channelfunc (c *PodManager) Collect(ch chan<- prometheus.Metric) {podStatus, podInofo := c.GetPodStatus()for podName, code := range podStatus {index := FindIndex(podName, &podInofo)ch <- prometheus.MustNewConstMetric(c.PodStatus,prometheus.CounterValue,float64(code),podName,podInofo[index].Namespace,podInofo[index].NodeName,podInofo[index].Status,)}}func (c *SystemManager) Describe(ch chan<- *prometheus.Desc) {ch <- c.CPULoad}func (c *SystemManager) Collect(ch chan<- prometheus.Metric) {cpu, _ := load.Avg()ch <- prometheus.MustNewConstMetric(c.CPULoad,prometheus.GaugeValue,cpu.Load1,"test",)}
定义一个函数中实现pod的采集指标工作,返回pod信息切片
func (c *PodManager) GetPodStatus() (podStatus map[string]int64, pods []PodInfo) {pods = GetPodInfo()podStatus = map[string]int64{}for _, value := range pods {if value.Status != "Running" {// 状态不为Running,都定义为0,表示异常podStatus[value.PodName] = 0} else {podStatus[value.PodName] = 1}}return podStatus, pods}func GetPodInfo() []PodInfo {podSlice := []PodInfo{}clientset, _, err := client.Connect("out-of-cluster")if err != nil {log.Println(err.Error())}pods, err := clientset.CoreV1().Pods("").List(context.TODO(), metav1.ListOptions{})if err != nil {panic(err.Error())}for _, value := range pods.Items {n := value.GetName()s := value.Status.Phaseif s == "Pending" || value.Status.ContainerStatuses == nil {info := &PodInfo{PodName: n, Namespace: value.GetNamespace(), NodeName: value.Spec.NodeName, Status: "Pending"}podSlice = append(podSlice, *info)continue}if s == "Pending" {e := value.Status.ContainerStatuses[0].State.Waiting.Reasoninfo := &PodInfo{PodName: n, Namespace: value.GetNamespace(), NodeName: value.Spec.NodeName, Status: fmt.Sprintf("%s", e)}podSlice = append(podSlice, *info)continue}if value.ObjectMeta.DeletionTimestamp != nil {podStatus := "Terminating"info := &PodInfo{PodName: n, Namespace: value.GetNamespace(), NodeName: value.Spec.NodeName, Status: podStatus}podSlice = append(podSlice, *info)continue}info := &PodInfo{PodName: n, Namespace: value.GetNamespace(), NodeName: value.Spec.NodeName, Status: fmt.Sprintf("%s", s)}podSlice = append(podSlice, *info)}return podSlice}
自定义指标信息
NewDesc的第一个参数为指标的名称,第二个为指标帮助信息,第三个是定义的label名称数组,第四个是定义的Labels
func NewPodManager(Tpye string) *PodManager {return &PodManager{Tpye: Tpye,PodStatus: prometheus.NewDesc("pod_status_info","Pod running status",[]string{"podname", "namespace", "nodename", "status"},prometheus.Labels{"Tpye": Tpye},),}}func NewSystemManager(Tpye string) *SystemManager {return &SystemManager{Tpye: Tpye,CPULoad: prometheus.NewDesc("cpu_load_info","cpu load",[]string{"load1"},prometheus.Labels{"Tpye": Tpye},),}}
主程序入口
func init() {//注册指标// Metrics have to be registered to be exposed:prometheus.MustRegister(collector.NewPodManager("pod")) // Add Go module build info.prometheus.MustRegister(collector.NewSystemManager("CPU"))prometheus.MustRegister(prometheus.NewBuildInfoCollector())}func main() {// metrics指标信息路由// Expose the registered metrics via HTTP.http.Handle("/metrics", promhttp.HandlerFor(prometheus.DefaultGatherer,promhttp.HandlerOpts{// Opt into OpenMetrics to support exemplars.EnableOpenMetrics: true,},))// 根路由,提示跳转至metricshttp.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {w.Write([]byte(`<html><head><title>Demo Exporter</title></head><body><h1>Demo Exporter</h1><p><a href='/metrics'>Metrics</a></p></body></html>`))})// 检测服务状态路由http.HandleFunc("/-/ready", func(w http.ResponseWriter, r *http.Request) {w.WriteHeader(http.StatusOK)log.Println(w, "ok")})// 启动http服务并监听2121端口log.Fatal(http.ListenAndServe(":2121", nil))}
运行结果
cpu
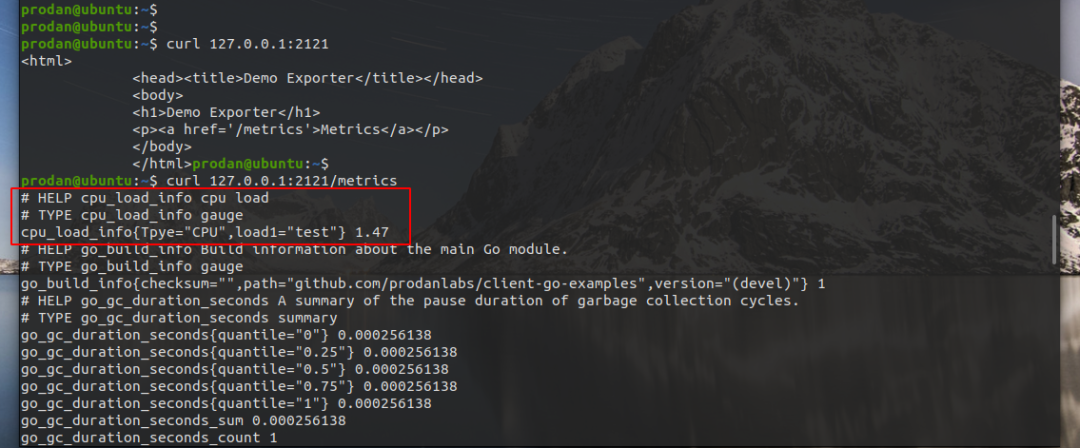
pod运行状态

