





日志打印memory/disk resource limit alarm set on node
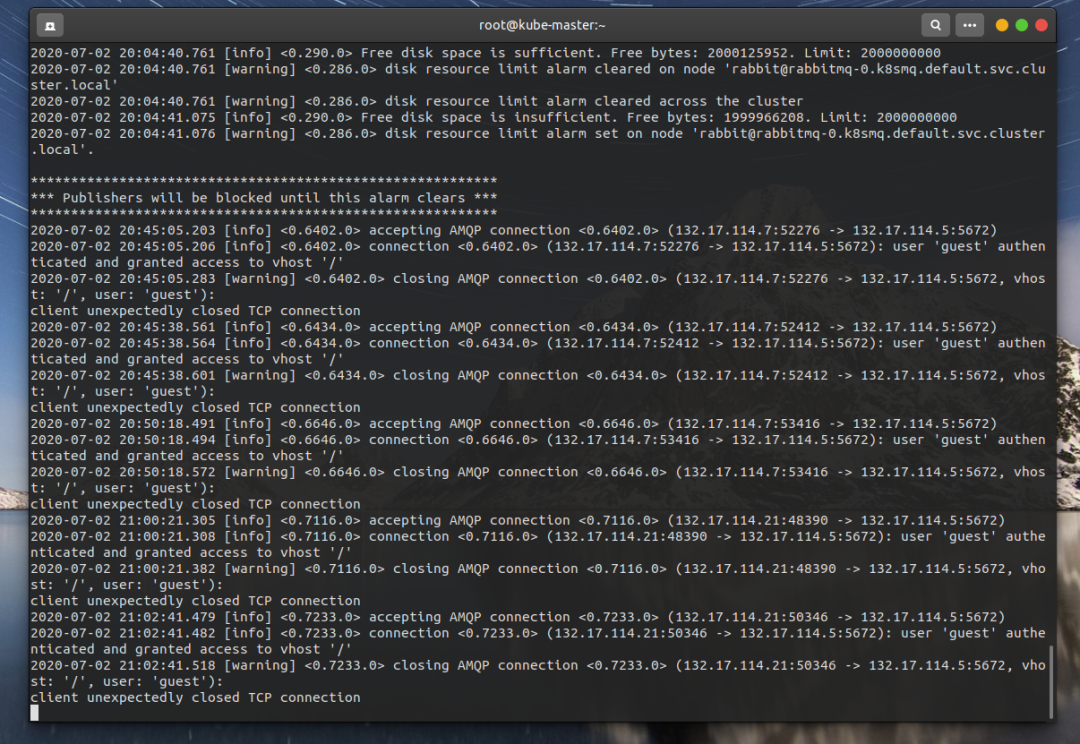
控制台显示连接阻塞
内存告警
vm_memory_high_watermark 默认是0.4,即rabbitmq使用的内存超过40%时,系统会阻塞连接。如设置0.5以上,erlang垃圾回收运行时,会消耗两倍内存。
vm_memory_high_watermark_paging_ratio 在broker达到high watermark阻塞发布者之前,它会尝试通过将队列的内容page到磁盘来释放内存,持久化和瞬时消息都会被page out(即把内存中的消息都输出到磁盘,包括持久化和非持久化的。持久化的消息一进队列就会被写进磁盘).
磁盘警告
disk_free_limit.absolute 磁盘可用空间阈值,当前磁盘可用空间小于这个值则触发告警
最终的配置文件(RabbitMQ集群运行在Kubernetes上)
---
apiVersion: v1
kind: ConfigMap
metadata:
name: rabbitmq-config
data:
enabled_plugins: |
[rabbitmq_management,rabbitmq_peer_discovery_k8s,rabbitmq_tracing,rabbitmq_federation,rabbitmq_federation_management,rabbitmq_delayed_message_exchange].
rabbitmq.conf: |
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_k8s
cluster_formation.k8s.host = kubernetes.default.svc.cluster.local
cluster_formation.k8s.address_type = hostname
cluster_formation.node_cleanup.interval = 10
cluster_formation.node_cleanup.only_log_warning = true
cluster_partition_handling = autoheal
queue_master_locator=min-masters
loopback_users.guest = false
cluster_formation.randomized_startup_delay_range.min = 0
cluster_formation.randomized_startup_delay_range.max = 2
cluster_formation.k8s.service_name = k8smq
cluster_formation.k8s.hostname_suffix = .k8smq.default.svc.cluster.local
vm_memory_high_watermark.absolute = 2GB
disk_free_limit.absolute = 200MB
#下面的配置会在内存使用到0.4 * 0.75=0.3的时候开始paging,在内存使用到0.4的时候阻塞发布者
vm_memory_high_watermark.relative = 0.4
vm_memory_high_watermark_paging_ratio = 0.75
创建RabbitMQ集群时分配的内存较小,编辑RabbitMQ的副本控制集增加内存,修改保存后,Kubernetes会自动滚动重启RabbitMQ集群

RabbitMQ集群重启后检查运行情况
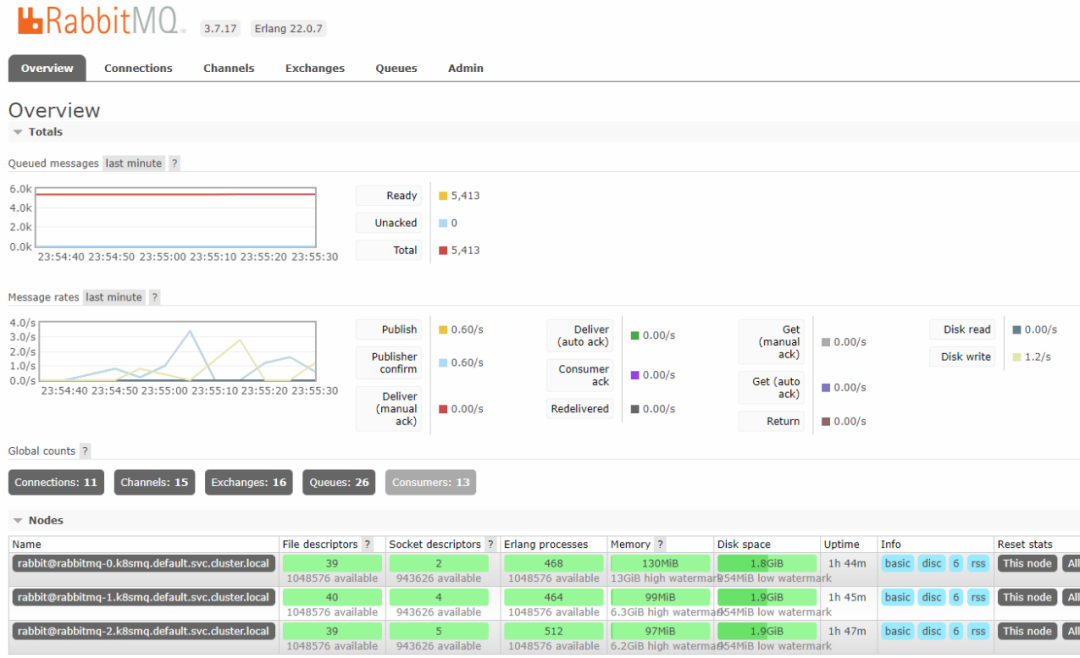
监控和Metrics
生产环境我们应该有完善且合理的监控机制,从而做到防患于未然。可以通过rabbitmq-exporter,把rabbitmq接入prometheus监控
文章转载自ProdanLabs,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
