




前言
这篇关于GTID的文章是我在15年写下的学习笔记, 当时所在的云数据库团队需要新上MySQL 5.6-GTID的实例, 并且需要升级数据库管控系统的功能. 主要是将MySQL的failover和switchover流程从以往的文件位点(file&pos)的方式升级到GTID的方式. 当时调研的过程中便写下了这个笔记. 如今已经是18年, 我又萌生了写博的想法(大学的时候有写, 工作之后就完全荒废了), 所以重新整理发到博客上,
对于一主多从的MySQL复制拓扑来说, 使用file&pos的同步方式对failover的过程来说是非常不友好的, 因为当复制拓扑中的Master宕机并新选出某个Slave作为New Master后, 其他Slave如何与New Master建立主从关系是个比较头痛的问题, 主要是因为其他Slave需要找到一个合适的位点来连接New Master, 这是一个很费力的过程: 扫描Slave各自的relaylog并找到在New Master上对应的位点.
但是, 如果使用了GTID, 一切都变得简单了.
GTID介绍
概念
GTID (global transaction identifier)是已提交事务的唯一表示, 不单在它产生的originating server是唯一的, 在复制拓扑中的所有server范围内都是唯一的, 该特性当gtid_mode=ON时才生效.
GTID的格式:
source_id:transaction_id
其中:
source_id就是产生该事务所在server的server_uuid,
transaction_id与事务提交顺序有关, 取值从1开始, 之后在同一个originating server的提交的事务, 它的transaction_id逐一递增.
比如,在 UUID为 3e11fa47-71ca-11e1-9e33-c80aa9429562 的server上提交的第58个事务的 GTID是:
3e11fa47-71ca-11e1-9e33-c80aa9429562:58
GTID Set
若干系统函数, 系统变量的输出形式是GTID set.
GTID set的形式如下:
uuid:interval [, uuid:interval]
其中interval是1或者1-5这样的区间.
比如GTID_SUBTRACT(set, subset)这个函数, 返回值是一个new set, 其中newset = set - subset. 像下面的例子:
select GTID_SUBTRACT('f76eb90f-82a2-11e5-a162-7ca23e9126c5:1-5,f76eb90f-82a2-11e5-a162-7ca23e9126c5:10-15', 'f76eb90f-82a2-11e5-a162-7ca23e9126c5:1-2')
返回结果:
f76eb90f-82a2-11e5-a162-7ca23e9126c5:3-5:10-15
GTID生命周期
我们可以在binlog里看到GTID, 并通过GTID分辨出事务来自哪个server. 另外, 如果事务已经在某个server上提交了, 后续的具有相同GTID的事务将会被忽略. 这样提供了一致性保证.
使用GTID后, slave不再需要master的上的文件名和偏移量(file&pos), 也即是 CHANGE MASTER TO语句不再需要指定MASTER_LOG_FILE 和 MASTER_LOG_POS参数.
事务在master上提交时, 被赋予一个GTID, GTID会立即写到binlog中,在事务本身的前面:
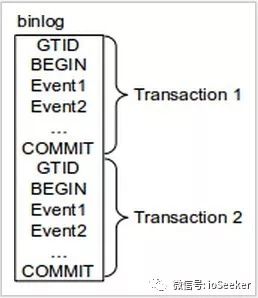
alt binlog数据传输到slave上并存到relay log后, slave将读取GTID, 并设置到gtid_next这个变量里, 之后slave上提交的事务必须使用这个GTID. 也就是说, slave对这个事务不产生新的GTID.
slave确认这个GTID没有被自己的binlog使用后, 开始执行事务. 事务提交时会将GTID写到binlog, 并将事务的其他event写到binlog中.
系统变量GTID_NEXT
gtid_next是session变量, 默认值是AUTOMATIC, 表示生成新GTID.
slave线程从relaylog读取到GTID后, 会设置gtid_nex参数. 比如, 从relaylog读取到了4d8b564f-03f4-4975-856a-0e65c3105328:4711这个GTID, 它会执行下面这个语句:
SET GTID_NEXT = 4d8b564f-03f4-4975-856a-0e65c3105328:4711;
mysqlbinlog也使用这样的机制, 当它读取到一个gitd-event, 便输出一个SET GTID_NEXT 语句.
当一个事务提交时, innodb会检查它是会否已经存在于系统变量GTID_EXECUTED中, 如果存在的话, 这个事务将会被忽略.
系统变量GTID_EXECUTED
变量GTID_EXECUTED中, 存有所有写到binlog中的所有gitd set, 它的值和SHOW MASTER STATUS 或者SHOW SLAVE STATUS中的Executed_Gtid_Set
字段是一样的.
比如server上应用了下事务:
0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:1
0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:2
4D8B564F-03F4-4975-856A-0E65C3105328:1
0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:3
4D8B564F-03F4-4975-856A-0E65C3105328:2
那么, GTID_EXECUTED的值就是:
"0EB3E4DB-4C31-42E6-9F55-EEBBD608511C:1-3,
4D8B564F-03F4-4975-856A-0E65C3105328:1-2"
对于slave, 如果io线程收到到数据, 存放在relaylog中, 可以通过show slave status查看Retrieved_Gtid_Set字段, 了解slave已经收到的事务.
复制协议
在5.6之前的主从复制, 当slave连接master时, 需要指定master的binlog位点(file&pos), 然后master发送这个点之后的所有数据.
现在新的协议是:
当slave连接master时, 发送它已经执行过的事务gitd区间.
master发送其他的事务给slave, 也就是slave还没有执行的事务.

相关函数
GTID_SUBSET()
Return true if all GTIDs in subset are also in set; otherwise false.GTID_SUBTRACT()
Return all GTIDs in set that are not in subset.WAIT_FOR_EXECUTED_GTID_SET()
Wait until the given GTIDs have executed on slave.WAIT_UNTIL_SQL_THREAD_AFTER_GTIDS()
Wait until the given GTIDs have executed on slave.
搭建主从
master上一定要开启binlog, 以及配置serverid
[mysqld]
log-bin=mysql-bin
server-id=1
启动master, 注意打开gtid_mode:
mysqld_safe --gtid_mode=ON --log-bin --log-slave-updates --enforce-gtid-consistency&
启动slave, 注意加上skip-slave-start 选项:
mysqld_safe --gtid_mode=ON --log-bin --log-slave-updates --enforce-gtid-consistency --skip-slave-start
在slave执行:
CHANGE MASTER TO MASTER_HOST = host, MASTER_PORT = port, MASTER_USER = user, MASTER_PASSWORD = password, MASTER_AUTO_POSITION = 1;
START SLAVE;
这样简单的一主一从就搭建好了.
具体操作:
http://dev.mysql.com/doc/refman/5.6/en/replication-gtids-howto.html
GTID在failover中的使用
场景1: newest slave当作new master
考虑下图的一主两从星型结构, A当作master, B,C都是它的slave:
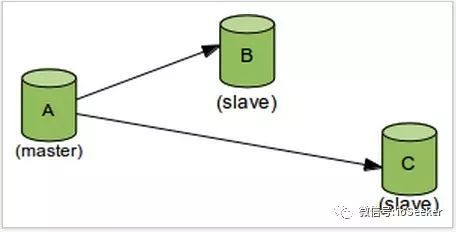
假设现在A宕机了, 我们需要做切换操作, 从B和C中找一个server来当作新的master, 并把其他的server当作它的slave:
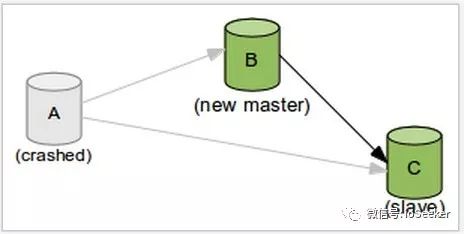
由于主从复制是异步的, B和C从原来的master中收到的、应用的事务个数都不一样, 可能其中一个数据比较新. 假设B的数据比C要新, 我们将B当作新的master. 那么我们需要将C当作B的slave, 并从C还没应用的事务开始主从复制.
假设A提交了3个事务, B复制了这3个事务, 但是C只复制了第一个事务:
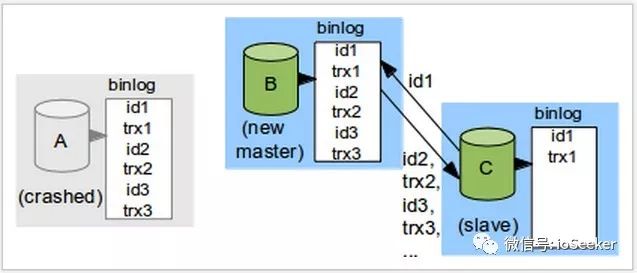
当A宕机后, 我们用B当作新的master, 把C当作B的slave. 在新的 replication协议下, C将会发送id1给B, 之后B将会把C没有执行的事务, 也就是(id2,tr2) , (id3, tr3) 发送给C, 之后在B上新提交的事务, 也会源源不断的发送给C.
场景2: 任意指定某 slave当作new master
有些时候, newest slave并不是理想的 new master, 可能是它的硬件配置不高, 网络不好. 我们一开始就预先选定了某硬件很强劲的slave当作备选master.
在下图中, 一开始A是master, BCD都是slave. 而且我们指定B当作备选master:
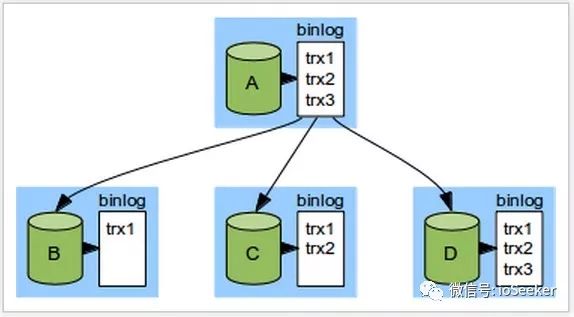
假设这时候A宕机了, 这个时候需要作切换, 因为D现在是newest, 就简单的做法就是将D当作新的master, 让其他server当作slave. 但是我们现在要把B当作新的master, 在此之前, 我们要更新B的数据, 做法是让B当作D的slave, 当B追上D时, 再切换B为master.
但是上图仅仅是现实情况的简化版, 真实情况是, slave可能已经将数据写到relaylog 但是还没有应用这些事务, 如下图:
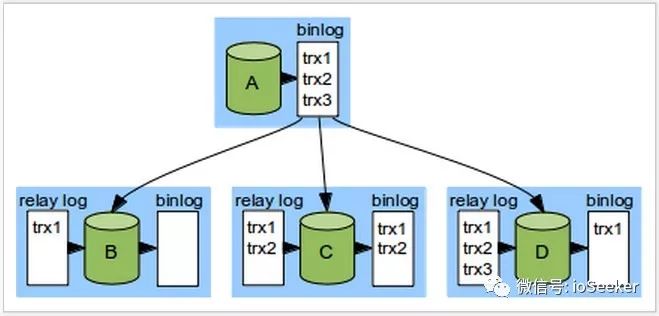
这个情景中, BCD分别收到了1, 2, 3个事务, 但是B一个事务都还没应用, C应用了2个, D应用了1个.
我们的目标是把B当作新的master, 再这之前需要更新他的数据.
第一种做法是, 让B依次连接C和D, 连接后, 等待B执行完C或者D中relaylog和binlog中的事务. 这样一轮下来, B的数据已经是newest, 已经可以切换成为新的master.
第二种方法, 是找到most slave, 也就是relay log数据最多的slave, 在这个例子中是D, 等待D的sql线程执行完relay log后, 再让B连接D, 等B的数据达到newest后, 切换成为新的master.
前面说过, slave收到的事务可以在SHOW SLAVE STATUS中的Retrieved_GTID_Set看到, 已经应用的事务可以在变量gtid_executed看到.
上述第一种做法的操作, 可以下面的伪代码实现, 其中candidate是备选master:
for each slave in slaves_of_the_master:
if slave != candidate:
candidate.query(STOP SLAVE)
candidate.query(CHANGE MASTER TO
MASTER_HOST = slave.host,
MASTER_PORT = slave.port)
candidate.query(START SLAVE)
slave_executed_gtids :=
slave.query(SELECT @@GLOBAL.GTID_EXECUTED)
slave_queued_gtids :=
slave.query(SHOW SLAVE STATUS)
[column = Retrieved_GTID_Set]
slave_all_gtids :=
slave_executed_gtids + ',' + slave_queued_gtids
candidate.query(
SELECT WAIT_UNTIL_SQL_THREAD_AFTER_GTIDS(
slave_all_gtids))
云数据库行业内failover的实现方式稍微更复杂一些, 因为我们需要在RPO和RTO之间做平衡, 首要是保证RPO(也就是尽量保证不丢数据), 但是也要兼顾RTO(不能因为failover中由于额外某些slave的故障导致failover时间太长)
使用GTID的一些限制
因为GTID是基于事务的, 当使用GTID时, 一些mysql的特性将会收到限制.
更新涉及到非事务引擎: 当在一个trx中, 既更新基于事务引擎的表, 又更新了非事务引擎的表, 这种情况会导致这个trx产生多个GTID. 这就破坏了GTID和事务之间一对一的关系, 进而导致基于GTID的主从复制不能正确工作. 其实现在已经很少人这么用, 我们团队5.6数据库已经默认把用户的MyISAM转换成Innodb.
CREATE TABLE … SELECT语句: 当使用row-based格式的binlog, 这个语句会产生两个独立的event: 一个新建table, 另外一个插入数据. 如果在trx中执行该语句, 这两个event可能会产生相同的GTID, 也就意味着插入数据的那个evnet会被跳过. 其实令一条SQL语句产生两个GTID即可避免这个问题, 对于这一点, 我提了个patch给官方:#82919 .
临时表: 当使用GTID时, 不支持CREATE TEMPORARY TABLE和 DROP TEMPORARY TABLE 这两个语句, 但是如果在事务外, 而且autocommit=1时, 可以执行这两个语句. 也即是事务内才会有问题, 事务外是ok的.
通过--enforce-gtid-consistency选项, 可以阻止上述语句的执行. 开启该选项后, 相关的语句执行会导致错误.
create table test2 select * from test1;
ERROR 1786 (HY000): CREATE TABLE ... SELECT is forbidden when @@GLOBAL.ENFORCE_GTID_CONSISTENCY = 1.
参考资料
replication-gtids-failover
flexible-fail-over-policies-using-mysql
