




“ 本文主要介绍了三种常见的存储引擎:哈希存储引擎、B树存储引擎和LSM树存储引擎。”
存储引擎是存储系统的发动机,直接决定了存储系统的性能和功能。存储引擎负责管理数据具体在存储介质上如何存储和检索。不同的存储引擎的优劣势不同,我们需要了解不同存储引擎的优缺点,才能根据需求选择合适的存储引擎来管理数据,从而来提高存储系统的性能。以下将介绍几种常用的存储引擎。
提示:本篇文章较长,认真阅读需要二十分钟左右
01
—
哈希存储引擎——Bitcast
哈希存储引擎是哈希表的持久化实现,支持增、删、改,以及随机读取操作,但不支持顺序扫描,对应的存储系统为键值(Key-Value)存储系统。Bitcast是一种日志型的基于hash表结构的健值对的存储系统,最早追溯于Riak分布式数据库。
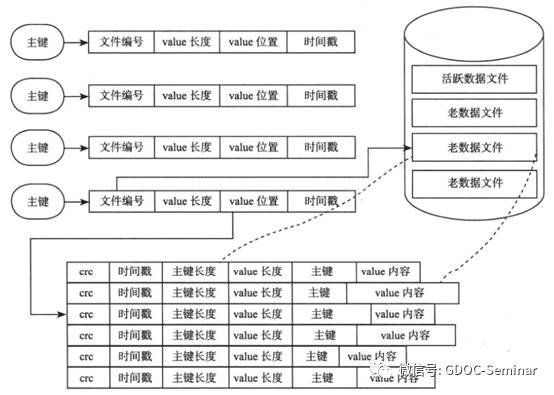
Bitcast仅支持追加操作(Append-only),即所有的写操作只追加而不修改老的数据。在Bitcast系统中,每个文件有一定的大小限制,当文件增加到相应的大小时,就会产生一个新的文件,老的文件只读不写。在任意时刻,只有一个文件是可写的,用于数据追加,称为活跃数据文件(active data file)。而其他已经达到大小限制的文件,称为老数据文件(older data file)。
Bitcast数据文件中的数据是一条一条的写入操作,每一条记录的数据项分别为主键(key)、value内容(value)、主键长度(key_sz)、value长度(value_sz)、时间戳(timestamp)以及crc校验值。(数据删除操作也不会删除旧的条目,而是将value设定为一个特殊的值用作标识)。内存中采用基于哈希表的索引数据结构,哈希表的作用是通过主键快速地定位到value的位置。哈希表结构中的每一项包含了三个用于定位数据的信息,分别是文件编号(file id),value在文件中的位置(value_pos),value长度(value_sz),通过读取file_id对应文件的value_pos开始的value_sz个字节,这就得到了最终的value值。写入时首先将Key-Value记录追加到活跃数据文件的末尾,接着更新内存哈希表,因此,每个写操作总共需要进行一次顺序的磁盘写入和一次内存操作。
Bitcast系统中的记录删除或者更新后,原来的记录成为垃圾数据。如果这些数据一直保存下去,文件会无限膨胀下去,为了解决这个问题,Bitcask需要定期执行合并(Compaction)操作以实现垃圾回收。所谓合并操作,即将所有老数据文件中的数据扫描一遍并生成新的数据文件,这里的合并其实就是对同一个key的多个操作以只保留最新一个的原则进行删除,每次合并后,新生成的数据文件就不再有冗余数据了。
Bitcast系统中的哈希索引存储在内存中,如果不做额外的工作,服务器断电重启重建哈希表需要扫描一遍数据文件,如果数据文件很大,这是一个非常耗时的过程。Bitcask通过索引文件(hint file)来提高重建哈希表的速度。
简单来说,索引文件就是将内存中的哈希索引表转储到磁盘生成的结果文件。Bitcast对老数据文件进行合并操作时,会产生新的数据文件,这个过程中还会产生一个索引文件,这个索引文件记录每一条记录的哈希索引信息。与数据文件不同的是,索引文件并不存储具体的value值,只存储value的位置(与内存哈希表一样)。这样,在重建哈希表时,就不需要扫描所有数据文件,而仅仅需要将索引文件中的数据一行行读取并重建即可,大大减少了重启后的恢复时间。
02
—
B+树存储引擎——Mysql InnoDB
相比哈希存储引擎,B树存储引擎不仅支持随机读取,还支持范围扫描。关系数据库中通过索引访问数据,在Mysql InnoDB中,有一个称为聚集索引的特殊索引,行的数据存于其中,组织成B+树(B树的一种)数据结构。

MySQLInnoDB按照页面(Page)来组织数据,每个页面对应B+树的一个节点。其中,叶子节点保存每行的完整数据,非叶子节点保存索引信息。数据在每个节点中有序存储,数据库查询时需要从根节点开始二分查找直到叶子节点,每次读取一个节点,如果对应的页面不在内存中,需要从磁盘中读取并缓存起来。B+树的根节点是常驻内存的,因此,B+树一次检索最多需要h-1次磁盘IO,复杂度为O(h)=O(logdN)(N为元素个数,d为每个节点的出度,h为B+树高度)。修改操作首先需要记录提交日志,接着修改内存中的B+树。如果内存中的被修改过的页面超过一定的比率,后台线程会将这些页面刷到磁盘中持久化。
03
—
LSM树存储引擎
LSM树索引其核心思想就是放弃部分读能力,换取写入的最大化能力,即若机器内存足够大,不需要一旦有数据更新就须将数据写入到磁盘中,先可以将更新的数据驻留在内存中,等到积累足够多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘中。
有关LSM树存储引擎的具体介绍将在文章《LSM树存储引擎》中介绍。
