





我们对于非结构化文本来做一下数据挖掘:以2个杭州求职群的聊天记录为例。时间节点是2020年5月28日-2020年6月10日
我们选取的数据是5.28日-6.10日期间的聊天记录
首先我们来看看大家喜欢聊什么?
一聊天的内容(内容和出现频率)
myfile.freq[1:30,]
words freq
1 工资 526
2 工作 515
3 小时 406
4 杭州 363
5 公司 317
6 要求 256
7 不限 231
8 提成 211
9 待遇 211
10 可以 198
11 上班 196
12 年龄 196
13 综合 193
14 提供 190
15 时间 184
16 免费 181
17 吃住 179
18 微信 176
19 包吃 168
20 一天 165
21 宿舍 163
22 培训 162
23 男女 156
24 招人 154
25 封顶 141
26 正常 140
27 开始 140
28 保底 137
29 招聘 134
30 公寓 132
献上更直观的词云图

二.聊天的活跃日期和时间段
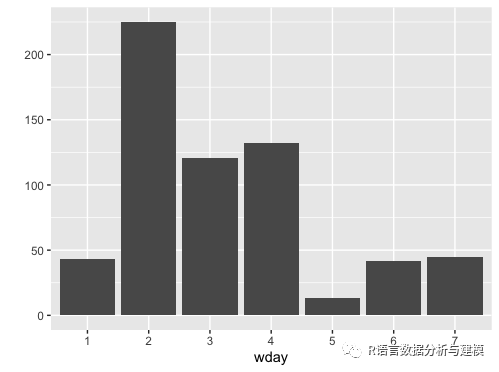
周二最为活跃
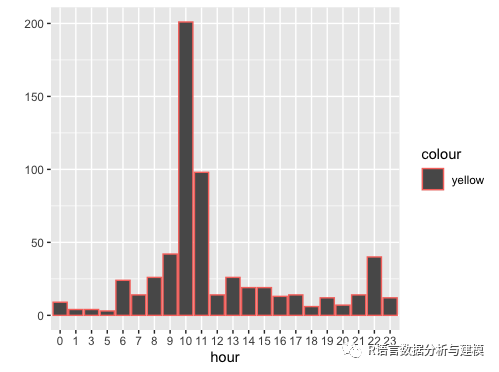
其中聊天记录共计621条,有效聊天人次是186人次
最为活跃的时间段是早上10:00-11:00
聊天记录超过150条的是”2020-06-01”
聊天记录超过100条的是"2020-06-01" "2020-06-09" "2020-06-10"
三.活跃人员和活跃天数
前十大发言人数:
(235093****)
\ua9c1༂༻༒༺༂\ua9c2(59964****)
(276772****)
A_小低调(118779****)
我是一只猫(146186****)
杭州-梧桐(148116****)
侧颜G(61058****)
(137031****)
错过了. 就不再来(160364****)
谁\U0001f612呀!(24545****)
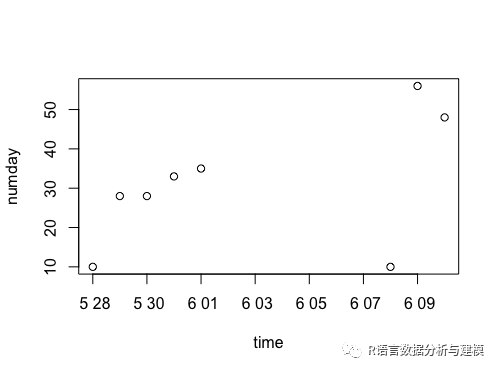
活跃天数
2020-05-28 2020-05-28 10
2020-05-29 2020-05-29 28
2020-05-30 2020-05-30 28
2020-05-31 2020-05-31 33
2020-06-01 2020-06-01 35
2020-06-08 2020-06-08 10
2020-06-09 2020-06-09 56
2020-06-10 2020-06-10 48
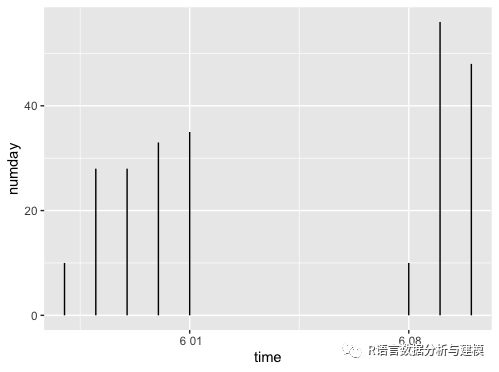
同款散点图
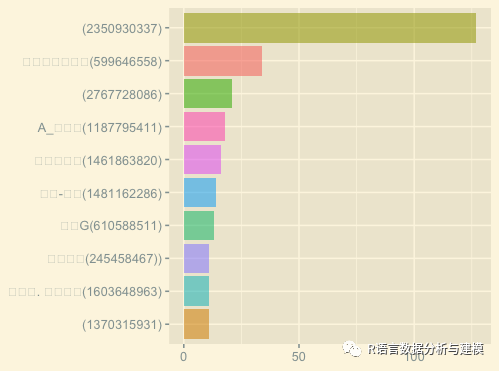
活跃人数前10名和频次
这款最好看,采用ggthemes包制作的
代码下篇文章发~
