





作者 罗小波 · 沃趣科技高级数据库技术专家
出品 沃趣科技

1、环境信息
主从库:双一、long_query_time=1、binlog_rows_query_log_events=ON、binlog_format=row、slow_query_log=ON、innodb_buffer_pool_size=10G、max_binlog_size=512M
从库:双TABLE、log_slow_slave_statements=ON、slave_parallel_type=LOGICAL_CLOCK、slave_parallel_workers=16、slave_preserve_commit_order=ON、slave_rows_search_algorithms='INDEX_SCAN,HASH_SCAN'、log_slave_updates=ON
主库:10.10.30.162
从库:10.10.30.163
CPU:8 vcpus
内存:16G
磁盘:100G(LSI 1.6T FLASH卡)
sysbench:sysbench 1.0.9
percona-toolkit:percona-toolkit-3.0.13-1.el7.x86_64
2、环境准备
mysql > call sys.ps_setup_enable_instrument('wait');
+-------------------------+
| summary |
+-------------------------+
| Enabled 310 instruments |
+-------------------------+
1 row in set (0.01 sec)
Query OK, 0 rows affected (0.01 sec)
mysql > call sys.ps_setup_enable_consumer('wait');
+---------------------+
| summary |
+---------------------+
| Enabled 3 consumers |
+---------------------+
1 row in set (0.00 sec)
主库造数2张1000W的表。
# 造数命令
[root@physical-machine ~]# sysbench --db-driver=mysql --time=99999 --threads=2 --report-interval=1 --mysql-host=10.10.30.162 --mysql-port=3306 --mysql-user=qbench --mysql-password=qbench --mysql-db=sbtest --tables=2 --table-size=10000000 oltp_read_write --db-ps-mode=disable prepare
# 表结构
CREATE TABLE `sbtest1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`k` int(11) NOT NULL DEFAULT '0',
`c` char(120) COLLATE utf8_bin NOT NULL DEFAULT '',
`pad` varchar(70) COLLATE utf8_bin NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `k_1` (`k`)
) ENGINE=InnoDB AUTO_INCREMENT=20000001 DEFAULT CHARSET=utf8 COLLATE=utf8_bin # 这里AUTO_INCREMENT=20000001是因为自增步长参数设置为了2,实际上数据只插入了1000W行
主库造数完成之后,查看从库复制状态,确认从库复制无延迟。
mysql > show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.10.30.162
Master_User: repl
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: mysql-bin.000015
Read_Master_Log_Pos: 215657137
Relay_Log_File: mysql-relay-bin.000044
Relay_Log_Pos: 215657350
Relay_Master_Log_File: mysql-bin.000015
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Exec_Master_Log_Pos: 215657137
Relay_Log_Space: 215657644
......
Seconds_Behind_Master: 0
......
Retrieved_Gtid_Set: 6f43ada4-d39d-11e9-9c97-5254002a54f2:1-7485
Executed_Gtid_Set: 6f43ada4-d39d-11e9-9c97-5254002a54f2:1-7485
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
# 从上述内容中,我们可以通过两种方式判断是否存在复制延迟(仅从SQL线程追赶IO线程的角度衡量,如果是IO线程读取的binlog日志本身与主库存在延迟,在从库侧无法判断,需要结合主从的实际情况进行判断)
## 方法一:比对二进制日志文件和位置信息,Master_Log_File = Relay_Master_Log_File && Read_Master_Log_Pos = Exec_Master_Log_Pos,如果它们完全相等,则说明从库侧无复制延迟
## 方法二:比对GTID SET信息,Retrieved_Gtid_Set = Executed_Gtid_Set,如果它们完全相等,则说明从库侧无复制延迟
主从库各自清理performance_schema统计数据,并切换binlog,避免对后续的操作过程造成干扰。
# 清理ps统计数据(sys.ps_truncate_all_tables()函数的作用:清空performance_schema下的%summary%和%history%表,有一个传参,表示是否在每一张表执行清空前打印表名,如果为FALSE,则不打印, 只在执行操作完成最后打印总操作表数量)
mysql > CALL sys.ps_truncate_all_tables(false);
+---------------------+
| summary |
+---------------------+
| Truncated 44 tables |
+---------------------+
1 row in set (0.09 sec)
Query OK, 0 rows affected (0.09 sec)
# 切换binlog
mysql > flush binary logs;
Query OK, 0 rows affected (0.02 sec)
主从库分别执行一个加压辅助脚本,主库并行执行2个UPDATE语句(分别对sbtest1和sbtest2表发起UPDATE操作),从库并行执行2个SELECT语句(分别对sbtest1和sbtest2表发起SELECT操作)(脚本代码详见文末的下载链接)。
# 主库(该脚本会按照指定的时间间隔循环检查执行时长超过该指定间隔时间的会话状态,如果存在超时的会话,则尝试使用show processlist语句、sys.session视图打印更加详细的会话信息,并尝试使用sys.innodb_lock_waits视图打印锁等待信息;如果不存在超时会话,则并行使用2个会话对指定的表执行UPDATE语句,注意:脚本中的两个UPDATE语句的id取值为id列的一个较小值,不要与后续需要执行的大事务中的id值范围有锁冲突)
[root@physical-machine ~]# sh exec_parallel_sql_master.sh
## 脚本运行过程中,会按照指定的时间间隔打印一些执行日志,每打印一次就表示UPDATE语句执行成功了一次
now() mark
2019-09-11 13:40:36 ------------------
now() mark
2019-09-11 13:40:37 ------------------
now() mark
2019-09-11 13:40:37 ------------------
......
# 从库(与主库中的exec_parallel_sql_master.sh脚本作用类似,但在从库中,不存在超时会话时,并行运行的语句从UPDATE改为SELECT)
[root@node2 ~]# sh exec_parallel_sql_slave.sh
## 脚本运行过程中,会按照指定的时间间隔打印一些执行日志,以及SELECT语句的查询结果
2019-09-11 13:40:54 ------------------
id k c pad
1000001 4982373 33215995692-11643009243-86512240766-52474552185-05677806687-01251571470-76461373271-04600478707-30936631606-18731704317 91106890267-89662465049-88180742274-99973317521-51514147703
now() mark
2019-09-11 13:40:55 ------------------
id k c pad
2000001 4979176 84112274222-72580329847-55073805313-86104475687-27118798543-60440415134-55566695297-03778364972-89646151895-46966443039 40891678273-04756075401-41893687834-80508607710-52345565443
now() mark
2019-09-11 13:40:55 ------------------
......
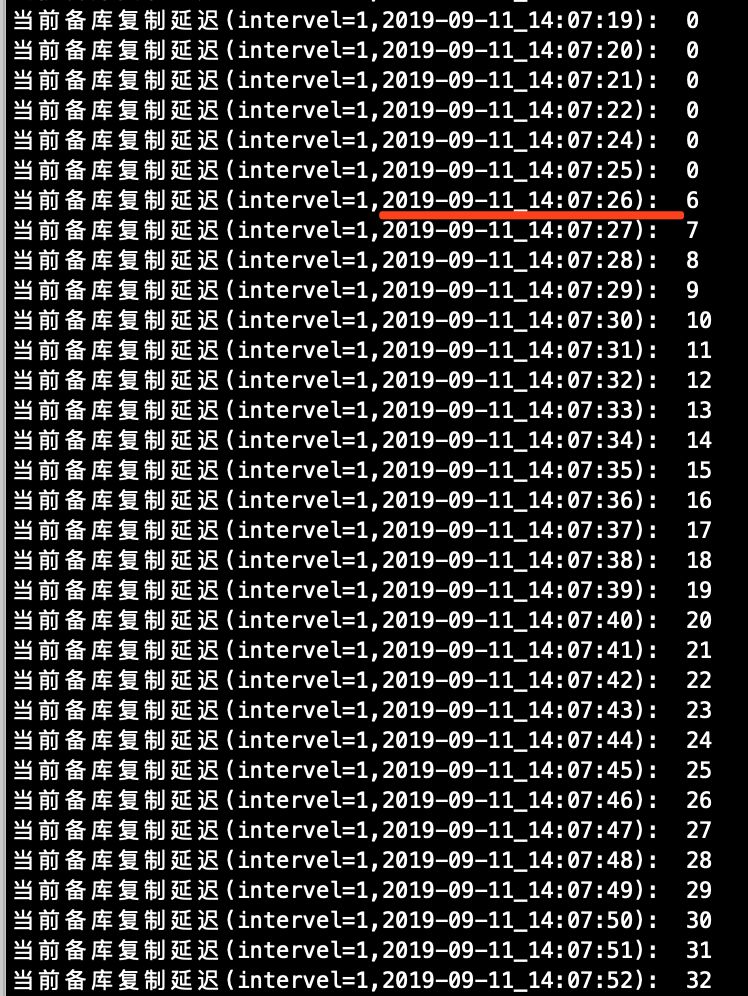
另起一个ssh终端会话,在从库运行一个每秒查询复制延迟的脚本(脚本代码详见文末的下载链接)。
[root@node2 ~]# sh check_slave_delay.sh
# 脚本运行过程中,会按照指定的时间间隔打印一些执行日志
当前备库复制延迟(intervel=1,2019-09-11_13:41:31): 0
当前备库复制延迟(intervel=1,2019-09-11_13:41:32): 0
当前备库复制延迟(intervel=1,2019-09-11_13:41:33): 0
......
主从库各自先查看一下慢查询日志、解析binlog,并分析慢查询日志(这里的步骤是为了与后续执行完成大事务后的分析结果做对比,没有对比就没有伤害嘛)。
# 主从库慢查询日志
## 查看主库慢查询日志文件,可以发现并没有慢查询日志内容
[root@node1 ~]# cat /data//mysqldata1/slowlog/slow-query.log
/usr/local/mysql/bin/mysqld, Version: 5.7.27-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /home/mysql/data/mysqldata1/sock/mysql.sock
Time Id Command Argument
......
[root@node1 ~]#
## 查看从库慢查询日志文件,可以发现仍然没有慢查询日志内容
[root@node2 ~]# cat /data//mysqldata1/slowlog/slow-query.log
/usr/local/mysql/bin/mysqld, Version: 5.7.27-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /home/mysql/data/mysqldata1/sock/mysql.sock
Time Id Command Argument
......
[root@node2 ~]#
# 主从库解析binlog,并分析慢查询日志
## 主库解析最后一个binlog,并使用pt-query-digest工具进行慢查询日志分析
[root@node1 binlog]# mysqlbinlog -vv mysql-bin.000023 > a.sql
[root@node1 binlog]# pt-query-digest --type=binlog a.sql
...... 解析结果详见下图1
## 从库解析最后一个binlog,并使用pt-query-digest工具进行慢查询日志分析
[root@node2 binlog]# mysqlbinlog -vv mysql-bin.000023 > b.sql
[root@node2 binlog]# pt-query-digest --type=binlog b.sql
......解析结果详见下图2
pt-query_digest 解析结果截图。
图1(主库)
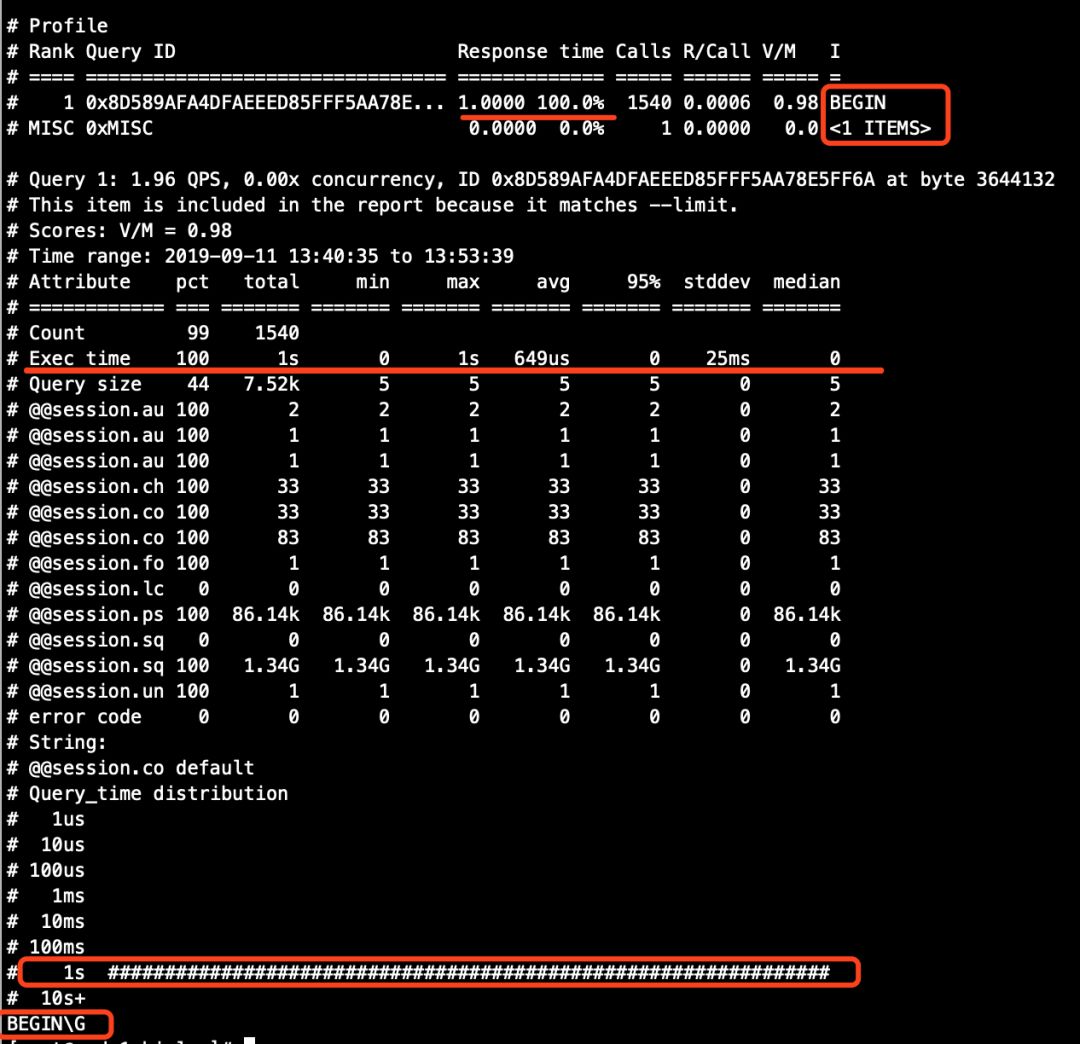
图2(从库)
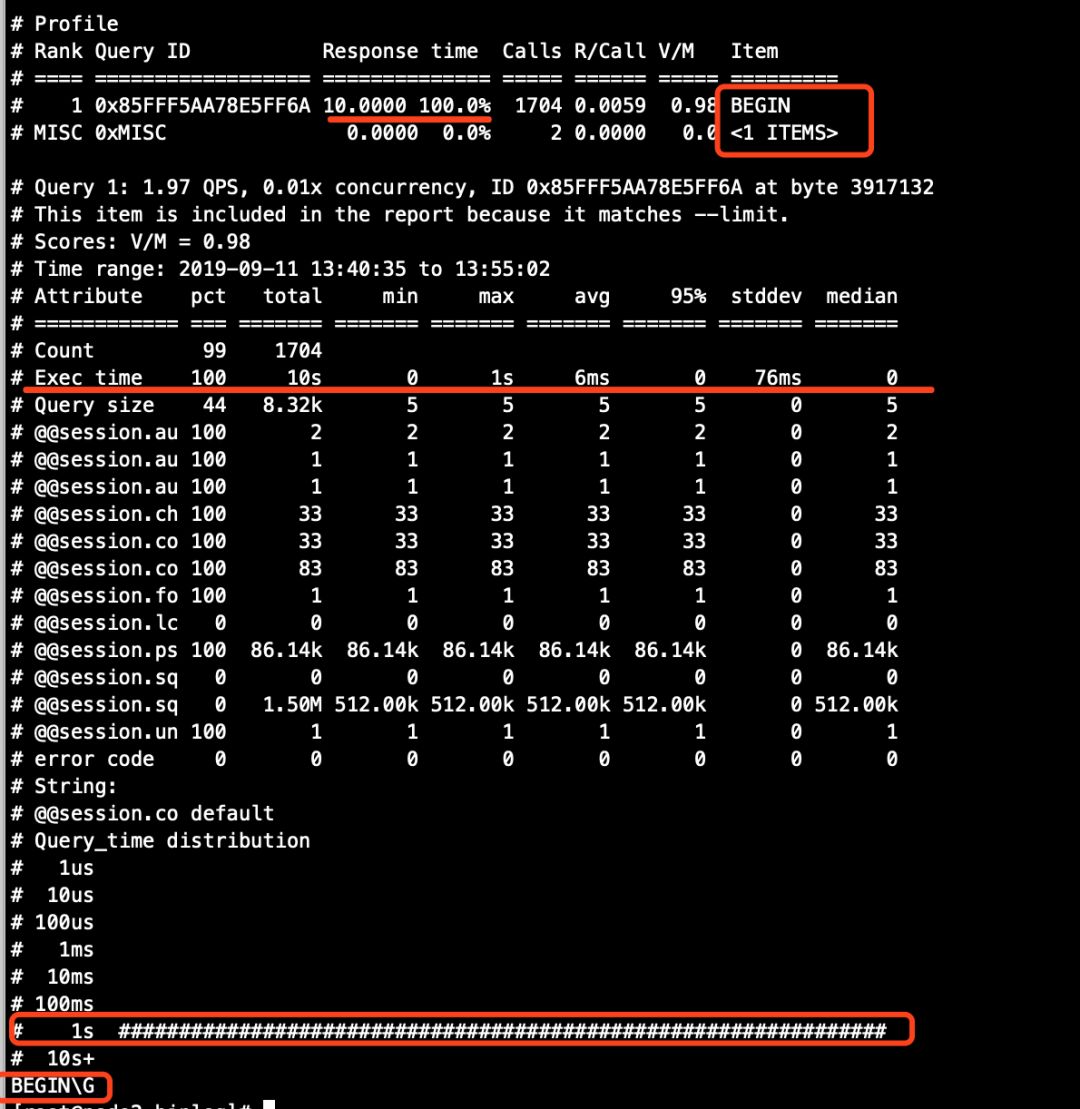
# 主库(从这里可以看到,exec_time>0的记录为1行,所以主库的binlog分析结果中,第一个语句也是唯一的一个语句的Exec time行的Total列是1S)
[root@node1 binlog]# cat a.sql |grep exec_time |grep -v 'exec_time=0'
#190911 13:52:26 server id 33061 end_log_pos 1010517 CRC32 0x9481512e Query thread_id=96524 exec_time=1 error_code=0
# 从库(从这里可以看到,exec_time>0的有10行记录,每行都是1,所以从库的binlog分析结果中,第一个语句也是唯一的一个语句的Exec time行的Total列是10S)
[root@node2 binlog]# cat b.sql |grep exec_time |grep -v 'exec_time=0'
#190911 13:42:44 server id 33061 end_log_pos 181363 CRC32 0x0be0bb2f Query thread_id=88584 exec_time=1 error_code=0
#190911 13:42:45 server id 33061 end_log_pos 182787 CRC32 0x86386f64 Query thread_id=88587 exec_time=1 error_code=0
#190911 13:44:26 server id 33061 end_log_pos 323911 CRC32 0x258368bc Query thread_id=89320 exec_time=1 error_code=0
#190911 13:46:16 server id 33061 end_log_pos 477703 CRC32 0xb91bf3e6 Query thread_id=90964 exec_time=1 error_code=0
#190911 13:47:04 server id 33061 end_log_pos 545343 CRC32 0x8dae4390 Query thread_id=91691 exec_time=1 error_code=0
#190911 13:48:53 server id 33061 end_log_pos 697711 CRC32 0xcbe1b667 Query thread_id=93332 exec_time=1 error_code=0
#190911 13:48:54 server id 33061 end_log_pos 698423 CRC32 0x44114126 Query thread_id=93338 exec_time=1 error_code=0
#190911 13:50:41 server id 33061 end_log_pos 847943 CRC32 0x27c5a588 Query thread_id=94939 exec_time=1 error_code=0
#190911 13:52:26 server id 33061 end_log_pos 995327 CRC32 0x3307103c Query thread_id=96524 exec_time=1 error_code=0
#190911 13:53:19 server id 33061 end_log_pos 1069375 CRC32 0x0540667c Query thread_id=97310 exec_time=1 error_code=0
现在,准备工作已经就绪,在主从库中执行切换binlog,准备入场了。
mysql > flush binary logs;
3、执行大事务
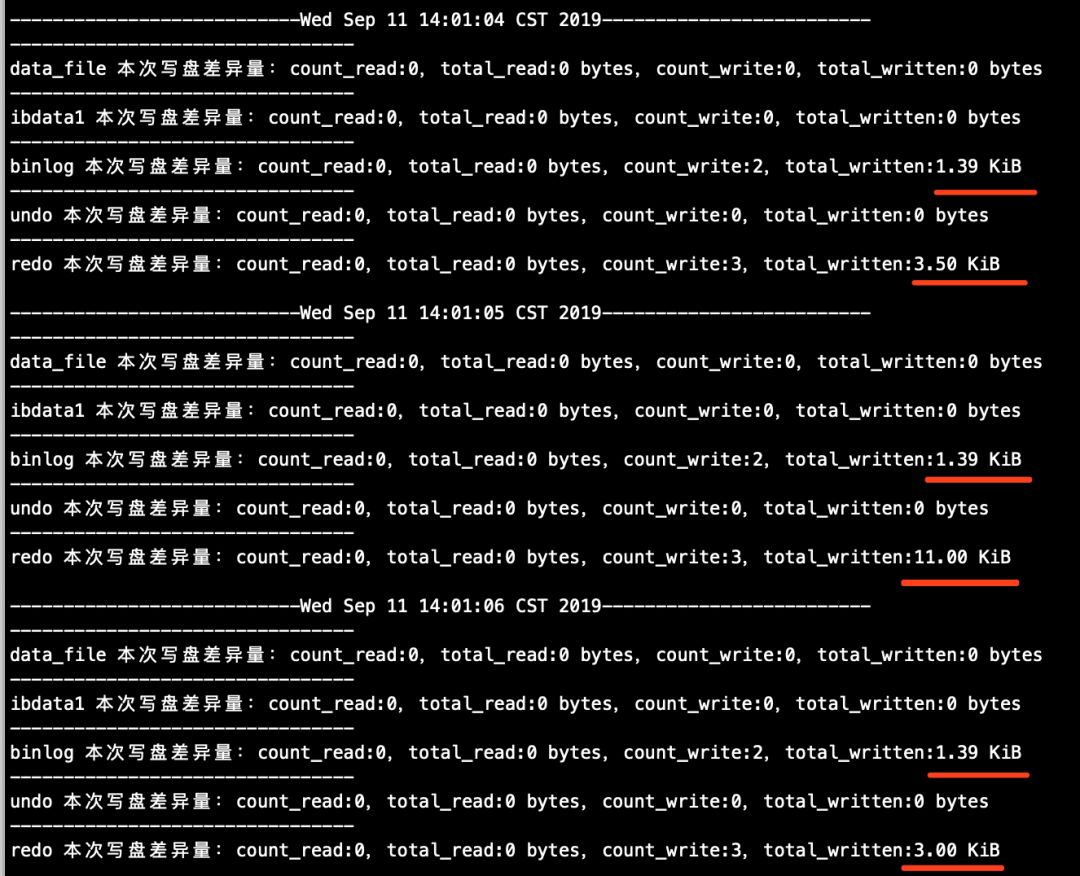
# 该脚本的作用是,按照指定间隔时间,从sys.x$io_global_by_file_by_bytes视图中抓取文件IO吞吐数据,该视图中的数据基本可以认为是实时数据(详情可查看微信公众号"沃趣技术"中的sys schema系列文章)。注意,针对主库运行的脚本中的mysql_ip参数修改为主库IP,针对从库运行的脚本中mysql_ip参数修改为从库IP
## 主库(执行打印结果详见下图3)
[root@node1 ~]# sh count_mysql_disk_file_io.sh
## 从库(执行打印结果详见下图4)
[root@node2 ~]# sh count_mysql_disk_file_io.sh
count_mysql_disk_file_io.sh脚本打印截图如下:
图3(主库)
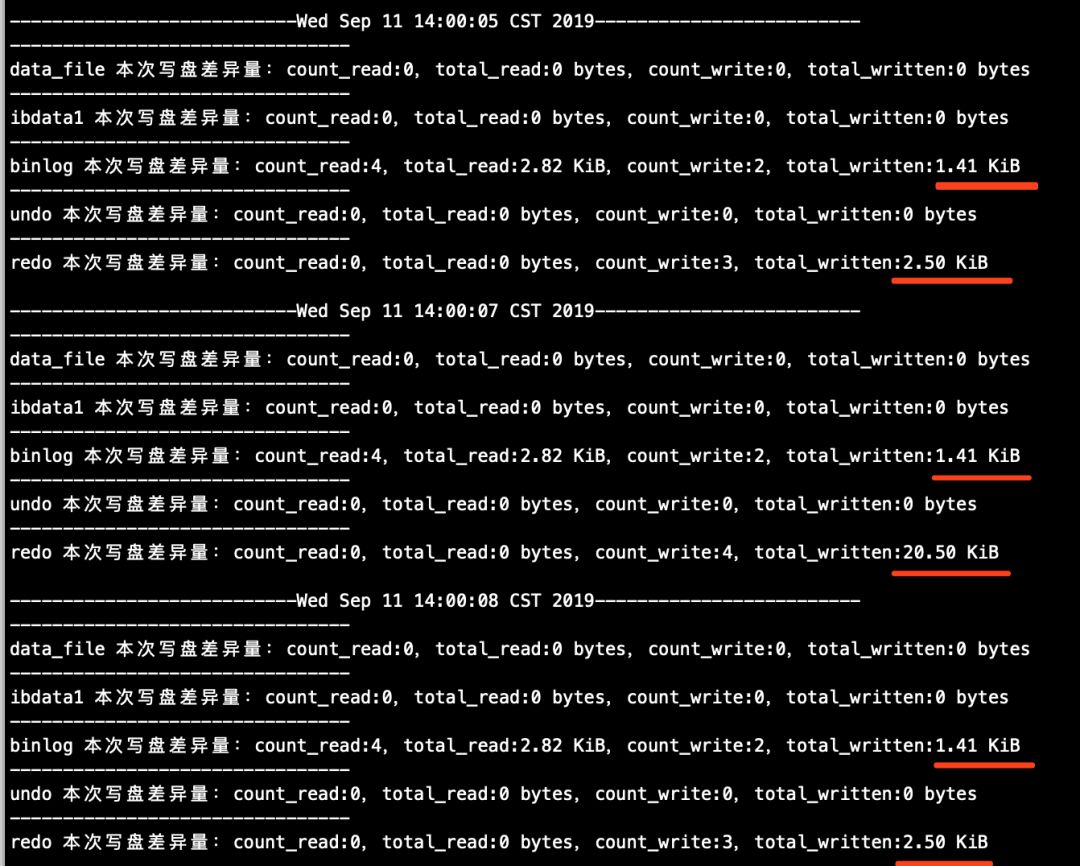
图4(从库)
# 主库(执行结果详见下图5)
mysql > select * from sys.io_global_by_file_by_bytes where count_read!=0 order by count_read desc;
......
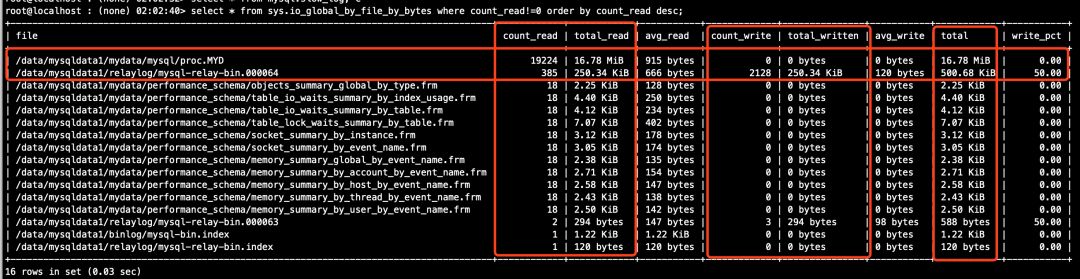
# 从库(执行结果详见下图6)
mysql > select * from sys.io_global_by_file_by_bytes where count_read!=0 order by count_read desc;
......
sys.io_global_by_file_by_bytes视图的执行结果截图如下:
图5(主库)
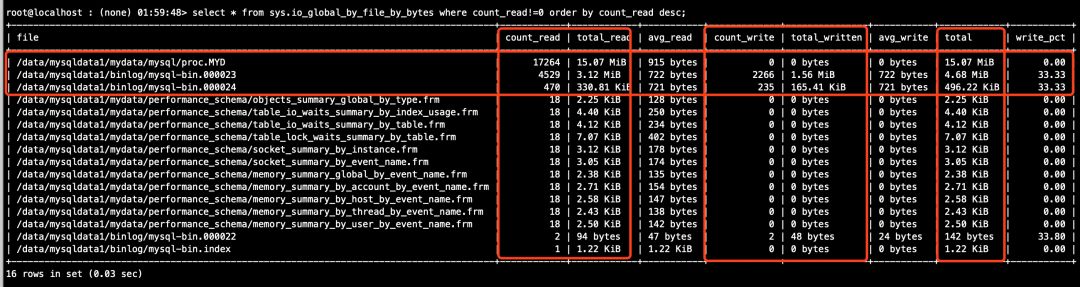
图6(从库)
mysql > use sbtest
Database changed
# 注意,这里不要加limit,会干扰exec_parallel_sql_master.sh和exec_parallel_sql_slave.sh脚本中的判断逻辑(通过上述环境信息可知,我们造数为1000W,且自增不长设置为2,所以,id>10000000大概是500W行的数据量级别)
mysql > explain update sbtest1 set k=k+1 where id>10000000;
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
| 1 | UPDATE | sbtest1 | NULL | range | PRIMARY | PRIMARY | 4 | const | 4938195 | 100.00 | Using where |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+---------+----------+-------------+
1 row in set (0.00 sec)
# 使用显式的事务执行该语句
mysql > begin; update sbtest1 set k=k+1 where id>10000000;commit;
......
在主库大事务未执行完成之前,可在主库反复执行show processlist查看线程状态信息(该步骤不是必须的)。
mysql > show processlist;
+--------+------+--------------------+--------+------------------+-------+---------------+--------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+--------+------+--------------------+--------+------------------+-------+----------------+--------------------------------------------+
| 4 | repl | 10.10.30.163:33375 | NULL | Binlog Dump GTID | 80999 | Master has sent all binlog to slave; waiting for more updates | NULL |
| 5 | repl | 10.10.30.164:49847 | NULL | Binlog Dump GTID | 80998 | Master has sent all binlog to slave; waiting for more updates | NULL |
| 88201 | root | localhost | sbtest | Query | 19 | updating | update sbtest1 set k=k+1 where id>10000000 |
| 107409 | root | localhost | NULL | Query | 0 | starting | show processlist |
+--------+------+--------------------+--------+------------------+-------+-----------------+--------------------------------------------+
4 rows in set (0.00 sec)
查看主库中数据文件的流量吞吐情况(该信息为count_mysql_disk_file_io.sh脚本的打印日志),从下图中可以发现,事务未执行完成之前,除了binlog之外,表空间文件、共享表空间、undo、redo的磁盘流量都有不同程度的大幅增加,说明事务未提交时,这几种文件都会写盘且,binlog不写盘(以往没少听说过“事务提交之后,脏页在后台刷新”这种话吧?嘿,这话听起来挺有迷惑性的。事务提交之后,后台线程的确会做刷脏的事情,不过,这句话可没说事务未提交之前后台线程不刷脏。这样设计显然是合理的,否则大事务产生的脏页总量超过内存时,事务就无法执行了)。
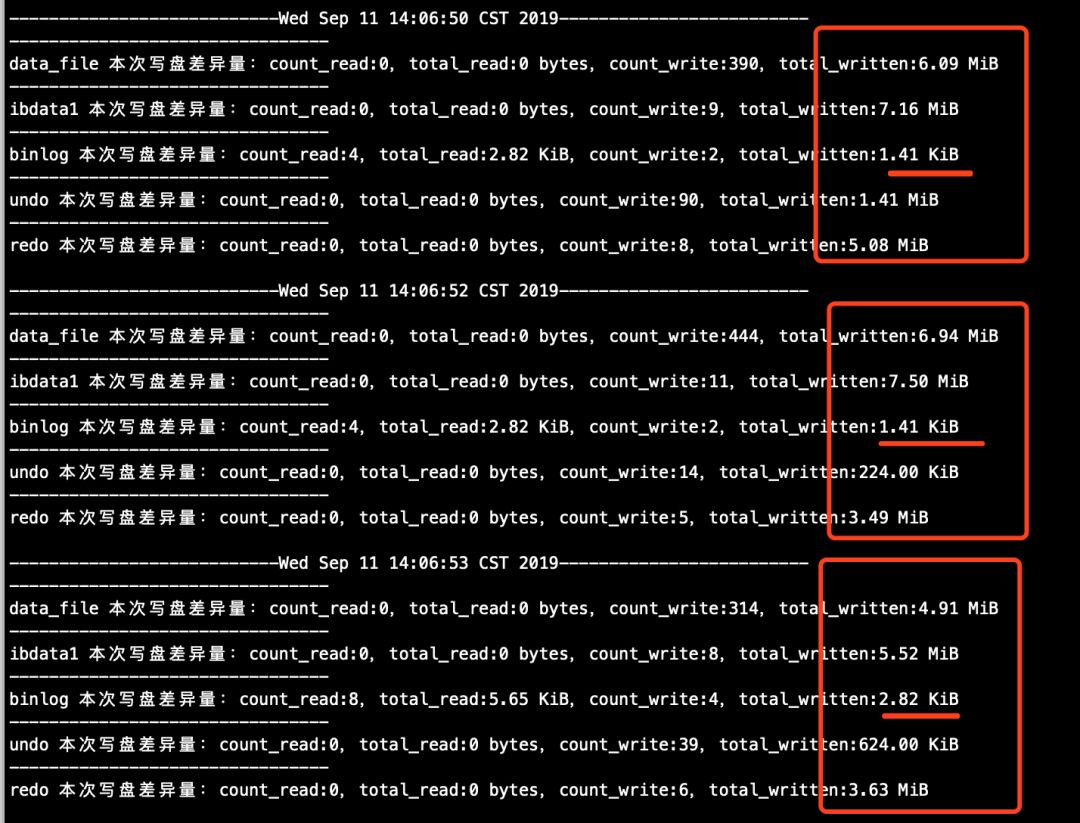
mysql > begin; update sbtest1 set k=k+1 where id>10000000;commit;
Query OK, 0 rows affected (0.00 sec) # 这里是begin语句执行的时间,为0.00 sec
Query OK, 5000000 rows affected (2 min 58.55 sec) # 这里可以看到UPDATE语句本身执行了2 min 58.55 sec
Rows matched: 5000000 Changed: 5000000 Warnings: 0
Query OK, 0 rows affected (5.01 sec) # 从这里可以看到,这里是UPDATE语句后边的commit语句,执行了5.01 sec
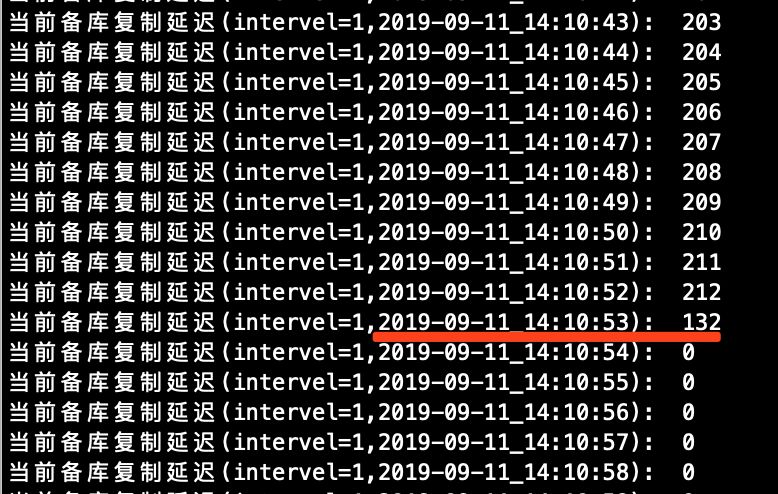
待到主库大事务执行完成之后,迅速观察从库的复制延迟情况,并查看下show processlist;
# 查看从库复制延迟
mysql > show slave status\G
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 10.10.30.162
Master_User: repl
Master_Port: 3306
Connect_Retry: 10
Master_Log_File: mysql-bin.000025
Read_Master_Log_Pos: 139733
Relay_Log_File: mysql-relay-bin.000064
Relay_Log_Pos: 642431
Relay_Master_Log_File: mysql-bin.000024
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
......
Exec_Master_Log_Pos: 642218
Relay_Log_Space: 1909355863
......
Seconds_Behind_Master: 101 # 从这里可以看到,这个延迟数值已经有126秒了(虽然不准确,但是这个量级的延迟数字已经足够说明复制存在延迟了)
......
Retrieved_Gtid_Set: 6f43ada4-d39d-11e9-9c97-5254002a54f2:1-27419
Executed_Gtid_Set: 6a3227ed-d39d-11e9-a7b0-525400c33752:1-2,
6f43ada4-d39d-11e9-9c97-5254002a54f2:1-27224
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name:
Master_TLS_Version:
1 row in set (0.00 sec)
# 查看从库线程状态
mysql > show processlist;
+--------+-------------+-----------+------+---------+-------+----------------+--------------------------------------------+
| Id | User | Host | db | Command | Time | State | Info |
+--------+-------------+-----------+------+---------+-------+---------------+--------------------------------------------+
| 5 | system user | | NULL | Connect | 81296 | Waiting for master to send event | NULL |
| 6 | system user | | NULL | Connect | 0 | Reading event from the relay log | NULL |
# 大事务的SQL语句在这里(注意,row格式下数据回放的是数据的逐行变更日志,并不是SQL语句文本,这里看到的SQL语句文本来自binlog_rows_query_log_events=ON参数记录的注释性的原始SQL文本,在从库回放主库binlog时会当做注释用途展示在这里)
| 7 | system user | | NULL | Connect | 316 | Executing event | update sbtest1 set k=k+1 where id>10000000 |
| 8 | system user | | NULL | Connect | 10270 | Waiting for an event from Coordinator | NULL |
| 9 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 10 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 11 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 12 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 13 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 14 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 15 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 16 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 17 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 18 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 19 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 20 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 21 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 22 | system user | | NULL | Connect | 81296 | Waiting for an event from Coordinator | NULL |
| 107297 | root | localhost | NULL | Sleep | 596 | | NULL |
| 127830 | root | localhost | NULL | Query | 0 | starting | show processlist |
+--------+-------------+-----------+------+---------+-------+-----------------+--------------------------------------------+
20 rows in set (0.00 sec)
顺便看一眼从库的数据文件流量探测脚本的情况(这些信息来自脚本count_mysql_disk_file_io.sh的打印日志),从下图中标记的地方,对比下主库的数据文件流量打印日志,可以发现它们在量级上是差不多的。
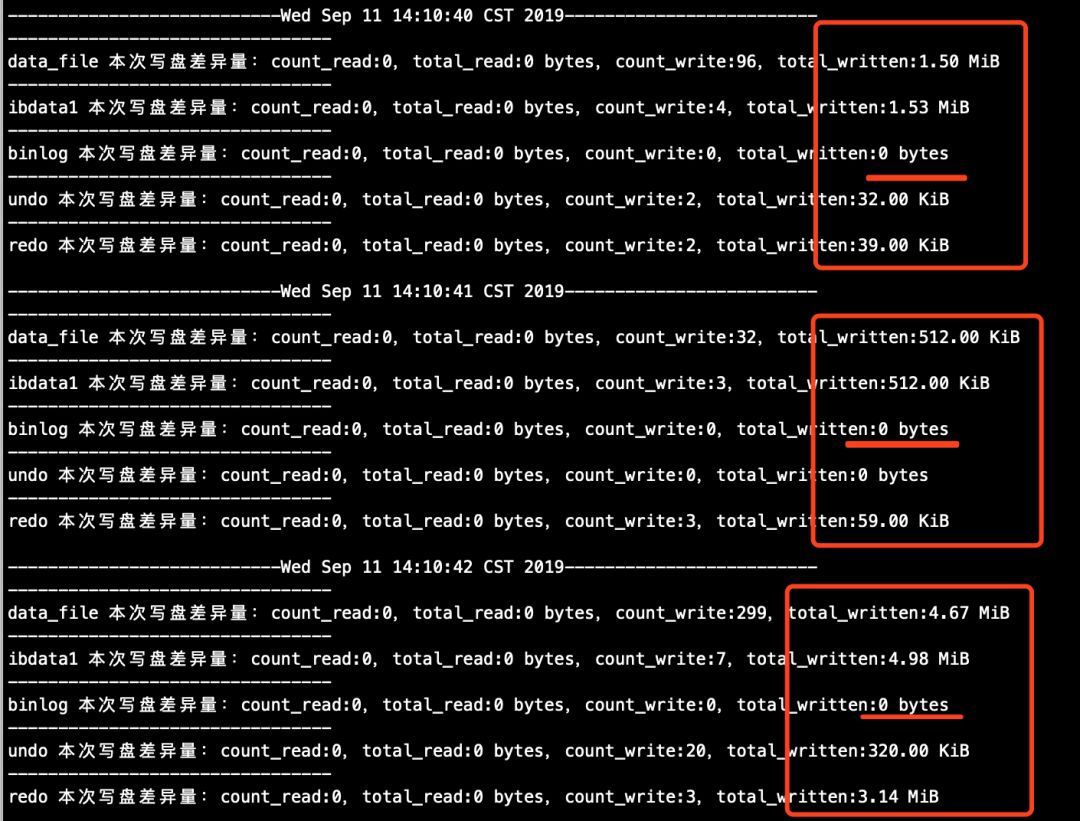
探测到开始大幅延迟的时间点。
探测到延迟结束的时间点。
# 主库(从下面找到的信息来看,大事务在主库的提交过程中,5秒左右就将binlog落盘完成了,紧随其后,大约有8秒的时间大量binlog读盘操作,这里是主库通过binlog dump线程将binlog发送给从库的过程。注意,如果sync_binlog不为1,那么在这个时候是否有大量binlog读盘操作不确定,有兴趣的同学自行测试)
[root@node1 ~]# grep -E 'Wed Sep|binlog' /tmp/count_mysql_disk_file_io.sh.log
---------------------------Wed Sep 11 14:07:19 CST 2019-------------------------
binlog 本次写盘差异量:count_read:4,total_read:2.82 KiB,count_write:2,total_written:1.41 KiB
---------------------------Wed Sep 11 14:07:20 CST 2019-------------------------
binlog 本次写盘差异量:count_read:4,total_read:2.82 KiB,count_write:51695,total_written:395.17 MiB
---------------------------Wed Sep 11 14:07:22 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:72236,total_written:552.22 MiB
---------------------------Wed Sep 11 14:07:23 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:63161,total_written:482.84 MiB
---------------------------Wed Sep 11 14:07:24 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:51005,total_written:389.92 MiB
---------------------------Wed Sep 11 14:07:25 CST 2019-------------------------
binlog 本次写盘差异量:count_read:35448,total_read:276.85 MiB,count_write:10,total_written:7.24 KiB
---------------------------Wed Sep 11 14:07:26 CST 2019-------------------------
binlog 本次写盘差异量:count_read:63276,total_read:494.19 MiB,count_write:2,total_written:1.41 KiB
---------------------------Wed Sep 11 14:07:28 CST 2019-------------------------
binlog 本次写盘差异量:count_read:72738,total_read:568.09 MiB,count_write:2,total_written:1.41 KiB
---------------------------Wed Sep 11 14:07:29 CST 2019-------------------------
binlog 本次写盘差异量:count_read:63220,total_read:493.69 MiB,count_write:2,total_written:1.41 KiB
---------------------------Wed Sep 11 14:07:30 CST 2019-------------------------
binlog 本次写盘差异量:count_read:73495,total_read:574.16 MiB,count_write:4,total_written:2.82 KiB
---------------------------Wed Sep 11 14:07:31 CST 2019-------------------------
binlog 本次写盘差异量:count_read:60512,total_read:472.76 MiB,count_write:2,total_written:1.41 KiB
---------------------------Wed Sep 11 14:07:32 CST 2019-------------------------
binlog 本次写盘差异量:count_read:69182,total_read:540.49 MiB,count_write:2,total_written:1.41 KiB
---------------------------Wed Sep 11 14:07:33 CST 2019-------------------------
binlog 本次写盘差异量:count_read:27818,total_read:217.25 MiB,count_write:2,total_written:1.41 KiB
---------------------------Wed Sep 11 14:07:35 CST 2019-------------------------
binlog 本次写盘差异量:count_read:4,total_read:2.82 KiB,count_write:2,total_written:1.41 KiB
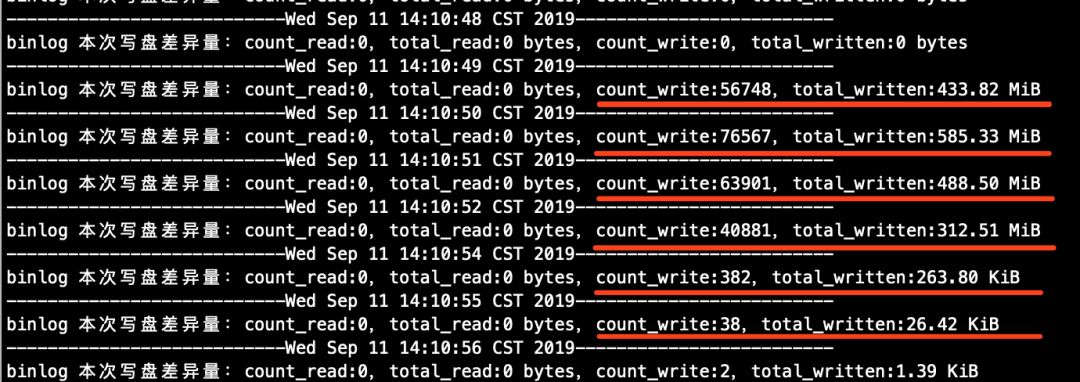
# 从库(从下面找到的信息来看,大事务在从库的提交过程中,6秒左右就将binlog落盘完成了。注意,这里指的是从库将大事务回放完成之后,写入自己的binlog文件的流量,而不是从库拉取主库binlog写relay log的流量)
[root@node2 ~]# grep -E 'Wed Sep|binlog' /tmp/count_mysql_disk_file_io.sh.log
......
---------------------------Wed Sep 11 14:10:48 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:0,total_written:0 bytes
---------------------------Wed Sep 11 14:10:49 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:56748,total_written:433.82 MiB
---------------------------Wed Sep 11 14:10:50 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:76567,total_written:585.33 MiB
---------------------------Wed Sep 11 14:10:51 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:63901,total_written:488.50 MiB
---------------------------Wed Sep 11 14:10:52 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:40881,total_written:312.51 MiB
---------------------------Wed Sep 11 14:10:54 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:382,total_written:263.80 KiB
---------------------------Wed Sep 11 14:10:55 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:38,total_written:26.42 KiB
---------------------------Wed Sep 11 14:10:56 CST 2019-------------------------
binlog 本次写盘差异量:count_read:0,total_read:0 bytes,count_write:2,total_written:1.39 KiB
......
上述代码段可能不便阅读,这里将上述内容截图列出。
图7(主库)
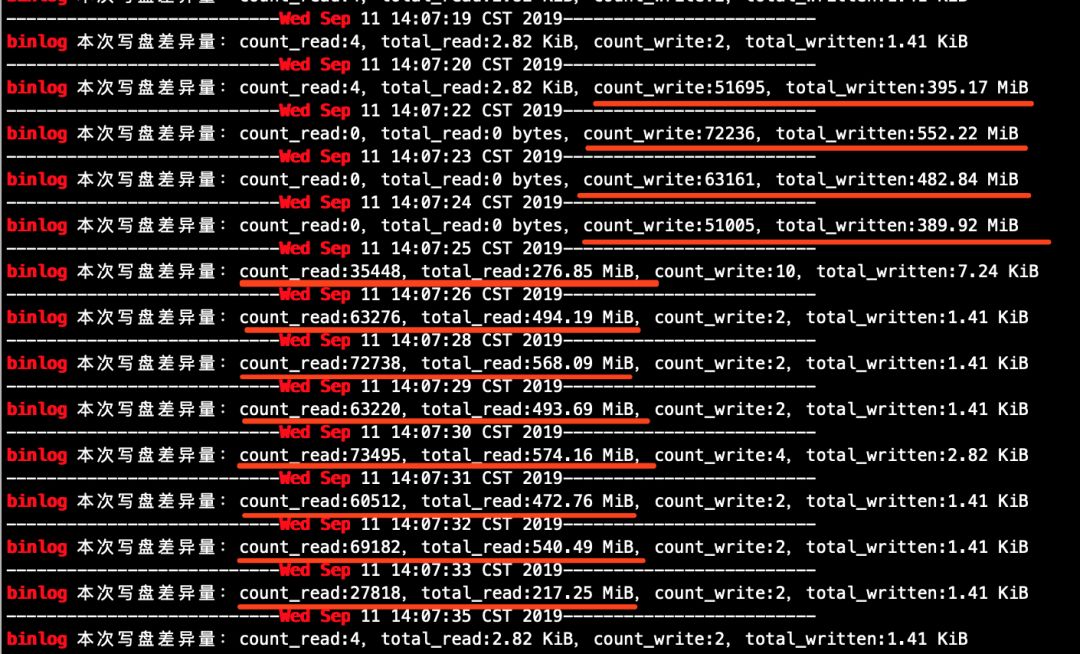
图8(从库)
4、分析大事务的影响
首先在主从库分别查看慢查询日志文件。
# 主库(发现大事务语句已经被记录在案了)
[root@node1 ~]# cat /data/mysqldata1/slowlog/slow-query.log
/usr/local/mysql/bin/mysqld, Version: 5.7.27-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /home/mysql/data/mysqldata1/sock/mysql.sock
Time Id Command Argument
......
# Time: 2019-09-11T14:07:20.291512+08:00
# User@Host: root[root] @ localhost [] Id: 88201
# Query_time: 178.546835 Lock_time: 0.000057 Rows_sent: 0 Rows_examined: 5000000
use sbtest;
SET timestamp=1568182040;
update sbtest1 set k=k+1 where id>10000000;
# Time: 2019-09-11T14:07:25.307290+08:00
# User@Host: admin[admin] @ [10.10.30.16] Id: 109940
# Query_time: 4.375712 Lock_time: 0.000000 Rows_sent: 0 Rows_examined: 0
SET timestamp=1568182045;
commit;
# 从库(咦,在从库的慢日志中,大事务逃脱了?嗯,看起来是的,因为咋们的复现环境是使用的row格式复制,回放过程中有效的日志记录只有数据的逐行变更记录,并不包含语句文本,不会完整地经过SQL层的一些流程,也就无法记录到慢查询日志中)
[root@node2 ~]# cat /data//mysqldata1/slowlog/slow-query.log
/usr/local/mysql/bin/mysqld, Version: 5.7.27-log (MySQL Community Server (GPL)). started with:
Tcp port: 3306 Unix socket: /home/mysql/data/mysqldata1/sock/mysql.sock
Time Id Command Argument
......
顺便用pt-query-digest工具解析下主库的慢查询日志,截个图列出。
图9(主库)
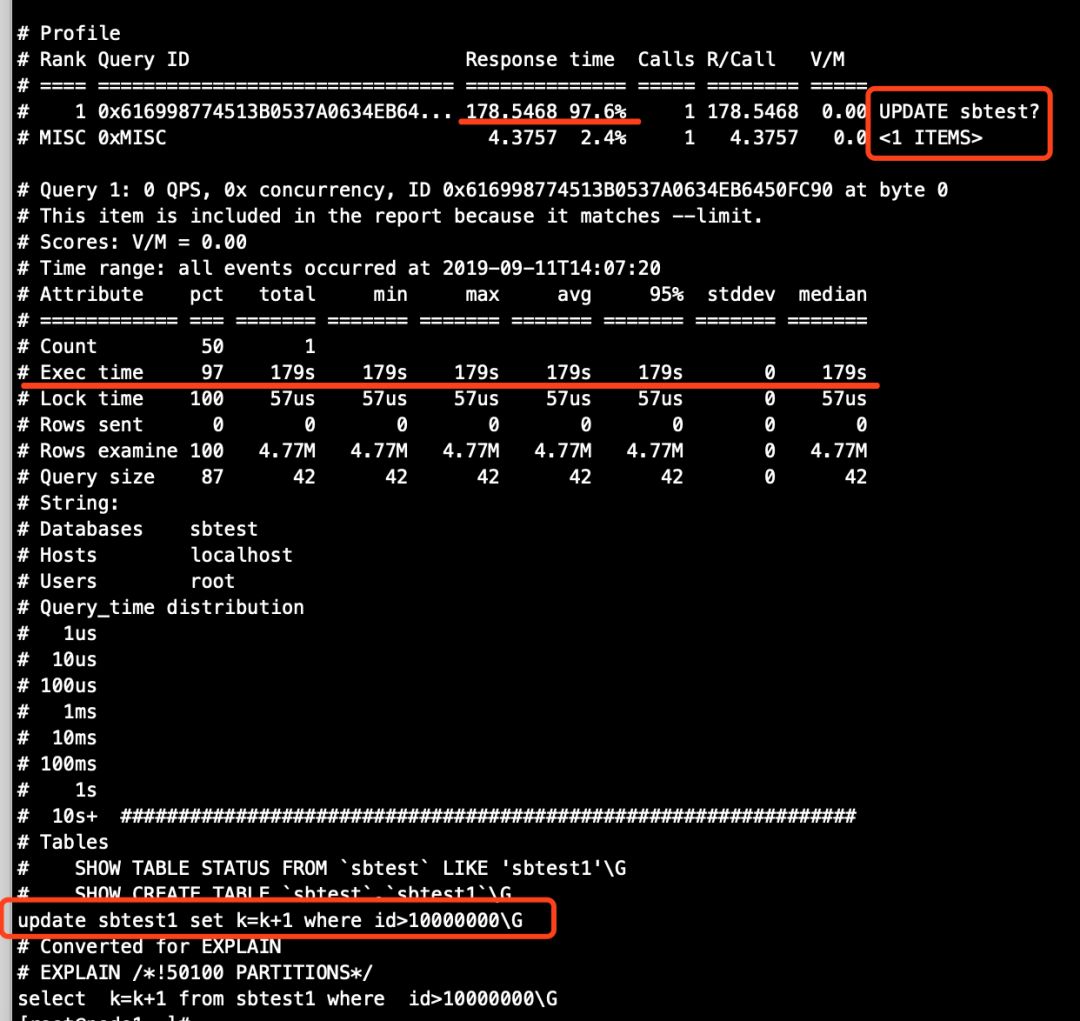
图10(从库)

现在,在主从库分别解析binlog日志查看,并使用pt-query-digest工具分析binlog。
# 主库(解析最后2个binlog,为什么要解析最后2个binlog呢,因为大事务一定不在倒数第一个binlog中,大事务执行完成之后,binlog尺寸会因为超过了max_binlog_size设置的大小,而立即进行日志切换,当然,如果大事务执行完成之后,后续没有新的事务进来,binlog就不一定会立即进行切换了)
[root@node1 binlog]# ls -lh
total 13G
......
-rw-r----- 1 mysql mysql 1.8G Sep 11 14:07 mysql-bin.000024
-rw-r----- 1 mysql mysql 449K Sep 11 14:12 mysql-bin.000025
-rw-r----- 1 mysql mysql 1.3K Sep 11 14:07 mysql-bin.index
[root@node1 binlog]# mysqlbinlog mysql-bin.000024 mysql-bin.000025 > b.sql
[root@node1 binlog]# ls -lh b.sql
-rw-r--r-- 1 root root 2.5G Sep 11 15:38 b.sql
[root@node1 binlog]# pt-query-digest --type=binlog b.sql
# 大事务的解析结果比较大,使用pt-query-digest工具解析会发生(core dumped),pt-query-digest工具解析时不需要用到BINLOG编码,所以,这里可以将binlog中不需要的BINLOG编码过滤掉再进行解析
[root@node1 binlog]# grep -E '\#|/\*|SET|BEGIN|COMMIT|DELIMITER' b.sql > b.txt
[root@node1 binlog]# ls -lh b.txt
-rw-r--r-- 1 root root 28M Sep 11 16:52 b.txt
[root@node1 binlog]# pt-query-digest --type=binlog b.txt
...... # 解析结果详见图11
# 从库
[root@node2 binlog]# ls -lh
total 13G
......
-rw-r----- 1 mysql mysql 1.8G Sep 11 14:10 mysql-bin.000024
-rw-r----- 1 mysql mysql 442K Sep 11 14:12 mysql-bin.000025
[root@node2 binlog]# mysqlbinlog mysql-bin.000024 mysql-bin.000025 > c.sql
[root@node2 binlog]# ls -lh c.sql
-rw-r--r-- 1 root root 2.5G Sep 11 15:42 c.sql
[root@node2 binlog]# grep -E '\#|/\*|SET|BEGIN|COMMIT|DELIMITER' c.sql > c.txt
[root@node2 binlog]# pt-query-digest --type=binlog c.txt
...... # 解析结果详见图12
pt-query_digest 解析结果截图。
图11(主库)
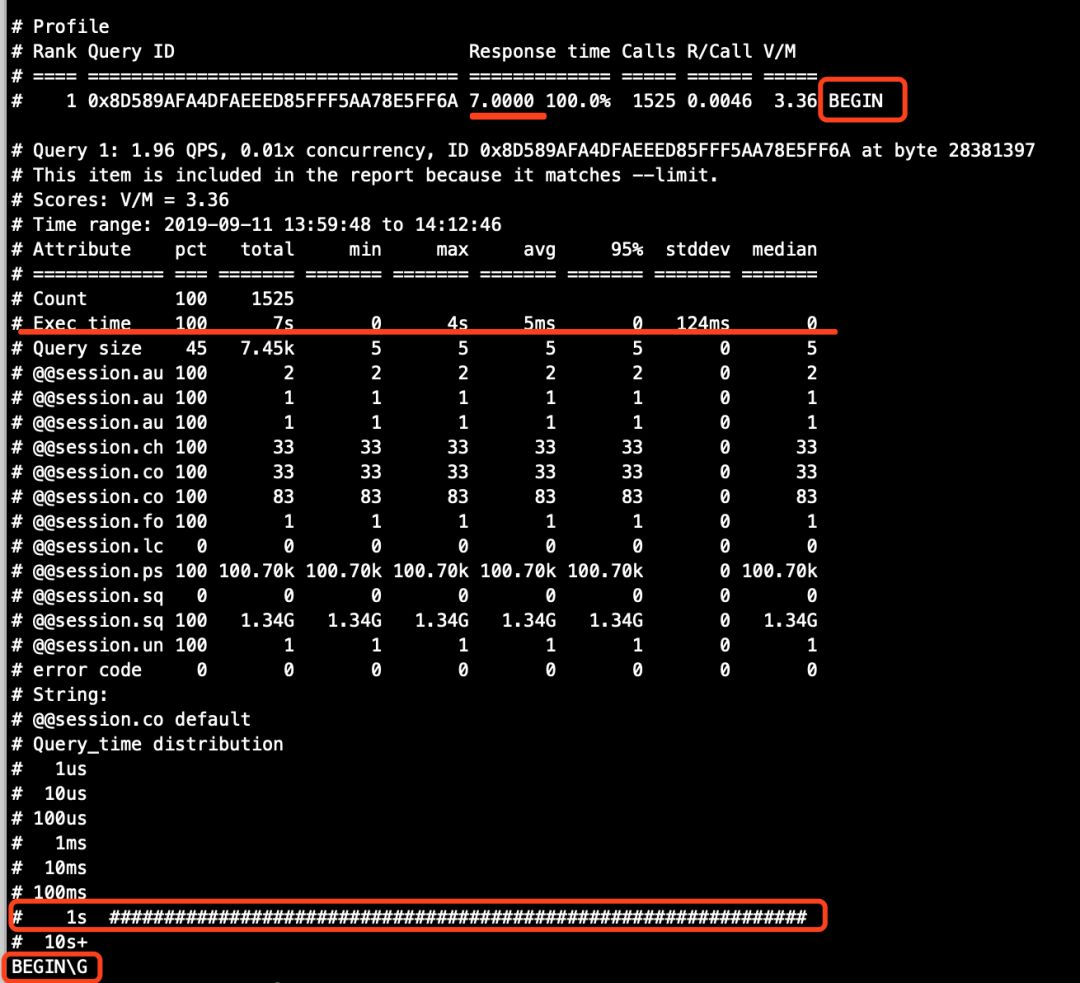
图12(从库)
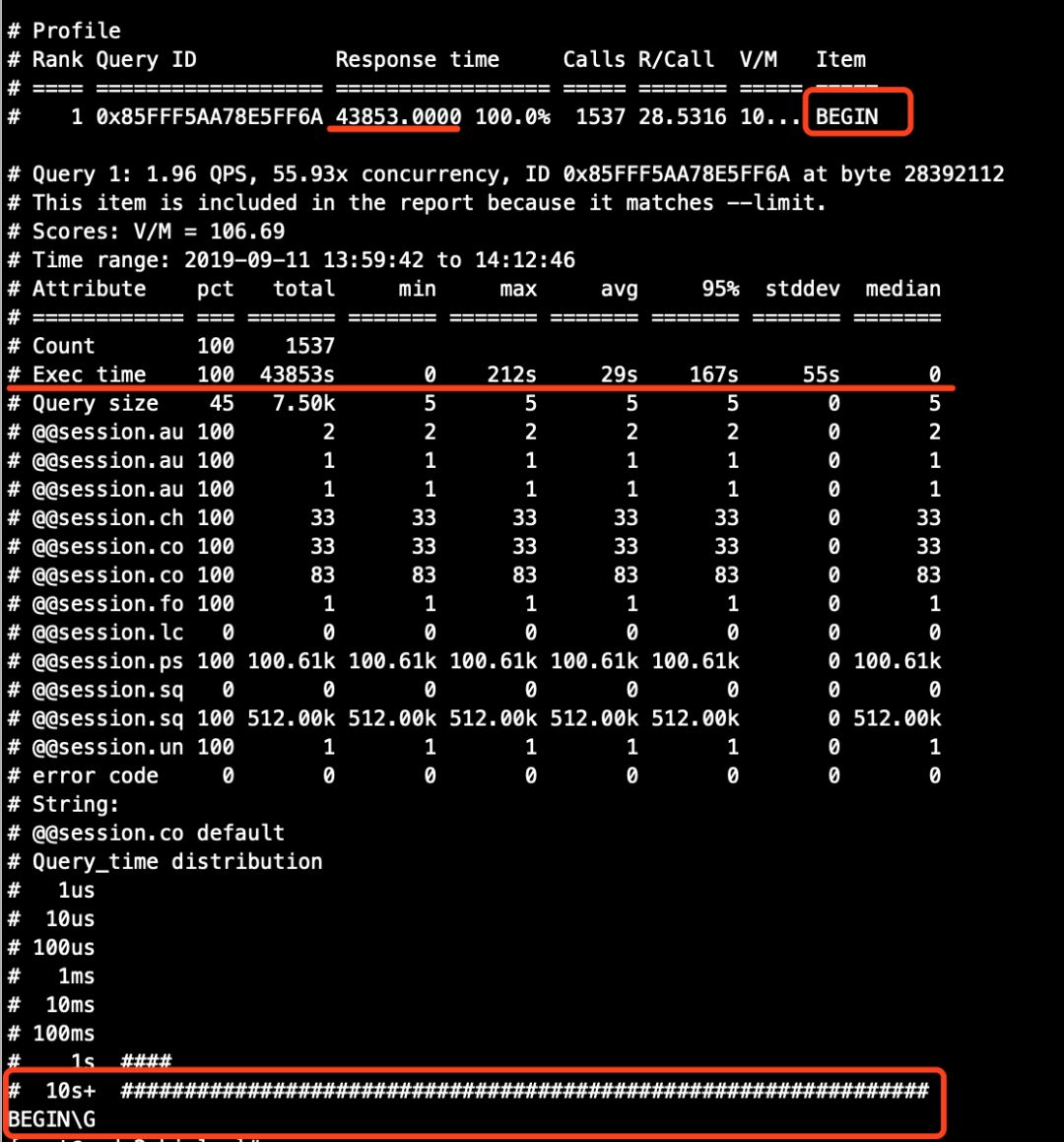
从上面两个图的对比结果来看。
大事务在主库binlog中逃脱了,因为row格式中有效的binlog记录的是数据的逐行变更数据,而非SQL语句文本,同理,在从库中也应该不会记录该大事务的语句。
从库的binlog分析结果中,语句的总执行时间大幅增加。在上文中更早之前我们通过分析binlog已经知道,从库回放会拉长事务的执行时间,但是图12中从库binlog解析记录的SQL总执行时间为43853s,换算成小时,约12个小时,可我们在这里,整个操作过程不到一个小时,很显然,pt-query-digest工具的分析结果中,是将所有BEGIN语句的时间都加在一起了,又因为在测试环境中的从库启用了多线程复制,每个worker线程独立运行,也就是说,假设有N个worker线程同时在回放事务,而每个worker线程同时将执行时间拉长1S,那么,pt-query-digest工具的统计结果中的总延迟时间就变成了N*1S=NS,以此推理可得,大事务在执行过程中,小事务分配binlog event变慢了,又或者被阻塞了,so...
下面,我同样也将exec_time属性不为0的记录过滤出来瞧瞧。
# 主库(发现主库一共有2行exec_time属性不为0的记录)
[root@node1 binlog]# cat b.txt |grep exec_time |grep -v 'exec_time=0'
#190911 14:07:21 server id 33061 end_log_pos 338 CRC32 0xdd75591e Query thread_id=109957 exec_time=4 error_code=0
#190911 14:07:22 server id 33061 end_log_pos 1061 CRC32 0x9482c46d Query thread_id=109974 exec_time=3 error_code=0
# 从库(发现从库一共有423行exec_time属性不为0的记录)
[root@node2 binlog]# cat c.txt |grep exec_time |grep -v 'exec_time=0'
......
#190911 14:07:21 server id 33061 end_log_pos 367 CRC32 0xe616b934 Query thread_id=109957 exec_time=212 error_code=0
#190911 14:07:22 server id 33061 end_log_pos 1079 CRC32 0x03ca1c89 Query thread_id=109974 exec_time=211 error_code=0
#190911 14:07:25 server id 33061 end_log_pos 1791 CRC32 0xc4e998ea Query thread_id=110012 exec_time=208 error_code=0
......
[root@node2 binlog]# cat c.txt |grep exec_time |grep -v 'exec_time=0' |wc -l
423
# 主库(发现了SQL被阻塞的记录,从下面show processlist输出结果中可以看到,两个update语句只修改一行记录,原本是不会被阻塞的,但是,现在,因为大事务,发生了阻塞,从后续的sys.session视图这里可以大致判断,其他小事务由于大事务在提交binlog阶段发生了阻塞,甚至导致出现了2个一模一样的UPDATE SQL,因为前一个SQL被阻塞未执行完,后一个完全一样的SQL进入之后甚至导致出现了锁等待)
[root@node1 binlog]# vim /tmp/exec_parallel_sql_master.sh.log
......
========================================================================================
警告!SQL发生阻塞!!!!!!-----------------------------------------
========================================================================================
show processlist信息如下:---------------------------------
Id User Host db Command Time State Info
4 repl 10.10.30.163:33375 NULL Binlog Dump GTID 81163 Master has sent all binlog to slave;waiting for more updates NULL
5 repl 10.10.30.164:49847 NULL Binlog Dump GTID 81162 Master has sent all binlog to slave; waiting for more updates NULL
88201 root localhost sbtest Query 4 starting commit
107409 root localhost NULL Sleep 164 NULL
109940 admin 10.10.30.16:62563 sbtest Query 4 starting commit
109957 admin 10.10.30.16:62597 sbtest Query 3 updating update sbtest1 set k=k+1 where id>1000000 limit 1
109974 admin 10.10.30.16:62631 sbtest Query 2 updating update sbtest1 set k=k+1 where id>1000000 limit 1
109991 admin 10.10.30.16:62665 NULL Query 0 starting show processlist
sys.session视图信息如下:---------------------------------
*************************** 1. row ***************************
thd_id: 109982
conn_id: 109940
user: admin@10.10.30.16
db: sbtest
command: Query
state: starting
time: 4
current_statement: commit
statement_latency: 3.09 s
......
current_memory: 0 bytes
last_wait: wait/synch/mutex/sql/MYSQL_BIN_LOG::LOCK_log
last_wait_latency: Still Waiting
......
pid: 24345
program_name: mysql
*************************** 2. row ***************************
# 锁等待信息
*************************** 1. row ***************************
*************************** 2. row ***************************
wait_started: 2019-09-11 14:07:22
wait_age: 00:00:02
wait_age_secs: 2
locked_table: `sbtest`.`sbtest1`
locked_index: PRIMARY
locked_type: RECORD
waiting_trx_id: 49083
waiting_trx_started: 2019-09-11 14:07:22
waiting_trx_age: 00:00:02
waiting_trx_rows_locked: 2
waiting_trx_rows_modified: 0
waiting_pid: 109974
waiting_query: update sbtest1 set k=k+1 where id>1000000 limit 1
waiting_lock_id: 49083:41:6881:62
waiting_lock_mode: X
blocking_trx_id: 49082
blocking_pid: 109957
blocking_query: update sbtest1 set k=k+1 where id>1000000 limit 1
blocking_lock_id: 49082:41:6881:62
blocking_lock_mode: X
blocking_trx_started: 2019-09-11 14:07:21
blocking_trx_age: 00:00:03
blocking_trx_rows_locked: 2
blocking_trx_rows_modified: 0
sql_kill_blocking_query: KILL QUERY 109957
sql_kill_blocking_connection: KILL 109957
*************************** 3. row ***************************
......
# 从库(在从库中并未发现SQL阻塞和锁等待记录)
[root@node2 ~]# cat /tmp/exec_parallel_sql_slave.sh.log |grep -E 'sys.session|wait_started'
......
现在,登录到主从数据库中,各自使用sys.io_global_by_file_by_bytes视图查询相关数据文件的总吞吐统计数据。
# 主库(见图13)
mysql > select * from sys.io_global_by_file_by_bytes where count_read!=0 order by count_read desc;
......
# 从库(见图14)
mysql > select * from sys.io_global_by_file_by_bytes where count_read!=0 order by count_read desc;
......
sys.io_global_by_file_by_bytes视图的执行结果截图。
图13(主库)
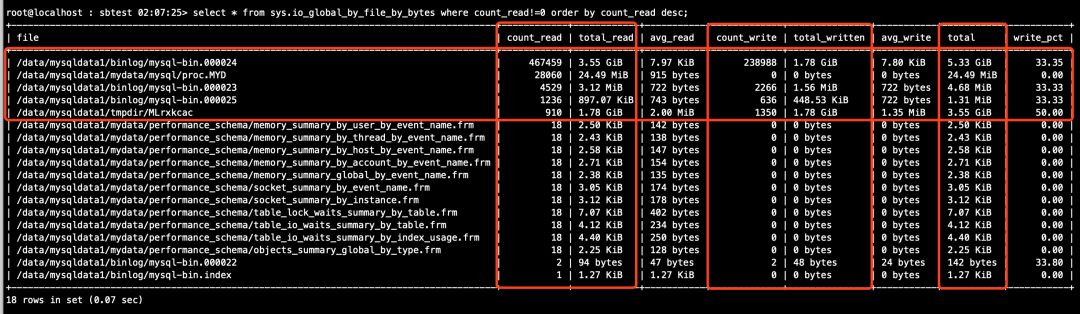
图14(从库)
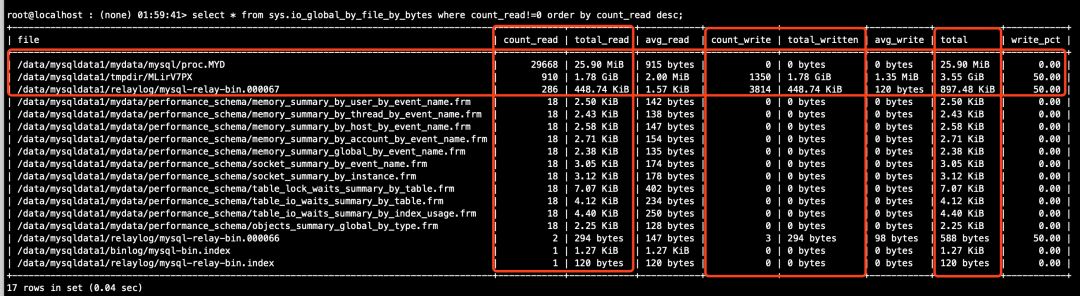
从上述图13和图14中可以看到,吞吐统计数据都毫无悬念地大幅增加了,不过。。主库中出现了一个临时文件/data/mysqldata1/tmpdir/MLrxkcac,读取和写入的总流量都为1.78G,从库中也出现了一个临时文件/data/mysqldata1/tmpdir/MLirV7PX,读取和写入总流量也都为1.78G,额,还真是巧了,这个临时文件是做啥的呢?再仔细一看图13中主库的/data/mysqldata1/binlog/mysql-bin.000024文件的写入总流量也为1.78G,主从库中出现的临时文件会不会跟写binlog有啥关系呢?咋们来推导一下,大事务未提交时,binlog是不能落盘的,那整个事务的binlog日志量往哪里放呢?内存?那万一内存不够用怎么办?那写磁盘吧?往哪儿写呢?临时文件?会不会这里看到的这个临时文件就是用来暂存未提交大事务的binlog的呢?
# 查看binlog目录下的mysql-bin.000024文件
[root@node1 binlog]# ls -lh
total 22G
......
-rw-r----- 1 mysql mysql 1.8G Sep 11 14:07 mysql-bin.000024 # 咦,不对啊,磁盘上这个文件是1.8G,对不上?别慌,我们换个思路,继续往下看
-rw-r----- 1 mysql mysql 449K Sep 11 14:12 mysql-bin.000025
# 会不会是单位算法不一样呢?sys.io_global_by_file_by_bytes视图中的字节流单位是使用sys.format_bytes()函数进行转换的,那我们改用ls -l查看,去掉-h选项查看磁盘文件,把字节数据拿出来,使用数据库中的sys.format_bytes()函数算算看
[root@node1 binlog]# ls -l
total 22186044
......
-rw-r----- 1 mysql mysql 1909214744 Sep 11 14:07 mysql-bin.000024 # 从这里可以看到,字节数据为1909214744
-rw-r----- 1 mysql mysql 459299 Sep 11 14:12 mysql-bin.000025
-rw-r----- 1 mysql mysql 1300 Sep 11 14:07 mysql-bin.index
# 登录数据库算算
mysql > select sys.format_bytes(1909214744);
+------------------------------+
| sys.format_bytes(1909214744) |
+------------------------------+
| 1.78 GiB | # 从这里可以看到,正好1.78G
+------------------------------+
1 row in set (0.00 sec)
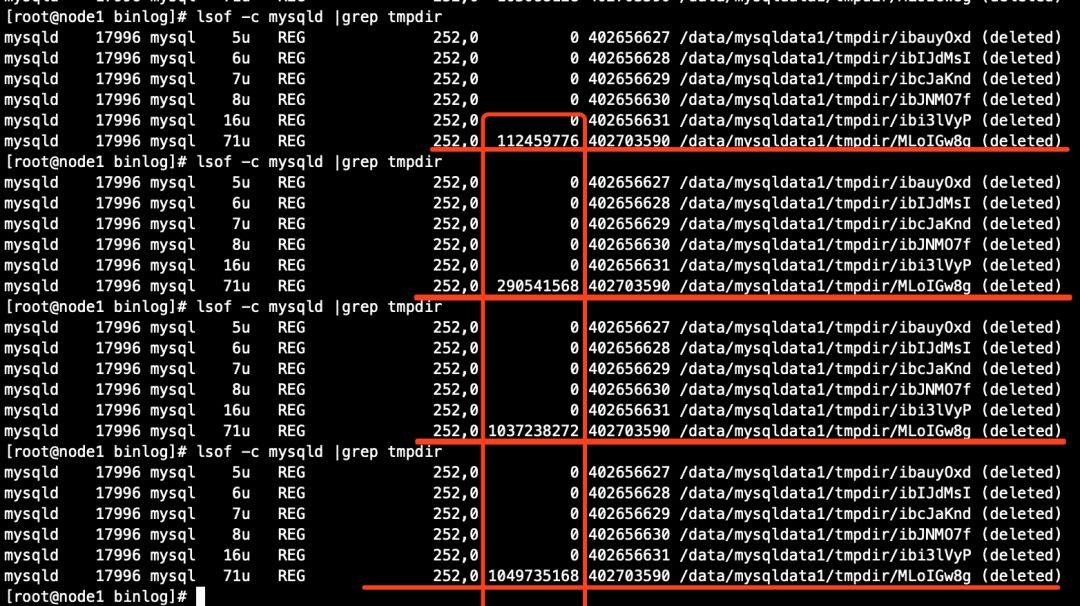
PS:对于ML开头的临时文件,事务未执行提交之前,在ps中无法被捕获到,但可以在操作系统层面使用lsof命令查看,如下(看到某个文件的字节数在不断增加的时候,就表示mysqld进程正在不断地使用临时文件存放一些临时数据,但是,当事务提交时,lsof命令捕获到的临时文件条目的字节数会被清零):
5、优化大事务的影响
# 将优化参数持久化
[root@node1 binlog]# cat /etc/my.cnf
......
[mysqld]
binlog_transaction_dependency_tracking=WRITESET
transaction_write_set_extraction=XXHASH64
......
# 也可以动态修改,但是顺序不能搞错,需要先修改transaction_write_set_extraction参数为XXHASH64,否则会报错
mysql > set global transaction_write_set_extraction=XXHASH64;
Query OK, 0 rows affected (0.00 sec)
mysql > set global binlog_transaction_dependency_tracking=WRITESET;
Query OK, 0 rows affected (0.00 sec)
现在,咋们将上述所有步骤重新跑一下,看看大事务是否会阻塞其他的小事务(过程略)。
对于主库来说,小事务仍然会在大事务提交binlog阶段发生短暂阻塞(如果磁盘吞吐不太好,那这个问题可大可小了)。 对于从库来说,复制延迟仍然存在,但通过pt-query-digest工具解析binlog结果来看,总执行时间减小了一些,但仍然与未优化前处于同一个量级。
现在回过头来继续聊大事务究竟怎么搞呢?当你没有办法去优化某件某个大事务的,最好的办法就是...消灭它,如何消灭大事务呢?回到文章开头那句话:“在开发规范里明令禁止大事务(单个事务操作的数据量不建议超过10000行),尽可能将大事务拆分为小事务,即便特殊情况不得不跑大事务,至少也要在会话级别将binlog格式改成statement。
最后
特别强调一下,对于MySQL InnoDB存储引擎来说,建议设置主键或唯一索引,再不济也要有二级索引,否则,那感觉一定很酸爽,你可以准备两张没有任何索引的表,用上述过程操作一遍试试看
另外,喜欢用级联复制的同学们注意了,除非必须,否则不建议使用级联复制,以现在的服务器硬件配置来说,使用级联复制带来的好处还不如带来的问题多。
6、附录
脚本:
https://pan.baidu.com/s/11t-WbJns42jO8_s7YW5pDQ
日志:
https://pan.baidu.com/s/1SvVhvt59peB1gHuhHqAA0g
关于exec_time属性的详细解释,详情可参考 高鹏(重庆八怪)的《深入理解MySQL主从原理》专栏中的第八讲。
关于大事务binlog未落盘之前,是否会写临时文件的详细解释,详情可参考 高鹏(重庆八怪)的《深入理解MySQL主从原理》专栏中的第十三、第十四讲。最后,附一张高清图(该图为第十四讲文末的高清图),留意左侧绿色方框内的内容。
| 作者简介
罗小波·沃趣科技高级数据库技术专家
IT从业多年,主要负责MySQL 产品的数据库支撑与售后二线支撑。曾参与版本发布系统、轻量级监控系统、运维管理平台、数据库管理平台的设计与编写,熟悉MySQL体系结构,Innodb存储引擎,喜好专研开源技术,多次在公开场合做过线下线上数据库专题分享,发表过多篇数据库相关的研究文章。
相关链接
MySQL行级别并行复制能并行应用多少个binlog group?
Oracle RAC Cache Fusion 系列十四:Oracle RAC CR Server Part One
Oracle RAC Cache Fusion 系列十三:PCM资源访问
Oracle RAC Cache Fusion 系列十二:Oracle RAC Enqueues And Lock Part 3
Oracle RAC Cache Fusion 系列十一:Oracle RAC Enqueues And Lock Part 2
Oracle RAC Cache Fusion 系列十:Oracle RAC Enqueues And Lock Part 1

更多干货,欢迎来撩~
