




检查点 (Checkpoint) 只是一个数据库事件,它存在的根本意义在于减少崩溃恢复(Crash Recovery)时间。检查点事件由CKPT后台进程触发,当检查点发生时,CKPT进程会负责通知DBWR进程将脏数据(Dirty Buffer)写出到数据文件上;CKPT进程的另外一个职责是负责更新数据文件头及控制文件上的检查点信息。
检查点(checkpoint)的工作原理
在Oracle数据库中,当进行数据修改时,需要首先将数据读入内存中(Buffer Cache),修改数据的同时,Oracle会记录重做信息(redo)用于恢复。
因为有了重做信息的存在,Oracle不需要在事务提交时(Commit)立即将变化的数据写回磁盘(立即写的效率会很低),重做的存在也正是为了在数据库崩溃之后,数据可以恢复。
最常见的情况,数据库可能因为断电而Crash,那么内存中修改过的、尚未写入数据文件的数据将会丢失。在下一次数据库启动之后,Oracle可以通过重做日志(redo)进行事务重演(也就是进行前滚),将数据库恢复到崩溃之前的状态,然后数据库可以打开提供使用,之后Oracle可以将未提交的事务进行回滚。
在这个启动过程中,通常大家最关心的是数据库要经历多久才能打开。也就是需要读取多少重做日志才能完成前滚。当然我们希望这个时间越短越好,Oracle也正是通过各种手段在不断优化这个过程,缩短恢复时间。
检查点的存在就是为了缩短这个恢复时间。
当检查点发生时(此时的SCN被称为Checkpoint SCN)Oracle会通知DBWR进程,把修改过的数据,也就是此Checkpoint SCN之前的脏数据(dirty data)从Buffer Cache写入磁盘,当写入完成之后,CKPT进程则会相应更新控制文件和数据文件头,记录检查点信息,标识变更。
因此检查点操作可以分为三个阶段:
第一阶段,CKPT进程初始化检查点,同时捕获检查点RBA,通常就是当前的RBA
第二阶段,DBWR进程写出所有满足条件的Buffer,也即所有RBA<=Checkpoint RBA的Buffer
第三阶段,当所有Buffer写出后,CKPT进程在控制文件中记录完成的检查点。
Checkpoint SCN可以从数据库中查询得到:
SQL> select file#,checkpoint_change#,to_char(checkpoint_time,'yyyy-mm-dd hh24:mi:ss') CPT
2 from v$datafile;
FILE# CHECKPOINT_CHANGE# CPT
---------- ------------------ ------------------------------
1 8904572779065 2006-06-05 16:25:19
2 8904572779065 2006-06-05 16:25:19
3 8904572779065 2006-06-05 16:25:19
……………….
13 rows selected
SQL> select dbid,CHECKPOINT_CHANGE# from v$database;
DBID CHECKPOINT_CHANGE#
---------- ------------------
3965153484 8904572779065
在检查点完成之后,此检查点之前修改过的数据都已经写回磁盘,重做日志文件中的相应重做记录对于崩溃/实例恢复不再需要。
下图中标记了三个日志组,假定在T1时间点,数据库完成并记录了最后一次检查点,在T2时刻数据库Crash。那么在下次数据库启动时,T1时间点之前的Redo不再需要进行恢复,Oracle需要重新应用的就是T1至T2之间数据库生成的重做日志(Redo)。
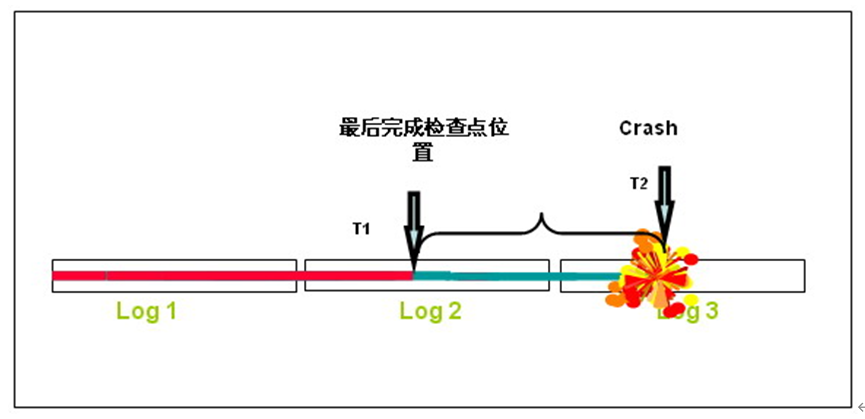
从上图也可以很容易的看出,检查点的频度对于数据库的恢复时间具有极大的影响,如果检查点的频率高,那么恢复时需要应用的重做日志就相对的少,恢复时间就可以缩短。
然而,需要注意的是,数据库的内部操作的相关性极强,过于频繁的检查点同样会带来性能问题,尤其是更新频繁的数据库。所以数据库的优化是一个系统工程,不能草率。
更进一步的可以知道,如果Oracle可以在性能允许的情况下,使得检查点的SCN逐渐逼近Redo的最新变更,那么最终可以获得一个最佳平衡点,使得Oracle可以最大化的减少恢复时间。
为了实现这个目标,Oracle在不同版本中一直在改进检查点的算法。
