集群因子是什么?

简单的说,集群因子是影响执行计划的因素之一,集群因子过高,会导致执行计划不准确,该走索引的时候,不走索引。
下面来测试一下,clustering factor对执行计划的影响。
创建一张测试表test,表结构与dba_objects相同
SQL> create table test as select * from dba_objects where 1=2;
Table created |
往表test里插入数据
SQL> begin 2 for i in 1..10 loop 3 insert *+ append */ into test select * from dba_objects order by i; 4 commit; 5 end loop; 6 end; 7 / PL/SQL procedure successfully completed. |
该表有727530条记录
SQL> select count(*) from test;
COUNT(*) ---------- 727530 |
该表共占用15360个数据块,大小为120M
SQL> set wrap off SQL> col owner for a10; SQL> col segment_name for a15; SQL> select segment_name,blocks,extents,bytes/1024/1024||'M' "size" from user_segments where segment_name='TEST';
SEGMENT_NAME BLOCKS EXTENTS size --------------- -------------- --------------------------- TEST 15360 86 120M |
在object_id列上创建一个索引
SQL> create index idx_objct on test(object_id);
Index created. |
查看索引的信息,占用1664个数据块,大小为13M
SQL> select segment_name,segment_type,blocks,extents,bytes/1024/1024||'M' "size" from user_segments where segment_name='IDX_OBJCT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS EXTENTS size --------------- ------------------ ---------- ---------- ----------------------- IDX_OBJCT INDEX 1664 28 13M |
查看该索引的集群因子为727520,跟表的记录数(727530)差不多
SQL> set wrap on SQL> col index_name for a15 SQL>select index_name,clustering_factor,num_rows from user_indexes where index_name='IDX_OBJCT';
INDEX_NAME CLUSTERING_FACTOR NUM_ROWS --------------- ----------------- ---------- IDX_OBJCT 727520 727520 |
收集表统计信息
SQL> exec dbms_stats.gather_table_stats(user,'test',cascade=>true);
PL/SQL procedure successfully completed. |
再查看索引集群因子,发现没有变化,这里的集群因子和num_rows是相同的,说明表clustering factor是无序的
SQL> col index_name for a15 SQL>select index_name,clustering_factor,num_rows from user_indexes where index_name='IDX_OBJCT';
INDEX_NAMECLUSTERING_FACTOR NUM_ROWS --------------- ----------------- ---------- IDX_OBJCT 727520 727520 |
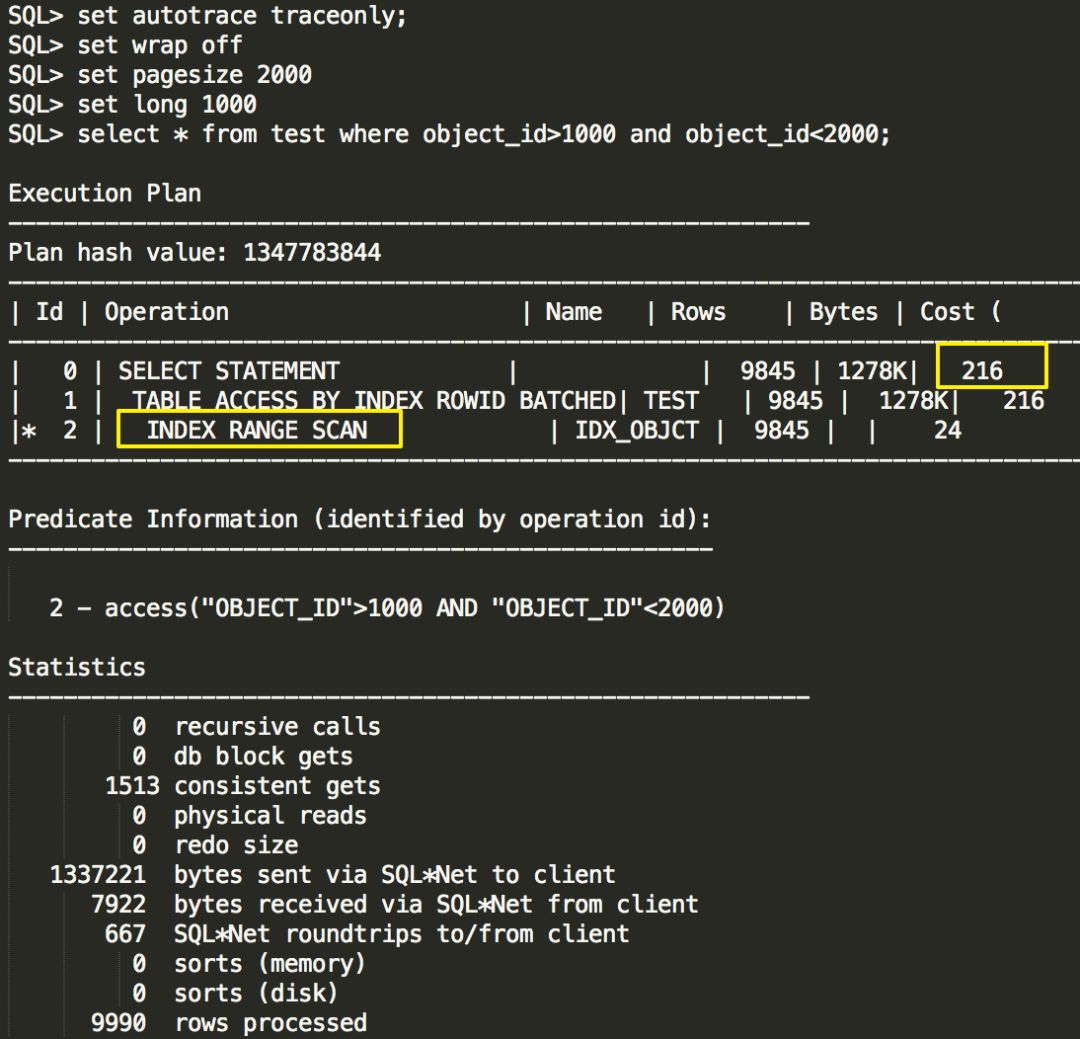
执行一个查询,观察该查询的执行计划,走的索引,代价是13,这是没有问题的
再执行一次查询,从sql语句看,本次查询应该走索引范围扫描,但是从执行计划来看,是走的全表扫描,代价是3897
SQL> alter system flush buffer_cache;
System altered.
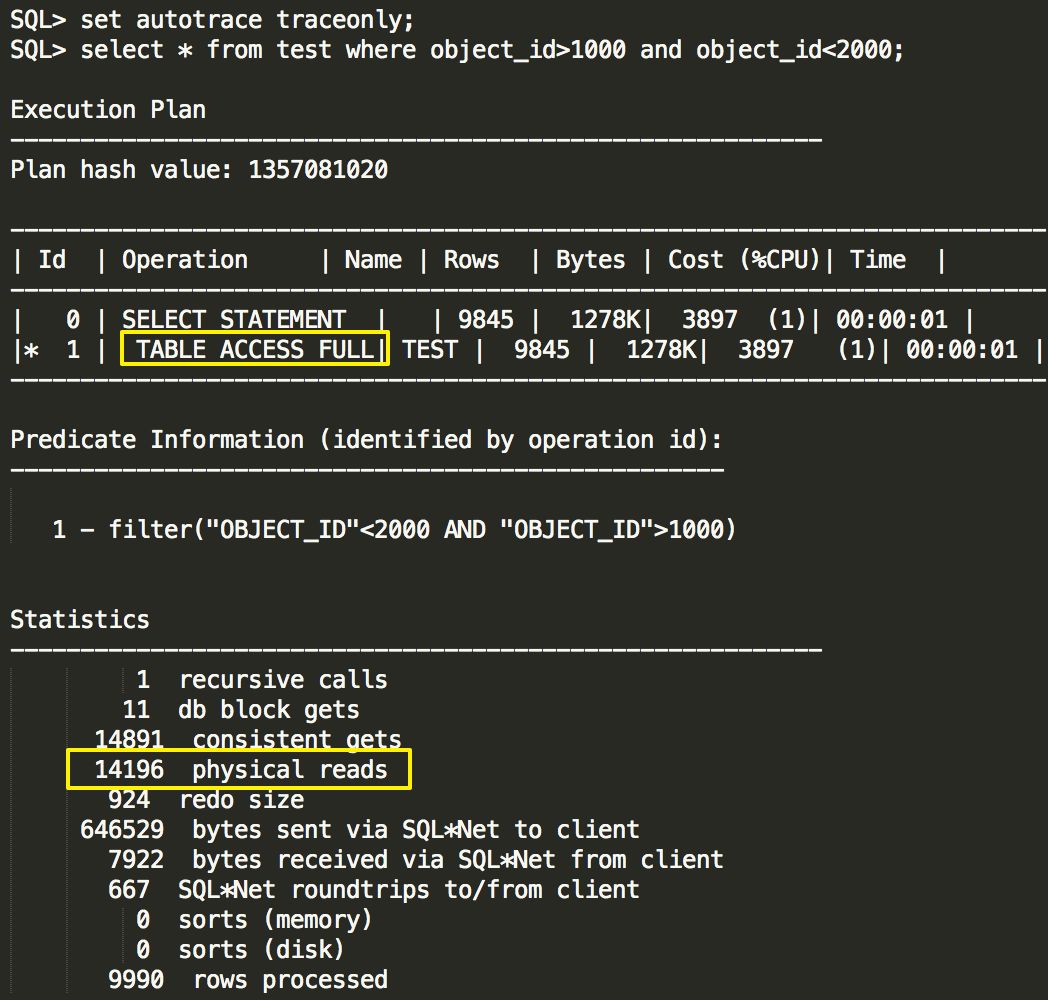
通常,全表扫描的代价要比索引扫描的代价高很多,为什么这里会选择代价更高的全表扫描,而不选择代价低一点的索引呢?
这里有个问题,一般来说,全表扫描的代价是比索引扫描高,但是这里ORACLE选择的是全表扫描,很有可能是统计信息给出来的全表扫描代价比索引扫描代价更低,所以ORACLE就选了全表扫描。
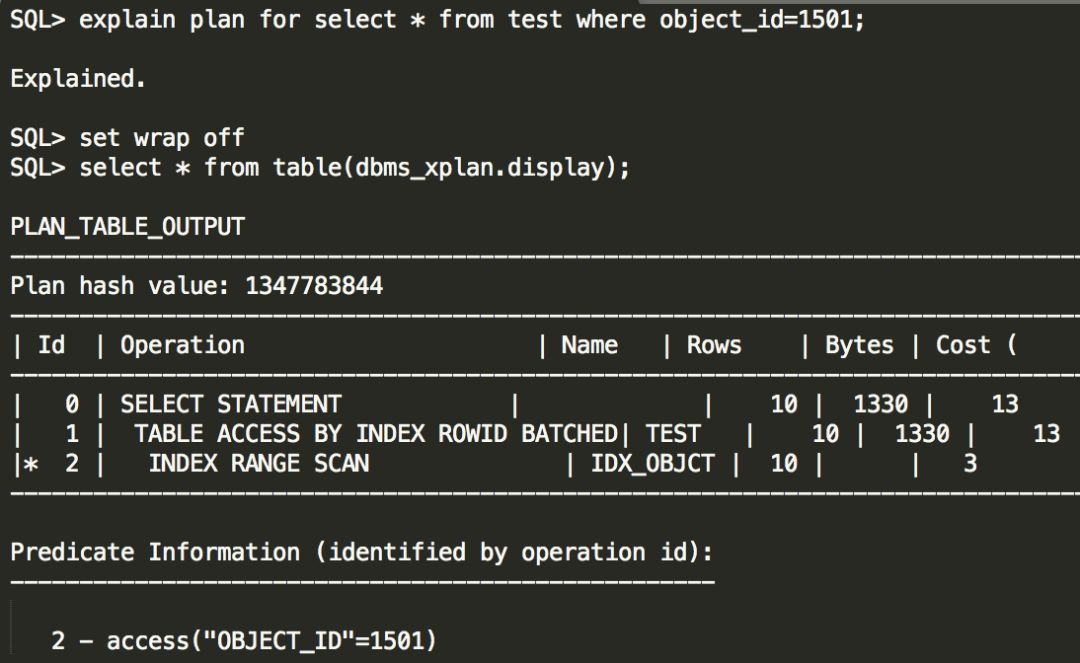
重新执行一次查询,这次强制走索引查询,执行计划显示也确实是索引范围扫描,代价是9872,很明显,9872远大于3897,这就解释了为什么ORACLE当初选择使用全表扫描而不是选择索引扫描
SQL> alter system flush buffer_cache;
System altered.
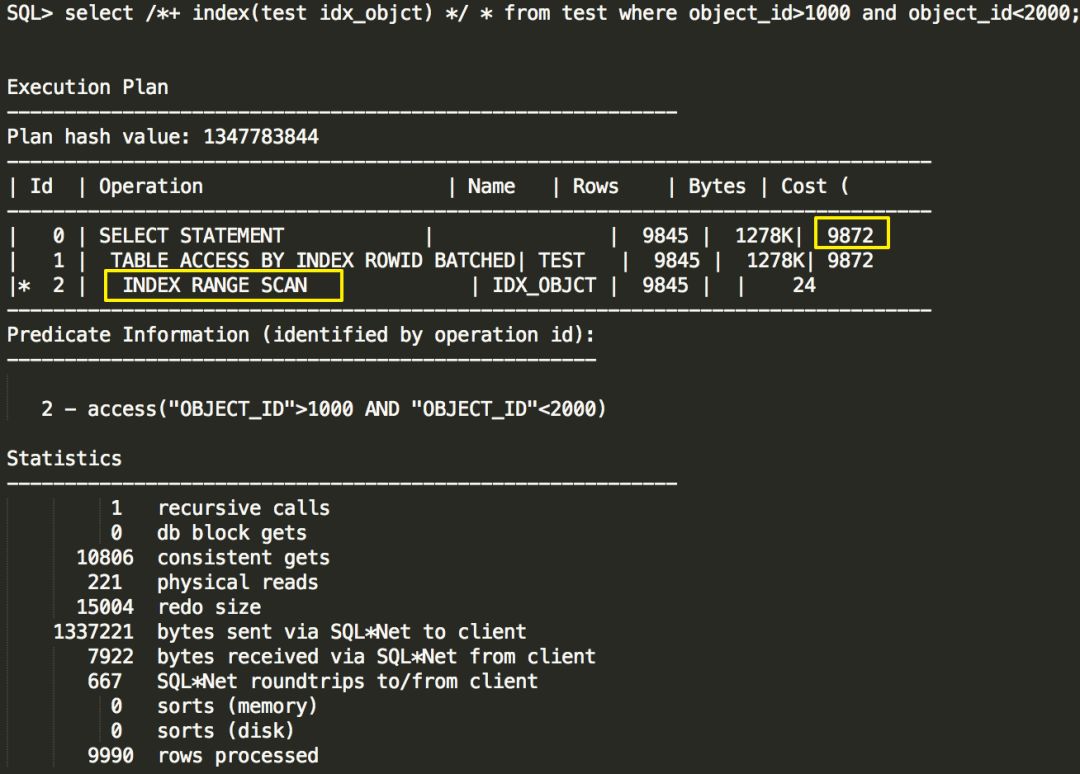
为什么索引扫描的代价会比全表扫描的代价要大?
因为索引代价是受clustering factor影响的,从刚才测试结果中可以看出,clustering factor是很高的,clustring factor=727520,下面是集群因子计算方式

【1】按顺序扫描一个索引
【2】比较两次rowid指向的数据块,如果两次指向的数据块不同,集群因子增加1
【3】扫描完整个索引后,得到的clustering factor值被存储起来
集群因子反应的是数据行在数据块中的离散程度。
要想解决以上的问题,只有降低clustering factor,需要对表的存储位置进行排序
重建test表,命名为new_test
SQL> create table new_test as select * from test where 1=0;
Table created. |
将原来test里的数据插入到新的new_test里
SQL> insert *+ append */ into new_test select * from test order by object_id;
727530 rows created.
SQL> commit;
Commit complete. |
删除原来的test表
SQL> truncate table test;
Table truncated. |
新表new_test占用15360个数据块,大小120M
SQL> select segment_name,blocks,extents,bytes/1024/1024||'M' "size" from user_segments where segment_name='TEST';
SEGMENT_NAME BLOCKS EXTENTS size
--------------------------------------------------------------------------------
TEST 15360 86 120M
索引占用1536个数据块,大小为12M
SQL>select segment_name,segment_type,blocks,extents,bytes/1024/1024||'M' "size" from user_segments where segment_name='IDX_OBJCT';
SEGMENT_NAME SEGMENT_TYPE BLOCKS EXTENTS size
--------------------------------------------------------------------------------
IDX_OBJCT INDEX 1536 27 12M
索引集群因子727520
SQL>select index_name,clustering_factor,num_rows from user_indexes where index_name='IDX_OBJCT';
INDEX_NAME CLUSTERING_FACTOR NUM_ROWS IDX_OBJCT
--------------------------------------------------------------------------------
IDX_OBJCT 727520 727520
重建索引
SQL> alter index IDX_OBJCT rebuild;
Index altered. |
索引重建之后,集群因子变成了14183
SQL>select index_name,clustering_factor,num_rows from user_indexes where index_name='IDX_OBJCT';
INDEX_NAME CLUSTERING_FACTOR NUM_ROWS -------------------------------------------------------------------------------- IDX_OBJCT 14183 727520 |
收集统计信息,查看test表占用了14346个数据块,与集群因子的数量接近,说明相邻rowid是存在一个block里的
SQL> exec dbms_stats.gather_table_stats(user,'test',cascade=>true);
PL/SQL procedure successfully completed. |
SQL> select blocks from dba_tables where table_name='TEST';
BLOCKS ---------- 14346 |
再执行一次查询,从执行计划看,是没有问题的,索引范围扫描,而且代价降低到216
SQL> alter system flush buffer_cache;
System altered. |