




对大数据的生态一直关注着,今年给自己立了一个flag,加入到该阵营来,用数据来说话。本篇属于该系列的入门篇,简单的介绍下hadoop的安装及demo运行。在安装前,因为容器的流行,自己第一感觉是不想在主机安装,(主要是个人来说一般没有这么多的资源)直接通过docker来一键安装,在此推荐一篇博客给大家,http://kiwenlau.com/2016/06/12/160612-hadoop-cluster-docker-update/ 这篇博客详细的介绍了如何在容器跑hadoop集群,有兴趣的可以去了解下原理,其实主要在dockerfile里,看完便一目了然。今天我要给大家介绍的是自己如何在mac上安装伪集群,因为自己之前已经安装了flink,并跑了一些job,想把flink跑完的数据存储在hdfs里,这才有了本篇的内容,接下来记录本次安装的主要步骤及安装过程中出现的一些问题:
1.检查java环境
通过java -version检查是否安装jdk

2.配置ssh
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
3.开启远程登录
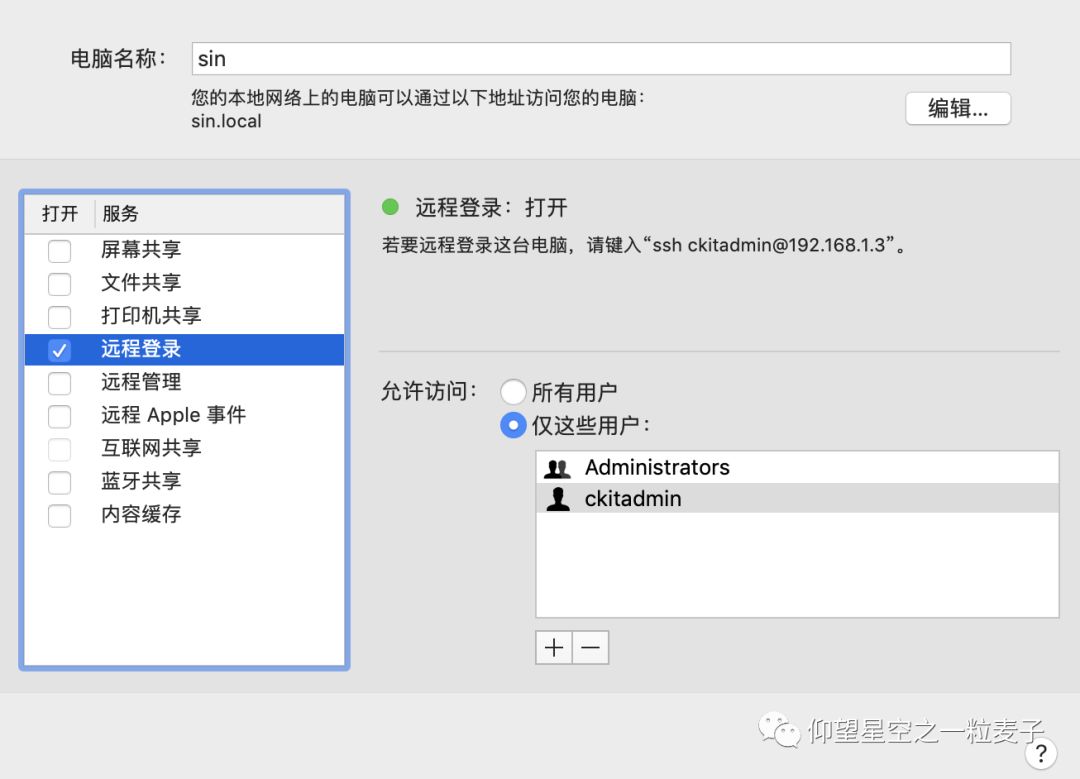
远程登录:
ssh localhost
4.安装hadoop
brew install hadoop
4.1配置
需要修改的文件都在 usr/local/Cellar/hadoop/3.2.1_1/sbin/ 目录下:
将/usr/libexec/java_home查到的 Java 路径,记得去掉注释 #。

hadoop-env.sh
export JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_191.jdk/Contents/Home
core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/Cellar/hadoop/hdfs/tmp</value>
<description>A base for other temporary directories</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
mapred-site.xml
<name>mapreduce.framework.name</name>
<value>yarn</value>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>localhost</value>
</property>
4.2 Hadoop namenode 格式化
hdfs namenode -format
4.3 启动集群
./start-all.sh
4.4 查看进程是否启动

namenode、 secondarynamenode、datanode、resourcemanager、nodemanager 5个进程
4.5 webui查看页面
检查 namenode 和 datanode 是否正常
http://localhost:9870/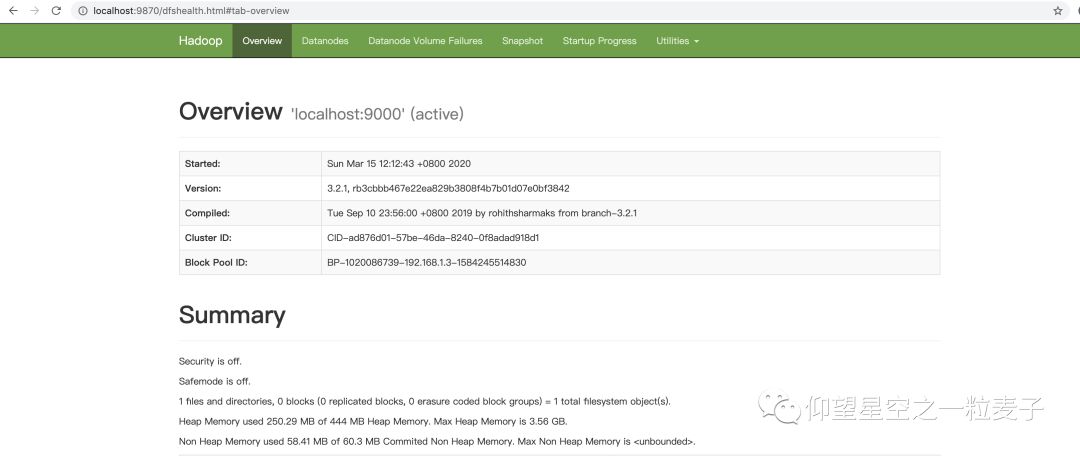
检查 Yarn 是否正常
http://localhost:8088/cluster
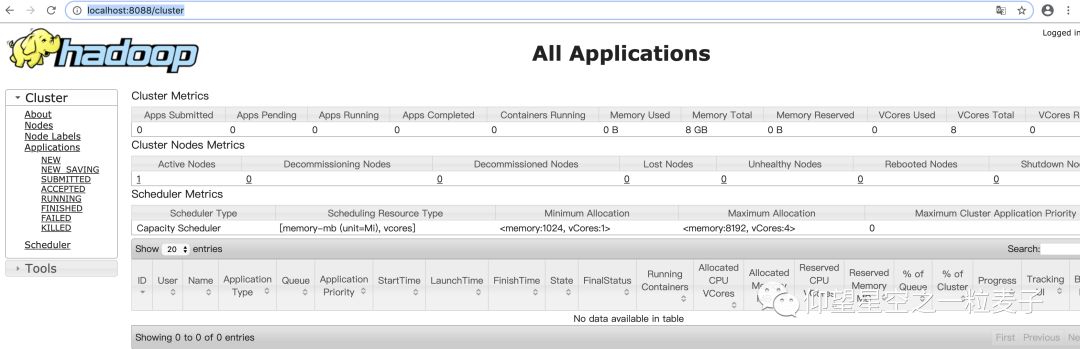
恭喜你~当你看到此时,说明你的环境已经准备就绪。等待下一章节的flink 实时处理后存储到hdfs的精彩内容吧!
