在“基于深度学习的文本分类” 和 “细想神毫注意深” 里面描述了深度学习以来,语言模型有极大的提高,尤其在嵌入,知识融合,基础模块,注意力方面突飞猛进。 随着嵌入的发展,尤其在CoVe开启了上下文嵌入, ELMO开启了无监督上下文嵌入之后, 一下子进入了大爆炸时代!
预训练语言模型 PLMs
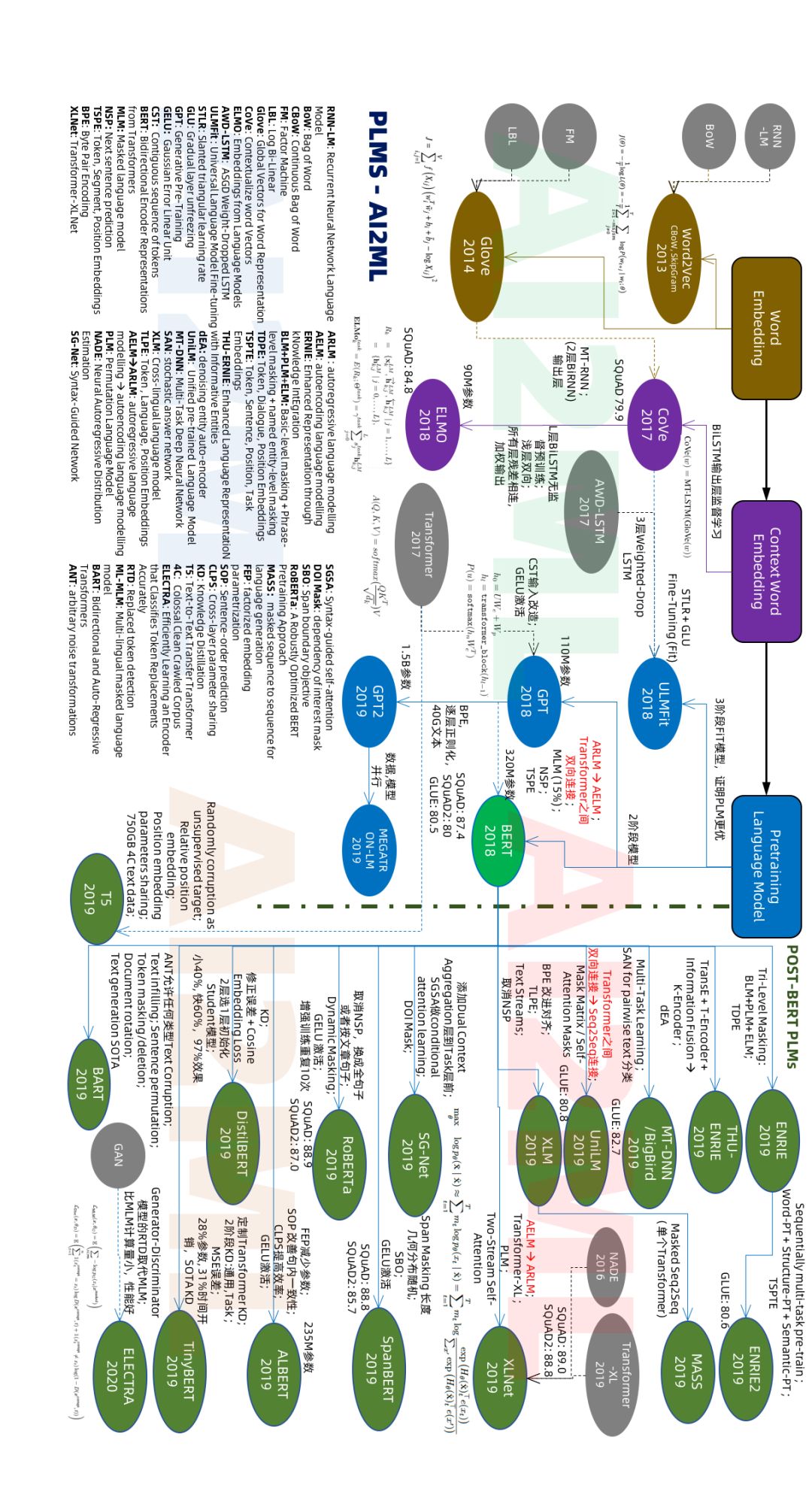
大体上预训练模型在经历中4个时代, 第一个是轰动性的词嵌入(Word Embedding)时代, 这个时代的杰出代表是Word2Vec和Glove;第二个是上下文嵌入(Context Word Embedding),代表为CoVe和ELMO;第三个时代是预训练模型,代表是GPT和BERT; 第四个时代是改进型和领域定制型。 改进型代表为ALBERT和XLNet,而领域定制化代表为SciBert (Scientific Bert) 和BioBert(Biomedical Bert)。 这里领域定制化(Domain Specific)的BERT不是我们强调的重点,先忽略。
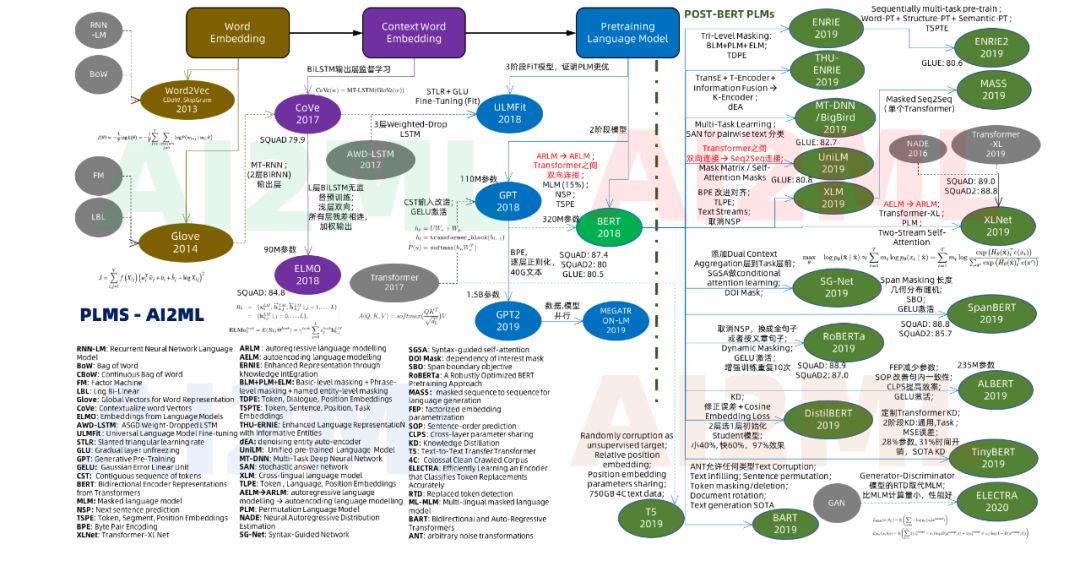
AI2ML-PLMs 2019 (更详细的大图,见文末)
自然语言处理的难点示意
难点来自两个大方面,一个是语言本身的难点。 另外一个是处理的难点。
常见的语言本身的难点如下:
1. 文本中的词义程度(同义词,反义词)难以量化表达
古代形容美女,沉鱼,落雁,闭月,羞花, 到底谁最美?有人说古代排名是西施、王昭君、貂蝉、杨玉环 依次以沉鱼落雁之容,闭月羞花之貌的顺序来排。突然间位置信息暗含了词义程度。 计算机怎么知道。
2. 一词多义要看语境
他喜欢苹果,你喜欢黑莓,我喜欢小米。大概率说的是手机
他喜欢苹果,你喜欢黑莓,我喜欢香蕉。大概率说的是水果
说的到底是水果还是手机,有时候真的很难
3. 句子含义需要背景知识
一树梨花压海棠, 女大三抱金砖, 字面上都无法理解透夫妻关系。 需要很强的背景知识补充。
4. 强调的部分不一样,蕴含的意思有差别
张柏芝又生了个儿子!
王刚又生了儿子!
只是生的多?还是儿子多? 真的很难!
5. 句子省略,需要常识推理
小明的妈妈有三个孩子, 大儿子叫大毛, 二儿子叫二毛。
二毛的弟弟叫什么?
6. 省略指代需要上下文
王思聪最近被限制消费,你说老王会不会救小王。
小王是省略指代王思聪,然后推理老王是谁。
7. 句子含义需要与时俱进
你才是老司机,你们全家都是老司机。
突然间,司机,老师,都变了味道。
8. 句子生成需要符合语法,并且维持风格一致性
人生若只如第一次碰面。
问世间,真情是嘛东西。
风格穿插会让生成句子的质量难以衡量。
9.句子理解还要逻辑分析
乌龟很快追上了兔子, 它跑的太慢了。
乌龟很快追上了兔子, 它跑的太快了。
需要从“追”联系“快/慢”里面进行逻辑分析。
10. 超越文本本身的人性物性分析
爱恨情长,来龙去脉,瞻前顾后, 无微不至 等人的模型就很难建立。
例如:该来的不来 -> 不该走的倒走了 --> 我不是说你们的!
除了语言的难点, 还有处理本身的难点。 如下
1. 如何动态处理长句子,段落的问题
尤其长句子,段落之间的依赖关系,是否被模型忽视了?
兼顾能力和效率。
2. 如何实现无监督半监督模型,自学习。
海量标注依赖极大的人工,而且信息爆炸更新很快。
类似“锦鲤梦”,“盘它” 冒的太快了。
3. 计算效率的提升,训练时间,参数量,可计算性等等。
提出上中下策略供选择,平衡模型复杂性,可用性和准确性。
4. 统一模型处理
一个模型搞定分类,推理,翻译,问答,摘要等等。
5. 模型稳定性
如何兼顾随机性,数据增强, 知识融合的前提下实现稳定性。
6. 模型的平台化
区分核心部件和专用部件,实现可装配,数据模型并行,自适应等。
PLM中的典型技巧
1. AE, AR 结构选择,还是统一?
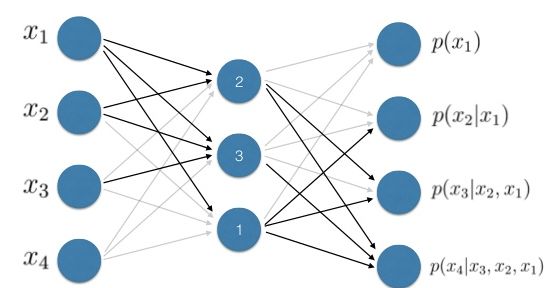
XLNet首次针对的提出AR结构加上PLM,可以达到BERT里面AE的效果,但是在依赖关系上(句子生成能力)上要强于Bert。
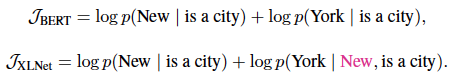
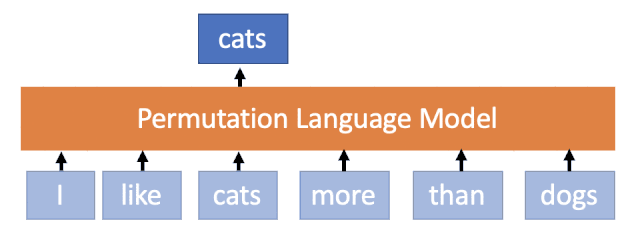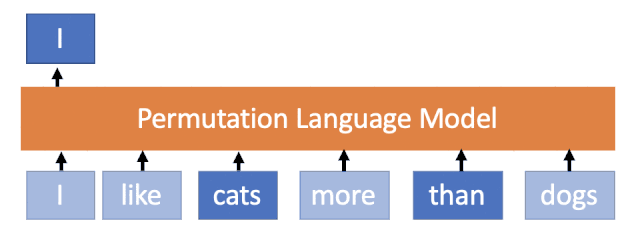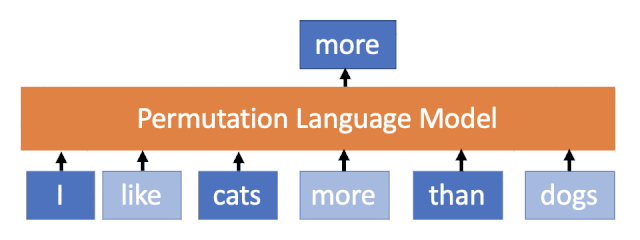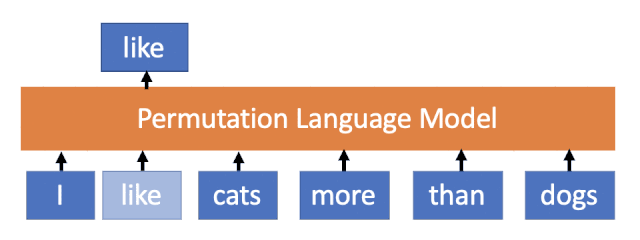
MASS说我们选择好的Mask+Seq2Seq-Attention结构,可以在两种间极端场景下,取中庸之道
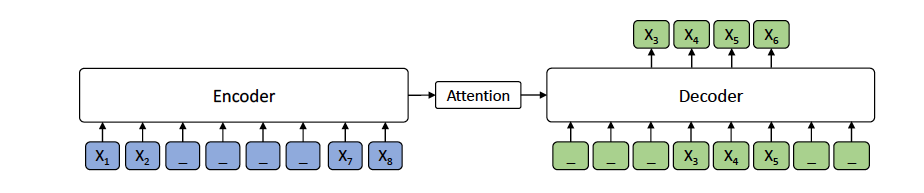
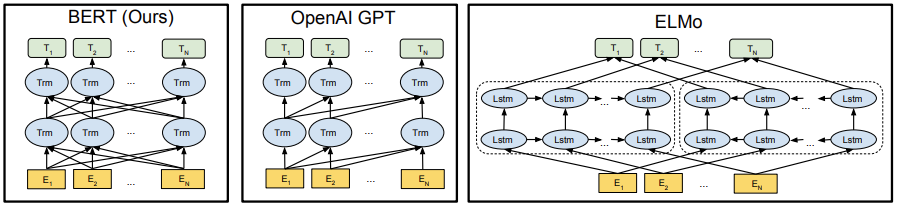
2. 单向,浅层双向,双向,Seq2Seq

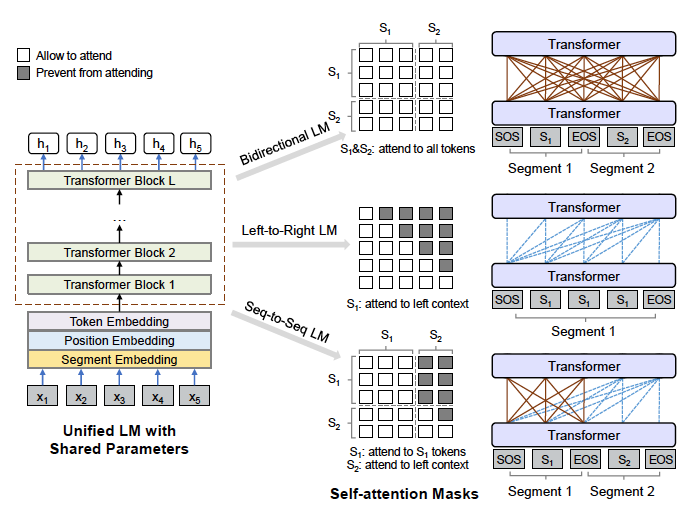
UNILM 干脆搞个Mask矩阵来统一架构框架。
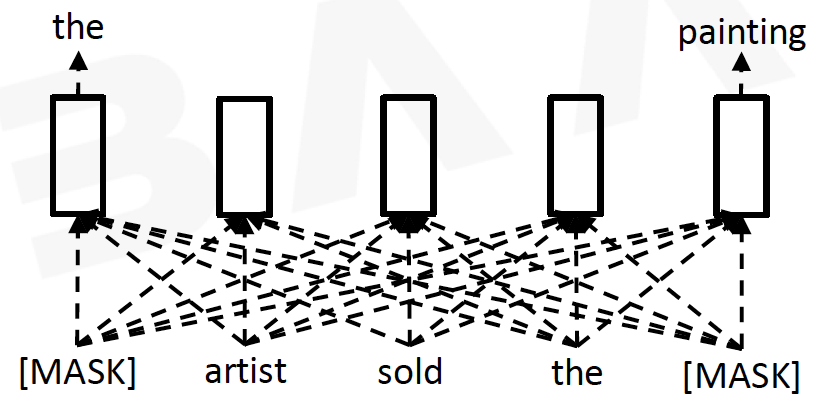
3. 到底哪种MASK机制是最好的?
ENRIE说Dialogue要作为Mask;
ENRIE2说句子和Task也得加入Mask;
XLM说语言也得加入Mask;
SGNet说DOI也要加入Mask

SpanBERT说Mask的随机要满足几何分布
RoBERTa说Mask最好是动态的,可以做数据增强
能加入Mask的东西太多太多了!还能不能有更进一步的升华?
4. MASK到底好不好?
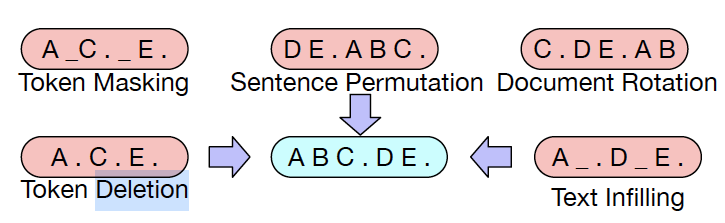
BART说Mask不够,最好再加上DELETION
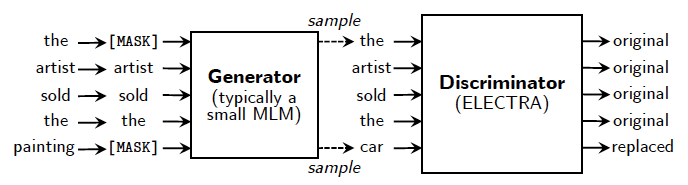
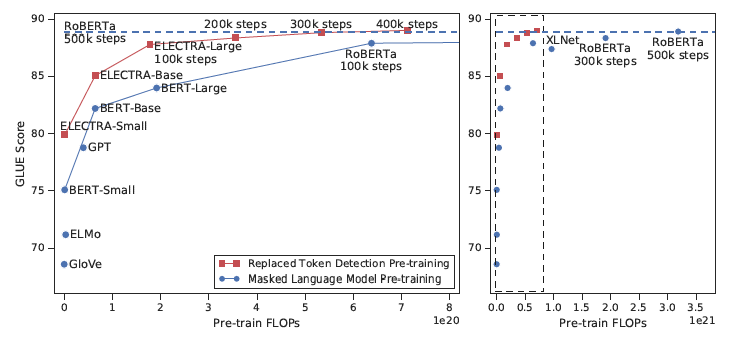
ELECTRA说Mask效率太差, 最好用RTD。
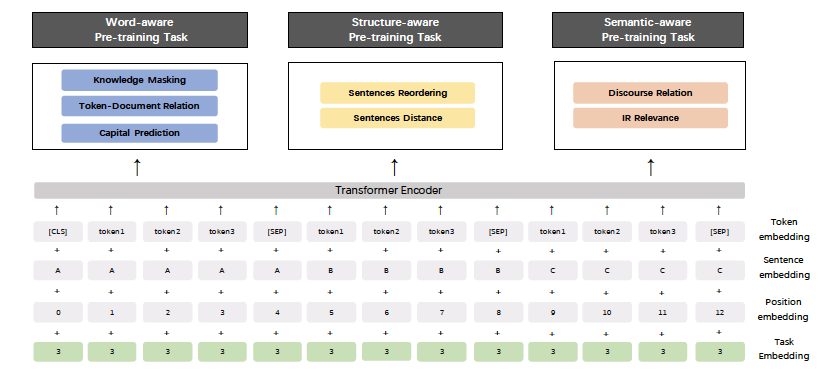
5. Task层如何划分? Task层要统一还是独立加强?
ERNIE2说分成Word,Structure 和Semantic的Task 。
MT-DNN说要分成 SSC, PTS, PTC, PR的。
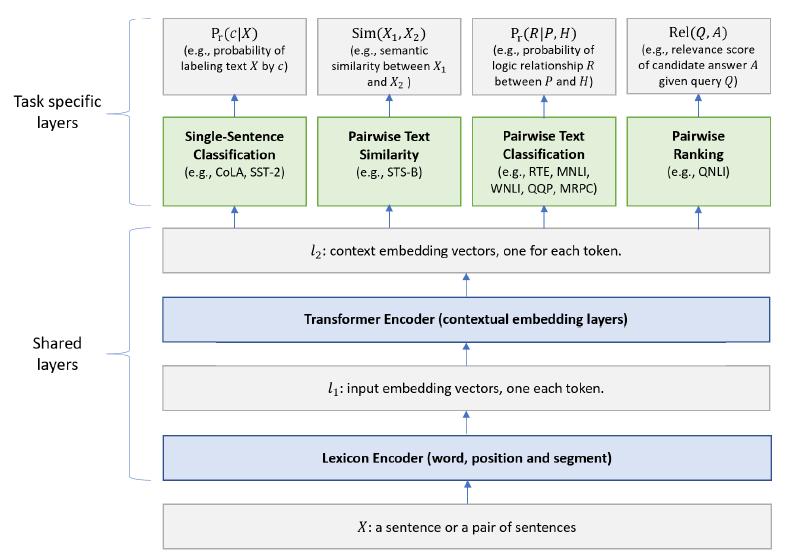
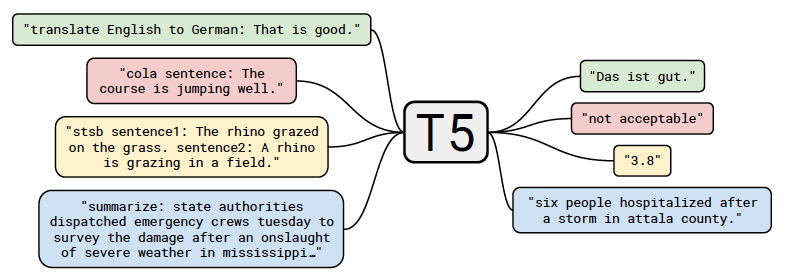
T5说,不要分了,稍微组织结构化点一个架构就够。
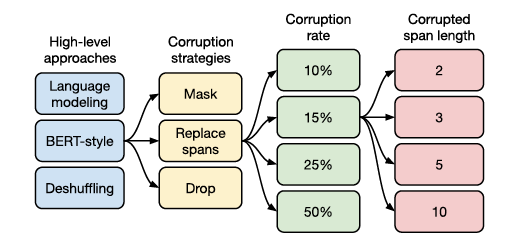
6. 随机性,Corruption,Mask该加多少比例?
BERT说15%, RoBERTa说还得重复10次, MASS说Span Mask得50%的Token覆盖。
7. Knowledge Distill该用什么误差?
DistillBERT说得加Cosine Embedding Loss, TinyBERT说MSE就行。
8. 位置关系和句子顺序关系该怎么用?
BERT说要NSP, XML说只要Text Streams不需要NSP, T5说最好用Relative Poistion。
9. 其他技巧:
Fine-Tuning, Multi-Task, Cross Language, GELU激活函数, Corruption/Deletion/Mask组合,BPE, Permutation, Attention Matrix, Matrix Factorization等等
从上诉技术点来看, PLMs本身对一词多义和上下文释义进行了很好的向量化解决, 然后通过模型融合可以添加知识(Knowledge Graph) 和语法(SG-Net)对于以前列的10个语言问题中部分问题可以深入分析了。 但是对于6个技术方面的问题, PLMs的确取得了前所未有的进展。 更多细节可以看本文最后的大图。
小结:
PLMs还处于混战阶段, 但是当前这个阶段已经将Mask模型, AR/AE架构, KD等方面进行了很多讨论和改进。 但是在知识推理的融合,模型的可视化, 模型的训练效率提升等众多方向还会带来进一步的提升。 仍需深入的基于模型实现端到端的应用:检索, 对话, 推荐,知识图谱还有一波提高。 在和其他技术融合,譬如强化学习和图计算方面还有很多探索。