




在使用clickhouse过程中,相信大家都会遇到各种各样的报错信息,下面是我在接触ck这不到1年时间里遇到的报错总结,会初略解释下发生错误的原因,及如何解决的办法,也希望可以给大家在日常排查问题有一些帮助。
一、连接超时
Cause: ru.yandex.clickhouse.except.ClickHouseException: ClickHouse exception, code: 159, host: xxx.xx.xx.xx, port: 8023; Read timed out
1.1、分析问题
http
协议是clickhouse
在生产环境中最常用的交互方式,包括官方提供的jdbc driver
、datagrip
等,后台都是使用的http
协议,当前滴滴内部我们对外开放的ck端口是8023,上面错误是http
协议在监听socket
返回结果的等待时间,jdbc driver
、datagrip
默认是30s,该参数不是Clickhouse
系统内的参数,它属于jdbc
在HTTP
协议上的参数,但它是会影响到max_execution_time
参数设置效果,因为它决定了客户端在等待结果返回上的时间限制。所以一般用户在调整max_execution_time
参数的时候也需要配套调整socket_timeout
参数,略微高于max_execution_time
即可。
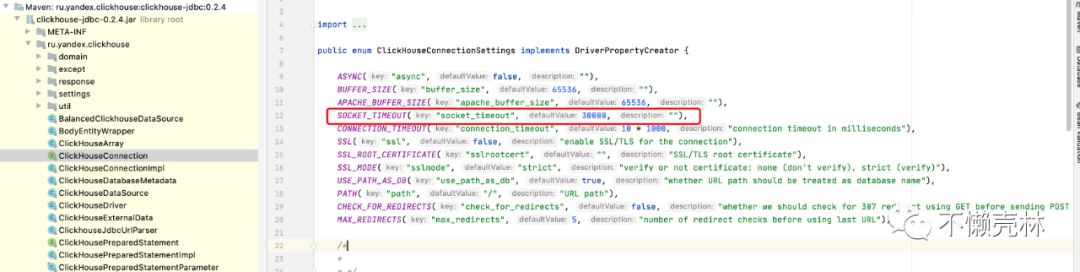
1.2、 解决问题
用户设置参数时需要在jdbc
链接串上添加socket_timeout
这个property
,单位是毫秒,例如:
// java示例
public void clickhouseJdbcTest() throws SQLException {
ClickHouseProperties properties = new ClickHouseProperties();
properties.setUser("hive_user_name"); // 数梦账号名
properties.setPassword("********"); // 数梦账号密码
properties.setDatabase("hive_user_password"); // 指定数据库
//properties.setDatabase("cluster01*hive_user_password"); 指定集群为cluster01
String jdbcUrl = "jdbc:clickhouse://xxx.xxx.xxx.xx:8024/db_name?socket_timeout=3600000";//chproxy地址
ClickHouseDataSource dataSource = new ClickHouseDataSource(jdbcUrl, properties);
ClickHouseConnectionImpl connection = (ClickHouseConnectionImpl) dataSource.getConnection();
ResultSet resultSet = connection.createStatement().executeQuery("select * from db_name.tb_name");
while (resultSet.next()) {
// resultSet.getString(1)
}
}
二、内存使用限制
Code: 241, Message: Memory limit (total) exceeded: would use 204.89 GiB (attempt to allocate chunk of 4349108 bytes), maximum: 204.89 GiB: (avg_value_size_hint = 23.250244140625, avg_chars_size = 18.30029296875
2.1、分析问题
默认情况下,ClickHouse会限制了SQL的查询内存使用的上限,当内存使用量大于该值的时候,查询被强制KILL。
2.2、解决问题
如果是
group by
内存不够,推荐配置上max_bytes_before_external_group_by
参数,当使用内存到达该阈值,进行磁盘group by
。推荐配置为max_memory_usage
的一半。如果是
order by
内存不够,推荐配置上max_bytes_before_external_sort
参数,当使用内存到达该阈值,进行磁盘order by
。如果是
count distinct
内存不够,推荐使用一些预估函数(如果业务场景允许),这样不仅可以减少内存的使用同时还会提示查询速度。
三、元数据不一致
Code: 107, e.displayText() = DB::ErrnoException: Cannot open file data1/default/clickhouse-data/metadata/database/table.sql, errno: 2, strerror: No such file or directory
3.1、分析问题
我们先解释一下ck的几个主语都是什么
clickhouse集群(cluster)
在物理构成上,clickhouse集群是由多个物理主机实例组成的分布式数据库,可能包含1个或者多个副本(replicas),1个或者多个分片(shard),在逻辑构成上,一个clickhouse集群可以包含多个数据库对象。高可用集群
当前除了把脉集群是单副本集群之外,其余集群都为多分片多副本,大家在使用的国内公共集群为4shard2replicas结构组成,高可用的定义是当某个副本服务不可用时,同一个shard的其余replicas可以继续服务,不会丢失数据,因为集群为高可用集群。单副本集群
把脉集群基于业务选择(日志),为多分片单副本集群,这个组成可能产生的风险就是某个副本服务不可用时,会导致整个集群不可用,需要等待该副本完全恢复服务状态,集群才能恢复分片(shard)
在超大规模海量数据处理场景下,单台服务器的存储和计算都会成为瓶颈,为了进一步提高效率,clickhouse将海量数据分散存储到多台服务器上,每台服务器只存储和计算海量数据的一部分,在这种架构下,每台服务器都被称为一个分片(shard)。副本(replica)
为了在异常情况下保证数据的安全性和服务的高可用性,clickhouse提供了副本机制,将单台服务器的数据冗余存储在多台服务器上数据库(database)
数据库是ClickHouse集群中的最高级别对象,内部包含表(Table)、列(Column)、视图(View)、函数、数据类型等。表(table)
表是数据的组织形式,由多行、多列构成。ClickHouse表从数据分布上,可以分为本地表、分布式表两种类型。从存储引擎上,可以分为单机表、复制表两种类型。本地表(Local Table)
大家看到的_local结尾的表均为本地表,本地表只会存储在当前写入的节点上,不会分散到多台机器上分布式表(Distributed Table)
分布式表是本地表的集合,它将多个本地表抽象为一张统一的表,对外提供写入、查询功能。当写入分布式表时,数据会被自动分发到集合中的各个本地表中;当查询分布式表时,集合中的各个本地表都会被分别查询,并且把最终结果汇总后返回。单机表(Non-Replicated Table)
单机表的数据(只有把脉集群),只会存储在当前机器上,不会被复制到其他机器,即只有一个副本。复制表(Replicated Table)
复制表的数据,会被自动复制到多台机器上,形成多个副本。基于以上基本概念,我们可以发现问题其实是集群下某个分片操作失败,而其他分片操作成功,由此产生的元数据
metadata
不一致,目前我们的所有ddl操作都是基于集群去遍历相关节点处理的,例如我们在server01
上执行一个creat table
操作,server01
节点负责创建日志,并将日志推送到zookeeper
,同时也由server01
节点负责监听监控任务的执行进度,如下图,我们根据线程DDLWorker
找出query id
,根据query id
从zookeeper
找对日志内容。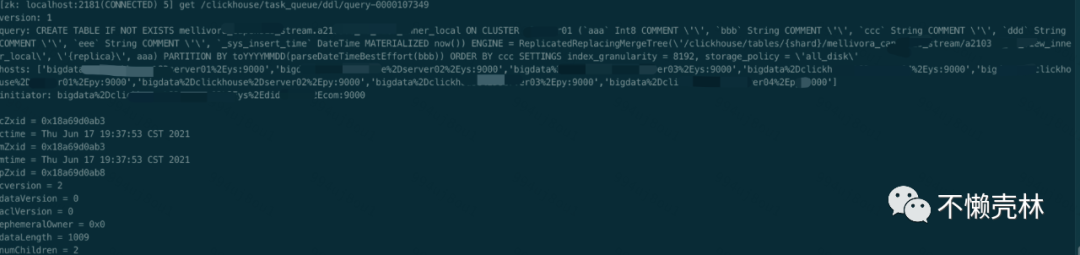
这个日志中的信息:版本号、执行的语句、需要执行该语句的hosts列表。其它节点监听到此操作日志后,后判断自己是否在该hosts列表内,如果包含,则进入执行流程,执行完毕后写入/clickhouse/task_queue/ddl/query-0000107349/finished
从上面截图看出已经完成的节点列表,这过程中可能会发生的是某些分片成功,而某些分片失败的问题,为什么会有这些差异呢,比如说我们有一张表叫tb
,字段叫a
,原先的类型是Nullable(String)
,现在要改为String
去ALTER TABLE tb MODIFY COLUMN a String COMMENT 'test'
,这时候分片a刚好说空本地表,则可以转换成功,而分片b是非空的本地表,由于字段值含有null,转换失败,此时就发生了元数据不一致的问题。
3.2、解决问题
目前我们禁止了`alter table modify tb`操作,另外在所有的`DDL`操作中,为了保持原子性,在外部起了一个程序定时去校验所有集群的所有表,标记出表结构不一致的问题,根据`ddl log`自动去还原`meta data`
四、并发超过阈值
4.1、错误1:
code: 202, host: xxxxx, port: 8123; Code: 202, e.displayText() = DB::Exception: Too many simultaneous queries. Maximum: 100
4.1.1、分析问题
ck抛出异常,当前同时接收到太多查询,或者大量的数据写入库,导致树合并频率过高,查询速度下降,出现了很多慢查询
4.1.2、解决问题
#100个最大同时查询数
<max_concurrent_queries>100</max_concurrent_queries>
4.2、错误2:
code: 252, host: xxxx, port: 8123; Code: 252, e.displayText() = DB::Exception: Too many parts (308). Merges are processing significantly slower than inserts.
4.2.1、分析问题
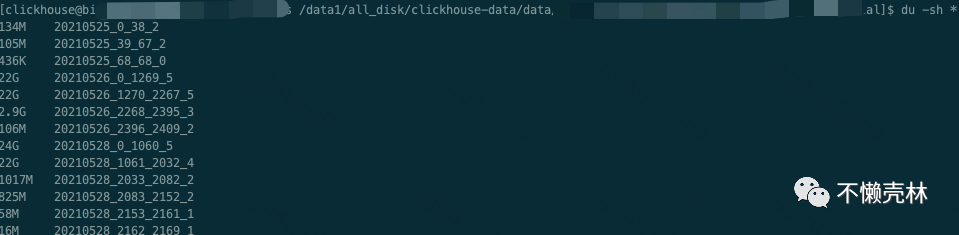
相信很多同学在刚开始使用 clickhouse 的时候都有遇到过该异常,出现异常的原因是因为 MergeTree 的 merge 的速度跟不上目录生成的速度, 数据目录越来越多就会抛出这个异常, 所以一般情况下遇到这个异常,降低一下插入频次就 ok 了,目前我们对流表分区都会强制`toYYYYMMDD`,意思就是1天生成1个分区,另外配置了流数据写入批次,间隔30000ms或者到达2000000条提交一次batch,每次写入ck就会生成一个part,之后再写入的数据会跟当前这个part去做合并,直至我们配置的阈值被触发

这边我顺便解释下分区,每个分区是由若干个part
组成的,每个part
对应一个目录,一般命名格式为{partition}{min_block_number}{max_block_number}{level}
,如果经过mutate(alter)
操作,则还会有{data_version}
的后缀。在part
命名格式{partition}{min_block_number}{max_block_number}{level}_{data_version}
中:partition
是分区值。min_block_number
和max_block_number
表示这个part
包含的最小、最大的block number
。每次数据写入都会至少生成一个block
,每个block
会有自己的block_number
。level
表示这个part
经过了几次merge
,每merge
一次会更新生成一个level
+1后的part
目录。data_version
表示mutate
操作的data_version
,每一次mutate
都会生成一个新的data_version
的part
目录,这个值的含义其实和block_number
类似,同时也和block_number
共用自增id
空间,通过这个值可以判断每个part
是否包含在本次mutate
操作的影响范围内,block_number
、level
以及mutation
在不同的partition
中是相互独立的。
4.2.2、解决问题
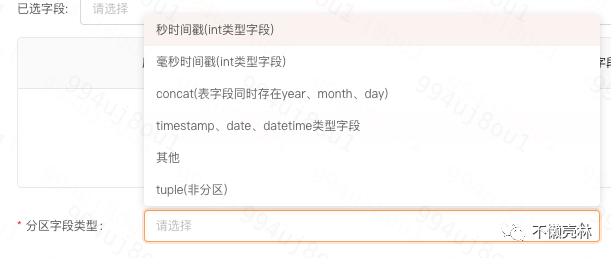
设置合理的分区,分区字段的设置要慎重考虑,如果每次插入涉及的分区太多,那么不仅容易出现上面的异常,同时在插入的时候也比较耗时,原因是每个数据目录都需要和 zookeeper
进行交互,所以当前我们底层引擎在数梦上给用户如下的配置,最终我们都是会格式化为日期类型年月日
五、总结
以上经历均为本人在使用clickhouse
这1年多里时常会遇到,或者在用户群里看到同学在咨询的问题,笔者借着这次机会做一次总结,由于使用clickhouse
经验不足,本人也才疏学浅,一些解释可能有借鉴和解释不清晰的地方,欢迎大家一起交流一起讨论,有兴趣的同学请加入我们的用户群吧。
