




在Apache Kafka的心脏,是基于日志一个简单的数据结构,使用顺序操作与底层硬件的工作共生。以日志为中心的设计带来了高效的磁盘缓冲和CPU缓存使用,预取,零拷贝数据传输以及许多其他好处,从而创造了众所周知的高效率和吞吐量。对于Kafka的新手来说,该主题及其作为事务日志的底层实现通常是他们了解的第一件事。
但是,日志本身的代码在整个系统中只占很小的一部分。Kafka的代码库中有很大一部分负责跨集群中的多个代理安排分区(即日志),分配领导权,处理故障等。这是使Kafka成为可靠且受信任的分布式系统的代码。
从历史上看,Apache ZooKeeper是此分布式代码如何工作的关键部分。ZooKeeper提供了权威的元数据存储,该元数据存储着系统最重要的状态:分区位于何处,哪个副本是领导者,等等。ZooKeeper的使用在早期就很有意义-它是一种功能强大且经过验证的工具。但是归根结底,ZooKeeper是一个在一致性日志之上的有点特质的文件系统/触发API。Kafka是一致日志之上的pub sub API。这导致操作系统的人员在两个日志实现,两个网络层和两个安全实现(分别具有不同的工具和监视挂钩)之间进行调优,配置,监视,安全以及有关通信和性能的原因。它变得不必要地复杂。
当然,替换ZooKeeper是一项艰巨的工作,去年4月,我们启动了一项社区计划,以加快进度并在年底之前交付一个工作系统。
我只是与Jason,Colin和KIP-500团队坐在一起,经历了完整的Kafka服务器生命周期,生产,使用和完全没有Zookeeper。真是太甜了!
-Ben Stopford(@benstopford)2020年12月15日
因此,我们非常高兴地说,KIP-500代码的早期版本已提交进入主干,并且有望在即将发布的2.8版本中包括。第一次,您可以在没有ZooKeeper的情况下运行Kafka。我们将其称为Kafka Raft元数据模式,通常简称为KRaft(发音为craft
)模式。
要小心的是,有些功能在此抢先体验版本中不可用。我们尚不支持使用ACL和其他安全功能或交易。另外,在KRaft模式下不支持分区重新分配和JBOD(预计在今年晚些时候的Apache Kafka发行版中将提供这些功能)。因此,请考虑使用Quorum Controller实验软件-我们不建议将其用于生产工作负荷。但是,如果您尝试使用该软件,则会发现许多新的优势:部署和操作更简单,您可以在单个过程中完整地运行Kafka,并且每个集群可以容纳更多的分区(请参见下方的尺寸)。
仲裁控制器:事件驱动的共识
如果您选择使用新的仲裁控制器运行Kafka,则先前由Kafka控制器和ZooKeeper承担的所有元数据职责将合并到这一新服务中,并在Kafka群集本身内部运行。如果您有用例,仲裁控制器也可以在专用硬件上运行。
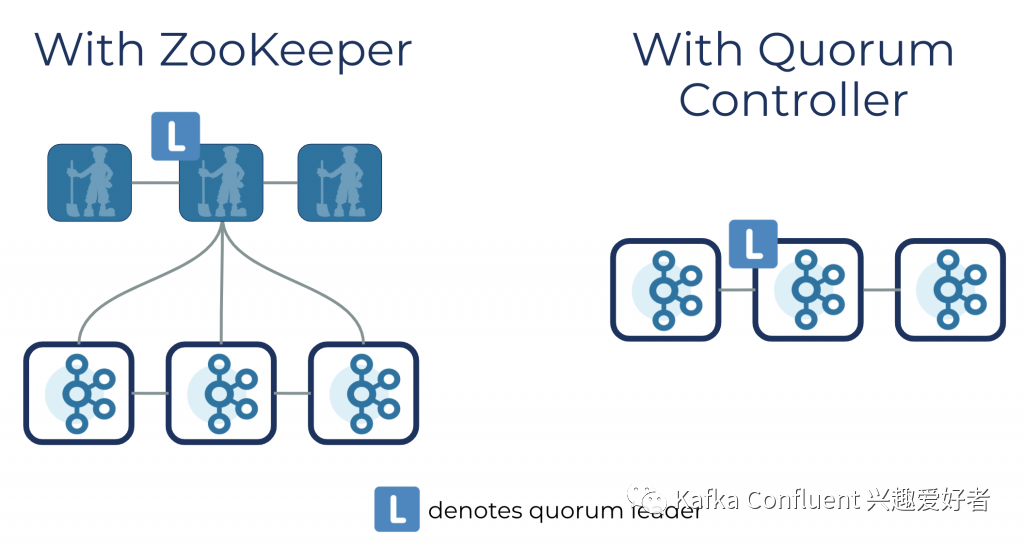
但在内部,它变得很有趣。仲裁控制器使用新的KRaft协议来确保元数据在仲裁中准确复制。该协议在很多方面都与ZooKeeper的ZAB协议和Raft相似,但是有一些重要的区别,值得注意的是,它使用事件驱动的体系结构。
仲裁控制器使用事件源存储模型存储其状态,该模型确保始终可以准确地重新创建内部状态机。快照会定期删除用于存储此状态的事件日志(也称为元数据主题),以确保日志不会无限期增长。仲裁中的其他控制器通过响应活动控制器创建并存储在其日志中的事件来跟随活动控制器。因此,例如,如果一个节点由于分区事件而暂停,则它可以通过在重新加入日志时访问日志来迅速赶上它错过的任何事件。这显着减少了不可用性窗口,从而缩短了系统的最坏情况恢复时间。
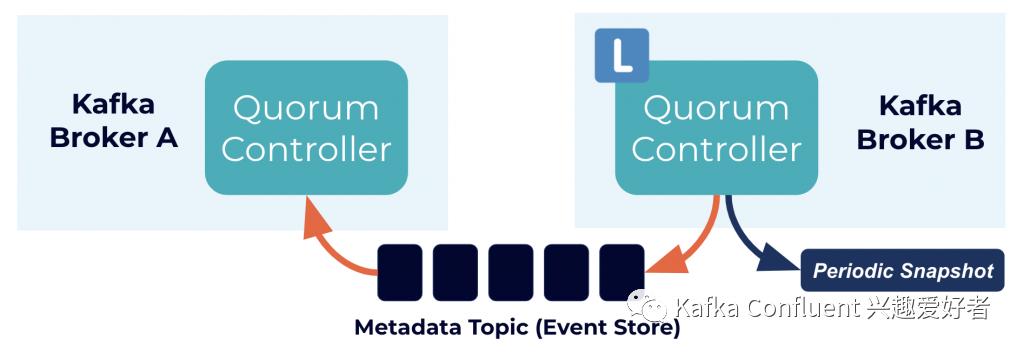
KRaft协议的事件驱动性质意味着,与基于ZooKeeper的控制器不同,仲裁控制器不需要在ZooKeeper处于活动状态之前从其加载状态。领导层变更时,新的活动控制器已经在内存中保存了所有已提交的元数据记录。此外,在KRaft协议中使用了相同的事件驱动机制来跟踪整个集群中的元数据。以前由RPC处理的任务现在受益于事件驱动以及使用实际日志进行通信。这些变化(以及那些在原始设计中得到充分体现的变化)带来的令人愉悦的结果是,Kafka现在可以支持比以前更多的分区。让我们更详细地讨论。
扩展Kafka:支持数百万个分区
Kafka群集可以支持的分区数由两个属性确定:每个节点的分区数限制和群集范围的分区限制。两者都很有趣,但是迄今为止,元数据管理已成为整个集群范围限制的主要瓶颈。以前的Kafka改进建议(KIP)改进了每个节点的限制,尽管总有很多事情可以做。但是,Kafka的可扩展性主要取决于添加节点以获取更多容量。在这里,集群范围的限制变得很重要,因为它定义了系统内可伸缩性的上限。
新的仲裁控制器旨在处理每个群集更多的分区。为了对此进行评估,我们进行了与2018年之前运行的测试类似的测试,以宣传Kafka固有的分区限制。这些测试测量关闭和恢复所花费的时间,这是旧控制器的O(#partitions)操作。正是这一操作使Kafka如今可以在单个群集中支持的分区数量达到上限。
正如上文提到的Jun Rao所解释的那样,以前的实现可以实现20万分区,而限制因素是在外部共识(ZooKeeper)和内部领导者管理(Kafka控制器)之间移动关键元数据所花费的时间。使用新的仲裁控制器,这两个角色都由同一个组件担当。事件驱动的方法意味着控制器故障转移现在几乎是瞬时的。以下是在我们的实验中执行的,运行200万个分区(上限为以前的上限的10倍)的集群的摘要号:
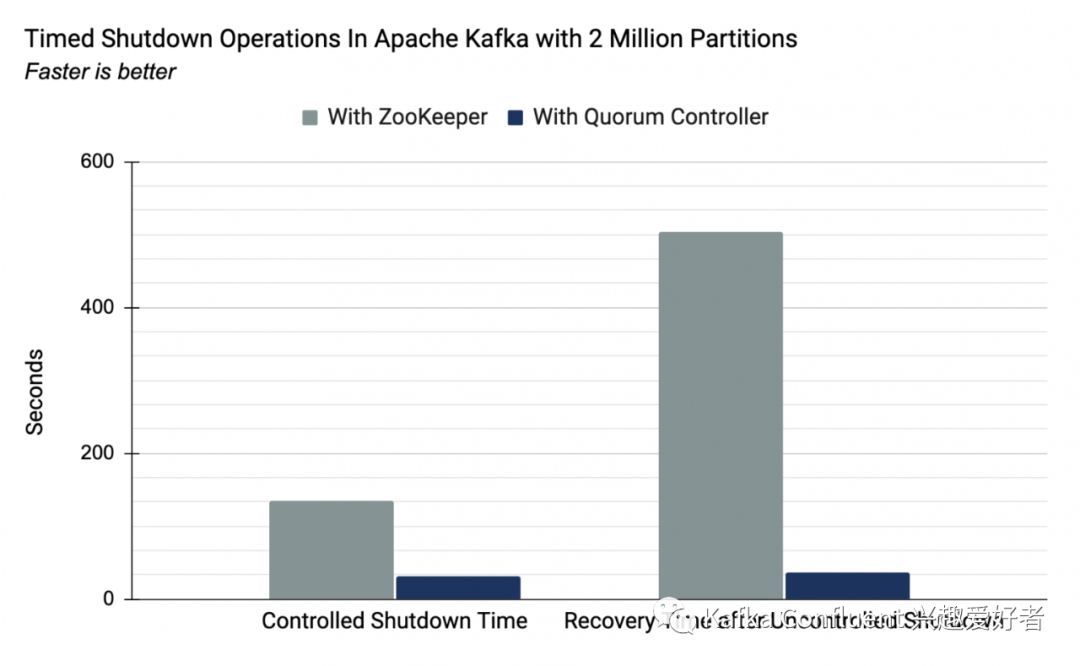
使用基于ZooKeeper 的控制器 | 带仲裁控制器 | |
| 受控关机时间 (200万个分区) | 135秒 | 32秒 |
| 从不受控制的关机中恢复(200万个分区) | 503秒 | 37秒 |
受控和非受控关机的两种措施都很重要。受控关闭会影响常见的操作场景,例如滚动重启:部署软件更改的标准过程,同时始终保持可用性。从不受控制的关闭中恢复可能更重要,因为它设置了系统的恢复时间目标(RTO),例如,在意外故障(例如,VM或pod崩溃或数据中心变得不可用)之后。尽管这些措施仅是更广泛的系统性能的指标,但它们直接衡量了ZooKeeper的使用所施加的众所周知的瓶颈。
请注意,受控和非受控测量无法直接比较。不受控制的关闭情况包括选举新领导人所需的时间,而不受控制的情况则没有。这种差异是故意的,以使受控案例与Jun Rao的原始度量保持一致。
缩减Kafka:将Kafka作为一个单一过程
kafka通常被认为是重量级的基础架构,而管理ZooKeeper(第二个独立的分布式系统)的复杂性则是存在这种感觉的重要原因。这通常会导致项目在开始时选择较轻的消息队列(例如ActiveMQ或RabbitMQ之类的传统队列),并在规模需求时迁移到Kafka。
这是不幸的,因为围绕提交日志形成的Kafka提供的抽象既适用于启动时可能看到的小规模工作负载,也适用于Netflix或Instagram上的高吞吐量工作负载。此外,如果要添加流处理,则无论是使用Kafka Streams,ksqlDB还是其他流处理框架,都需要Kafka及其提交日志抽象。但是由于管理两个独立的系统(Kafka和Zookeeper)的复杂性,用户经常感到他们必须在规模还是入门之间做出选择。
这种情况将不再出现。KIP-500和KRaft模式提供了一种很棒的,轻巧的方式来开始使用Kafka或将其用作ActiveMQ或RabbitMQ之类的整体经纪人的替代品。轻量级的单进程部署也更适合边缘方案以及使用轻量级硬件的方案。云为同一问题增加了有趣的切线角度。诸如Confluent Cloud之类的托管服务完全消除了运营负担。因此,无论您是要运行自己的集群,还是希望它为您运行,您都可以从小规模开始,随着基础用例的扩展而扩展到(可能)大规模—所有这些都使用相同的基础架构。让我们看一下单进程部署的外观。
以无Zookeeper的kafka为例
新的Quorum控制器今天以实验模式在主干中可用,预计将包含在即将发布的Apache Kafka 2.8版本中。那你该怎么办呢?如前所述,一个简单但非常酷的新功能是创建单个进程Kafka集群的能力,如下面的简短演示所示。(请点击左下角阅读原文观看视频)
当然,如果要扩展以支持更高的吞吐量并添加复制以实现容错功能,则只需添加新的代理进程。如您所知,这是基于KRaft的仲裁控制器的早期访问版本。请不要将其用于关键工作负载。在接下来的几个月中,我们将添加最后遗漏的部分,对协议进行TLA +建模,并在Confluent Cloud中强化仲裁控制器。
您可以立即尝试使用新的Quorum Controller。在GitHub上查看完整的自述文件。
背后的团队
如果没有Apache Kafka社区和一群分布式系统工程师,这是(并且一直是)一项巨大的努力,但要在疫情期间不知疲倦地工作,在大约九个月的时间内从零将一个工作系统转变为一个工作系统,是不可能的。在此,我们要特别感谢Colin McCabe,Jason Gustafson,Ron Dagostino,Boyang Chen,David Arthur,Jose Garcia Sancio,Guohang Zhang Wang,Alok Nikhil,Deng Zi Ming,Sagar Rao,Feyman,蔡家平,Jun Rao ,Heidi Howard和Apache Kafka社区的所有成员都帮助实现了这一目标。
