





死锁
问题出现
最近线上随着流量变大,突然开始报如下异常,即发生了死锁问题:
Deadlock found when trying to get lock; try restarting transaction ;
问题分析
查询事务隔离级别
利用 select @@tx_isolation
命令获取到数据库隔离级别信息:

查询数据库死锁日志
利用 show engine innodb status
命令获取到如下死锁信息:
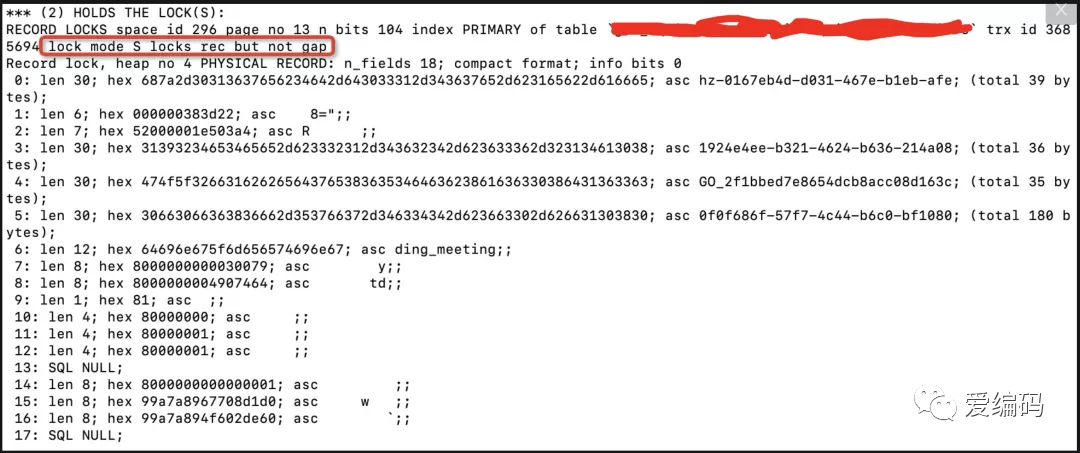
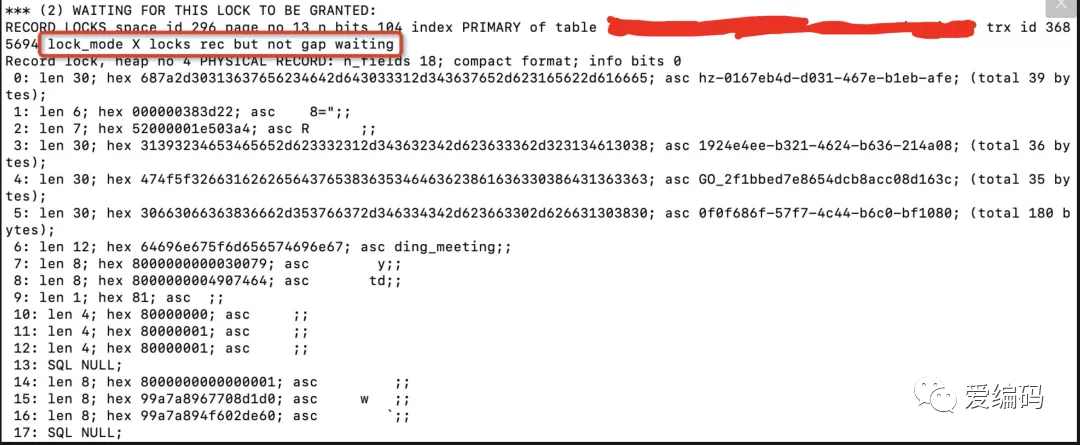
由上可知,是由于两个事物对这条记录同时持有S锁(共享锁)的情况下,再次尝试获取该条记录的X锁(排它锁),从而导致互相等待引发死锁。
分析代码
根据死锁日志的SQL语句,定位获取到如下伪代码逻辑:
@Transactional(rollbackFor = Exception.class)
void saveOrUpdate(MeetingInfo info) {
// insert ignore into table values (...)
int result = mapper.insertIgnore(info);
if (result>0) {
return;
}
// update table set xx=xx where id = xx
mapper.update(info);
}
获得结论
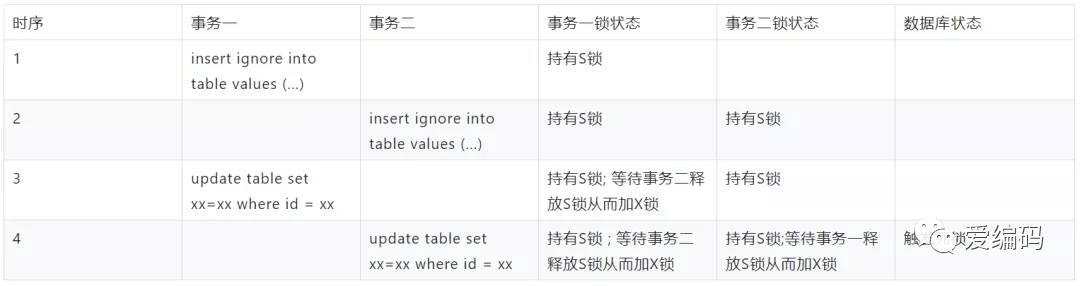
分析获得产生问题的加锁时序如下,然后修改代码实现以解决该问题。
慢SQL
问题出现
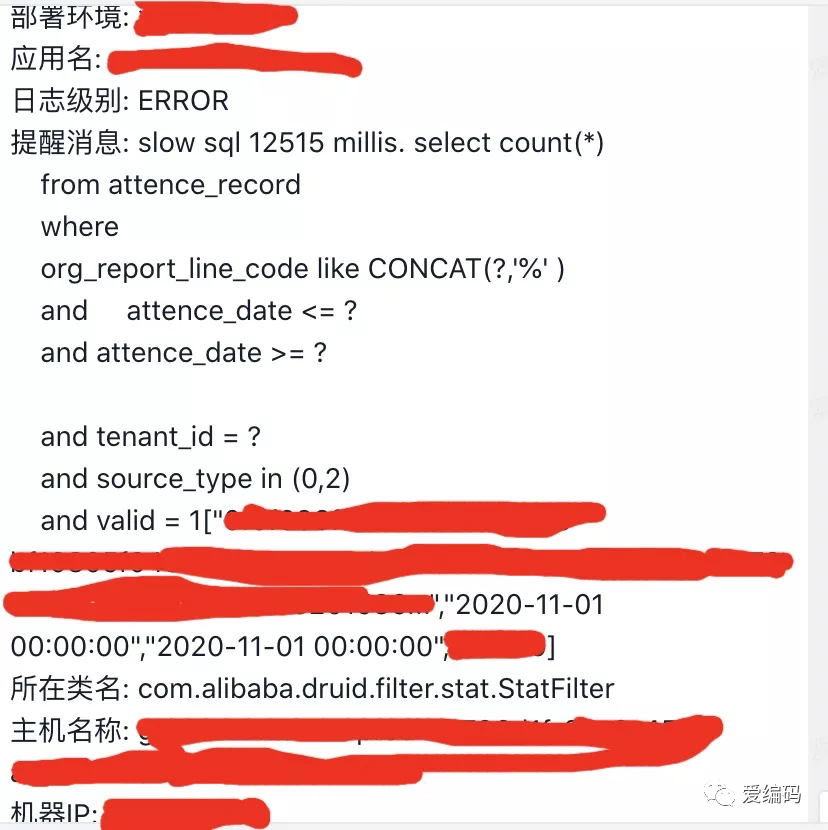
应用TPS下降,并出现SQL执行超时异常或者出现了类似如下的告警信息,则常常意味着出现了慢SQL。
问题分析
分析执行计划:利用explain指令获得该SQL语句的执行计划,根据该执行计划,可能有两种场景:
SQL不走索引或扫描行数过多等致使执行时长过长。 SQL没问题,只是因为事务并发导致等待锁,致使执行时长过长。
1优化SQL
通过增加索引,调整SQL语句的方式优化执行时长, 例如下的执行计划:

该SQL的执行计划的type为ALL,同时根据以下type语义,可知无索引的全表查询,故可为其检索列增加索引进而解决。
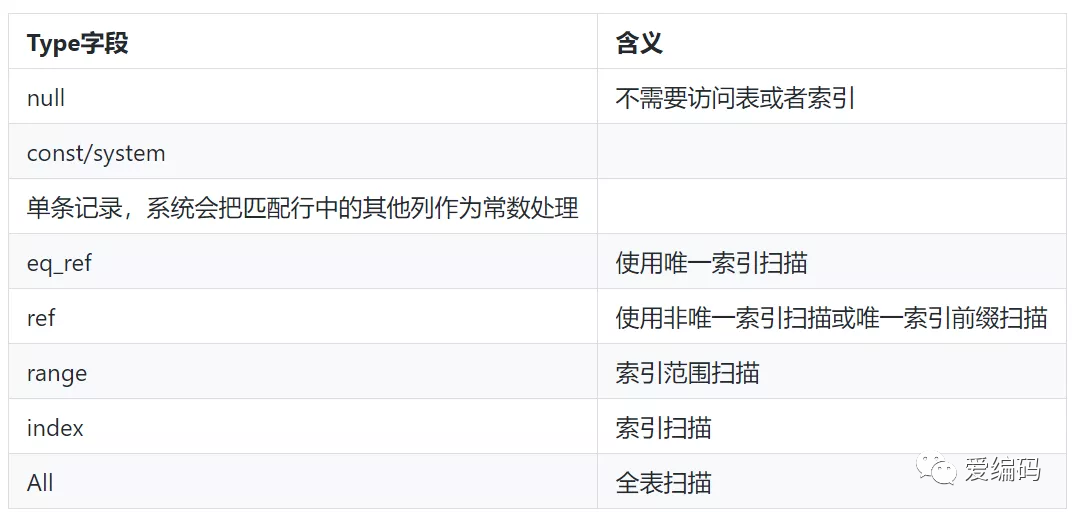
2 查询当前事务情况
可以通过查看如下3张表做相应的处理:
-- 当前运行的所有事务
select * from information_schema.innodb_trx;
-- 当前出现的锁
SELECT * FROM information_schema.INNODB_LOCKS;
-- 锁等待的对应关系
select * from information_schema.INNODB_LOCK_WAITS;
(1)查看当前的事务有哪些:
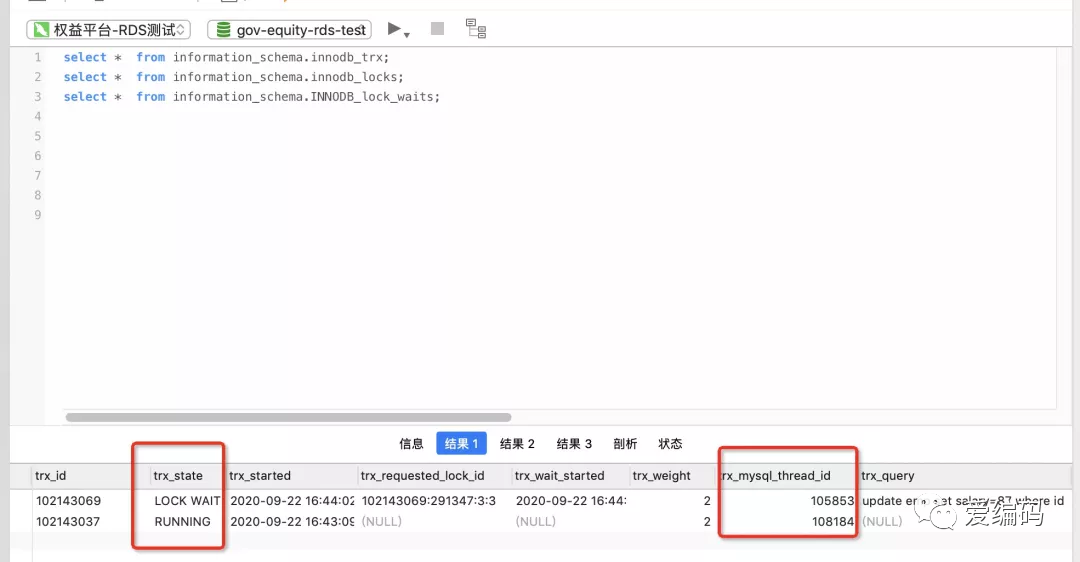
(2)查看事务锁类型索引的详细信息:

lock_table字段能看到被锁的索引的表名,lock_mode可以看到锁类型是X锁,lock_type可以看到是行锁record。
分析
根据事务情况,得到表信息,和相关的事务时序信息:
DROP TABLE IF EXISTS `emp`;
CREATE TABLE `emp` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`salary` int(10) DEFAULT NULL,
`name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name` (`name`(191)) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=6 DEFAULT CHARSET=utf8mb4;
A事物锁住一条记录,不提交,B事物需要更新此条记录,此时会阻塞,如下图是执行顺序:
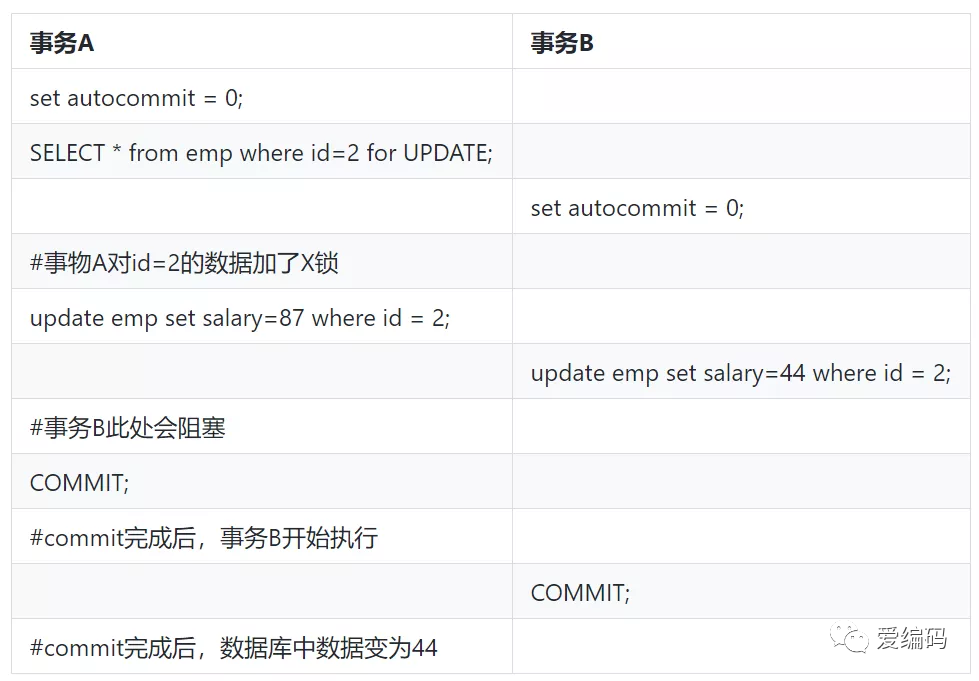
解决方案
(1)修改方案
由前一步的结果,分析事务间加锁时序,例如可以通过tx_query字段得知被阻塞的事务SQL,trx_state得知事务状态等,找到对应代码逻辑,进行优化修改。
(2)临时修改方案
trx_mysql_thread_id是对应的事务sessionId,可以通过以下命令杀死长时间执行的事务,从而避免阻塞其他事务执行。
kill 105853
连接数过多
问题出现
常出现too many connections异常,数据库连接到达最大连接数。解决方案
解决方案:
通过set global max_connections=XXX增大最大连接数。 先利用show processlist获取连接信息,然后利用kill杀死过多的连。
常用脚本如下:
排序数据库连接的数目
mysql -h127.0.0.0.1 -uabc_test -pXXXXX -P3306 -A -e 'show processlist'| awk '{print $4}'|sort|uniq -c|sort -rn|head -10
相关知识
锁类型

表锁的优势:开销小;加锁快;无死锁。
表锁的劣势:锁粒度大,发生锁冲突的概率高,并发处理能力低。
加锁的方式:自动加锁。查询操作(SELECT),会自动给涉及的所有表加读锁,更新操作(UPDATE、DELETE、INSERT),会自动给涉及的表加写锁。也可以显示加锁。
共享读锁:lock table tableName read
独占写锁:lock table tableName write
批量解锁:unlock tables
X/S锁
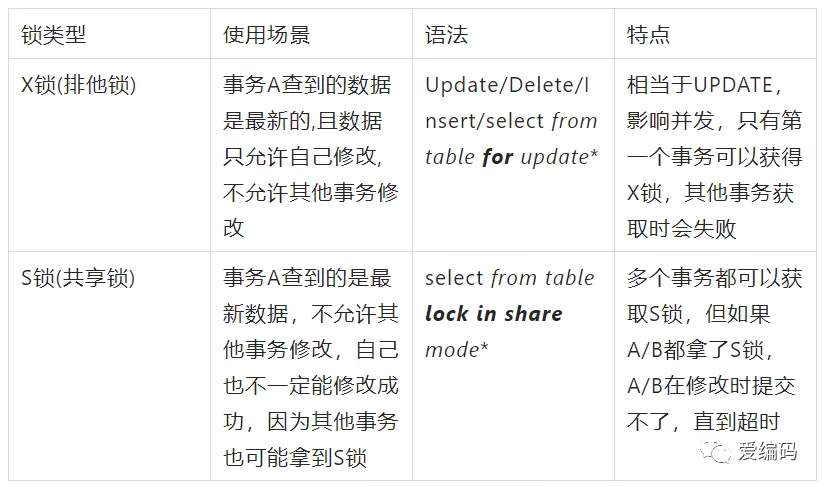
一条SQL的加锁分析
-- select操作均不加锁,采用的是快照读,因此在下面的讨论中就忽略了
SQL1:select * from t1 where id = 10;
SQL2:delete from t1 where id = 10;
组合分为如下几种场景:
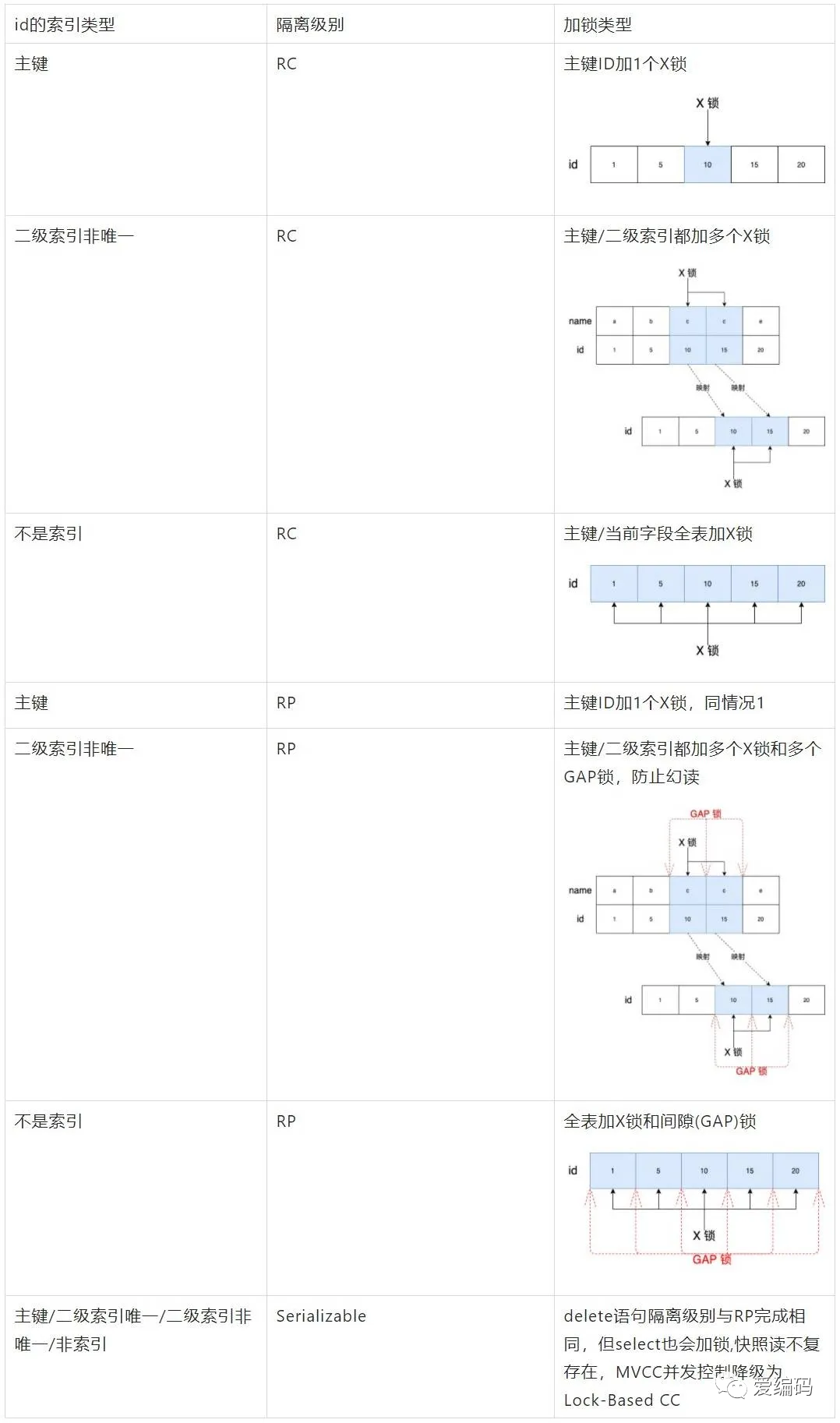
分析
【组合5】Insert操作,如insert [10,aa],首先会定位到[6,c]与[10,b]间,然后在插入前,会检查这个GAP是否已经被锁上,如果被锁上,则Insert不能插入记录。因此,通过第一遍的当前读,不仅将满足条件的记录锁上 (X锁),同时还是增加3把GAP锁,将可能插入满足条件记录的3个GAP给锁上,保证后续的Insert不能插入新的id=10的记录,也就杜绝了同一事务的第二次当前读,出现幻象的情况。
既然防止幻读,需要靠GAP锁的保护,为什么【组合5】是RR隔离级别,却不需要加GAP锁呢?
GAP锁的目的,是为了防止同一事务的两次当前读,出现幻读的情况。而【组合5】id是主键(unique键),都能够保证唯一性。
一个等值查询,最多只能返回一条记录,而且新的相同取值的记录,一定不会在新插入进来,因此也就避免了GAP锁的使用。
总结
Repeatable Read隔离级别下,id列上有一个非唯一索引,对应SQL:delete from t1 where id = 10; 首先,通过id索引定位到第一条满足查询条件的记录,加记录上的X锁,加GAP上的GAP锁,然后加主键聚簇索引上的记录X锁,然后返回;然后读取下一条,重复进行。直至进行到第一条不满足条件的记录[11,f],此时,不需要加记录X锁,但是仍旧需要加GAP锁,最后返回结束。
什么时候会取得gap lock或nextkey lock 这和隔离级别有关,只在REPEATABLE READ或以上的隔离级别下的特定操作才会取得gap lock或nextkey lock。
一些建议
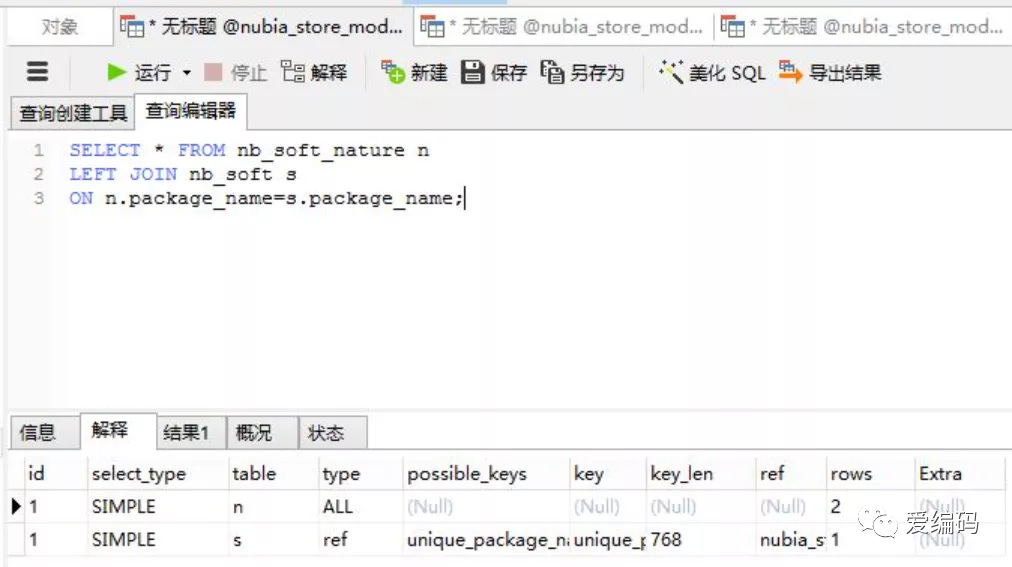
1 小表驱动大表
nb_soft_nature:小表 nb_soft:大表 package_name:都是索引
MySQL 表关联的算法是Nest Loop Join(嵌套循环连接),是通过驱动表的结果集作为循环基础数据,然后一条一条地通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。
(1)小表驱动大表
2 使用自增长主键
结合B+Tree的特点,自增主键是连续的,在插入过程中尽量减少页分裂,即使要进行页分裂,也只会分裂很少一部分。并且能减少数据的移动,每次插入都是插入到最后。总之就是减少分裂和移动的频率。
