





作者介绍

黎俊杰,性能优化专家,跟随国内知名性能优化大师白鳝(老白)多年,子衿技术团队性能优化主要技术骨干,具有12年以上大型制造物流、电力能源行业信息系统需求设计与管控、业务逻辑设计、软硬件架构设计、数据存储结构设计、数据库存储过程&函数&触发器&SQL语句的开发与优化、小机&X86服务器硬件维护与优化、AIX&Linux操作系统运维与优化、大型Oracle&PostgreSQL高可用设计实施运维及优化、Weblogic中间件运维与优化、HP&IBM&EMC存储设备运维与优化、大型园区主干网络设计与思科防火墙&路由器&三层交换机&二层交换机配置管理经验,积累了大量规划设计、故障分析诊断、优化调整的技术文档。对新系统需求设计与实现逻辑设计引导、数模设计、SQL优化审核、数据库自动化运维、趋势预测、智能告警、报表分析等方面具有独到的研究与实际开发应用经验。
目 录
一、环境介绍
二、问题现象
三、主要矛盾问题分析
四、具体原因分析
(一)是什么事件引发这么大的gc等待事件
1、GC等待时间最多的SQL语句
2、gc Buffer Busy等待最严重的对象
3、导致gc等待严重的事件小结
(二)是什么原因导致产生大量的心跳流量
1、第一条引发心跳流量大的SQL语句6gsjptndc2jax
2、第二条引发心跳流量大的SQL语句8bsz8gansr3v0
3、第三条引发心跳流量大的SQL语句cbzqkd3hsrc8k
4、节点间心跳网络传输量巨大原因分析小结
(三)当前心跳大流量合理与正常吗
1、当前心跳网络流量分析
2、当前心跳大流量不合理性分析小结
(四)是什么事件产生严重行锁争用等待
1、引发行锁争用的表分析
2、引发行锁争用的SQL语句分析
3、严重行锁争用原因分析小结
(五)在大流量需求下为什么心跳流量却只有约20MB/s15
1、网络历史流量分析
2、网络流量变化原因分析
五、本次事件原因与隐患问题总结
(一)本次故障直接现象原因总结
(二)本次故障暴露出的其它隐患总结
在充满激情与挑战的2016年里,亲身主导与参与处置分析的信息系统疑难故障估摸也有个六七十次以上吧。有些故障在处置与分析后进行了总结,也有些故障在处置结束或分析出原因后,因为工作的“繁忙”与自己的懒惰却没有进行总结。其实所谓“繁忙”也许只是给自己的一个借口而已吧,因为谁都知道,时间就象乳沟,挤挤总是有的。对于大量的亲身经验没有得到及时的总结,也确实是我这一年工作中留在心中的一大遗憾啊。
此文所述的故障,现在已经可以准确的说这是我在2016年最后一次的信息系统故障处置与原因分析任务了,在此,一定要把经验总结出来。这也是我写在2016年的最后一天,2017年发表的第一篇个人技术文章。文章具有“打賞”功能,希望这篇文章能帮助到更多的DBA同行朋友,当然也希望能得到更多朋友的“打賞”,鼓励我在2017年里多一些勤快,少一些懒惰,能多写一些能够帮助到大家的经验总结技术文章。
一、环境介绍
一套两节点的ORACLE RAC数据库,两个节点的心跳网络网卡均为千兆支持全双工网卡,均与千兆支持全双工交换机相连,形成千兆心跳网络。
二、问题现象
业务系统响应缓慢,数据库上反映出节点间心跳网络数据传输量不大,Estd Interconnecttraffic (KB)指标值在20MB左右,并不算大,离千兆网络的吞吐量峰值还差得太远,但是GC相关等待严重,等待次数多,仅gc buffer busy在60分钟内就待待五百多万次,平均响应时间长,达到40ms。
三、主要矛盾问题分析
分析该数据库的当前主要矛盾问题,还是先从AWR的TOP5事件入手。
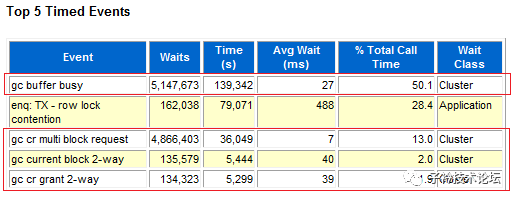
从上面1小时AWR报告中的top 5事件来看,gc buffer busy,gc cr multi blockrequest等待次数最多,分别为五百一十多万次和四百八十多万次,而且Avg Wait的时间也非常长,gc buffer busy、gc current block 2-way、gc cr grant 2-way等待的平均时间分别为27ms、40ms和39ms,说明由于节点间不仅cache fusion的 block传输需求量巨大,而且是大到当前的网络传输速度不足以支撑,致使整个业务响应访问缓慢。
上面说到cache fusion的 block传输需求量巨大,那因为cache fusion产生的网络流量到底有多大呢,从下面显示数据来看,流量却只有20MB左右:
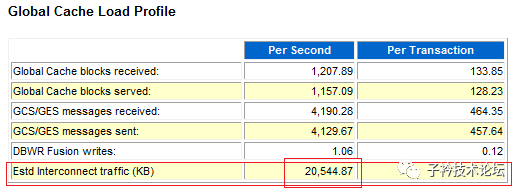
分析上述数据,发现了主要的矛盾问题:一方面是有大量的数据需要通过心跳线传输,因为量太大与传输能力的不足,导致平均响应时间非常长,但另一方面却发现心跳的数据传输量只有20MB左右,千兆网卡的能力完全没有发挥出来,形成巨大的“供”、“需”不对称矛盾。找到这个矛盾点,或许问题原因就能真相大白。
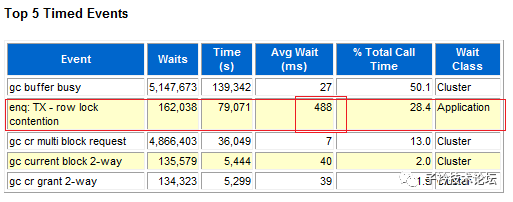
同时,顶级等待事件top5中4个事件为gc相关事件,其中夹杂着一个enq:TX-row lock contention行级锁争用等待事件,并且这个等待的次数也非常大,1小时达到十六万多次,平均每次需要等待488ms,两个问题放在一起,到底哪个问题是最矛盾的问题,很容易让人迷失方向。下面是top 5中的enq:TX-row lock contention等待信息情况:
分析到此,衍生出5个主要矛盾问题:
(1)是什么事件引发这么大的gc等待事件?
(2)是什么原因导致产生大量的心跳流量?
(3)当前心跳大流量合理与正常吗?
(4)是什么事件产生严重行锁争用等待?
(5)在大流量需求下为什么心跳流量却只有约20MB/s?
下面一章,将对上面5个问题进行详细的分析,将问题白盒化后就能见到真相。
四、具体原因分析
(一)是什么事件引发这么大的gc等待事件
1、GC等待时间最多的SQL语句

SQL_ID为6gsjptndc2jax、8bsz8gansr3v0 、cbzqkd3hsrc8k的三条SQL语句在跨节点等待上鹤立鸡群,等待事件与集群相关的主要是gc buffer busy、gc cr multi block request、gc current block 2-way,三条语句所操作的表都是SSO.TASK_TASKINFOTB,在两个节点上的情况基本相同。
三条SQL语句的详细文本如下:
(1) SQL_ID:6gsjptndc2jax
delete from task_taskinfotb where appid=:1 and apptaskid=:2 |
(2)SQL_ID:8bsz8gansr3v0
insert into task_taskinfohistb select * from task_taskinfotb t where t.appid=:1 and t.apptaskid=:2 |
(3)SQL_ID:cbzqkd3hsrc8k
update task_taskinfotb set task_taskinfotb.LASTHANDLETIME=:1,task_taskinfotb.status=:2 where task_taskinfotb.appid=:3 and task_taskinfotb.apptaskid=:4 |
2、gc Buffer Busy等待最严重的对象
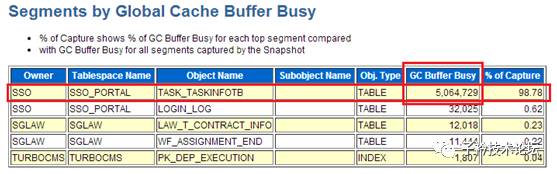
gc bufferbusy的表则也是集中在SSO.TASK_TASKINFOTB一张表上面,占整个数据库gc buffer busy的98.78%。与上面的发现引发gc事件的SQL语句中所操作的表相吻合。
3、导致gc等待严重的事件小结
由于业务设计时没有设计尽查让相同表的操作只在一个节点上执行,而是同时在两个节点上对SSO.TASK_TASKINFOTB一张表做大量相同的update、delete操作,形成较大的gc事件,以及有可能的大量块扫描(如全表扫描)导致gc buffer busy的block数量增大加剧了gc等待事件,下一节“是什么原因导致需要大量的心跳流量”将验证这一点。
(二)是什么原因导致产生大量的心跳流量
上一节,分析了导致大量gc等待原因的事件,并且有巨大的buffer block通过心跳传输需求,是什么原因导致需要这么巨大的gc buffer block传输量呢,很有可能是gc事件的SQL语句执行的是全表扫描所致。下面来验证一下。
1、第一条引发心跳流量大的SQL语句6gsjptndc2jax:
(1)SQL语句6gsjptndc2jax的执行统计信息
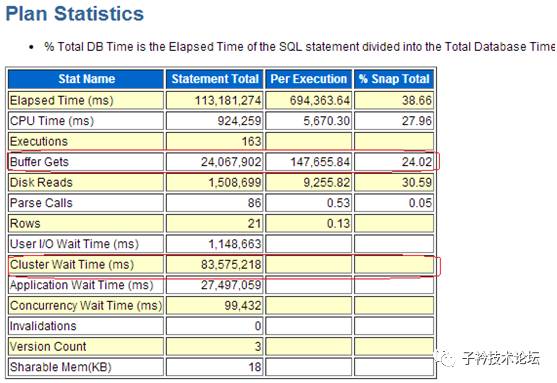
统计信息非常直观的看出BUFFER GETS的数量与Cluster Wait Times的时间消耗非常长。
(2)SQL语句6gsjptndc2jax的执行计划
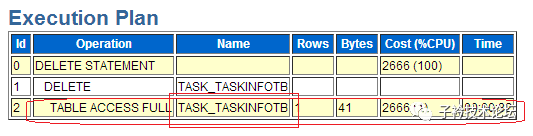
果然是对TASK_TASKINFOTB表执行全表扫描,扫描一次需要32秒。可以非常明确,这条SQL语句如果同时在RAC的两个节点上同时执行,必定会产生较大的心跳网络流量。
2、第二条引发心跳流量大的SQL语句8bsz8gansr3v0
(1)SQL语句8bsz8gansr3v0的执行统计信息
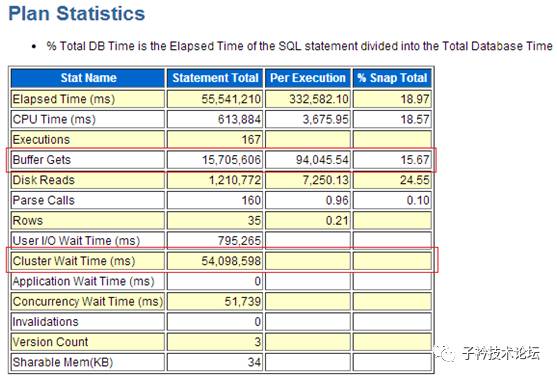
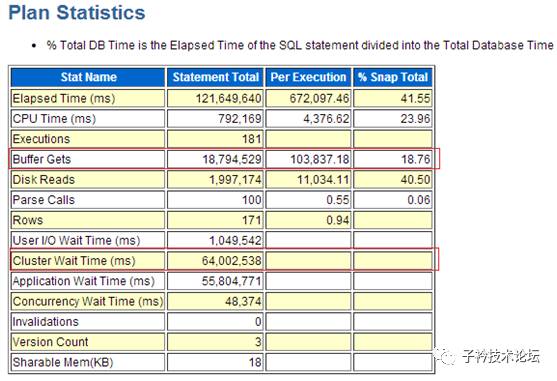
同样的是统计信息非常直观的看出BUFFER GETS的数量与Cluster Wait Times的时间消耗非常长。
(2)SQL语句8bsz8gansr3v0的执行计划
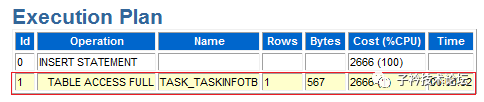
第二条SQL语句仍然是对TASK_TASKINFOTB表执行全表扫描,扫描一次需要32秒。可以非常明确,这条SQL语句如果同时在RAC的两个节点上同时执行,必定会产生较大的心跳网络流量。
3、第三条引发心跳流量大的SQL语句cbzqkd3hsrc8k
(1)SQL语句cbzqkd3hsrc8k的执行统计信息
(2)SQL语句cbzqkd3hsrc8k的执行计划
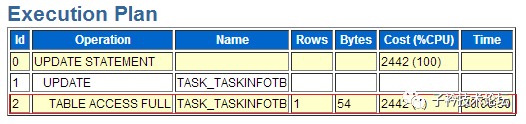
第三条SQL语句仍然是对TASK_TASKINFOTB表执行全表扫描,扫描一次需要30秒。
4、节点间心跳网络传输量巨大原因分析小结
TASK_TASKINFOTB表的大小有702MB,三条全表扫描,并且在RAC的两个节点同时执行频繁的SQL语句,必定会带来巨大的节点间心跳网络数据传输。
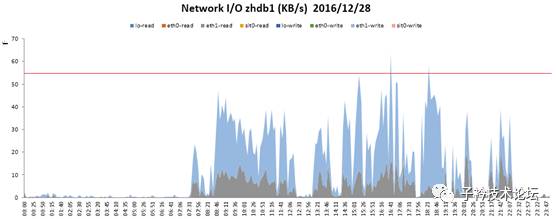
上面以系统正常运行时期2016年12月28日(周三)的网络传输数据来看,心跳网络(eth1)的高峰流量达到55MB左右,超过百兆网络能够提供带宽能力的2倍多,必须千兆网络才能满足需求。
(三)当前心跳大流量合理与正常吗
1、当前心跳网络流量分析
在上面的“是什么事件引发这么大的gc等待事件”与“是什么原因导致需要大量的心跳流量”两节中,已知明确知道了是三条操作SSO.TASK_TASKINFOTB表全表扫描的语句所致。但这种大流量需求是正常的吗,除了上面所说的设计时没有考虑尽量将操作同一张表的业务放置在一个节点上执行外,是否还有其它的隐患推手呢?
三条SQL每次执行真正操作最多的行数也才170余条而已,经过对SSO.TASK_TASKINFOTB表的分析,发现该表中却只有67148行数据,平均行长度为505(bytes),但是却占用了89918个Block(每个block大小为8Kb),segment大小达到了702MB。

根据所存的数据计算,SSO.TASK_TASKINFOTB表的真正大小应该在36MB左右,但却被撑到了702MB,碎片率达到了94.9%。
2、当前心跳大流量不合理性分析小结
在当前业务访问设计不改变的情况下,如果消除这94.9%的碎片,表的大小可以下降到约36MB,这样,即使三条SQL语句都是执行的全表扫描,那节点间的网络流量也可以从当前业务正常运行情况下的55MB左右下降到5-7MB左右,是百兆网络就能足足满足的需求。
当然,36MB的表执行全表扫描,消耗的代价仍然会较大,如果为这三条SQL语句设计合适的索引,执行效率可以得到更大的提升、节点间的流量还可以进一步下降。至于怎么为这三条SQL语句设计索引,本文将不做深入分析设计。
(四)是什么事件产生严重行锁争用等待
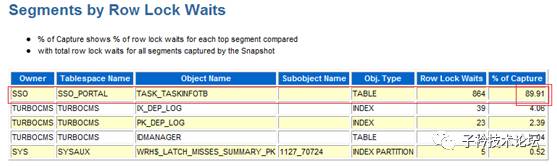
1、引发行锁争用的表分析
2、引发行锁争用的SQL语句分析
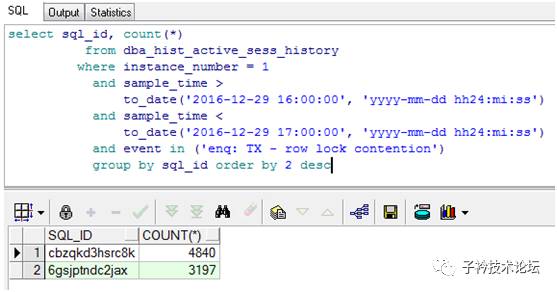
等待事件为‘enq:TX-row lock contention’的就只有SQL_ID为cbzqkd3hsrc8k和6gsjptndc2jax的两条SQL语句,并且这两条语句都是对OWNER为sso的task_taskinfotb表做操作,一条为update,一条为delete,两条SQL语句具体文本分别如下:
delete from task_taskinfotb where appid=:1 and apptaskid=:2 |
update task_taskinfotb set task_taskinfotb.LASTHANDLETIME=:1,task_taskinfotb.status=:2 where task_taskinfotb.appid=:3 and task_taskinfotb.apptaskid=:4 |
从执行SQL语句等待事件为“enq:TX-row lock contention”中操作的表与AWR报中“Segments by Global Cache Buffer Busy”,得到的对象均是SSO.TASK_TASKINFOTB表,说明gc最大的问题就在这张表上。
产生enq:TX-row lock contention等待事件的原因主要有:
1)不同的session更新或删除同一条记录
2)唯一索引插入重复值
3)位图索引同时被update 、delete或同时并发的向位图索引字段上插入相同的值
查询SSO.TASK_TASKINFOTB表的索引分布情况如下:
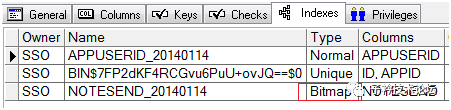
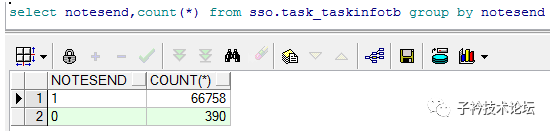
在SSO.TASK_TASKINFOTB表上果然有一个NOTESEND列的位图索引,并且NOTESEND列的值只有两种,说明在位图索引上大量update、delete是产生大量enq:TX-row lock contention等待事件的主要原因。下面是NOTESEND列的值分组统计结果:
3、严重行锁争用原因分析小结
引发严重行锁争用的SQL语句,同时也是引发高gc与心跳网络间大流量语句中的其中两条(cbzqkd3hsrc8k和6gsjptndc2jax),但引起行争用的原因,却是因为SSO.TASK_TASKINFOTB表上的一个只有两种值的位图索引所致,由于位图索引的特性是对列的每个键值建立一个位图,如果对位图索引列进行insert、update、delete ,会导致此列值的位图向量发生改变,将表上此列值的所有行全部锁定。解决该位图索引问题,该行锁争用问题就可以解决。至于该位图索引该怎么解决,本文暂不做详细分析。
(五)在大流量需求下为什么心跳流量却只有约20MB/s
本文中所分析的问题,从表象上看,最大的矛盾是数据库有较大的心跳间数据传输需求,但是速度却很慢,慢到平均等待时间达到27-40毫秒,可实际节点间心跳传输量又上不去,只有20MB/S的怪异现象。
1、网络历史流量分析
(1)12月29日,读、写分别统计显示图
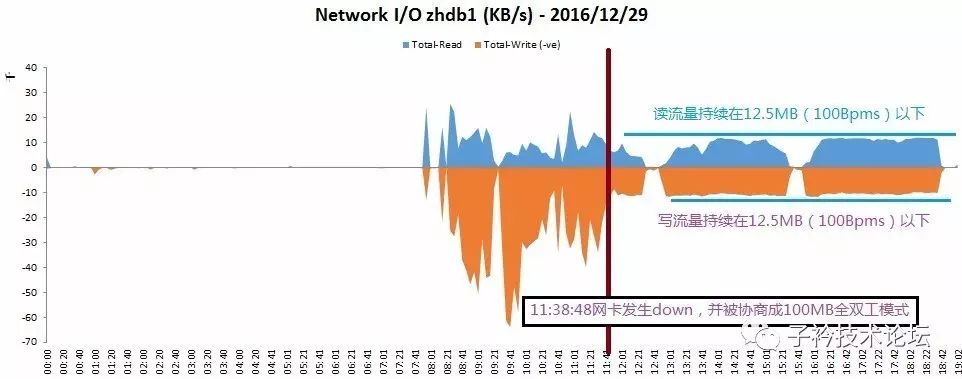
(2)12月29日,读、写汇总统计显示图
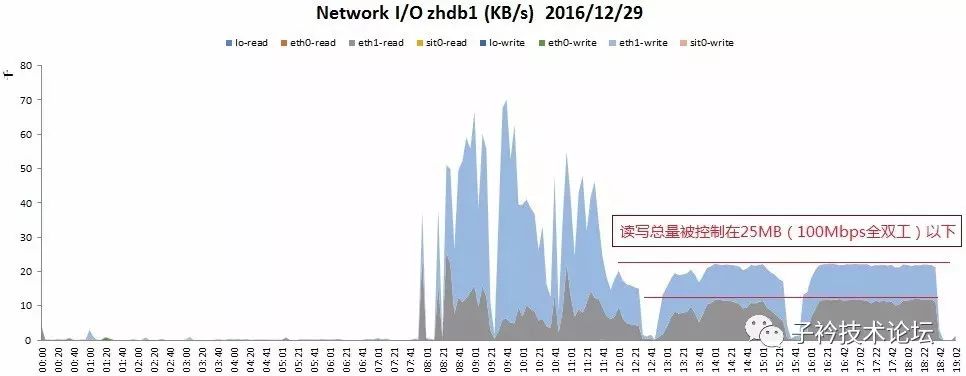
从上面12月29日的心跳网络流量图分析,发现在11:38:48这个时间点以前的网络流量读写高峰达到约70MB/S,但是在这时间之后,读写总流量即只有约20MB/S,而且流量大小几乎无波动,平成一条线,太有规则性。
(3)12月30日,读、写分别统计显示图
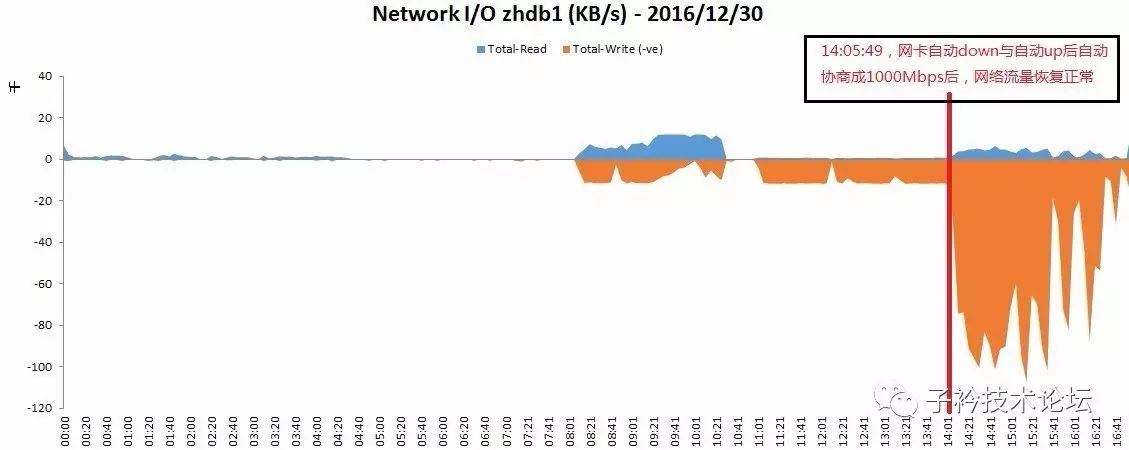
12月30日的心跳网络数据的趋势,和12月29日相比,正好呈反向趋势,在14:05:49以前,网络流量稳定得平成一条线,而在之后,心跳网络流量突然增长至80MB/s。这两天的对比数据数据看着确实有意思,也很容易让人激动,笔者在看到这个数据时也确实是激动了一把^_^。
2、网络流量变化原因分析
(1)经分析操作系统日志,发现在2016-12-29 11:38:48,1节点,心跳网络网卡发生Down,并自动UP,在UP后,网络速率自动协商成100Mbps全双工模式。

(2)100Mbps全双式模式下,网络上传、下载分别最大为12.5MB以下(100/8=12.5),网络上下行总速度最大为25MB。
(3)根据历史网络流量数据显示,业务正常运行情况下,RAC两个节点间的心跳网络读写总流量达到60-70MB/s,高峰时能达到100MB/s左右,但是在12月29日11:38:48秒以后,网络读写总速度被限制在了25MB/s以下,并且总流量非常均衡的维护在20MB/s左右,说明流量需求无法上升。
(4)直到2016年12月30日14:05:45,网卡再次down并自动up后,自动协商成1000Mbpms全双工。

(5)自动协商成1000Mbps全双工后,网络流量恢复正常。
五、本次事件原因与隐患问题总结
(一)本次故障直接现象原因总结
本次故障,从直接现象来看,是因为网络发生自动down与自动up后,在交换机与服务器自动协商速率与模式时出现了问题,没有选择双方最大的处理能力的1000Mbps全双工,而错误的选择了100Mbps全双工,导致需求较大的网络流量被压制,形成系统响应缓慢的故障。
至于引发网络自动down与自动up并自动协商速率的原因,经初步分析主要有如下几种原因:
(1)交换机端口可能的不稳定或需要重新协商速率导致的down与up;
(2)网络线路质量欠佳可能导致的瞬间中断与恢复导致的down与up;
(3)服务器网卡硬件的不稳定可能导致的自动down与up;
(4)服务器网络微码的过低有可能存在BUG导致的自动down或需要重新协商速率导致的down与up;
(5)操作系统层网卡驱动版本有可能过低存在BUG导致的自动down或需要重新协商速率导致的down与up,经排查,该网卡驱动版本当前为1.6.9,而当前最高版驱动版本为V5以上。
(二)本次故障暴露出的其它隐患总结
(1)SSO.TASK_TASKINFOTB表的碎片率达到了94.9%,本应只占约36MB左右数据量的表,大小被碎片化到了702MB,导致RAC环境中两个节点同时执行的全表扫描SQL语句产生大量的心跳网络数据传输,引发严重的gc等待事件,在网络速度支撑能力不足时,致使系统响应缓慢。
(2)三条全表扫描的SQL语句,没有设计有效的索引,导致产生大量的心跳网络数据传输,引发严重的gc等待事件。
(3)SSO.TASK_TASKINFOTB表在一个只有2种值的NOTESEND字段上设计了一个位图索引(bitmap),致使update、delete更新该列数据时,因为位图索引的特性,产生严重的行级锁争用。
(4)系统设计时缺乏对根据ORACLE RAC工作特性原理而设计的相同表操作尽可能的节点隔离。
本文中所述的4项隐患问题,在系统一切正常时,都不会严重影响至系统停运,而在此次,遇到了心跳网络从千兆被适应到了百兆的这个小异常,它们就共同制造出了这起信息系统较为严重故障事件。
