




作者简介: |
黎俊杰 性能优化专家,跟随国内知名性能优化大师白鳝(老白)多年,子衿技术团队性能优化主要技术骨干,具有12年以上大型制造物流、电力能源行业信息系统需求设计与管控、业务逻辑设计、软硬件架构设计、数据存储结构设计、数据库存储过程&函数&触发器&SQL语句的开发与优化、小机&X86服务器硬件维护与优化、AIX&Linux操作系统运维与优化、大型Oracle&PostgreSQL高可用设计实施运维及优化、Weblogic中间件运维与优化、HP&IBM&EMC存储设备运维与优化、大型园区主干网络设计与思科防火墙&路由器&三层交换机&二层交换机配置管理经验,积累了大量规划设计、故障分析诊断、优化调整的技术文档。对数据库自动化运维、趋势预测、智能告警、报表分析等方面具有独到的研究与实际开发应用经验。 |

企业的信息化系统,为了满足高可用要求,基本都会花高成本构建各类高可用架构,希望在发生故障时,能有各种自动、半自动或可手工切换与接管的后备环境,达到可缩短故障时间与降低故障所带来的影响的目的。但是,您所构建的各类高可用架构,在故障时,真的能实现自动或快速切换的高可用目标吗。
下面高可用架构,是笔者要分享的“高可用,要用时,高不可用”原因诊断分析案例中的的HA部署架构:
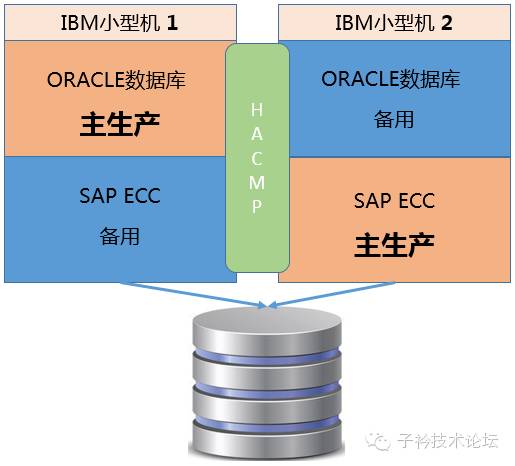
第1台主机,运行有ORACLE主生产数据库(单实例),同时充当SAP ECC 的备用环境
第2台主机,运行有SAP ECC主生产环境,同时充当ORACLE数据库备用环境(shutdown状态)
上述部署结构,以两台小机+1台共享存储,采用HACMP做为高可用管理软件,构成典型的HA架构,同时,两台主机均有自己的主运行程序,并且充当另一台主机所运行程序功能的备用主机,当第1台主机出现故障时,数据库可以通过HACMP自动或手动的切换到2节点上,当第2台主机故障时,SAP ECC也可以自动或手动的切换到1节点上,形成了一个两节点的功能互备的高可用集群架构。
如果说是满足一定RTO(Recovery TimeObjective,复原时间目标)要求的高可用架构,这个设计还是挺理想的。
就是设计这么理想的高可用架构,在有故障需要切换时,却切遇到了问题,导致了好几个小时的故障,这到底是怎么回事呢?
1、HA高可用无法切换故障现象
(1)2节点(RXXXHPRD2,物理IP:10.X.XX.67,虚拟IP:10.X.XX.68),因为SAPECC重启时起不来,系统维护人员手工对操作系统进行了重启
(2)2节点(RXXXHPRD2,物理IP:10.X.XX.67,虚拟IP:10.X.XX.68)操作系统重启后,正常情况下,2节点集群中的软件及资源(sap ecc、虚拟IP,共享存储卷激活状态)应该漂到1节点,以继续提供服务,这也是两台服务器创建HA的目标
(3)在2节点重启完成,1节点没有正常接管的情况下,手工启动2节点的高可用软件(HACMP)失败,导致2节点无法激活共享VG,以及对SAPECC绑定的对外提供服务的虚拟IP 10.X.XX.68不能生成
(4)手工在1节点上进入高可用管理软件(HACMP),试图将资源转移到1节点,同样无法成功
(5)在虚拟IP 10.X.XX.68不能生成的情况下,SAP ECC无法正常启动
2、本HA故障案例分析所涉及日志来源信息列表
序号 | 日志名称 | 所属 | 日志说明 |
1 | hacmp.out | 1 | 记录HACMP 事件脚本和实用程序的运行情况 |
2 | cluster.log | 1 | 记录集群脚本和后台进程等运行情况 |
3 | cluster.log | 2 | 记录集群脚本和后台进程等运行情况 |
3、 本次临时故障解决方法
(1)通过在2节点(RXXXHPRD2,物理IP:10.X.XX.67,虚拟IP:10.X.XX.68)上,手工激活共享卷(civg卷),即绕过高可用(HACMP),以单节点、无高可用方式运行
(2)手工将虚拟IP:10.X.XX.68绑定到2节点的en2网卡上,以使SAP ECC所指定的IP地址活跃可通
(3)在2节点手工启动SAP ECC,启动成功,并可对外提供服务
4、 故障原因及高可用不能正常切换总结
(1) 在2节点的civg上,于2015年1月27日和10月29日,两次采用extendvg命令对civg中添加磁盘的不恰当的或不完整的操作方式,导致在2节点的加盘信息,没有被自动同步到1节点的VG中,也未实施手工同步操作
(2) 在HACMP软件做切换的过程中,对civg卷组中的磁盘信息校验时,发现本机磁盘状态信息与HACMP的信息不一致,从而无法启动
5、 故障原因分析过程及证明日志
(1) 通过在集群节点1(RXXYHPRD1IP:10.X.XX.65)上的高可用管理软件(HACMP)日志中查看到,集群节点2(RXXXHPRD2 IP:10.X.XX.67),在7点26分重启操作系统后,集群节点1上的高可用管理软件(HACMP)侦测到网络心跳故障,集群节点1中的高可用管理软件(HACMP)做出了资源切换动作:
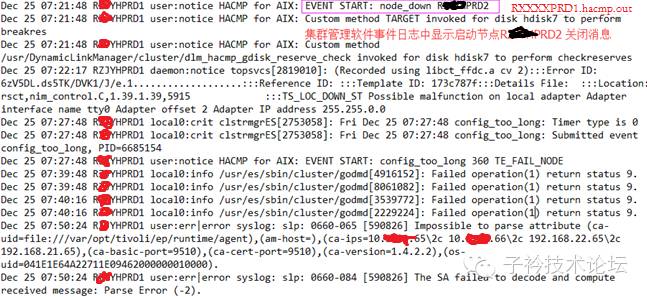
(2)HACMP尝试把SAP软件所使用的civg资源在集群节点1激活,但是不成功,报出错误日志信息如下:
0516-052 varyonvg: Volume group cannotbe varied on without a\n\tquorum. More physical volumes in the group must beactive.\n\tRun diagnostics on inactive PVs.' ,This normally happens when a PV is added/deleted into a VG on onenode and not imported。
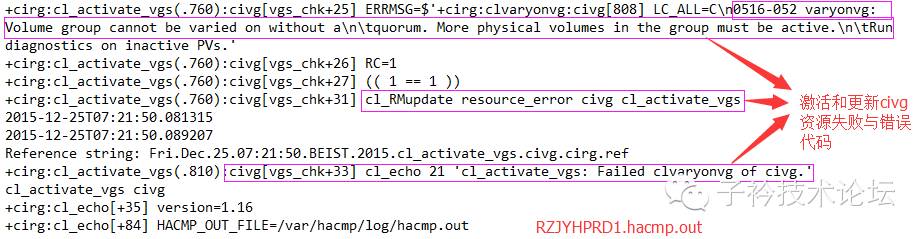
根据上面错误日志判断,有些盘是后来追加到civg卷组中,却因没做导入(import)操作或缺少高可用(HA)信息同步过程,2个集群节点的civg卷组中的物理卷信息不一致导致此次资源切换失败。
(3)1节点报出civg不能激活的原因为“新增加的磁盘(PV)没有加入到VG中来”的告警信息

(4)人工对比1节点和2节点的磁盘信息,发现确实不一致
A、1节点的磁盘信息
操作系统中有看到“hdisk42”和 “hdisk45”两块盘,没有相对应的VG信息,说明没有加入到任何VG中。
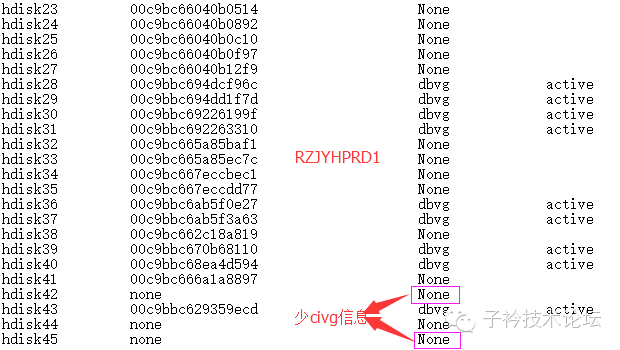
B、2节点的磁盘信息
操作系统中有看到“hdisk42”和 “hdisk45”两块盘,均有对应的VG信息,并且是对应的civg,说明在2节点,这两块盘是有加入VG的。

(5)找出在2015年1月27日和2015年10月29日分别有在2节点上增加磁盘,并且增加的磁盘,正好是1节点上没有对应VG关系的“hdisk42”和 “hdisk45”两块盘
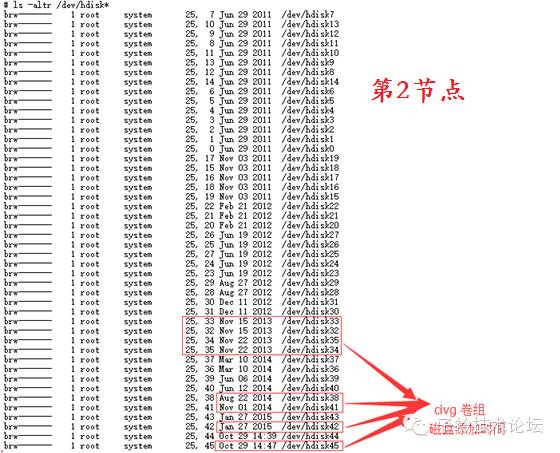
(6)2节点上曾使用smit extendvg命令加盘历史命令记录
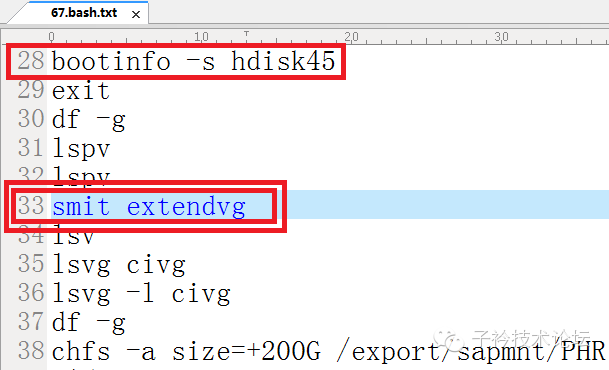
6、 高可用,要用时,高不可用原因总结
在建设初期,投入了大量的软硬件设备构建了高可用架构,但是,由于日常运行维护过程中,没有注意适应HA的标准化维护规范,导致高可用环境遭到了破坏,到真正故障出现时,高可用就高不可用了。
7、改进建议
(1)对于基于HACMP的高可用集群环境,避免使用extendvg命令加盘。
(2)建议基于HACMP的高可用集群环境下加盘采用AIX推荐的C-SPOC功能(HACMP Logical Volume Management)进行VG容量扩展。
1)即日起,凡是推送在【子衿技术】平台的文章,阅读量超过1000,该文章作者可获赠礼品。
2)投稿数量较多的作者可获赠礼品。
3)从关注的用户中每月抽取3名幸运关注用户,这3名幸运用户可获赠礼品。
技术干货文章随时欢迎向“子衿技术团队”订阅号投稿。
投稿邮箱:xx.miaojingwen@163.com。

欢迎扫码关注子衿技术
