




在前几次介绍中,周末君都是基于OpenGL2.0提供的功能给大家进行介绍,但是随着对渲染性能要求的逐渐提高,OpenGL也紧跟时代步伐,推出了3.0版本,而3.0里面很多都是对渲染性能的优化,今天就给大家介绍其中一种:Pixel Buffer Object (PBO)
PBO的主要优点是可以通过 DMA (Direct Memory Access) 快速地在显卡上传递像素数据,而不影响CPU的时钟周期(中断)。另一个优势是它还具备异步 DMA 传输。让我们对比使用 PBO 前后的纹理传送方法。
传统方式是从图像文件或视频中加载纹理。首先,资源被加载到系统内存(Client)中,然后使用 glTexImage2D() 函数从系统内存复制到 OpenGL 纹理对象中(Client->Server)。这两次数据传输(加载和复制)完全由 CPU 执行 PBO传输方式则是由OpenGL控制的。虽然CPU有参与加载纹理到PBO,但不涉及将像素数据从PBO传输到纹理对象的工作,而是由GPU(OpenGL驱动)来负责PBO到纹理对象的数据传输的,这也就意味着OpenGL执行DMA传输操作不会占用CPU的时钟周期。此外,OpenGL还可以安排稍后执行的异步DMA传输。所以glTexImage2D()可以立即返回,CPU也无需等待像素数据的传输了,可以继续其他工作 最后用两张图对比一下:
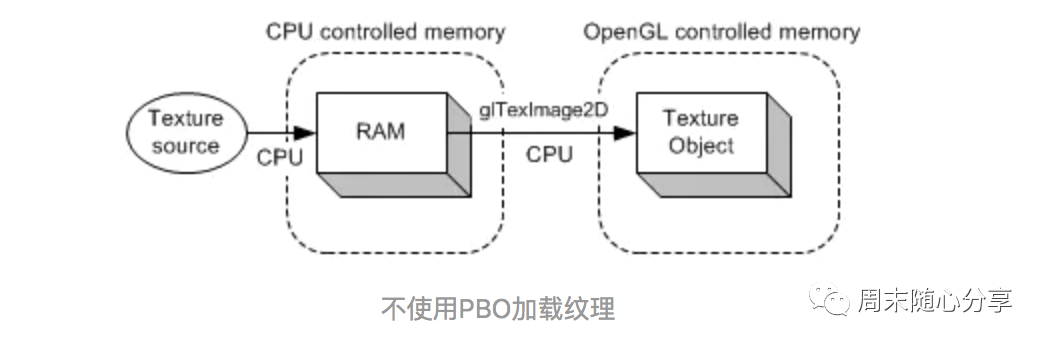
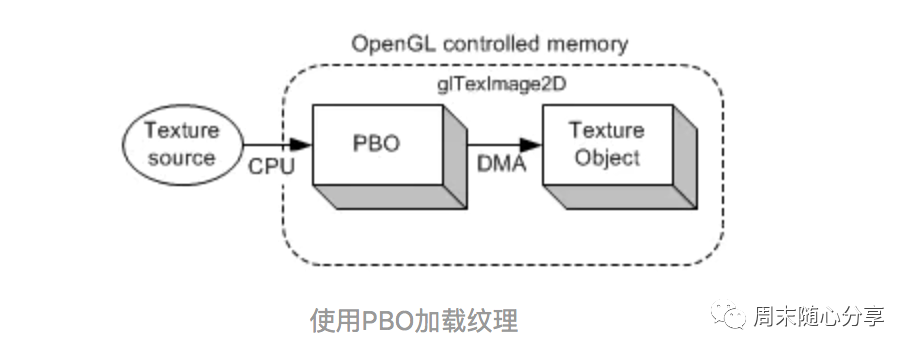
基于上面说的优点,PBO有一个典型的应用就是视频软解,由于它异步传输的特性,在视频软解时就可以在解出一帧数据后通知GPU来取数据,然后CPU马上去解下一帧数据,这样每帧耗时相对传统方式就能减少一半时间
说了这么多PBO优点,那怎么使用它呢?接下来就来实例演示一下PBO如何把一个视频进行离屏渲染并保存!
PBO是OpenGL3.0才引入的特性,因此android minSdkVersion如果小于18,那么你需要下载google提供的gl3stub.c文件,不然编译都通过不了,会一直报错找不到GLESv3,具体可以参考google提供的demo:
https://github.com/googlesamples/android-ndk/tree/master/gles3jni
下载好gl3stub.h和gl3stub.c后把它放到你的工程jni目录下,编译选项加入它们,然后在你的cpp或者c文件内引用它,比如:
#include <GLES2/gl2.h>#include "gl3stub.h"
这个头文件里面只包含了GLES3.0独有的api,所以你如果还用到了GLES2.0的api,你需要包含gl2.h,这样调用才不会报错 在包含gl3stub头文件后还不能使用3.0特性,如果你认真看gl3stub文件内容你会发现需要手动调用gl3stubInit()这个函数后才能真正开始调用
创建PBO
void initPBO(int width, int height) {glVersion = (const char *) glGetString(GL_VERSION);LOGI("opengl version:%s", glVersion);mPboIndex = 0;mPboNewIndex = 1;mInitRecord = true;//每个像素包含RGBA四个字节,所以乘于4mPboSize = width * height * 4;LOGI("picture width,height:%d,%d", width, height);glGenBuffers(2, mPboIds);if (mPboIds[0] == 0 || mPboIds[1] == 0) {LOGI("%s", "generate pbo fail");return;}//绑定到第一个PBOglBindBuffer(GL_PIXEL_PACK_BUFFER, mPboIds[0]);//设置内存大小glBufferData(GL_PIXEL_PACK_BUFFER, mPboSize, NULL, GL_STATIC_READ);//绑定到第而个PBOglBindBuffer(GL_PIXEL_PACK_BUFFER, mPboIds[1]);//设置内存大小glBufferData(GL_PIXEL_PACK_BUFFER, mPboSize, NULL, GL_STATIC_READ);//解除绑定PBOglBindBuffer(GL_PIXEL_PACK_BUFFER, 0);}
使用PBO进行视频离屏渲染并保存:
在软解过程中,第n帧,PBO1正被glTexSubImage2D()函数使用。而PBO2用于读取新的纹理。在第n+1帧时,2个PBO交换角色,并继续更新纹理。因为DMA传输的异步性,更新和复制可被同时执行。CPU将新纹理更新到一个PBO中,同时GPU从另一个PBO中复制纹理
1、视频解码并进行渲染
// "index" 用于从PBO中拷贝像素数据至texture object// "nextIndex" 用于更新另一个PBO中的像素数据index = (index + 1) % 2;nextIndex = (index + 1) % 2;// 绑定纹理glBindTexture(GL_TEXTURE_2D, textureId);// 绑定PBOglBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, pboIds[index]);// 从PBO中拷贝像素数据至texture objectglTexSubImage2D(GL_TEXTURE_2D, 0, 0, 0, WIDTH, HEIGHT,GL_BGRA, GL_UNSIGNED_BYTE, 0);// 绑定另一个PBO,用texture source对它进行更新glBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, pboIds[nextIndex]);// 注意:glMapBufferARB()会引起同步问题// 如果GPU正在使用这块buffer, glMapBufferARB()将会等待// 直到GPU完成操作. 为了避免等待,你可以先调用// glBufferDataARB() ,并传入NULL指针, 然后再调用glMapBufferARB()。// 如果按照上面的方法调用的话, PBO之前存储的数据将会被丢弃,并且// glMapBufferARB() 将会立即返回一个新分配的指针,// 即使GPU仍然在使用之前的数据glBufferDataARB(GL_PIXEL_UNPACK_BUFFER_ARB, DATA_SIZE, 0, GL_STREAM_DRAW_ARB);// 映射buffer object(PBO)到客户端内存GLubyte* ptr = (GLubyte*)glMapBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB,GL_WRITE_ONLY_ARB);if(ptr){// 直接更新映射的bufferupdatePixels(ptr, DATA_SIZE);glUnmapBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB);// release the mapped buffer}// 在使用完PBO以后,通过ID 0 来释放PBO// 一旦绑定到0,所有的像素操作都将被重置glBindBufferARB(GL_PIXEL_UNPACK_BUFFER_ARB, 0);
2、读取渲染后的视频帧数据并保存
// "index" 用于从FBO中读取像素到PBO// "nextIndex" 用于更新另一个PBO中的像素index = (index + 1) % 2;nextIndex = (index + 1) % 2;// 设置读取的目标framebufferglReadBuffer(GL_FRONT);// 从FBO中读取像素至PBO// glReadPixels()将会立刻返回glBindBufferARB(GL_PIXEL_PACK_BUFFER_ARB, pboIds[index]);glReadPixels(0, 0, WIDTH, HEIGHT, GL_BGRA, GL_UNSIGNED_BYTE, 0);// 映射PBO到客户端,并通过CPU处理其数据glBindBufferARB(GL_PIXEL_PACK_BUFFER_ARB, pboIds[nextIndex]);GLubyte* ptr = (GLubyte*)glMapBufferARB(GL_PIXEL_PACK_BUFFER_ARB,GL_READ_ONLY_ARB);if(ptr){processPixels(ptr, ...);glUnmapBufferARB(GL_PIXEL_PACK_BUFFER_ARB);}// 重置PBO的像素操作glBindBufferARB(GL_PIXEL_PACK_BUFFER_ARB, 0);
这边有几点说明一下:
1)首先是为什么使用2个PBO
一个pbo用于存放已经解码的数据,等待GPU来读取,另一个pbo用于准备下一帧数据,这样复制和更新就能同时进行
然后pbo个数为什么是2个而不是3个或4个呢,因为通常情况下CPU读取一帧的时间和GPU处理一帧的时间不会相差太大,所以两个pbo已经足够用了,当然如果CPU处理比较快的情况可以设置多个pbo用于提前存放解码数据
2)如果是YUV数据的话,glReadPixels大小就得改了,如下:
glReadPixels(0, 0, width, height * 3 / 8, GL_RGBA, GL_UNSIGNED_BYTE, 0);
3/8怎么来的呢,很简单,之前说过总大小是3/2,总大小 4(RGBA) 就是3/8了,至于为什么是height乘3/8的原因就是像素填充是从左到右,从上到下的,所以要从前往后读,宽度必须填满,高度就是决定实际读多少了。
3)glMapBufferRange的作用就是将OpenGL控制的pbo地址映射到CPU来,所以这个地址是可以直接使用的,不用再调用memcpy来拷贝一遍,不然反而失去了PBO的优势
4)glReadPixels传入的数组必须是malloc或者new创建的,不能是直接声明大小的,比如uint8_t data[size]这种是会出现fault addr错误, new 或者malloc才不会报错
5)这边再强调一下,pbo是针对连续多帧渲染保存这种情况比较有优势,所以一般用于视频的渲染保存,单个pbo或者只读取一两次就不需要使用pbo了,不会提升多大速度
总结
经过上面的初步介绍,小伙伴们应该对PBO有了大概的印象,总的来说PBO优点就是针对视频这种需要快速处理多帧数据情况,传统方式会同步等待,而PBO由于异步DMA特点可以节省将近一半时间,对于离屏渲染来说是极大的优化
好了,周末君关于OpenGL的介绍暂告一段落了,当然OpenGL3.0中还有像VAO、ETC2这种关于性能和内存的优化,后面有机会将会继续介绍,今天的分享就到这了^_^
