




2 日志拷贝
继上一章节,当集群中选出了leader,接下来关键的工作是将收到数据同步到Follower,即,leader接受到客户端的cmd请求,构造raft log (类似mysql binlog),并且log拷贝到Follower,得到集群中过半数节点存储成功确认后,给客户端返回成功。
首先看一下runLeader的处理逻辑
raft库中日志拷贝有两种方式: 1)对每个follower会单独开一个协程进行拷贝操作,并且是串行拷贝的,每条日志项都是严格按照index的顺序进行拷贝的,并且每次拷贝请求都要等待follower的ack,才会执行下一次拷贝。 2) 并行拷贝(pipeline),一个协程里面会并行进行拷贝操作,不等对端的follower返回,继续处理其他的拷贝请求
2.1 leader端主循环
func (r *Raft) runLeader() {
......
// Start a replication routine for each peer
r.startStopReplication() //leader节点根据当前的configuration,为集群中其他节点开启一个复制日志的goroutine
......
noop := &logFuture{
log: Log{
Type: LogNoop,
},
}
r.dispatchLogs([]*logFuture{noop}) //成为leader,raft安全性要求,必须马上复制一条noop的日志
// Sit in the leader loop until we step down
r.leaderLoop() //进入leader主循环,接受新来的日志等
}
关于noop日志类型:
Leader一旦当选,立即向其它节点同步一个心跳消息(no-op)。这是为了确保当前没有提交的日志也能尽快得到提交。Leader只会追加日志序列,刚当选时已经存在的日志序列,Leader会努力将它们同步到所有节点,如果Follower存在的日志和Leader有冲突,就会被抹平。最终Leader和Follower的日志就会完全一致。 在raft算法的论文中,&5.4.2章节有详细说明该日志的作用。
从上面分析可以看出,成为leader后,主要是有三个大步骤:首先是新建goroutine来接受复制日志的请求,然后通过函数dispatchLogs发送一条noop的日志,最后进入r.leaderLoop()主循环,接受其他goroutine的信号请求。
可以看到,日志拷贝中,函数dispatchLogs是关键性函数,下面看看该函数的实现。
func (r *Raft) dispatchLogs(applyLogs []*logFuture) {//分发日志,第一次会增加一条noop日志,index=2
term := r.getCurrentTerm() //当前的leader任期,第一次成为leader的时候,这里应该是2
lastIndex := r.getLastIndex() //最后index,初始化的时候应该为1
logs := make([]*Log, len(applyLogs))
for idx, applyLog := range applyLogs {
applyLog.dispatch = now
lastIndex++
applyLog.log.Index = lastIndex
applyLog.log.Term = term
logs[idx] = &applyLog.log
r.leaderState.inflight.PushBack(applyLog) //这里保存了将要apply的日志
}
if err := r.logs.StoreLogs(logs); err != nil { //leader本地写数据失败,那么马上通知调用方失败
for _, applyLog := range applyLogs {
{
//applylog里面有一个channel,外部调用者通过这个channel来获取反馈。respond就往该channel写入操作结果
applyLog.respond(err)
}
//写日志失败,leader直接变成follower,每次runLeader的时候,会自动把inflight清空,新建一个链表
r.setState(Follower)
return
}
/**
* 这里是计算集群中大多数节点已经写到磁盘的日志的最大index,称作quorumMatchIndex;
* 如果quorumMatchIndex > commitIndex(已知的最大的已经被提交的日志条目的索引值);
* 会通过commitCh发起一个apply请求,触发更新本地的fsm
*/
r.leaderState.commitment.match(r.localID, lastIndex)
// Update the last log since it's on disk now
r.setLastLog(lastIndex, term) //保存本地最后一条日志的index和term
// Notify the replicators of the new log
for _, f := range r.leaderState.replState { //通知所有节点,已经写入了新的日志,需要拷贝日志
//这里会通知到r.startStopReplication()里面创建的goroutine
//goroutine中,通过s.triggerCh来接受日志拷贝请求,然后给对端发起AppendEntriesRequest的rpc请求
asyncNotifyCh(f.triggerCh)
}
}
2.2 leader接受客户端的日志请求
前面介绍的是,candidate 转换为-> leader的时候,在leader主循环中同步一条noop日志和往期日志的逻辑。在raft集群正常运行的情况,大多数还是leader收到客户端的日志请求,然后分发处理的场景。该处理逻辑放到前面提高的leader主循环函数leaderloop里,对应的raft库中,对于调用提供了提交日志的api函数func (r *Raft) Apply(cmd []byte, timeout time.Duration) ApplyFuture,调用者可以使用这个函数apply一条日志。 Apply函数:
func (r *Raft) Apply(cmd []byte, timeout time.Duration) ApplyFuture { //写入一个命令到日志里
......
logFuture := &logFuture{
log: Log{
Type: LogCommand,
Data: cmd,
},
}
logFuture.init()
select {
......
case r.applyCh <- logFuture: //这里可以看到,是把日志信息写到channel里面
return logFuture //返回一个future结构体,调用者可以根据结构体的里的channel,阻塞等待日志apply的结果
}
}
leader处理的主循环的leaderLoop:
func (r *Raft) leaderLoop() { //主循环
for r.getState() == Leader {
select {
case newLog := <-r.applyCh://主循环从channel中拿到日志请求 收到apply日志请求,applyCh是一个无缓冲的channel。必须处理完了这个请求,才能收到下一个applyCh的内容
// Group commit, gather all the ready commits
ready := []*logFuture{newLog}
for i := 0; i < r.conf.MaxAppendEntries; i++ { //如果是批量apply,则把另外的entry也拿到
select {
case newLog := <-r.applyCh:
ready = append(ready, newLog)
......
}
}
......
r.dispatchLogs(ready) //分发日志,把日志拷贝到其他节点,并且触发一次match操作,查看是否需要触发fsm的更新
}
}
}
......
2.3 follower和candidate的处理
leader发送了AppendEntriesRequest的rpc请求,其他的节点肯定会收到leader发过来的增加日志请求,并进行逻辑处理和回包。前面有提到,所有的raft节点都会有函数r.processRPC(rpc)处理收到其他节点的rpc请求。因此处理AppendEntriesRequest也是在该函数进行分发处理的。
r.processRPC(rpc) -> case *AppendEntriesRequest: -> r.appendEntries(rpc, cmd)
函数appendEntries:
func (r *Raft) appendEntries(rpc RPC, a *AppendEntriesRequest) {
resp := &AppendEntriesResponse{ //日志拷贝的回包
RPCHeader: r.getRPCHeader(),
Term: r.getCurrentTerm(),
LastLog: r.getLastIndex(), //当前Follower拥有的logIndex
Success: false,
NoRetryBackoff: false,
}
var rpcErr error
defer func() {
rpc.Respond(resp, rpcErr) //退出的时候,给其他节点发送一个回包,当前log已经append成功与否
}()
/**
* 如果同步请求的任期号比Follower的任期号还小,那就直接拒绝,并带上自己的任期号,以便Leader进行跟上时代(更新自己的任期号)。
*/
if a.Term < r.getCurrentTerm() {
return
}
//如果leader的term比自己的大或者candidate收到一个appendEntry请求,立即变成Follower并刷新本地的term
if a.Term > r.getCurrentTerm() || r.getState() != Follower {
r.setState(Follower)
r.setCurrentTerm(a.Term)
resp.Term = a.Term
}
// Save the current leader
r.setLeader(ServerAddress(r.trans.DecodePeer(a.Leader)))
/**
* 检查prevLogIndex与prevLogTerm是否在当前的follower中
* prevLogIndex: 新的日志条目紧随之前的索引值
* prevLogTerm: revLogIndex 条目的任期号
* 如果在Follower中找不到对应的prevlogIndex,那么会返回日志拷贝失败。
* leader端收到后,根据resp回包带的lastindex,算出应该给Follower拷贝的日志索引从哪个index开始
*/
if a.PrevLogEntry > 0 {
lastIdx, lastTerm := r.getLastEntry()
var prevLogTerm uint64
if a.PrevLogEntry == lastIdx {
prevLogTerm = lastTerm
} else {
var prevLog Log
if err := r.logs.GetLog(a.PrevLogEntry, &prevLog); err != nil {
......
return
}
prevLogTerm = prevLog.Term
}
if a.PrevLogTerm != prevLogTerm {
......
return
}
}
.......
/**
* 上面对比完日志项,找到Follower与leader匹配的日之后,follower还要有以下的操作步骤
* _1) 检查leader的日志与follower的日志的冲突部分,把Follower冲突部分删除掉,日志项以leader为准。
* 具体的方式,把Follower_lastIndex到leader_newLogEntryFisrtIndex(leader新日志的第一个index)这两个范围的index的日志从Follower中删除掉
* _2) 通过r.logs.StoreLogs(newEntries)更新本地日志
* _3) r.processLogs(idx, nil)检查当前leader的commitIndex是否已经更新,如果是,则更新Follower的fsm
*/
//上面的动作完成之后,给leader回包
resp.Success = true //
r.setLastContact() //更新与leader最后一次通信的时间
return
}
2.4 leader收到Follower回包,更新fsm
日志条目在leader先写入磁盘,然后通过发送AppendEntriesRequest更新到集群中的Follower节点中,然后在leaderloop监听commitCh查看日志项是否已经提交成功。那日志从leader拷贝到接受Follower回包,是如何发起一个commitCh的操作的呢?下面分析一下leader收到Follower回包的过程。
leader发起拷贝是由主协程发起的,由主循环监听applyCh触发一个增加日志的动作,然后再次触发拷贝的动作。而日志拷贝对于每个Follower而言,leader端是并发进行的,不是由主协程直接与Follower进行通信。而是asyncNotifyCh(f.triggerCh)通知拷贝日志的协程开始拷贝日志的动作。leader会为每个Follower都建立一个goroutine拷贝日志,主要的处理函数是func (r *Raft) replicateTo(s *followerReplication, lastIndex uint64) (shouldStop bool)
//replicateTo函数中,收到Follower的回包,如果是Follower拷贝成功,调用updateLastAppended更新Follower已经拷贝的日志项
if resp.Success {
// Update our replication state
updateLastAppended(s, &req)
// Clear any failures, allow pipelining
s.failures = 0
s.allowPipeline = true
}
func updateLastAppended(s *followerReplication, req *AppendEntriesRequest) {
// Mark any inflight logs as committed
if logs := req.Entries; len(logs) > 0 {
last := logs[len(logs)-1]
s.nextIndex = last.Index + 1
//match函数前面提到,会计算每个节点已经拷贝的日志项
//然后计算大多数达到的最大index,通过recalculate发起一个commitCh操作,触发leader的fsm更新
s.commitment.match(s.peer.ID, last.Index)
}
......
}
leader节点在主协程中,监听到commitCh,会做一下动作
//收到一个commit完成的请求,准备应用日志,更新到状态机,产生函数func (c *commitment) recalculate()
case <-r.leaderState.commitCh:
commitIndex := r.leaderState.commitment.getCommitIndex() //已知的最大的已经被提交的日志条目的索引值
r.setCommitIndex(commitIndex)
......
for {
//inflight可以认为这个链表保存了写到磁盘但是没有应用到fsm的log
//
e := r.leaderState.inflight.Front() //这是一个链表,包含了log命令。把log加入链表的函数dispatchLogs
commitLog := e.Value.(*logFuture)
idx := commitLog.log.Index
if idx > commitIndex {
break
}
// Measure the commit time
metrics.MeasureSince([]string{"raft", "commitTime"}, commitLog.dispatch)
r.processLogs(idx, commitLog) //准备更新本地状态机 //这里会通过commitLog反馈给调用者
r.leaderState.inflight.Remove(e) //应用这条log到状态机了,就把log从链表中删除
}
......
至此,一个日志下发,拷贝至Follower,leader统计response,commit状态发起,应用到fsm,全部过程已经完成。下面用以一个简单的流程图描述一下。
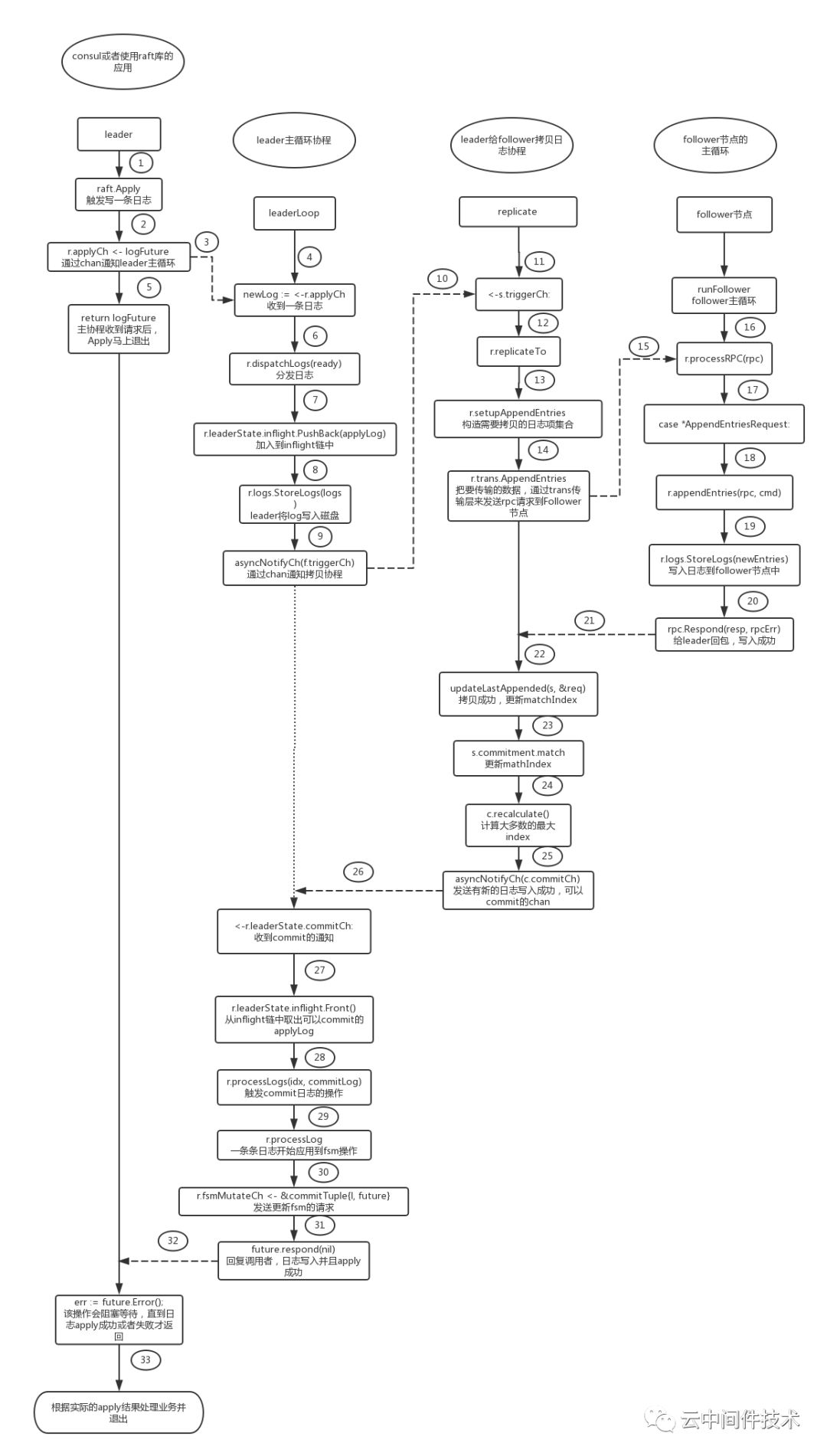
2.5 leader定期心跳包
raft中规定,leader需要定期向follower发送心跳包,保证自己的任期的权威性。raft库中心跳包和日志拷贝发送包的是一样的,都是AppendEntriesRequest。区别是: 1) 心跳包不包含任何日志项Entries,日志条数为0 2) follower中有一个专门处理心跳包heartbeat的函数,当收到心跳包的时候,会直接进行快速回复。follower中心跳包处理的协程和日志复制拷贝的协程不是同一个。(目的:当follower阻塞在日志拷贝的IO中时,follower依然可以收到并且处理leader的心跳包) 3) 心跳包中不包含LeaderCommitIndex(leader已经提交的日志index),这里可以优化一下,心跳包也发送CommitIndex,加快apply日志到follower中
2.6 总结
本文重点介绍了consul raft 算法的日志复制流程及核心点,下次将介绍集群中节点的加入移除原理。
