




我感到很遗憾的一件事,咱们长期以来IT运维对weblogic中间件运维停留在人工模式,却没有一套完善weblogic自动化监控告警平台,无法实时把握weblogic平台的运行健康情况,同时也无法提前做到故障告警提醒。一旦系统出缓慢现象,还是需要人工去检查,找出盲点来做优化。但是一旦系统出现瘫痪状态,没有告警通知,运维人员也有可能茫然不知。对于故障问题分析工程师需要人工登录服务器去收集相关配置和日志信息,即使是很熟练的工程师,估计也得消耗半小时或者更长时间才能有个初步的诊断,而对于那些不熟悉环境的工程师,估计消耗时间更加长。对客户来说,这样的处理效率无疑是一场灾难。这样势必会让客户觉得我们的工作不专业,也会给IT维护组带来大量投诉。因此为了有效果的保障业务系统在weblogic平台运行良好,提升客户的满意度,需要对业务系统建立起weblogic中间件性能自动监控和告警,以保障业务系统正常动作,这也是现有 业务发展的迫切需要 。
对于现有运维技术缺乏提前预防措施和问题精确定位分析,主要存在如下几个方面问题:
当业务已经受到影响,用户报障过来,第一时间无法判断是中间件、服务器主机、网络和数据库等性能导致业务缓慢原因,还需要花费大量人力物力来收集信息和定位分析问题。
IT 运维人员对中间件服务巡检还是要依靠人工检查,工作效率相当低,时效性不高和准确性难以保证,且不利于后期巡检记录数据分析。
当业务出现缓慢时,同时中间件当时是否可能存在异常,不得而知,需要人工去web界面检查,由于系统多的情况,检查相当耗时间,无法及时发现中间件是哪个指标存在问题。对于故障定位大打折扣,同时也无法让IT运维人员时刻把握中间件的健康运行状态,问题处理效果非常低。
当中间件服务出现异常时没有一套中间件性能指标告警,IT维护人员无法第一时间接收到问题报障,却是由用户发起报障过来才知晓,导致故障处理延时。
针对上面介绍的痛点问题制定一套机制有效地weblogic中间件性能自动监控告警和分析方法,通过日常对中间件的运行情况信息采集,然后对监控指标做告警,一旦weblogic中间件性能指标有异动触碰到设定的告警阀值,就会产生告警,并将告警推送短信接口平台,以短信方式下发给相关部门人员。同时通过告警级别做出相应简单分析。不需要完全依赖于人工处理,直接发现中间件性能问题。解脱了运维人员人工巡检和问题排查的工作,也让应用能够更加高效地平稳地运行,减少故障的发生。对weblogic中间件性能进行提前预警,在处理紧急事件时,有实时监控数据做辅助分析,性能问题和故障问题分析快速定位。大大提升业务系统的性能稳定性,提升问题处理效率。
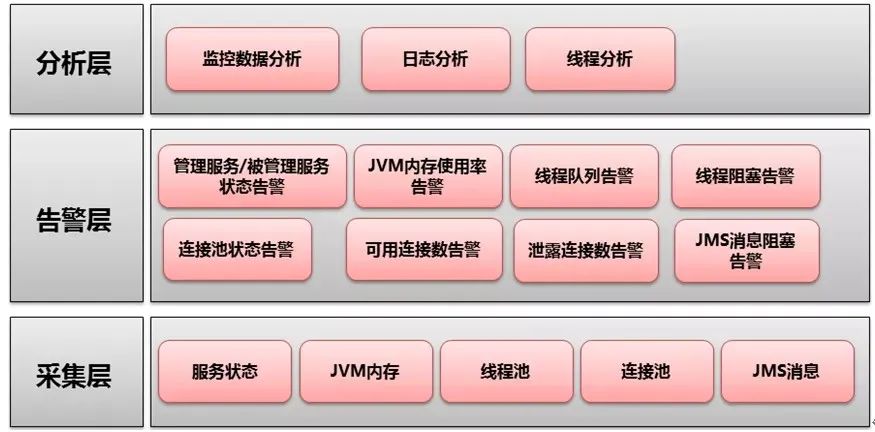
针对此架构分来三个模块从下至上分别是采集层、告警层和分析层。
此模块负责对业务系统所使用的weblogic 的中间件性能指标数据进行实时采集,针对大型业务系统,业务本身访问比较繁忙,频繁采集所有业务模块性能数据,势必干扰业务正常使用。weblogic 指标数据采集工作,可以通过weblogic 自带的wlst 工具与JMX Client 和weblogicMBean 来通信, 获取WLS 实时动态运行的指标数据,此采集方法对weblogic 服务性能无任何影响。weblogic 采集监控只需要在业务系统的其中一台 weblogic 服务器上面部署,并配置 cron 定时任务,每隔 3 分钟自动调度采集监控脚本。并将采集的数据以文本方式存储。采集监控是通过主程序 shell 脚本调用 wlst 工具,通过 WLST 执行 python 采集脚本,最终会采集到两份数据,一份用于历史数据监控分析,用于故障后了解决故障前的性能情况。另一份数据用于告警分析,并将这份数据推送给告警模块来处理。
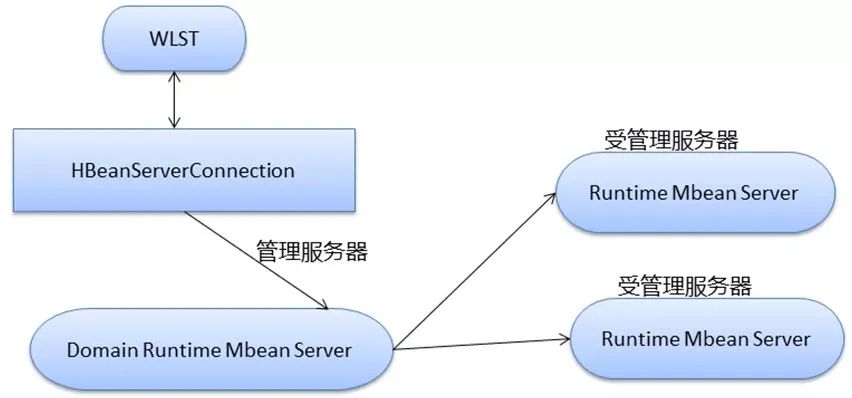
1) WebLogicMBean 主要具有以下三种类型的MBeans
a) Adminserver MBeans, 封装从config.xml 读取的整个weblgoicdomain 的配置信息。
b)Configuration MBeans, 每个weblogic 被管服务器一份,是AdminserverMBeans 的copy, 用于server 配置自己。
c) Runtime MBeans, 代表着运行时刻WebLogic Server 的各种组件和子系统。
2) Weblogic 自动监控脚本会连接weblogic MBeans 来捕获的以下数据:
a) 实时采集WLS 管理/ 被管理服务器服务状态信息;
b) 实时采集WLS JVM 堆内存使用信息;
c) 实时采集WLS 线程池相关指标信息;
d) 实时采集WLS 连接池相关指标信息;
e) 实时采集WLS JMS 消息列队信息。
此模块负责指标异常告警和短信下发。通过上层采集模块推送过来的指标采集的数据,根据该模块对应指标定义的指标阀值来做判断,超过预定的告警阀值,将告警信息推送给短信接口平台,然后短信平台根据告警级别下发下发手机短信给相关部门。
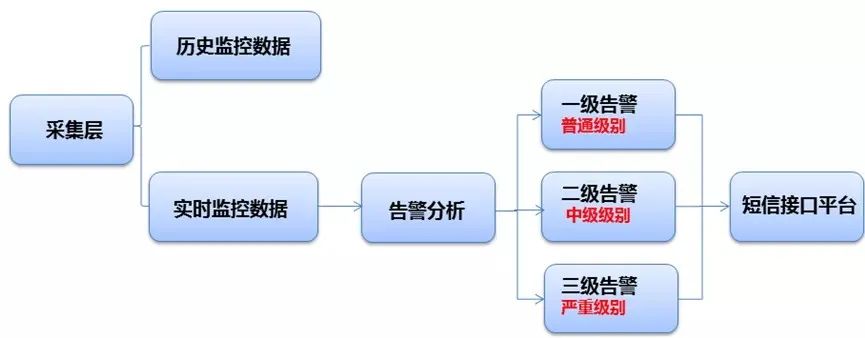
1) weblogic 告警指标预定义阀值:
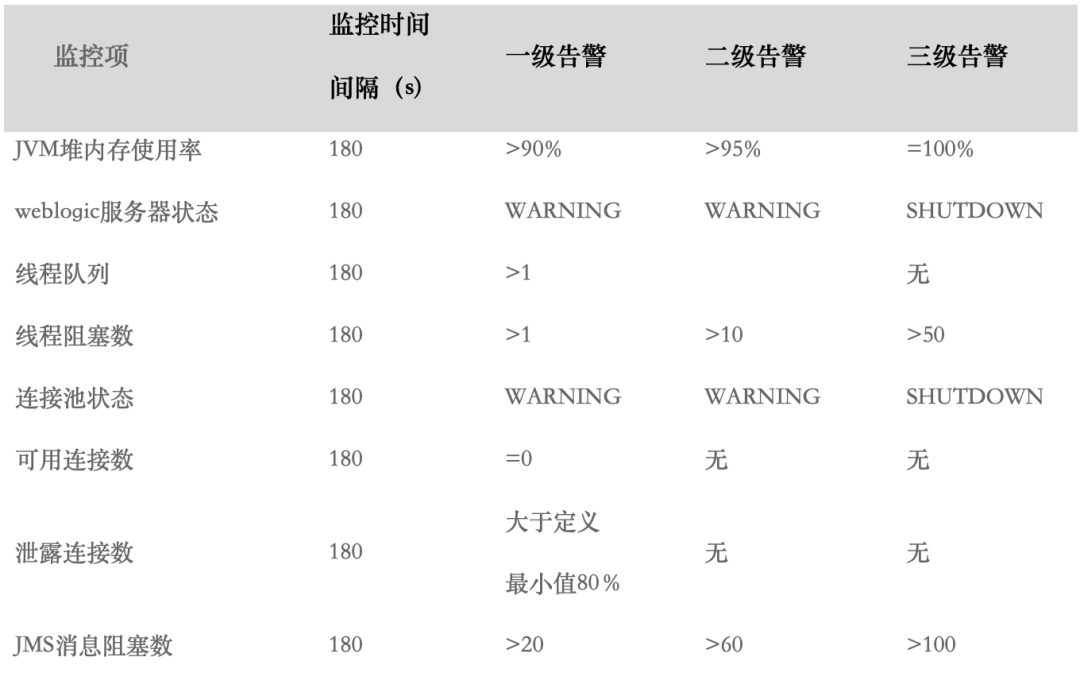
c) 三级告警(严重级别):weblogic 中间件服务严重异常,服务性能下降,资源耗尽,基本中间件服务处于瘫痪状态,业务无法正常提供服务。超过了指定的三级告警指标阀值,短信接口会自动下发告警信息给业务部门、开发部门和运维部门人员重点关注。
1) 监控数据分析
1、当系统产生故障时IT运维工程师可以借助这份历史监控数据来做辅助定位分析。这份监控数据也能让工程师了解故障前后weblogic中间件各指标的性能情况,降低工程师分析问题的难度,最终可以通过数据做出相应判断。
2) 日志分析
3) 线程分析
1、当weblogic出现线程阻塞、JVM内存耗尽和内存泄露等类似告警,会自动通过weblogic.Admin命令生成thread dump,GC和内存dump文件。
2、借助 IBM HA ,JCA,GA,mat等性能分析工具,用于分析线程和内存使用,GC资源回收等情况。

本期作者|jaymarco 中间件高级专家,现就职于国内某服务公司,主要负责数据库、中间件、大数据等基础软件建设、优化和业务保障工作。具有10年的电信与银行企业一线/二线运维服务管理经验。目前专注于云计算、中间件、开源技术和数据库等领域技术研究。持有Oracle OCP、weblogic OCP、Docker容器、Postgresql PGCE和阿里云ACP等认证。
