





在Oracle中,什么是聚簇因子(Clustering Factor)?
Oracle数据库中最普通、最为常用的即为堆表,堆表的数据存储方式为无序存储,当对数据进行检索的时候,非常消耗资源,这个时候就可以为表创建索引了。在索引中,数据是按照一定的顺序排列起来的。当新建或重建索引时,索引列上的顺序是有序的,而表上的顺序是无序的,这样就存在了差异,即表现为聚簇因子(Clustering Factor,简称CF),也称为群集因子或集群因子等,本书统一称为聚簇因子。聚簇因子值的大小对CBO判断是否选择相关的索引起着至关重要的作用。
在Oracle数据库中,聚簇因子是指按照索引键值排序的索引行和存储于对应表中数据行的存储顺序的相似程度,也就是说,表中数据的存储顺序和某些索引字段顺序的符合程度。CF是基于表上索引列上的一个值,每一个索引都有一个CF值。
Oracle按照索引块所存储的ROWID来标识相邻索引记录在表块中是否为相同块。Oracle通过如下方法计算CF:检查索引块上每一个ROWID的值,查看是否前一个ROWID的值与后一个ROWID指向了相同的数据块,如果指向了不相同的数据块那么CF的值增加1。当索引块上的每一个ROWID被检查完毕,即得到最终的CF值。举个例子,比如说索引中有a、b、c、d、e五个记录,首先比较a和b是否在同一个块,如果不在同一个块,那么CF+1,然后继续比较b和c。同理,如果b和c不在同一个块,那么CF+1,这样一直进行下去,直到比较了所有的记录才结束,最终得到CF的值。注意,这里Oracle在比对ROWID的时候并不需要回表去访问相应的表块。
具体来说,计算CF的算法如下所示:
(1)聚簇因子的初始值为1。
(2)Oracle首先定位到目标索引处于最左边的叶子块。
(3)从最左边的叶子块的第一个索引键值所在的索引行开始顺序扫描,在顺序扫描的过程中,Oracle会比对当前索引行的ROWID和它之前的那个索引行(它们是相邻的关系)的ROWID,如果这两个ROWID并不是指向同一个表块,那么Oracle就将聚簇因子的当前值递增1;如果这两个ROWID是指向同一个表块,那么Oracle就不改变聚簇因子的当前值。注意,这里Oracle在比对ROWID的时候并不需要回表去访问相应的表块。
(4)上述比对ROWID的过程会一直持续下去,直到顺序扫描完目标索引所有叶子块里的所有索引行。
(5)上述顺序扫描操作完成后,聚簇因子的当前值就是索引统计信息中的CLUSTERING_FACTOR,Oracle会将其存储在数据字典里。
好的CF值接近于表上的块数,而差的CF值则接近于表上的行数。CF值越小,相似度越高,CF值越大,相似度越低。如果CF的值接近块数,那么说明表的存储和索引存储排序接近,也就是说表中的记录很有序,这样在做INDEX RANGE SCAN的时候,读取少量的数据块就能得到想要的数据,代价比较小。如果CF值接近表记录数,那么说明表的存储和索引排序差异很大,在做INDEX RANGE SCAN的时候,由于表记录分散,所以会额外读取多个块,代价较高。
由于聚簇因子高的索引走索引范围扫描时比相同条件下聚簇因子低的索引要耗费更多的物理I/O,所以聚簇因子高的索引走索引范围扫描的成本会比相同条件下聚簇因子低的索引走索引范围扫描的成本高。Oracle选择索引范围扫描的成本可以近似看作是和聚簇因子成正比,因此,聚簇因子值的大小实际上对CBO判断是否走相关的索引起着至关重要的作用。其实,聚簇因子决定着索引回表读的开销。在Oracle数据库中,能够降低目标索引的聚簇因子的唯一方法就是对表中数据按照目标索引的索引键值排序后重新存储。需要注意的是,这种方法可能会同时增加该表上存在的其它索引的聚簇因子的值。
可以通过如下的命令显式的设置聚簇因子的值:
1EXEC DBMS_STATS.SET_INDEX_STATS(OWNNAME=>'LHR',INDNAME=>'IND2',CLSTFCT=>400000000,NO_INVALIDATE=>FALSE);
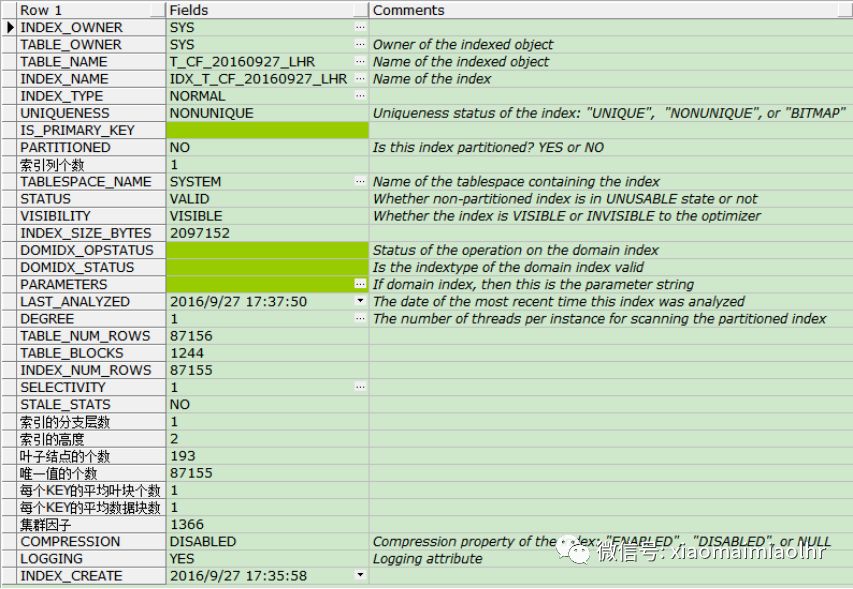
CF值可以通过查询视图DBA_INDEXES中的CLUSTERING_FACTOR列来获取。下边的SQL是查询索引的相关信息,通过视图DBA_INDEXES、DBA_OBJECTS和DBA_TABLES关联得到,可以查询当前索引的大小、行数、创建日期、索引高度和聚簇因子等信息。
1SELECT DI.OWNER INDEX_OWNER,
2 DI.TABLE_OWNER,
3 DI.TABLE_NAME,
4 DI.INDEX_NAME,
5 DI.INDEX_TYPE,
6 DI.UNIQUENESS,
7 (SELECT DECODE(NB.CONSTRAINT_TYPE, 'P', 'YES')
8 FROM DBA_CONSTRAINTS NB
9 WHERE NB.CONSTRAINT_NAME = DI.INDEX_NAME
10 AND NB.OWNER = DI.OWNER
11 AND NB.CONSTRAINT_TYPE = 'P') IS_PRIMARY_KEY,
12 DI.PARTITIONED,
13 (SELECT COUNT(1)
14 FROM DBA_IND_COLUMNS DIC
15 WHERE DIC.INDEX_NAME = DI.INDEX_NAME
16 AND DIC.TABLE_NAME = DI.TABLE_NAME
17 AND DIC.INDEX_OWNER = DI.OWNER) 索引列个数,
18 DI.TABLESPACE_NAME,
19 DI.STATUS,
20 DI.VISIBILITY,
21 (SELECT (SUM(BYTES))
22 FROM DBA_SEGMENTS ND
23 WHERE SEGMENT_NAME = DI.INDEX_NAME AND ND.OWNER = DI.OWNER
24 GROUP BY SEGMENT_NAME) INDEX_SIZE_BYTES,
25 DI.DOMIDX_OPSTATUS,
26 DI.DOMIDX_STATUS,
27 DI.PARAMETERS,
28 DI.LAST_ANALYZED,
29 DI.DEGREE,
30 DT.NUM_ROWS TABLE_NUM_ROWS,
31 DT.BLOCKS TABLE_BLOCKS,
32 DI.NUM_ROWS INDEX_NUM_ROWS,
33 DECODE(DI.NUM_ROWS, 0, '', ROUND(DI.DISTINCT_KEYS / DI.NUM_ROWS, 2)) SELECTIVITY,
34 DIS.STALE_STATS,
35 DI.BLEVEL 索引的分支层数,
36 DI.BLEVEL + 1 索引的高度,
37 DI.LEAF_BLOCKS 叶子结点的个数,
38 DI.DISTINCT_KEYS 唯一值的个数,
39 DI.AVG_LEAF_BLOCKS_PER_KEY 每个KEY的平均叶块个数,
40 DI.AVG_DATA_BLOCKS_PER_KEY 每个KEY的平均数据块数,
41 DI.CLUSTERING_FACTOR 集群因子,
42 DI.COMPRESSION,
43 DI.LOGGING,
44 (SELECT D.CREATED
45 FROM DBA_OBJECTS D
46 WHERE D.OBJECT_NAME = DI.INDEX_NAME
47 AND D.OBJECT_TYPE = 'INDEX'
48 AND D.OWNER = DI.OWNER) INDEX_CREATE
49 FROM DBA_INDEXES DI
50 LEFT OUTER JOIN DBA_IND_STATISTICS DIS
51 ON (DI.OWNER = DIS.OWNER AND DI.INDEX_NAME = DIS.INDEX_NAME AND
52 DI.TABLE_NAME = DIS.TABLE_NAME AND DI.TABLE_OWNER = DIS.TABLE_OWNER AND
53 DIS.OBJECT_TYPE = 'INDEX')
54 LEFT OUTER JOIN DBA_TABLES DT
55 ON (DI.TABLE_NAME = DT.TABLE_NAME AND DI.TABLE_OWNER = DT.OWNER)
56 WHERE DI.INDEX_NAME = 'IDX_T_CF_20160927_LHR';
使用PLSQL Developer工具运行查看可以得到如下的结果:
针对聚簇因子的内容,可以做一个实验来深入理解它的作用。建立实验环境如下所示:
1CREATE TABLE T_CF_161021_LHR_01 AS SELECT TRUNC(ROWNUM/100) ID ,OBJECT_NAME FROM DBA_OBJECTS WHERE ROWNUM<1000;
2CREATE TABLE T_CF_161021_LHR_02 AS SELECT MOD(ROWNUM,100) ID ,OBJECT_NAME FROM DBA_OBJECTS WHERE ROWNUM<1000;
3CREATE INDEX INX_T1_LHR ON T_CF_161021_LHR_01(ID);
4CREATE INDEX INX_T2_LHR ON T_CF_161021_LHR_02(ID);
5EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'T_CF_161021_LHR_01',CASCADE => TRUE);
6EXEC DBMS_STATS.GATHER_TABLE_STATS(USER,'T_CF_161021_LHR_02',CASCADE => TRUE);
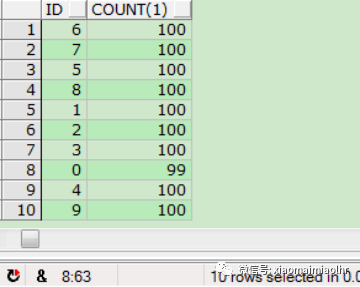
表T_CF_161021_LHR_01的数据量分布,每个ID对应大约100行记录:
1SELECT T.ID,COUNT(1) FROM T_CF_161021_LHR_01 T GROUP BY T.ID;
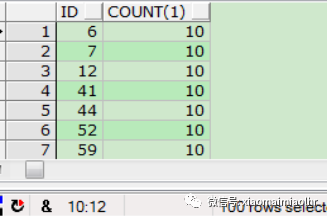
表T_CF_161021_LHR_02的数据量分布,每个ID对应大约10行记录:
1SELECT T.ID,COUNT(1) FROM T_CF_161021_LHR_02 T GROUP BY T.ID;
当这两个表的ID为2时,查看其执行计划:
1SYS@lhrdb> SET AUTOT TRACE EXP
2SYS@lhrdb> SELECT * FROM T_CF_161021_LHR_01 A WHERE A.ID=2;
3100 rows selected.
4Execution Plan
5----------------------------------------------------------
6Plan hash value: 894988015
7--------------------------------------------------------------------------------------------------
8| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
9--------------------------------------------------------------------------------------------------
10| 0 | SELECT STATEMENT | | 100 | 2000 | 2 (0)| 00:00:01 |
11| 1 | TABLE ACCESS BY INDEX ROWID| T_CF_161021_LHR_01 | 100 | 2000 | 2 (0)| 00:00:01 |
12|* 2 | INDEX RANGE SCAN | INX_T1_LHR | 100 | | 1 (0)| 00:00:01 |
13--------------------------------------------------------------------------------------------------
14Predicate Information (identified by operation id):
15---------------------------------------------------
16 2 - access("A"."ID"=2)
17
18SYS@lhrdb> SELECT * FROM T_CF_161021_LHR_02 A WHERE A.ID=2;
1910 rows selected.
20Execution Plan
21----------------------------------------------------------
22Plan hash value: 775989556
23----------------------------------------------------------------------------------------
24| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
25----------------------------------------------------------------------------------------
26| 0 | SELECT STATEMENT | | 10 | 200 | 3 (0)| 00:00:01 |
27|* 1 | TABLE ACCESS FULL| T_CF_161021_LHR_02 | 10 | 200 | 3 (0)| 00:00:01 |
28----------------------------------------------------------------------------------------
29Predicate Information (identified by operation id):
30---------------------------------------------------
31 1 - filter("A"."ID"=2)
可以看到,针对表T_CF_161021_LHR_01,执行计划选择了索引扫描,而针对表T_CF_161021_LHR_02,执行计划选择了全表扫描。由于这两个表中都有999行记录,而表T_CF_161021_LHR_01返回100行记录,表T_CF_161021_LHR_02返回10行记录,执行计划应该都选择索引才对,但表T_CF_161021_LHR_02却选择了全表扫描。现在来看一下这两个表的聚簇因子情况,如下所示:
1SYS@lhrdb> SELECT A.INDEX_NAME,
2 2 B.NUM_ROWS,
3 3 B.BLOCKS,
4 4 A.CLUSTERING_FACTOR
5 5 FROM USER_INDEXES A,
6 6 USER_TABLES B
7 7 WHERE A.INDEX_NAME IN ('INX_T1_LHR','INX_T2_LHR')
8 8 AND A.TABLE_NAME = B.TABLE_NAME;
9INDEX_NAME NUM_ROWS BLOCKS CLUSTERING_FACTOR
10------------------------------ ---------- ---------- -----------------
11INX_T1_LHR 999 4 4
12INX_T2_LHR 999 4 400
可以看到T_CF_161021_LHR_01的CF值和表的块数相同,说明表的存储和索引存储排序接近,数据分布比较集中,所以,执行计划选择了索引扫描。表T_CF_161021_LHR_02的CF值是表行数的一半,CF值较大,说明表数据分布比较分散,可能需要读取更多的块,所以,Oracle选择了全表扫描。
由此看出,聚簇因子和Oracle的执行计划是息息相关的。
& 说明:
有关CF的更多知识和实验可以参考:http://blog.itpub.net/26736162/viewspace-2139229/
本文选自《Oracle程序员面试笔试宝典》,作者:李华荣。

---------------优质麦课------------

详细内容可以添加麦老师微信或QQ私聊。
● 本文作者:小麦苗,只专注于数据库的技术,更注重技术的运用
● 作者博客地址:http://blog.itpub.net/26736162/abstract/1/
● 本系列题目来源于作者的学习笔记,部分整理自网络,若有侵权或不当之处还请谅解
● 版权所有,欢迎分享本文,转载请保留出处
● QQ:646634621 QQ群:618766405
● 提供OCP、OCM和高可用部分最实用的技能培训
● 题目解答若有不当之处,还望各位朋友批评指正,共同进步
长按下图识别二维码或微信扫描下图二维码来关注小麦苗的微信公众号:xiaomaimiaolhr,学习最实用的数据库技术。



