




最近大家可能在各种开源技术大会上看到了一个比较热门的开源项目叫 MLSQL。作为一门语言,MLSQL 可以帮助大家解决在 AI 和大数据领域的许多问题,也已经收获了一些使用超过 3 年的用户。不过还有一些对 MLSQL 不太熟悉的小伙伴们可能还有点疑惑,MLSQL 到底是做什么的?能解决什么问题呢?
最近小编特地对 Kyligence 技术合伙人、MLSQL 作者祝海林同学进行了采访,通过十问十答,一起来看看 MLSQL 究竟是做什么的吧~
想深入了解 MLSQL 的小伙伴快点击「阅读原文」免费报名10月30日的 Kylin X MLSQL Meetup 吧!和多位技术大佬在上海面对面交流~
Q0: MLSQL 要帮用户解决的核心问题是什么?
MLSQL 可以给用户提供:
稳定可靠的数据工程能力
强大的基于 Notebook 交互能力
简单但又足够灵活的机器学习能力
从桌面到纯云端的全方位覆盖
同时这些所有的数据连接,应用分析和AI能力都可以选择在 MLSQL 引擎上,使用 MLSQL 语言实现。
MLSQL 语言面向大数据和 AI 设计,天生分布式,帮助企业以更低成本的落地 Data + AI, 让数据真正实现平民化,人人都可以用上和用好数据。
Q1: MLSQL的技术方向和核心能力是什么?
MLSQL 技术方向其实很清晰,就是通过一个语言来帮助用户获取 Data + AI 工作所需要的所有能力。
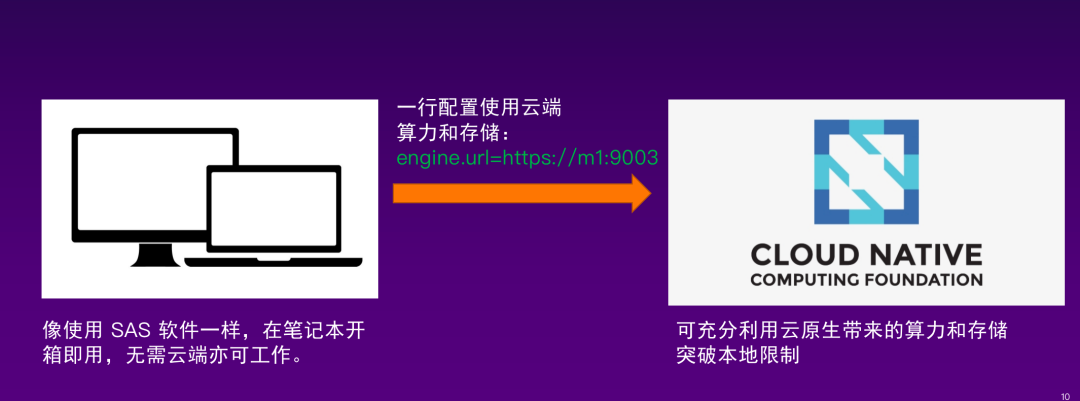
MLSQL 语言目前已经实现从桌面到云端的覆盖,用户可像使用 SAS 软件一样在自己的笔记本上无需依赖服务器端就可以开始做数据分析工作。同时,语言引擎是云原生的,用户可以通过修改一行配置就实现算力和存储的云端扩展。
Q2:大数据/AI 这套东西找个高级工程师花2个月用开源一搭不就完了?
数据和 AI 的使用成本高,收益难以抵消成本
就算不考虑成本,也很难找到足够符合要求的人
在这套体系下,对数据使用者要求很高,如图所示,数据科学家要学习大量的系统和语言,并且要工程师们配合,才能去落地一个算法或者一个数据处理过程。
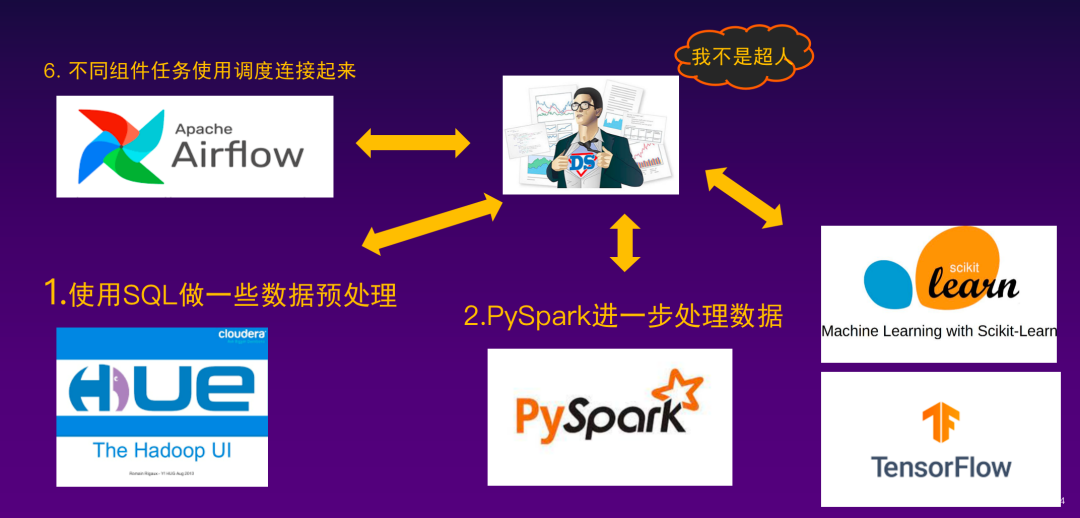
而实际上,不仅仅是使用者感受到痛苦,对这套体系的维护者也提出了很大的挑战:

企业也很难受,往往会发现落地一个算法到某个具体场景的成本远高于收益,这也是为什么数据和 AI 迟迟难以落地的根本原因。
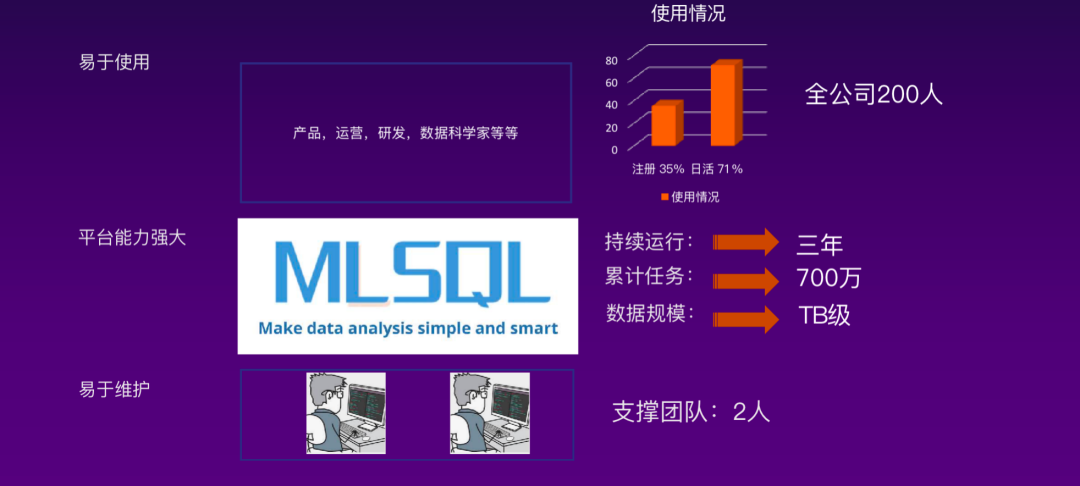
而如果使用 MLSQL,那么事情会是什么样子呢?使用者广泛、使用成本低、运维成本低,仅需很少的维护人员,可以最有效的利用数据的价值!
Q3:MLSQL与 SQL/Python/PySpark 之类的什么不同呢?
命令行支持
脚本化
支持引用
支持第三方模块
支持模板
支持函数定义
支持分支语句
相比 Python,MLSQL 是一个天生支持分布式的语言,但同时也具备强大的可编程能力。但是我们知道 MLSQL 是同时面向大数据和 AI 的分布式语言,而 MLSQL 尽管功能强大,但对算法的支持默认是需要使用 Java/Scala 开发的 native 插件来完成的,同时,为了能够拥抱现有的 Python AI 生态,所以 MLSQL 需要也必须提供支持运行 Python 脚本能力,Python 是作为寄生语言存在于 MLSQL 当中。
我们通过 pyjava 库,让 Python 脚本可以访问到 MLSQL 产生的临时表(在 MLSQL 中,模型也可以存储成表),也可以让 MLSQL 宿主语言获取 Python 的结果,通过引入 Ray,我们给 Python 提供了分布式编程能力,从而使得整个语言都是分布式的。
下面是一个语言示例:
!sh wget "https://github.com/allwefantasy/spark-deep-learning-toy/releases/download/v0.01/cifar.tgz";!sh mkdir -p tmp/cifar10;!sh tar -xf "cifar.tgz" "-C" "/tmp/cifar10";include project.`./src/common/PyHeader.mlsql`;load binaryFile.`/tmp/cifar10/cifar/train/*.png` as cifar10;!python conf "cache=true";!python conf "schema=st(field(content,binary),field(path,string))";!python conf "dataMode=data";run command as Ray.`` whereinputTable="cifar10"and outputTable="cifar10_resize"and code='''import io,cv2,numpy as npfrom pyjava.api.mlsql import RayContextray_context = RayContext.connect(globals(),"127.0.0.1:10001")def resize_image(row):new_row = {}image_bin = row["content"]oriimg = cv2.imdecode(np.frombuffer(io.BytesIO(image_bin).getbuffer(),np.uint8),1)newimage = cv2.resize(oriimg,(28,28))is_success, buffer = cv2.imencode(".png", newimage)io_buf = io.BytesIO(buffer)new_row["content"]=io_buf.getvalue()new_row["path"]=row["path"]return new_rowray_context.foreach(resize_image)''';-- 引入一些函数,方便在SQL中使用include project.`./src/common/functions.mlsql`;-- 这里,arrayLast 函数来源于 ./src/common/functions.mlsql 中select arrayLast(split(path,"/")) as fileName,contentfrom cifar10_resizeas final_dataset;save overwrite final_dataset as image.`/tmp/size-28x28`where imageColumn="content"and fileName="fileName";
上面这个是跑在 MLSQL 桌面版上的一个示例,做的事情很简单:
下载 cifar10 数据集
加载图片数据得到表
对表使用 Python 中 opencv 进行加工,这个过程也是分布式处理的
python 输出结果重新给 select 语句处理
最后保存结果成图片文件而非表里。
从这里我们可以看到,Python 在 MLSQL 里只是一段文本片段,但是 MLSQL 可以执行它,并且用它来处理和输出数据,这也包括机器学习相关的工作。
PySpark 本质上还是 Python 代码,只是引入了一个新的编程范式(约定),从而实现分布式数据处理。他首先需要你掌握 Python,其次还需要你学习他的新的编程范式,而这种范式往往会让你和原先的 Python 编程相冲突,你难以理解到底哪部分是分布式的,那部分是单机的,以及序列化导致的诡异问题。并且,PySpark 适合数据处理而非 AI 相关的工作,他的编程范式不足以满足灵活的 AI 需求。
在 MLSQL 中,你可以不使用 Python,仅仅需要一些基础的类 SQL 语法就可以完成数据和 AI 的工作,但是如果你一定需要 Python,我们借助 Ray 提供了一个更友好的分布式编程。譬如,简单通过一个 @ray.remote 注解,就可以把 Python 的一个方法或者一个类转变成可能运行在任何节点的方法和类,从而轻松的实现分布式编程。
@ray.remotedef f(i):time.sleep(1)return ifutures = [f.remote(i) for i in range(4)]print(ray.get(futures))
我们也有更复杂的分布式模型训练的案例:MLSQL深度学习入门【二】-分布式模型训练_哔哩哔哩_bilibili
Q4:MLSQL 怎么帮助仅仅有 Web 工程师的小团队去落地数据和 AI 能力?
MLSQL 针对数据科学家,提供了 Python 脚本的嵌入能力。但实际上,MLSQL 完全可以不使用 Python,就可以完成 AI 的全部 Pipeline。
下面是一段简单的示例代码:
-- 训练train mock_data as RandomForest.`/tmp/model` wherekeepVersion="true"and evaluateTable="mock_data_validate"and `fitParam.0.labelCol`="label"and `fitParam.0.featuresCol`="features"and `fitParam.0.maxDepth`="2";-- 注册模型register RandomForest.`/tmp/model` as model_predict;-- 预测数据,支持批流,http APIselect vec_array(model_predict(features)) from mock_data as output;
MLSQL 抽象出了 train 用来训练模型,抽象了 register 用来将模型转化为函数,而有了函数之后,就可以将其应用在 SQL 当中进行批流预测,同时,我们也可以使用 http 请求使用这个函数:
!sh curl "-XPOST""http://127.0.0.1:9003/model/predict" "-d"'''dataType=row&sql=select vec_argmax(model_predict(vec_dense(doc))) as predicted_label&data=[{"doc":[5.1,3.5,1.4,0.2]}]''';
在上面的示例中,用户通过select语句组织函数,对传递进系统的data数据进行处理。更完整的例子参考这个视频:MLSQL 机器学习最简教程(无需Python!)
一个普通的工程师,仅仅需要花费一天的时间学习 MLSQL 语法,然后可能再花费半天到一天的时间,就可以完成算法的开发到部署。
Q5: 如果我们大数据体系已经非常成熟,还能/需要引入MLSQL么?

MLSQL 安装部署使用维护的四个环节很简单,大家可以从桌面版就用起来,此时根本无需维护。而服务器版本,只需一个引擎(以及可插拔的 Ray),外加提供一个存储(对象存储或者 HDFS)即可。在使用场景上,可全栈,譬如批,流,机器学习都能 cover 住,也可以只是整个生产流程的一个小环节。如果非常成熟了,那么多加一个组件也不是问题~
Q6:怎么可以快速体验到 MLSQL 语言?
即刻使用的在线体验环境
最新版本的 MLSQL 引擎服务(版本号:2.2.0)
简单易用的 Notebook 和 Workflow 产品能力

大家可以复制链接在线体验 MLSQL :https://www.mlsql.tech/home(建议使用 Web 浏览),也可下滑至文末查看 MLSQL 快速体验的教程哦~
Q7:服务器版和桌面版的区别
桌面版是基于 VSCode 开发的一个语言插件,这使得你开发 MLSQL 就像开发传统的 Java/Go 等语言一样。为了能够运行你写的 MLSQL 代码,通常需要你配置一个语言的 SDK,这也和传统 JDK 或者 Go 一样。桌面版是可以脱离服务器端独立运行的。
尽管如此,你可以在桌面端通过修改配置,连接到云端的语言引擎执行你的代码:
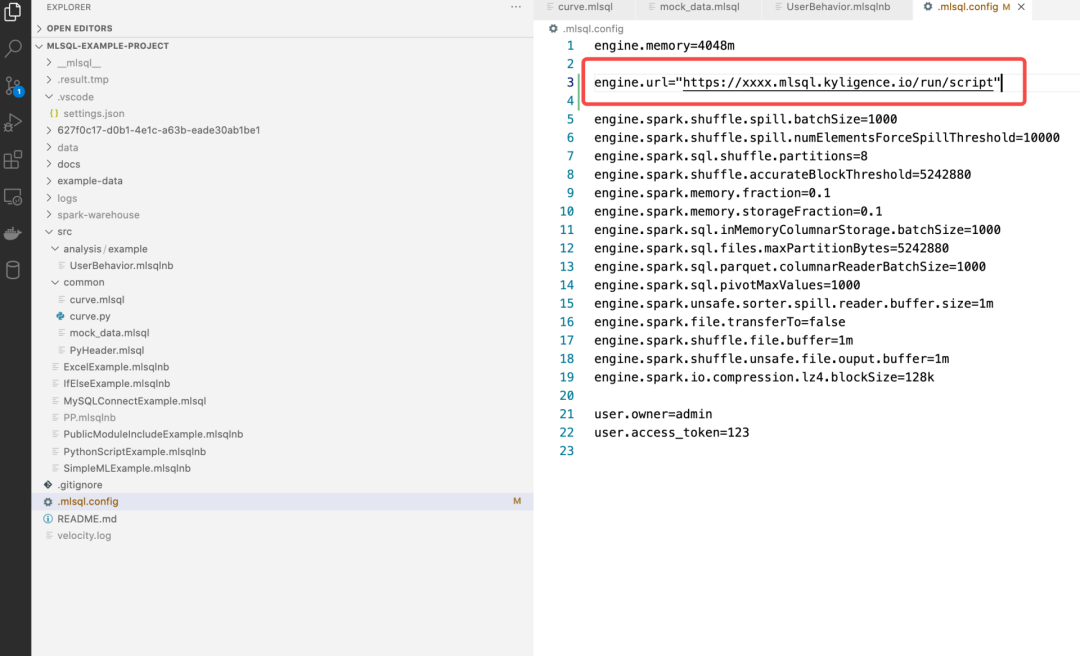
因为 MLSQL 的语言执行引擎和 Java/Go 不同,他是一个分布式引擎,所以可以部署在 K8s,Yarn 等分布式系统中,拥有更强大计算和存储能力。
服务器版是指将 MLSQL 语言引擎部署在私有的 K8s 环境亦或是云上,同时我们也提供了 Console 等纯 Web 端的交互产品,方便你管理和开发 MLSQL 代码。
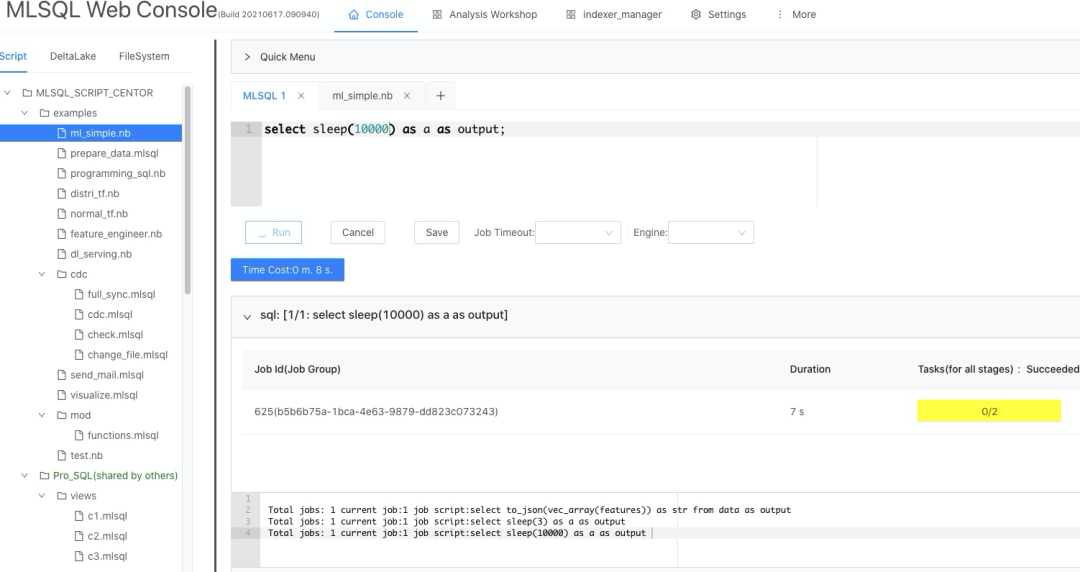
Q8:是不是必须要上 K8s,没有上 K8s 的系统我们是怎么处理的?如传统系统。
MLSQL 服务器版支持并推荐大家使用 K8s,当然也支持也包括 Yarn, Standalone 等传统部署模式,所以大家可以放心使用。
Q9:K8s 上存储分离带来的性能损耗以及 shuffle 盘的弹性问题是需要我们解决还是 MLSQL 自己就能解决?
MLSQL 内置了数据湖,并且引入了JuiceFS 来解决存储和分离的问题。在我们提供的 mlsql-deploy 部署工具中,我们也内置了JuiceFS 的支持。用户在使用它部署MLSQL Engine 到 K8s 的时候仅需提供 Redis/TiKV/MySQL 任意一个即可加速 MLSQL 数据的读取和写入。同时我们也通过 JuiceFS 提供弹性使用本地盘和对象存储帮助用户解决 Shuffle 的性能以及可扩展性问题,避免被磁盘空间所困扰。
看完上面十问十答,你是不是也想快速体验一把 MLSQL,这不在线试用教程来啦~手把手教你快速上手 MLSQL!
首先,大家打开 MLSQL 官网 https://www.mlsql.tech/home 即可看到下方页面:

注册登录在线试用环境 MLSQL Lab 之后,即可看到下方页面:

Quick Start 快速开始:可通过探索 MLSQL 内置的 Notebook 进行快速上手;
Import & Connect Data 上传数据:支持用户上传自定义数据文件;
Create a New Notebook 创建笔记本:同时支持数据科学家常用的 Notebook 模式,以及低代码开发的 Workflow 模式
如果大家刚刚接触,建议先从「快速开始」进行探索,接下来我们就带大家快速体验一把👇
在 Workspace 工作区中,MLSQL 自带了两个 Notebook 和一个 Workflow,来帮助初学者了解 MLSQL 的基础使用和语法。
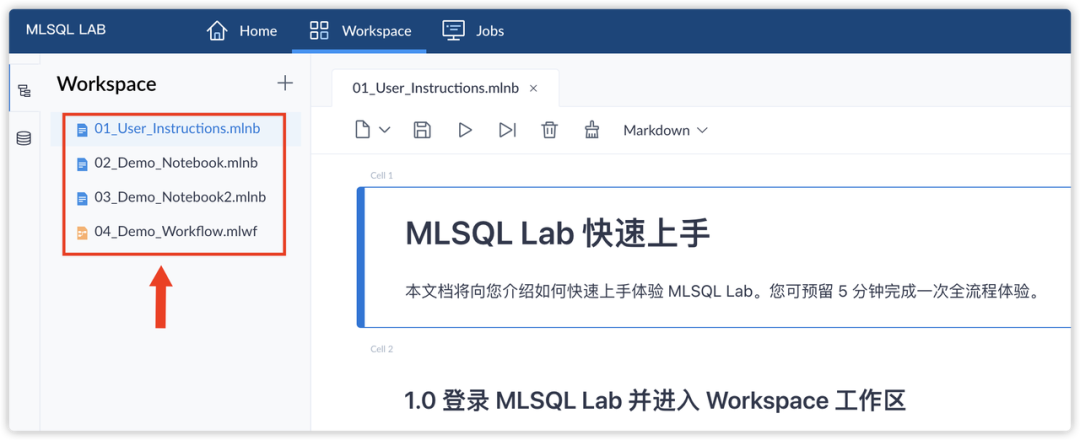
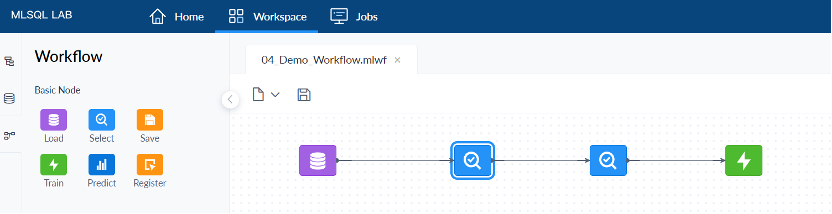
打开其中一个 Demo 的 Notebook,点击 「Run All 运行全部」,即可运行当前 Notebook 中的全部代码行,展现出分析和预测的结果。
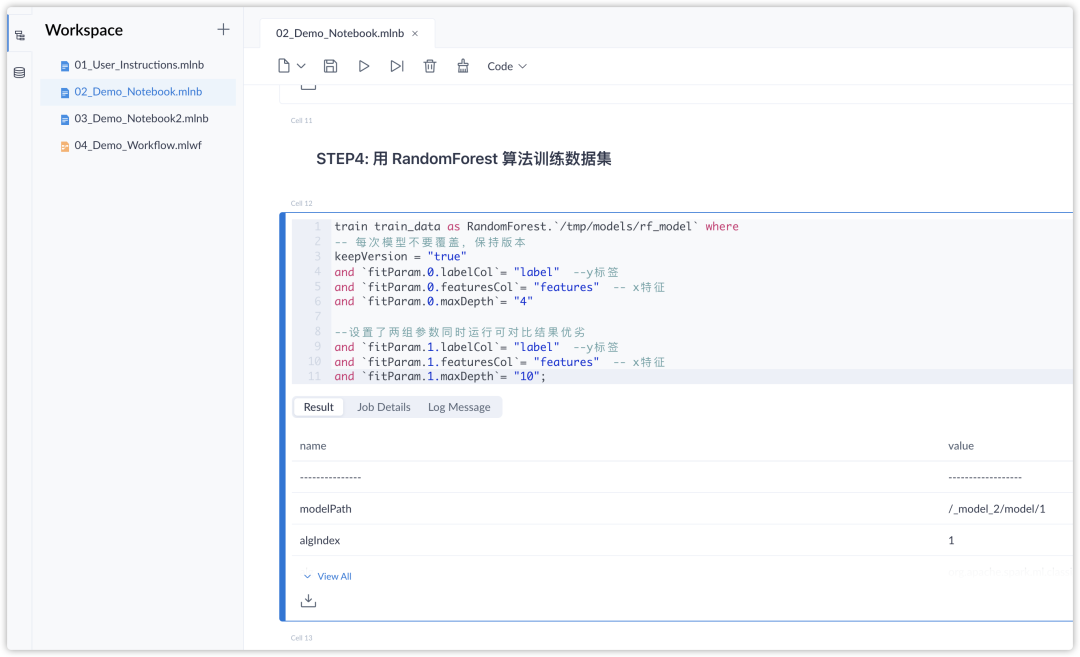
MLSQL Lab 的两个 Notebook 的示例包含了两个来自 Kaggle 的数据集,初次接触机器学习的用户就能基于它们进行分析和预测啦!示例完整的展现了如何用 MLSQL 进行从数据的导入,清洗,拆分,训练,预测,调优。如果大家对更多主题的数据集分析预测感兴趣,欢迎大家通过「Import & Connect Data」和「Create a New Notebook」来开启更多自定义的探索~
希望上面这十问十答和在线试用可以解答大家的一些疑惑,如果你在学习 MLSQL 的过程中有什么问题,欢迎在本文下方留言讨论。
想了解更多精彩内容,欢迎大家点击「阅读原文」免费报名参加10月30日由 Kyligence 主办的 Kylin X MLSQL Meetup,来上海和包括 MLSQL 作者在内的多位技术大佬进一步交流~
👇 扫码加入活动群👇

点击阅读原文,立即免费报名
