




上一篇文章讲述了存储的基础知识(戳此回顾),但是存储的基础知识还没有结束,因为在存储基础知识里,最重要的RAID技术还没有深入讲解,所以本篇文章,会就RAID磁盘阵列技术,进行详细讲解,并为后续的存储虚拟机技术,作进一步铺垫。
如之前文章所述,无论是DAS、NAS,还是SAN,都是存储系统,一个存储系统可以包含多块磁盘;不同磁盘之间的组织排列,就是磁盘阵列技术,也就是RAID技术。
RAID磁盘阵列技术的核心思想,主要有两个,包括:
(1)提升存储访问速度;
(2)提升存储可靠性;
这两大核心思想的实现,主要依赖于:
(1)独特的数据组织方式和存取方式,实现存储的高速访问;
(2)独特的数据冗余方式,实现数据备份,可恢复;
如下,依次讲解RAID的数据组织方式、存取方式以及冗余方式。
RAID数据组织方式
RAID磁盘阵列中的数据组织形式,如下图所示,主要从三个维度进行数据组织,即分区(Extent)、分条(Strip)、和条带(Stripe),如下:
分区:是将磁盘进行纵向分割,比如将磁盘0分割为分区0和分区1,将磁盘1分割为分区2和分区3,依次类推;
分条:是将磁盘进行横向分割,比如将磁盘0、1、2、3,横向分割出分条0、分条1等;
条带:纵向分割的分区和横向分割的分条,交叉之后形成条带;比如分区0和分条0交叉,形成条带0,0,分区2和分条0交叉,形成条带2,0;
需要注意的是条带可以包含多个数据块(Block),数据块是磁盘存储数据的最小单位,比如条带0,0包含数据块0和数据块1;一个条带包含的数据块数量,称之为分条深度,比如分条0深度为2,该分条内的条带均包含2个数据块,而分条1深度为1,该分条内的条带均包含1个数据块;一个分条跨越的分区数量,称之为分条尺寸,比如分条0跨越4个分区,所以分条尺寸为4。
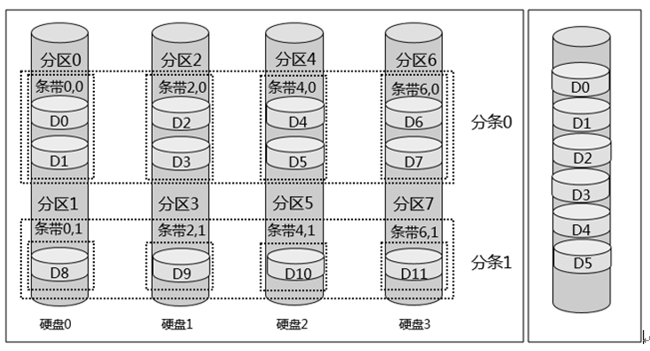
可以看到上述数据组织形式,是将数据打散开来的。虽然我们数据实际的组织形式是离散的,但是逻辑上呈现的仍然是连续的寻址空间,如上右图所示。
RAID数据存取方式
根据上述离散的数据组织形式,不难发现数据的存取,也是离散的。比如要将一段数据,存入D0~D3,就需要将数据,依次存入磁盘0的条带0,0,和磁盘1的条带2,0。反过来,数据的读取也是一样的。但是这种离散的数据存取方式,可以极大提高磁盘的存取速度,原因很简单,如果要写入数据D0~D7,可以将这些数据块并行写入四个磁盘,写入速度几乎提高四倍。反之,读取数据,也可以进行并行读取。
RAID数据冗余方式
RAID磁盘阵列中的数据冗余方式,主要分为镜像冗余和校验冗余,如下:
镜像冗余:这个很好理解,就是数据一比一镜像备份,比如磁盘1存储原始数据,磁盘2存储镜像备份数据,这时磁盘2就是磁盘1的备份;如果磁盘1故障,磁盘2可以直接恢复数据。
校验冗余:镜像冗余对于数据的保护性还是很强的,但是缺点很明显,就是存储利用率低,即两块磁盘,只有一块磁盘存储有效数据,另一块磁盘存储的是镜像备份数据,存储空间利用率只有50%,这个利用率已经非常低了。
这时候,可以基于一些校验算法(比如奇偶校验),根据原始数据,使用校验算法生成校验数据,这部分校验数据就是冗余数据;如果原始数据因为磁盘故障丢失,这时可以使用校验算法,基于校验数据(冗余数据)逆向恢复原始数据。
举个例子,异或校验算法,可以根据100个原始数据生成50个校验数据(冗余数据),如果100个原始数据中有50个数据因为故障丢失了,那么根据剩下的50个原始数据,以及50个校验数据,使用异或校验算法,可以逆向恢复丢失的那50个原始数据;这样存储空间利用率是100(原始数据)/150(原始+校验数据)= 66.6666%。
通常,校验算法越先进,生成的校验数据(冗余数据)越少,存储空间利用率越高。但是越先进的校验算法,也意味着该算法越复杂,执行起来越消耗资源。
在RAID中,可以选择使用XOR异或校验算法,或者海明码;后者海明码更加先进,但是也更加复杂,运行海明码所带来的巨大资源消耗,往往让人难以接受,所以现在RAID中,多使用简单可行的异或校验算法。
上一章节就RAID技术原理进行了详细讲解,在遵循基本数据组织原理基础上,RAID磁盘阵列实际可以灵活安排数据组织结构,以提供不同的数据保护能力,和不同的数据存取性能,这就是不同的RAID级别。
RAID技术发展至今,已经有了RAID 0~6,这七种级别,不同级别代表RAID磁盘阵列不同的存储性能,存储成本和数据安全性;现在依次看下这七种RAID级别,如下:
RAID 0
该级别提供了RAID磁盘阵列最高的存储性能,RAID 0就是完全按照【分区&分条&条带】这三个维度,进行数据的组织存取,简称为条带化的数据存储;条带化的数据存储形式,在上面章节,已经详细讲解过了,如下,这里不再赘述。
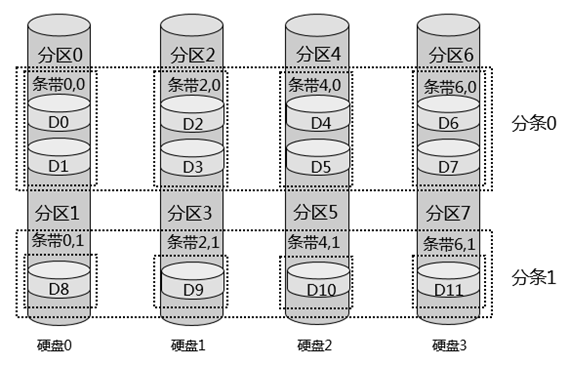
RAID 0提供了超高的数据存取速度,因为数据是条带化存储的,意味着数据可以并行存取,比如要读取数据D0~D7,则可以并行读取磁盘0的条带0,0,磁盘1的条带2,0,磁盘2的条带4,0,以及磁盘3的条带6,0;反之,写入数据,也可以进行并行写入。
所以RAID 0磁盘阵列的性能,是和阵列中磁盘数量成正比的,最简单的公式就是RAID 0总体性能=单一磁盘性能*磁盘数量,比如阵列中包含4块磁盘,单一磁盘性能为50MBps,则RAID 0磁盘阵列性能为200MBps,因为可以同时并行存取这四块磁盘。
但是上述只是理想情况下的假设,因为RAID 0磁盘阵列存在性能的边际递减,也就是说如果单一磁盘性能为50MBps,则两块磁盘的RAID 0性能约为95MBps,三块磁盘的RAID 0性能约为130MBps,依次类推;但就算存在性能的边际递减,RAID 0磁盘阵列的存储性能,仍然是最优秀的。
综上,RAID 0的优点是存储性能高,缺点也很明显,即不提供数据保护。
RAID 1
RAID 1级别的数据组织形式,非常简单,采用最简单的镜像备份数据,如下:
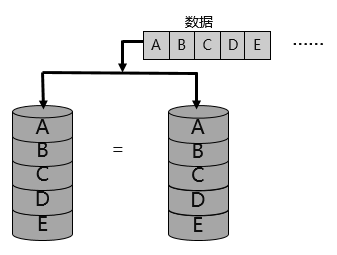
根据上图所示,可以看到RAID 1级别的数据组织,就是使用两块磁盘,一块磁盘存储原始数据,另一块磁盘存储镜像备份数据;如果因为磁盘故障,导致原始数据丢失,根据另一块磁盘里的镜像备份数据,可以快速恢复数据,所以RAID 1级别提供了较高的数据可靠性。
RAID 1级别,相较于RAID 0级别,在数据存储性能上是有损失的,尤其是写入数据,因为每次写入数据,实际写入的数据既要写入原始磁盘,也要写入镜像备份的磁盘(如果镜像备份的磁盘性能较低,容易形成性能瓶颈);但是读取数据的性能,还是可以的,因为可以从原始磁盘和镜像磁盘,并行读取数据;但无论如何,RAID 1肯定比不上RAID 0级别的存储性能。
综上,RAID 1级别的优点是数据可靠性高,缺点也很明显,就是存储成本高(因为需要两块磁盘,一块存储原始数据,一块存储镜像备份数据),存储空间利用率低(只有50%);所以RAID 1级别磁盘阵列,适合数据可靠性要求非常高的场景,比如银行,证券交易所等。
RAID 2
考虑采用镜像备份的方式保护数据,存储成本较高,存储空间利用率较低,所以可以使用校验冗余的方式保护数据,而不再使用RAID 1中的镜像冗余;RAID 2就是基于海明码,计算校验冗余数据,如果原始数据丢失,根据校验数据,海明码算法,可以逆向计算,并恢复原始数据,如下:
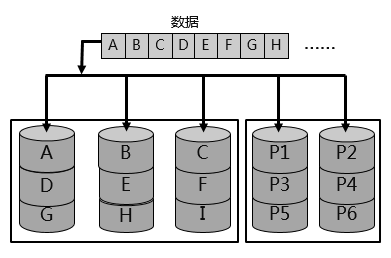
根据上图所示,可以看到前三块磁盘存储的是原始数据,最后两块磁盘存储的是海明码根据原始数据计算出的校验数据,所以最后两块磁盘也被称为校验盘。
校验算法可以正向计算(原始数据–>校验数据),即使用校验算法,根据原始数据,计算出校验数据;校验算法也可以反向计算(校验数据->原始数据),即使用校验算法,根据校验数据,计算出原始数据;这一特性,也就保证了,如果有原始数据丢失,那么根据校验数据,可以计算恢复出原始数据。
但是海明码算法有个特点,就是如果原始数据磁盘较少,那么校验磁盘和原始数据磁盘的数量几乎一致,比如原始数据磁盘3个,那么校验磁盘就需要2个(存储空间利用率60%),再比如原始数据磁盘4个,那么校验磁盘就需要3个(存储空间利用率57%);但是如果原始磁盘的数量非常多,那么校验磁盘的数量会快速下降,比如原始磁盘数量64个,那么校验磁盘只需要7个(存储空间利用率90%)。
综上,RAID 2级别的优点是依据海明码提供数据保护,缺点也很明显,在数据量较低(数据磁盘较少)时,校验磁盘的数量几乎和数据磁盘的数量一致,导致存储成本高,存储空间利用率低;所以RAID 1级别,非常适合于一些大数据存储场景,本身就需要海量磁盘进行数据存储。
RAID 3
采用海明码校验算法,在存储数据量较少时,体现不出海明码的先进性,同时海明码本身算法复杂,海明码计算起来,也非常消耗资源,所以磁盘阵列里更加倾向于简单的异或校验算法,这就是RAID 3级别;RAID 3级别,使用异或校验算法,计算校验数据,为原始数据,提供校验冗余的保护:
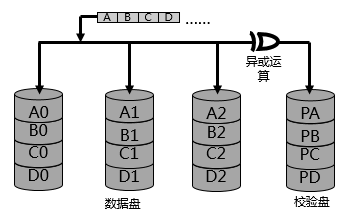
另外,RAID 3的数据组织形式,和RAID 0一样,采用条带化的数据组织形式,所以RAID 3在保证了数据存储性能较高的前提下,提供了数据的校验保护,可以说是非常经济实惠的磁盘阵列技术。
RAID 5
RAID 5和RAID 3非常相似,都是采用条带化的数据组织形式(存储性能高),也都采用简单的异或校验算法,计算校验数据,提供原始数据的校验保护(数据可靠性高)。
唯一的区别,在于RAID 3级别将所有的校验数据,专门存放于检验盘,如果校验盘故障了,则所有的校验数据丢失,原始数据的保护性,也就没有了;所以RAID 5将校验数据,分散的存放于各个磁盘,不再单独设置校验盘,如下:
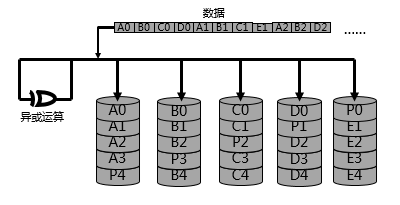
根据上图所示,可以发现RAID 5级别,不再单独设置校验盘,校验数据(P数据),分散的存放于各个磁盘,这样无论哪个磁盘故障,校验数据都不会完全丢失,剩余的校验数据,仍然可以帮助完成原始数据的回复。
RAID 6
无论是RAID 3,还是RAID 5,它们使用异或运算,计算校验数据,保护原始数据,所提供的保护性都是有限的,即只能保护一块原始数据磁盘;换言之,如果磁盘阵列中有一块数据磁盘故障,根据校验数据,可以恢复那块数据磁盘中的原始数据,但是如果同时两块(或以上)磁盘故障,那么就无法完全恢复数据了;这个实际并不难理解,所有的保护措施,都是有限保护,而不是无限保护。
RAID 6的核心思想,就是如果同时两块数据磁盘故障了,能不能恢复数据,答案是肯定的;只需要执行两次异或校验算法,生成两份校验数据,校验数据的增加,使得即使出现两块数据磁盘故障,两块故障数据磁盘里的原始数据,也都可以进行恢复,如下:
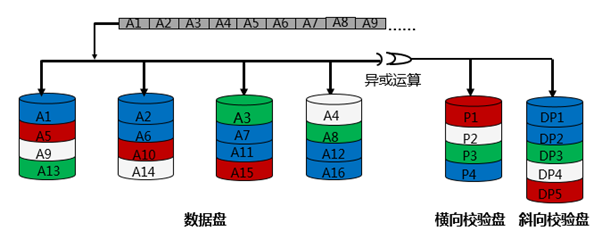
根据上图所示,可以发现RAID 6使用两次异或运算,计算出了两份校验数据(横向校验数据和斜向校验数据),校验数据的增加,也就保证了,就算是两块数据磁盘故障,也能恢复数据。
如果大胆的去预测,只要不断增加校验数据,我们甚至可以保证三块数据磁盘故障情况下恢复数据,或者四块数据磁盘故障情况下恢复数据等等;但是一味增加校验数据,就意味着磁盘存储利用率的不断下降,如果存储空间利用率都不到50%(即校验数据都超过了原始数据),那么还不如直接使用RAID 1镜像备份来保护数据。
综上,RAID 6通过增加校验数据,提供更高的数据保护,但是因为校验数据多了(冗余数据多了),所以存储空间利用率也在下降。
RAID 10
因为RAID 1级别并没有使用条带化的数据组织形式,如下所示,所以虽然RAID 1提供了非常高的数据保护(镜像保护),但是存储性能整体不高。
我们自然而然的在想,能不能在RAID 1级别中,也引入条带化的数据组织形式,考虑到RAID 0级别是条带化数据组织的典型,于是将RAID 1和RAID 0结合,就产生了RAID 10级别,即使用RAID 1的镜像备份保护数据(提升数据可靠性),也使用RAID 0的条带化组织数据(提升存储性能)。
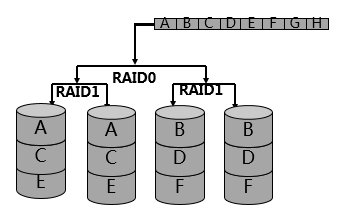
综上,所有的RAID级别,大致可以分为三类,(1)RAID 0级别,以条带化形式组织数据,提供超高的存储性能,(2)RAID 1级别,以镜像冗余保护数据,提供超高的存储可靠性,(3)RAID 2 & RAID 3 & RAID 5 & RAID 6,这四个级别,均以校验冗余,提供数据的保护性;其中RAID 2使用海明码校验算法,RAID 3& RAID 5& RAID 6均使用异或校验算法。
到这里为止,我们对于RAID磁盘阵列技术,应该已经很熟悉了。但是需要注意的是,RAID磁盘阵列,一般无法直接使用,计算设备使用的存储资源,主要是LUN形式的存储资源,即逻辑存储资源。
我们可以将RAID磁盘阵列划分为一个逻辑单元(LU,Logical Unit),或者多个逻辑单元(LU,Logical Unit),如下所示。为了便于使用和描述逻辑单元,使用逻辑单元号(LUN,Logical Unit Number),来标识一个逻辑单元。一个LUN对应的可能是磁盘,也可能是其它存储设备。
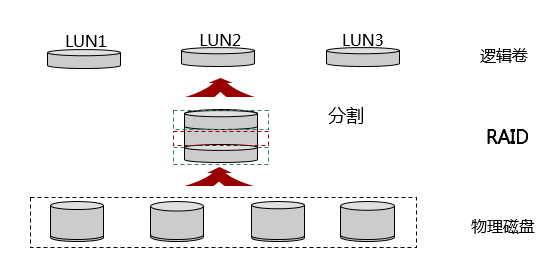
所以,LUN的主要作用是将外部存储设备(可以是RAID磁盘阵列,或者其它存储设备),映射为基本的块存储设备,以使得服务器可以对其进行分区,格式化等一系列磁盘操作,而不必关心这个LUN的物理组成(RAID磁盘阵列组成的,或者其它存储设备组成的)。
最后,通过RAID磁盘阵列当然可以提供对于数据的保护,RAID磁盘阵列基础上的数据保护,是比较底层的数据保护;除此之外,我们还可以有其它数据保护机制,即上层的数据保护机制,包括多路径技术和快照技术。
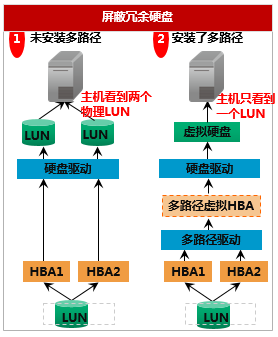
如果服务器到存储设备的路径只有一条,那么这仅有的一条路径如果故障,则服务器将无法访问存储设备,后果比较严重;所以通常情况下,会在服务器到存储设备之间,规划多条路径。
但是如果在服务器和存储设备之间规划多条路径,容易让服务器认为有多个存储设备(多个LUN,即多个逻辑存储单元),如下所示;如下左侧,只有一个LUN,但是因为多路径的存在,服务器看到了两个LUN,这会引起混淆;所以使用多路径软件,多路径软件,会让服务器只看到一个LUN,并且如果有路径故障,及时切换到备用路径上,如下右侧所示。
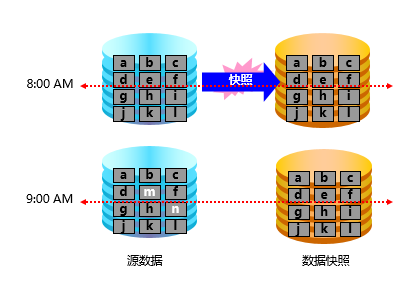
上一章节,详细讲述了多路径的数据保护机制,本章节继续讲述另外一种数据保护机制,即快照技术;对于在线存储业务,通常需要保证,当存储设备故障,或文件操作不当而损坏时,能够将数据恢复到某个可用的时间点状态;比如9点钟,我在编辑一个文件,但是因为操作不当(比如没有保存文件,就强制下线了),这时候我就需要将文件数据恢复到9点钟时的文件状态,因为9点钟那个时间点,我确定文件数据是基本可用的。
这时候,就可以使用快照技术,快照技术使用快照卷指向之前时间点的文件数据,依据快照卷,可以将数据恢复到之前时间点的状态;如下所示,8点钟时间点,针对文件数据,进行了快照卷备份,9点钟时间点,原始文件数据发生了改变,但是基于数据快照(Snapshot),仍然可以将文件数据,恢复到8点钟时间点状态。
最后,本篇文章进一步补充了存储基础知识,即RAID磁盘阵列技术,结合之前一篇文章,我们对于存储基本拥有了一个全面而深入的学习,知道了一系列存储基础知识;那么下一篇文章,就可以讲解最激动人心的存储虚拟化技术了。
怎么样,今天的内容都学明白了吧,请大家持续关注,后续继续更新此专题~
*原创不易,记得点个「在看」,分享朋友圈再走哦~

