




前提说明:
❝以下的相关的示例代码基于当前使用pika的版本是1.2最新版本的!
以下的相关的示例代码基于当前使用pika的版本是1.2最新版本的!
以下的相关的示例代码基于当前使用pika的版本是1.2最新版本的!
不同的版本的之间客户端的差异挺大的!以前的旧的版本很多的函数和传参再新版里面几乎是木有了!
1 消息可靠性的问题
如何保证我们的消息正确的发生到了MQ?
其实这个消息可靠性的问题,在业务处理上某些业务场景还是非常的重要,对于强依赖性的消息的话,我们必须要确保我们的消息正确的投递到我们的MQ上,甚至于需要确保我们的消息被正确的进行消费了,避免重复消费等问题,甚至有些时候我们还不可规避的需要处理消息消费的幂等性的问题.
❝PS:消息消费的幂等性其实是指我的消息就算多次的消息同一个消息,我的到的结果都是一样的!
所以关于消息可靠性的问题,其实我们的可以分为两侧去分析:
1.1:生产端的消息投递的可靠性
之前的几个示例的中,其实关注消息投递可靠性是没有涉及到,我们的前几个示例只管消息的发送出去,都不在乎它是不是真的意见正确的发送到我们的MQ上面。这一小篇主要来思考一些这些问题。
首先一个消息正确的投递到MD 需要经过的步骤有:
消息投递的过程:消息---》交换机----》消息队列---》消息持久化存贮
上面的过程中其实每一步都涉及到我们的MQ消息处理可靠性的确认.如何确保我们的消息不丢失,或如何监测到我们的消息投递失败的的监听,这是我们的需要考虑的问题.
所以首先我们需要认清的问题点是消息丢失的可能性有哪几种?
1:消息投递到交换机的时候,就出现了异常---》消息丢失 2:消息已正确的进入到了我们的交换机----》但进入队列时异常了,或者说是routing_key匹配错了---消息丢失 3:消息正确的进入到我们的消息队列的时候,开启了持久化的时候,再持久化的时候出现问题---消息丢失
针对上述的几种,那我们的需要解决的问题点有:
1:我们的需要确保我们的消息到MQ是正常,成功了或错误了应该有回执通知 2:我们需要确保消息路由到正确的队列上~不能出现匹配错误的情况,有错误的情况,应该有回执通知生产者 3:需要确保我们的消息在队列里面正确的存贮---

官网提供的方案其实是有两种的:
使用事务机制

使用事务虽然可以保证消息的准确达到,但是它极大地牺牲了性能,因此我们为了性能上的要求,可以采用另一种高效的解决方案——通过使用Confirm模式来保证消息的准确性。
使用Confirm模式根据官网pika的文档
第1步是需要开启确认模式:
channel.confirm_delivery()
第2步:进行消息发布的时候设置强制标志和处理异常来检查消息是否已传递:
首先是设置强制标志:
mandatory=True
然后对我们的发布的消息进行一步的捕获处理
# 开启去人后,如果发送到我们的交换机异常的时候
channel.confirm_delivery()
# 发布交换机
# 设置强制标志和处理异常来检查消息是否已传递:
# 官网的最新版本的pika是使用的异常的捕获的方式来处理!
try:
channel.basic_publish(
# 默认使用的/的交换机
exchange='',
# 默认的匹配的key
routing_key='task_queuexxxxxxxxxx-xxxx',
# 发送的消息的内容
body=body,
# 发现的消息的类型
properties=properties,
# 下面这个属性值的设置很关键!表示设置强制性标志!
mandatory=True
# pika.BasicProperties中的delivery_mode=2指明message为持久的,1 的话 表示不是持久化 2:表示持久化
)
print('Message was published',channel)
except pika.exceptions.UnroutableError as e:
print('Message was returned',e)
except pika.exceptions.NackError:
print('Message was NackError')
except pika.exceptions.StreamLostError:
print('连接不上代理服务器了!MQ突然的停止运行了!')
except pika.exceptions.ConnectionClosedByBroker:
print('链接突然的断开了!')
下面的在管理端的UI进行关闭:
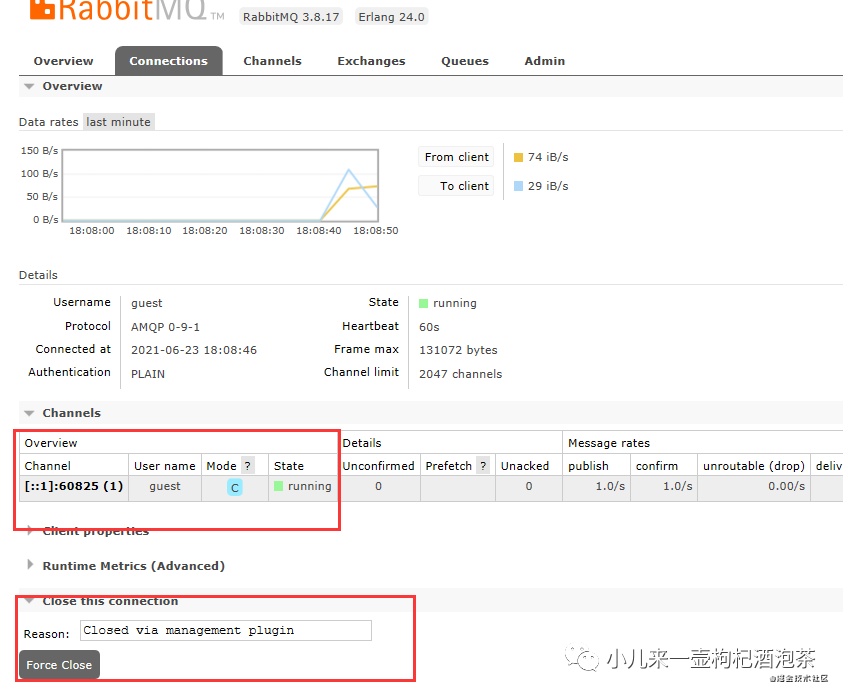
点击先的关闭的话,会触发 pika.exceptions.ConnectionClosedByBroker,这种情况下,你客户端只能重启或尝试重新创建新的链接进行处理!
另一种错误的示例:路由到不正确的key
一个完整的错误的示例,就是当我们的发布的消息路由到不存在的,或者说是不对的routing_key的时候的一个情况:
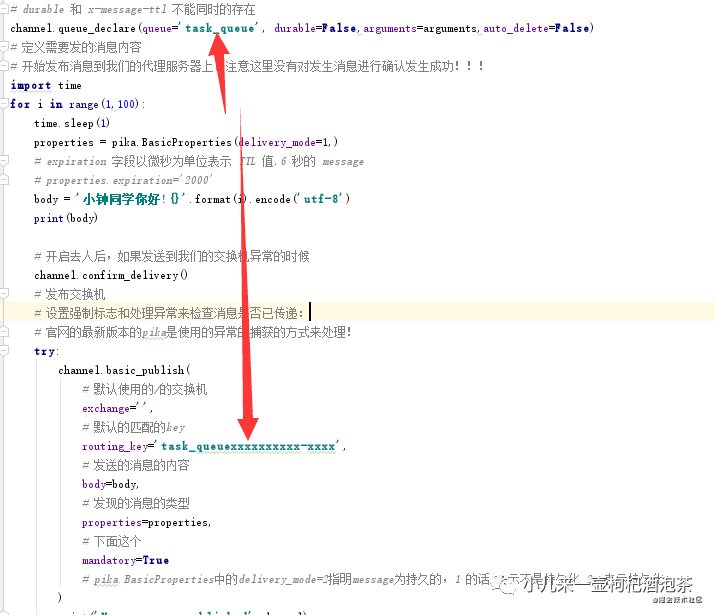
import pika
from pika import exceptions
import sys
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
arguments = {}
# TTL: ttl的单位是us,ttl=60000 表示 60s
# arguments['x-message-ttl'] = 2000
# auto_delete=False, # 最后一个队列解绑则删除 durable
# durable 和 x-message-ttl 不能同时的存在
channel.queue_declare(queue='task_queue', durable=False,arguments=arguments,auto_delete=False)
# 定义需要发的消息内容
# 开始发布消息到我们的代理服务器上,注意这里没有对发生消息进行确认发生成功!!!
import time
for i in range(1,100):
time.sleep(1)
properties = pika.BasicProperties(delivery_mode=1,)
# expiration 字段以微秒为单位表示 TTL 值,6 秒的 message
# properties.expiration='2000'
body = '小钟同学你好!{}'.format(i).encode('utf-8')
print(body)
# 开启去人后,如果发送到我们的交换机异常的时候
channel.confirm_delivery()
# 发布交换机
# 设置强制标志和处理异常来检查消息是否已传递:
# 官网的最新版本的pika是使用的异常的捕获的方式来处理!
try:
channel.basic_publish(
# 默认使用的/的交换机
exchange='',
# 默认的匹配的key
routing_key='task_queuexxxxxxxxxx-xxxx',
# 发送的消息的内容
body=body,
# 发现的消息的类型
properties=properties,
# 下面这个
mandatory=True
# pika.BasicProperties中的delivery_mode=2指明message为持久的,1 的话 表示不是持久化 2:表示持久化
)
print('Message was published',channel)
except pika.exceptions.UnroutableError as e:
print('Message was returned',e)
except pika.exceptions.NackError:
print('Message was NackError')
except pika.exceptions.StreamLostError:
print('连接不上代理服务器了!MQ突然的停止运行了!')
connection.close()
这个是我们的运行发布我们的消息的时候,我们的会正常的接收到异常的信息!

但是上面的返回的错误的信息,如果我们的想要了解的清除的话,似乎都不知道是意思,并且具体的错误的原因都无法了解!分析到内部的源码的时候发现:

它抛出其实一个_puback_return!儿这个对应的其实是一个ReturnedMessage:

来自:from pika.adapters.blocking_connection import ReturnedMessage
class ReturnedMessage(object):
"""Represents a message returned via Basic.Return in publish-acknowledgments
mode
"""
__slots__ = ('method', 'properties', 'body')
def __init__(self, method, properties, body):
"""
:param spec.Basic.Return method:
:param spec.BasicProperties properties: message properties
:param bytes body: message body; empty string if no body
"""
self.method = method
self.properties = properties
self.body = body
所以其实我们的可以从这里获取对应的返回上面相关的信息:我们可以从上面获取到相关的信息如:错误原因:
except pika.exceptions.UnroutableError as e:
# self._puback_return = ReturnedMessage(method, properties, body)
# ReturnedMessage
print("当前类型",type(e.messages))
print('Message was returned::::',e.messages[0].method)
print('Message was returned::::', e.messages[0].properties)
然后查看我们的打印输出的信息:
小钟同学你好!5
WARNING:pika.adapters.blocking_connection:Published message was returned: _delivery_confirmation=True; channel=1; method=<Basic.Return(['exchange=', 'reply_code=312', 'reply_text=NO_ROUTE', 'routing_key=task_queue2222'])>; properties=<BasicProperties(['delivery_mode=1'])>; body_size=20; body_prefix=b'\xe5\xb0\x8f\xe9\x92\x9f\xe5\x90\x8c\xe5\xad\xa6\xe4\xbd\xa0\xe5\xa5\xbd!5'
<BasicProperties(['delivery_mode=1'])>
当前类型 <class 'list'>
Message was returned:::: <Basic.Return(['exchange=', 'reply_code=312', 'reply_text=NO_ROUTE', 'routing_key=task_queue2222'])>
Message was returned:::: <BasicProperties(['delivery_mode=1'])>
上面提示reply_text=NO_ROUTE:意思是我们的找到这个队列的路由key!!!
❝PS:对于捕获到我的异常的地方,我们的可以再次进行消息的确认发布的成功的确认,不过感觉上面那种方式还是一种阻塞的方式,后续使用协程一部的aio-pika应该可以处理提供这些发布消息的阻塞的问题!后续有时间再看看!
1.2:消费端的消息消费的确认通知
消息端的消息消费的确认,通常如果对于我们的一些不太紧要的消息的,我们可以设置回消息的自动的确认机制。但是一些特殊的消息的话,则最好是建议开启我们的手动ack的模式,进行消息消费的完成的确认。(翻车纠正)
这个手动的ack的模式之前示例其实也有涉及过:
import pika
import time
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest", "guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
channel.queue_declare(queue='task_queue', durable=True)
print(' [*]能者多劳分配模式处理. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body.decode())
time.sleep(0.1)
print(" [x] Done")
# 默认开始的是需要手动的ack
kkk = ch.basic_ack(delivery_tag=method.delivery_tag)
print("手动ACK",kkk)
#设置预取消息数量
channel.basic_qos(prefetch_count=1)
# 开始进行订阅消费
channel.basic_consume(queue='task_queue', on_message_callback=callback,auto_ack=False)
# 消费者会阻塞在这里,一直等待消息,队列中有消息了,就会执行消息的回调函数
channel.start_consuming()
主要的地方如图示:
1.3:关于消费端的消息消费的Unacked的情况
如果对消息开启了手动的ack确认的模式,当消费者处理完消息不发送ack回执,此时我们的队列的消息,不会被删除,因为没有收到ACK的确认的消息,此时消息的状态会转变为:Unacked,那么消息会被重新放入队列(状态从Unacked变成Ready),有其他消费者存在时,消息会发送给其他消费者。
如下示例:主要是看消费端:
import pika
import time
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest", "guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
channel.queue_declare(queue='task_queue', durable=True)
print(' [*]能者多劳分配模式处理. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] Received %r" % body.decode())
time.sleep(0.1)
print(" [x] Done")
# 默认开始的是需要手动的ack
# kkk = ch.basic_ack(delivery_tag=method.delivery_tag)
print("我不手动ACK")
# 暂时不设置预取消息数量
channel.basic_qos(prefetch_count=1)
# 开始进行订阅消费
channel.basic_consume(queue='task_queue', on_message_callback=callback)
# 消费者会阻塞在这里,一直等待消息,队列中有消息了,就会执行消息的回调函数
channel.start_consuming()
上面的代码我开始了手动的确认的模式,并且只预取了一个消息,再我们的一直没有回复我们的消息ack的情况下:
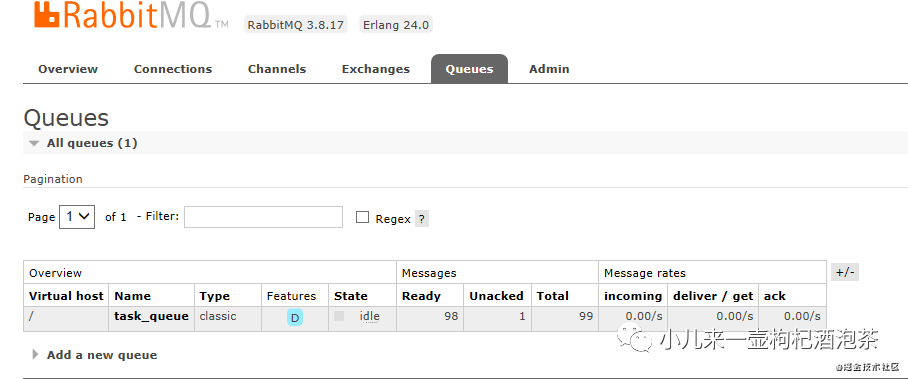
此时消息状态就转为了:Unacked,并且一直阻塞了!!!
此时断开消费者的链接:过些时间后,我们的消息从从 unacked的消息状态会重新变为ready等待消费,又回到我们的原来的队列里面去了!
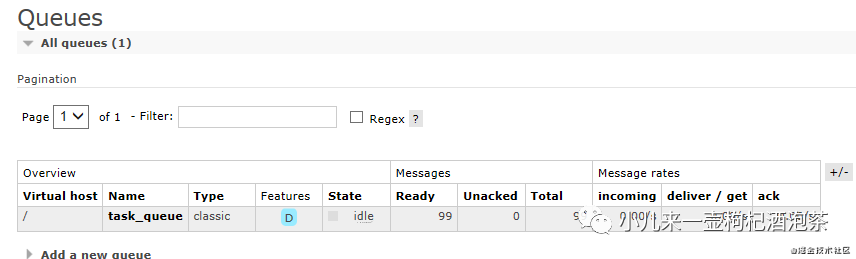
1.4 关于MQ的持久化
MQ的持久化,其实可以分为:
交换机的持久化
# 创建交换机,并指定类型
channel.exchange_declare(exchange='topic_ceshilogs', exchange_type='topic',durable=True)
队列的持久化
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
channel.queue_declare(queue='task_queue', durable=True)
消息的持久化
# pika.BasicProperties中的delivery_mode=2指明message为持久的,1 的话 表示不是持久化 2:表示持久化
properties = pika.BasicProperties(delivery_mode=1,)
# expiration 字段以微秒为单位表示 TTL 值,6 秒的 message
# properties.expiration='2000'
对于如果都开启的话,对MQ的性能肯定是有所影响滴,比较要处理的东西多了!
1.5 客户端断线重连机制
这里断线主要是针对发送的过程中,有可能出现的异常的问题!
官网基于retry的重试机制:
from retry import retry
@retry(pika.exceptions.AMQPConnectionError, delay=5, jitter=(1, 3))
def consume():
connection = pika.BlockingConnection()
channel = connection.channel()
channel.basic_consume('test', on_message_callback)
try:
channel.start_consuming()
# Don't recover connections closed by server
except pika.exceptions.ConnectionClosedByBroker:
pass
consume()
2 Rabbitma 消息幂等性问题
幂等性简单来说就是用户对于同一个行为的操作发起的一次请求或者多次请求的处理结果都是一致,也就是一次和多次的请求整个过程的相关的数据的变化是一致!不能存在不同的处理逻辑!
2.1 合理重试进行消息自动重试机制
消息重试触发的原因多种:
MQ Broker与消费端传输消息过程出现网络抖动导致的延迟传输 消费者消息消费过程的异常 定时消息的重复分发 ack确认时网络闪断
这种场景的话,主要是消费者的处理消费的异常的情况,如何进行消息的重试消费的处理的问题。目前除了PY以后,好像其他的都有客户端都实现了重试的机制,就是PY木有实现!可怜兮兮的需要自己实现!
此时可以使用第三方库的重试机制来处理这种重试!
如:
pip install tenacity
对于这个tenacity的使用可以参考官网的文档。
我这里不做过多的介绍!
这里的重试其实因为我需要针对某些错误的异常进行重试!一些验证性的异常的话!我觉得你再重试也都是没意义!所以我们在重试的时候强调的是合理重试比如导致你程序出现bug一直无法启动的那种!你就没必要重试了!重试通常主要是针对一些网络异常抖动之类的发引发的错误,重试可能会有机会再挽回的!
消息过程中异常导致消息重复消费完整重试示例(仅供参考):
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
import pika
import time
from tenacity import retry, retry_if_exception_type, retry_if_result
from tenacity import retry, stop_after_attempt, before_log, after_log, before_sleep_log,stop_after_delay
from tenacity import RetryError
import logging
logger = logging.getLogger(__name__)
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest", "guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
channel.queue_declare(queue='task_queue', durable=True)
print(' [*]能者多劳分配模式处理. To exit press CTRL+C')
def callback(ch, method, properties, body):
# 重试三次后 还是有问题的话,则抛出异常
# 重试的主要情况----ZeroDivisionError仅仅是为了演示!!!
# stop终止条件的retry
# 使用@stop_after_delay可以指定重试间隔-stop=stop_after_delay(5)-指定5秒后重试
# 使用@wait_fixed在程序重试前等待固定时间,下面就是每隔10秒进行重试
# stop_after_attempt- 重试2次后不再重试并抛出异常
@retry(wait=wait_fixed(10),stop=stop_after_delay(5) |stop_after_attempt(2),retry=retry_if_exception_type(ZeroDivisionError), before=before_log(logger, logging.DEBUG))
def yewukluji():
print(" [x] Received %r" % body.decode())
time.sleep(0.1)
print(" [x] Done")
5675/0
# 默认开始的是需要手动的ack
print('消费消息的消息编号:', method.delivery_tag)
try:
yewukluji()
except RetryError:
print("重试多次后!没办法你还是错误的!我把休息丢回去了!")
# 取消消息的接收,让它回到死信里面去
# multiple(bool) - 如果设置为True,则将传递标记视为“最多并包含”,
# 以便可以使用单个方法确认多个消息。
# 如果设置为False,则传递标记引用单个邮件。如果多个字段为1,并且传递标记为零,
# 则表示确认所有未完成的消息。
# requeue(bool) -
# 如果requeue为true,服务器将尝试重新排队该消息,继续一直尝试消费这个任务!。
# 如果requeue为false则丢弃或删除消息。
ch.basic_nack(delivery_tag=method.delivery_tag, multiple=False, requeue=False)
# 关闭,不关闭的话,它会一直去获取
# ch.close()
else:
print("完美的消费成功了!!!!")
ch.basic_ack(delivery_tag=method.delivery_tag)
# 暂时不设置预取消息数量
channel.basic_qos(prefetch_count=1)
# 开始进行订阅消费
channel.basic_consume(queue='task_queue', on_message_callback=callback)
# 消费者会阻塞在这里,一直等待消息,队列中有消息了,就会执行消息的回调函数
channel.start_consuming()
❝ps:上面作为演示,只是对应ZeroDivisionError进行异常尝试!这个其实没意义!仅做测试演示!
另外关于消息的取消处理的时候:
# 取消消息的接收,让它回到死信里面去
# multiple(bool) - 如果设置为True,则将传递标记视为“最多并包含”,
# 以便可以使用单个方法确认多个消息。
# 如果设置为False,则传递标记引用单个邮件。如果多个字段为1,并且传递标记为零,
# 则表示确认所有未完成的消息。
# requeue(bool) -
# 如果requeue为true,服务器将尝试重新排队该消息,继续一直尝试消费这个任务!。
# 如果requeue为false则丢弃或删除消息。
ch.basic_nack(delivery_tag=method.delivery_tag, multiple=False, requeue=False)
requeue=False:则会消息会直接的被丢弃! requeue=True: 则会一直循环重试重复消费这个消息,只有消费端断开后,这个消息会从unacked的消息状态会重新变为ready
2.2 消息幂等性问题,防止重复消费
既然有消息重复消费机制,那就可能存在消费被多次消费的可能性,而如果消息被多次的消费的,某些业务场景是不允许!比如转钱!哈哈 所以如何保证消息幂等性呐~
通常其实处理机制主要是再消息消费之前检验全局唯一的消息的ID是否被消费过!根据全局唯一消息ID或其他标志来去重而实现。
这种机制基于数据库的实现的方式的话,根据业务逻辑实现的话,其实可以分两种:
如果业务是处理插入操作的话,可以通过数据库表的唯一主键约束来实现,确保表中有且只有这个一个主键值
如果业务是其他操作如更新之类的话,可以使用数据库的乐观锁机制来实现。
还可以基于Redis的原子性实现,消费者在接收到消息的时候,可以根据消息ID或其他全局唯一的ID作为key执行 setnx 命令,如果执行成功就表示没有处理过这条消息,可以进行消费了,如果执行失败那么则表示消息之前已经被消费过了!不需要再进行消费!对于这个redis锁的有效期,则根据自己的业务来决定!
❝延伸扩展笔记:
乐观锁的意思是:假设数据一般情况下不会造成冲突,在数据进行提交更新处理的时候,才会正式对数据是否冲突进行检测,如果发现冲突,就会让返回用户错误的信息,让用户决定如何进行处理。(错误的概率可能相对不会那么高,对错误的发生保持乐观状态!)
悲观锁:相对于悲观锁而言,悲观锁的话,就是不管怎么样的你想修改我的所数据先要获取上锁,上锁之后其他人别想再来,需要等我处理完我的这个修改后,释放锁了再来获取,悲观锁它是直接对数据进行加锁的方式来以防止并发!(对错误的发生保持悲观状态,觉得有可能真的会发生,为安全,我只能自我保护上锁处理!!使用数据库的锁的方式,效率低,但是安全系数高点)
关于乐观锁一些补充:
乐观锁并未真正加锁,效率高。
方案1:记录数据版本。每次在执行数据的修改操作时,都会带上一个版本号,一旦版本号和数据的版本号一致就可以执行修改操作并对版本号执行+1操作,否则就执行失败,每次操作的版本号都会随之增加。[递增方案,可以多种]
上面这种版本号递增的方式对于高并发场景下的话,是存在一定的问题的!
方案2:更新的的时候使用原子操作
3 Rabbitma 队列的分类
Rabbitma的队列按照不同维度来分,可以分为
排他性队列 普通队列 延迟队列(死信队列) 惰性队列 发布订阅队列
3.1 Rabbitma 优先队列
所有的优先队列,其实就是对消息设置一个优先级的编号,用于消息的优先消息的排序。关于优先消息的场景,根据业务来订,如果比如紧急消息之类的通知处理的,需要优先被消费!
通过后端管理UI界面设置创建我们的优先级队列:
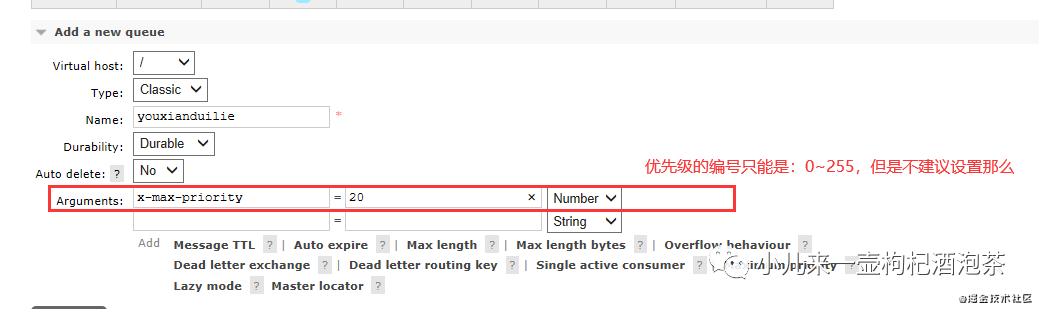 其他可选参数可以通过管理界面查看:
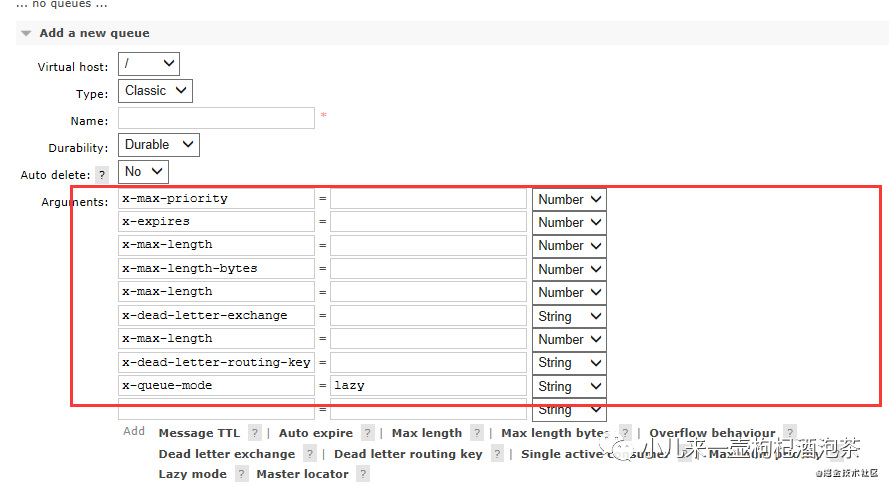
其他可选参数可以通过管理界面查看:
通过代码的方式设置创建我们的优先级队列和消息优先级:
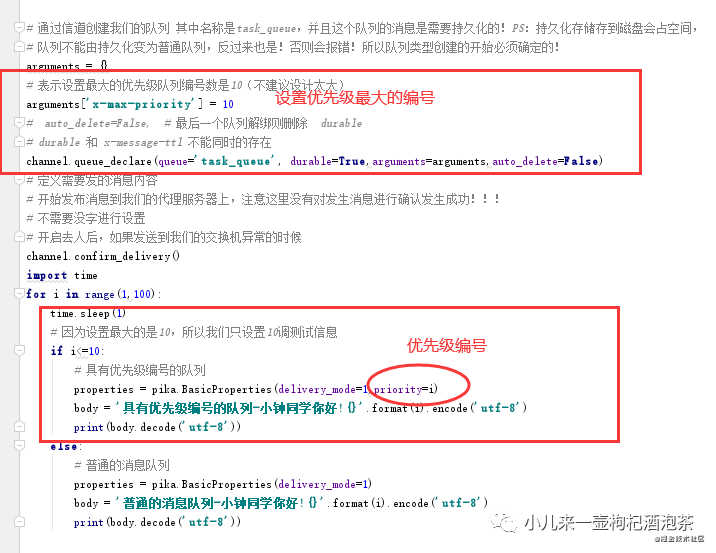
首先启动生产端:发布20调测试信息:

然后再启动我们的客户端查看消费结果:
优先级越高,它就越先消费了~

3.2 Rabbitma 惰性队列
普通队列和惰性队列的区别:
普通队列消息是存在MQ的内存中,消息会占MQ的内存 惰性队列的消息是存在磁盘中,消息会占磁盘的空间,但是数据会比较小(只是写入磁盘,但是不代表不会丢失,如果没启动持久化,重启MQ一样会丢失,所以和持久化队列有所区别,当然也可以惰性+持久化双核混搭!)
惰性队列其实关注的点是:消息存贮的方式它是存在内存还是存在磁盘。
惰性队列是把消息存在在磁盘中,当消息到MQ的时候,MQ把消息写入磁盘,而消费者需要获取消息的的时候,MQ需要先从磁盘读取消息到MQ的内存,再分发给我们的消费者!但是这个这个过程是一个耗时的过程。
惰性队列的应用场景:
消费端异常,导致MQ消息积压的时候,为避免MQ内存爆满,把消息存在磁盘中!
通过后端管理UI界面设置创建我们的惰性队列:
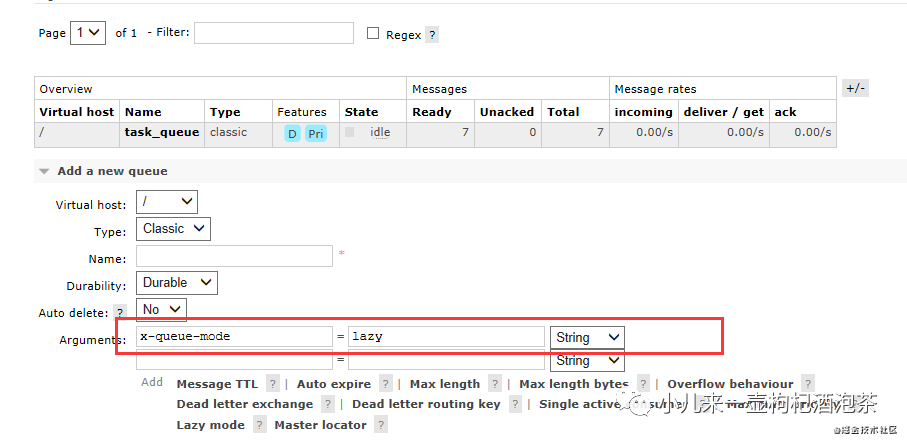
Lazy mode(x-queue-mode=lazy):Lazy Queues: 先将消息保存到磁盘上,不放在内存中,当消费者开始消费的时候才加载到内存中
通过代码的方式设置创建惰性队列:
arguments['x-queue-mode'] = 'lazy'
channel.queue_declare(queue='task_queue', durable=True,arguments=arguments,auto_delete=False)
验证持久化和惰性的:发送消息到一个没有持久化的队列中: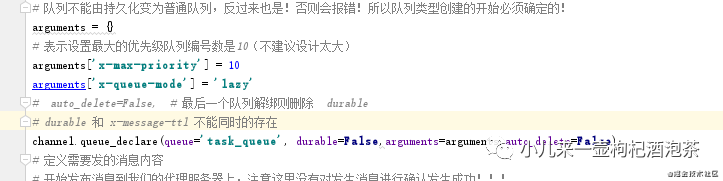
然后重启的MQ:
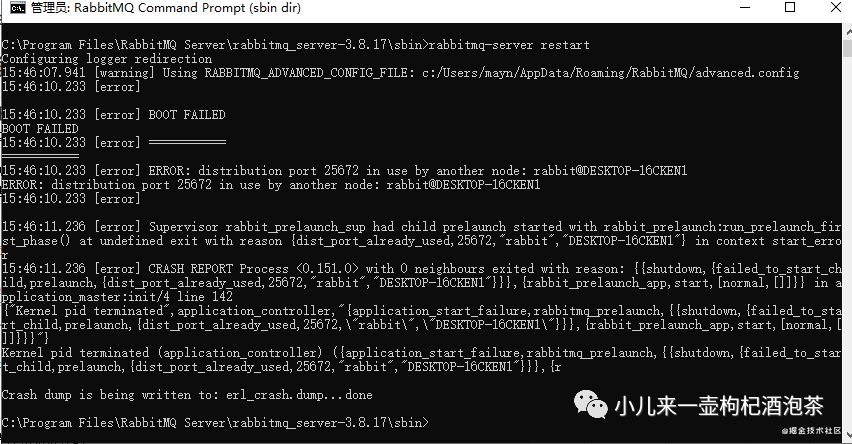
rabbitmqctl stop :停止rabbitmq
rabbitmq-server restart : 重启rabbitmq
rabbitmq-server start : 启动rabbitmq
观察队列没了!
更换另一种方式,此时我们的也把惰性+队列持久化一起启用,然后再重启MQ的话:
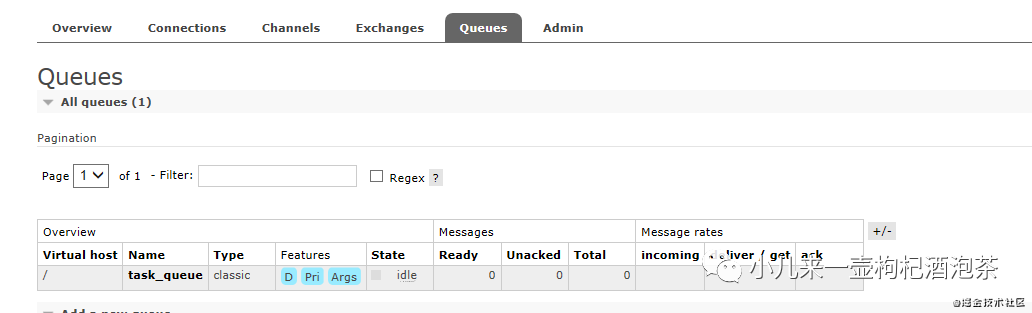
委屈了!!忘记了消息也需要持久化了!!!我们的队列是不会消息了!但是消息没了!此时再加上我们的消息也持久化再测试!

观察重启后(惰性+队列持久化—消息持久化):

惰性和普通队列的取舍:
惰性是为了减少消息对MQ内存的占用,避免相关内存不足而产生换页操作(内存和磁盘之前一种空间置换)
处理效率普通队列消息直接从内存获取,效率比惰性高
如果对效率执行要求不是很高,使用惰性的话,可以减少消息占用占用MQ内存的问题
3.2 Rabbitma 延迟队列(死信队列的延伸)
但是这里,结合上面的惰性的话,如果你的死信队列也上了一个量级的话!其实可以进一步优化我们的死信队列也是一个惰性队列,这样其实即可以减小内存占用,又可以实现消息的延迟消费!这样也是可以考虑的一种方案!
关于延迟队列!上一小节已有讲述,这里复制过来!
3.2.1 死信消息和死信队列
3.2.1.1 死信消息和死信队列定义
关于死信说明的官方文档地址为:https://www.rabbitmq.com/ttl.html#per-queue-message-ttl
需要了解的:Dead Letter Exchange 死信队列(DLX)队列的简称。
另外对于死信消息:通常如果我们的一个消息存在以下的情况下的话则这消息被称为死信消息:
1:消息被消费端拒绝,使用 channel.basicNack 或 channel.basicReject ,并且此时requeue 属性被设置为false
2:消息在队列的存活时间超过设置的TTL时间。
3:消息队列的消息数量已经超过最大队列长度,无法再继续新增消息到MQ中
4:一个队列中的消息的TTL对其他队列中同一条消息的TTL没有影响
对于死信消息的处理,Rabbitmq会依据是否配置死信队列的配置来决定消息的去留!如果开启了配置死信队列信息,则消息会被转移到这个 死信队列(DLX)中,如果没有配置,则此消息会被丢弃!
3.2.1.2 死信队列配置
官网文档:https://www.rabbitmq.com/dlx.html
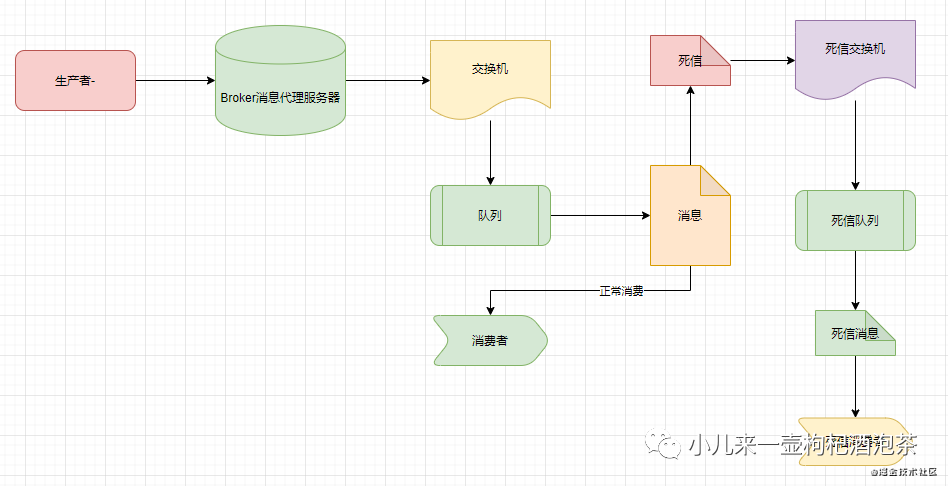
可以为每一个需要使用死信业务的队列配置一个死信交换机
每个队列都可以配置专属自己的死信队列,相关消息的进入死信队列需要经过死信交换机来进程归纳处理
死信交换机也只是一个普通的交换机,只是它是用来专门处理死信的交换机
创建队列时可以给这个队列附带一个死信的交换机,在这个队列里因各自情况出现问题的作废的消息会被重新发到附带的交换机,然后让这个交换机重新路由这条消息。
具体的图示:
若要使用策略指定DLX,请将键“死信交换”添加到策略定义中。例如:
rabbitmqctl
rabbitmqctl set_policy DLX ".*" '{"dead-letter-exchange":"my-dlx"}' --apply-to queues
Rabbitmqctl(Windows)
rabbitmqctl set_policy DLX ".*" "{""dead-letter-exchange"":""my-dlx""}" --apply-to queues
上面的策略将DLX队列“my-dlx”应用于所有队列。上面只是一个例子,实际上不同的队列可能会使用不同的死字设置(或者根本不使用)。
其他配置死信队里的方式有:
x-dead-letter-exchange:出现死信(dead letter)之后将死信(dead letter)重新发送到指定exchange
x-dead-letter-routing-key:出现死信(dead letter)之后将死信(dead letter)重新按照指定的routing-key发送
❝PS:当指定了死信交换机后时,除了通常对声明队列的配置权限外,用户还需要对该队列具有读取权限,并对死信交换机具有写权限。权限在队列声明时进行验证。
完整的一个简单的示例:
下面的示例主要是演示里:1:设置消息的过期的时间为2s,2s之后就变为我们的死信
2:变为死信的消息,会被转移到我们的另一个死信交换机的队列上
# !/usr/bin/env python
import pika
import sys
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# ========
# 创建异常交换器和队列,用于存放没有正常处理的消息。
channel.exchange_declare(exchange='xz-dead-letter-exchange',exchange_type='fanout',durable=True)
channel.queue_declare(queue='xz-dead-letter-queue',durable=True)
# 绑定队列到指定的交换机
channel.queue_bind(queue='xz-dead-letter-queue',exchange= 'xz-dead-letter-exchange',routing_key= 'xz-dead-letter-queue')
# =========
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
arguments = {}
# TTL: ttl的单位是us,ttl=60000 表示 60s
# arguments['x-message-ttl'] = 2000
# 指定死信转移到另一个交换机上具体的交换机的名称
arguments['x-dead-letter-exchange'] = 'xz-dead-letter-exchange'
# auto_delete=False, # 最后一个队列解绑则删除 durable
# durable 和 x-message-ttl 不能同时的存在
channel.queue_declare(queue='task_queue', durable=True,arguments=arguments,auto_delete=False)
# 定义需要发的消息内容
# 开始发布消息到我们的代理服务器上,注意这里没有对发生消息进行确认发生成功!!!
import time
for i in range(1,100):
time.sleep(1)
properties = pika.BasicProperties(delivery_mode=2,)
# expiration 字段以微秒为单位表示 TTL 值,6 秒的 message
properties.expiration='2000'
body = '小钟同学你好!{}'.format(i).encode('utf-8')
print(body.decode('utf-8'))
channel.basic_publish(
# 默认使用的/的交换机
exchange='',
# 默认的匹配的key
routing_key='task_queue',
# 发送的消息的内容
body=body,
# 发现的消息的类型
properties=properties# pika.BasicProperties中的delivery_mode=2指明message为持久的,1 的话 表示不是持久化 2:表示持久化
)
connection.close()
运行上面的生产者的代码后观察我们的输出:中国发出了8个消息,
小钟同学你好!1
小钟同学你好!2
小钟同学你好!3
小钟同学你好!4
小钟同学你好!5
小钟同学你好!6
小钟同学你好!7
小钟同学你好!8
结果这个8个消息都没有人去消费的时候:最后都转移到了死信的队列里面:

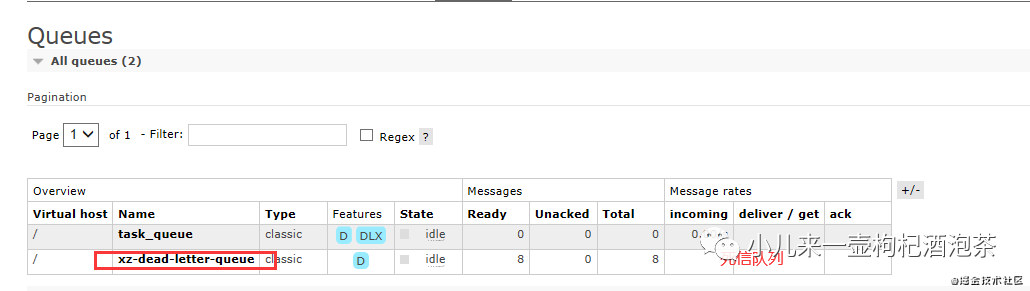
关于死信队列需要注意的点(来自官网的说明):
❝消息在发布到死信队列后DLX目标队列后会立即从原始队列中删除。这确保没有可能出现过多的消息积累,从而耗尽代理资源,但这确实意味着,如果目标队列无法接受消息,消息可能会丢失。
3.2.1.3 死信队列里面的死信的消费
当我们的死信消费者去消费死信消息时候,需要注意点有:
我们的“死信”消息消息的properties里面的header字段信息中增加一个叫做“x-death"的数组内容,包含了以下字段内容: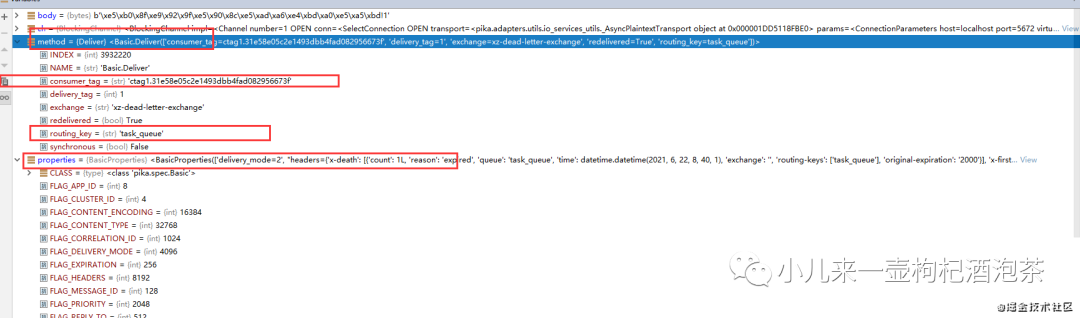
<BasicProperties(['delivery_mode=2', "headers={'x-death': [{'count': 1L, 'reason': 'expired', 'queue': 'task_queue', 'time': datetime.datetime(2021, 6, 22, 8, 40, 1), 'exchange': '', 'routing-keys': ['task_queue'], 'original-expiration': '2000'}], 'x-first-death-exchange': '', 'x-first-death-queue': 'task_queue', 'x-first-death-reason': 'expired'}"])>
其中我们的'x-death'内容为::
{'x-death': [{'count': 1L, 'reason': 'expired', 'queue': 'task_queue', 'time': datetime.datetime(2021, 6, 22, 8, 40, 1), 'exchange': '', 'routing-keys': ['task_queue'], 'original-expiration': '2000'}], 'x-first-death-exchange': '', 'x-first-death-queue': 'task_queue', 'x-first-death-reason': 'expired'}
具体每个字段的意思是:
queue :进入死信队列之前来自于哪个的消息队列名称 reason:这个消息变为死信的原因?expired 表示是因为过期!变为死信! count:这个消息在这个队列中被死了多少次 time:该消息发布时间 exchange :消息已发布到哪些交换机上,PS:如果这个消息是多次变为死信的话,这个地方最后就是死信的交换机 routing-keys 消息发不来来源的路由keys original-expiration:原消息的过期时间属性,PS:(如果消息是死信的话)每条消息ttl):。这个过期属性将从死信中删除,以防止它在被路由到的任何队列中再次过期。 x-first-death-exchange:第一次变成死死信的时候来源的交换机 x-first-death-queue:第一次变成死信的时候来源队列 x-first-death-reason:第一次变成死信的原因:expired 表示是因为过期!
其他变为死信的原因的说明:
rejected: 消息被消费者拒收且回放到消息独立
expired: 消息的设置来TTL时间到期
maxlen: 超过了队列运行的最大的值
3.2.1.4 延迟队列
RabbitMQ本身没有直接支持延迟队列功能,但是通过对死信队列和过期时间的使用,其实我们可以综合起上面的两个特性来实现一个所谓的延迟队列,延迟队列的意思就是:某个消息再某个固定的时间后失效后,则进入到死信队列里面,其他死信的消费者实时的处理这些过期的消息,这个就可以起到一个延迟处理的效果!
延迟队列加上惰性队列的组合,即可以减小内存占用,又可以实现消息的延迟处理
5 开启日志具体信息
在开发启动调试阶段,需要看到相关内置日志信息的话,通常需要开启一下日志配置(只需要在启动前配置即可):
# 配置开启的日志信息
import logging
logging.basicConfig(level=logging.INFO)
开启后可以看到具体的链接过程信息:
INFO:pika.adapters.utils.connection_workflow:Pika version 1.2.0 connecting to ('::1', 5672, 0, 0)
INFO:pika.adapters.utils.io_services_utils:Socket connected: <socket.socket fd=500, family=AddressFamily.AF_INET6, type=SocketKind.SOCK_STREAM, proto=6, laddr=('::1', 64257, 0, 0), raddr=('::1', 5672, 0, 0)>
INFO:pika.adapters.utils.connection_workflow:Streaming transport linked up: (<pika.adapters.utils.io_services_utils._AsyncPlaintextTransport object at 0x000001ED519C1080>, _StreamingProtocolShim: <SelectConnection PROTOCOL transport=<pika.adapters.utils.io_services_utils._AsyncPlaintextTransport object at 0x000001ED519C1080> params=<ConnectionParameters host=localhost port=5672 virtual_host=/ ssl=False>>).
INFO:pika.adapters.utils.connection_workflow:AMQPConnector - reporting success: <SelectConnection OPEN transport=<pika.adapters.utils.io_services_utils._AsyncPlaintextTransport object at 0x000001ED519C1080> params=<ConnectionParameters host=localhost port=5672 virtual_host=/ ssl=False>>
INFO:pika.adapters.utils.connection_workflow:AMQPConnectionWorkflow - reporting success: <SelectConnection OPEN transport=<pika.adapters.utils.io_services_utils._AsyncPlaintextTransport object at 0x000001ED519C1080> params=<ConnectionParameters host=localhost port=5672 virtual_host=/ ssl=False>>
INFO:pika.adapters.blocking_connection:Connection workflow succeeded: <SelectConnection OPEN transport=<pika.adapters.utils.io_services_utils._AsyncPlaintextTransport object at 0x000001ED519C1080> params=<ConnectionParameters host=localhost port=5672 virtual_host=/ ssl=False>>
INFO:pika.adapters.blocking_connection:Created channel=1
WARNING:pika.adapters.blocking_connection:Published message was returned: _delivery_confirmation=True; channel=1; method=<Basic.Return(['exchange=', 'reply_code=312', 'reply_text=NO_ROUTE', 'routing_key=task_queue222'])>; properties=<BasicProperties(['delivery_mode=1'])>; body_size=20; body_prefix=b'\xe5\xb0\x8f\xe9\x92\x9f\xe5\x90\x8c\xe5\xad\xa6\xe4\xbd\xa0\xe5\xa5\xbd!1'
还有错误时候的日志信息:
小钟同学你好!10
<BasicProperties(['delivery_mode=1'])>
Message was returned 1 unroutable message(s) returned
ERROR:pika.adapters.blocking_connection:confirm_delivery: confirmation was already enabled on channel=1
WARNING:pika.adapters.blocking_connection:Published message was returned: _delivery_confirmation=True; channel=1; method=<Basic.Return(['exchange=', 'reply_code=312', 'reply_text=NO_ROUTE', 'routing_key=task_queue222'])>; properties=<BasicProperties(['delivery_mode=1'])>; body_size=21; body_prefix=b'\xe5\xb0\x8f\xe9\x92\x9f\xe5\x90\x8c\xe5\xad\xa6\xe4\xbd\xa0\xe5\xa5\xbd!10'
总结:
以上是大部门代码是来自官网提供的一些简单案例,结合自己的实践做的简单的笔记!如有笔误!欢迎批评指正!感谢各位大佬!
结尾
简单小笔记!仅供参考!
❝END
❝简书:https://www.jianshu.com/u/d6960089b087
掘金:https://juejin.cn/user/2963939079225608
公众号:微信搜【小儿来一壶枸杞酒泡茶】
小钟同学 | 文 【原创】【欢迎一起学习交流】| QQ:308711822
