




之前的业务流程上处理异步的任务的都是都是基于celery+redis的方式来处理。刚巧最近一公众号的一位大佬提起关于RabbitMQ的应用的问题,也想着在我最近的业务上尝试一番,引入这个RabbitMQ.对于RabbitMQ估计许多人早已耳熟能详了吧!
这一篇的笔记也主要是为了后续在我们的fastapi里面融合我们的RabbitMQ做准备!
1 消息队列、消息中间件概念
首先关于消息队列(MQ)可能做后端的朋友大多数肯定知道它是用来做什么,主要场景在哪些地方?不过对于新手来说,可能也是一个很新的概念。这里我仅仅从我个人理解的去解释一下我对消息队列的一些认识。
消息队列其实是一种用于处理异步通信的协议方式,它可以实现进程间的或同一个进程之间不同线程的间的通讯,可以理解为是用于上下游传递消息一种方式
或者可以理解为拆分开消息队列的几个字其实它就是:消息+队列。
而这里的消息的话通常就是我们的需要处理的任务消息的抽象封装,这些消息通常被推送到一个带处理的队列里面进行排队等待被别人取出来进行消费。
那使用消息队列什么的好处呢?
异步处理,加速响应,提供web吞吐量。
应用和业务解耦,分派的消息可以提供不同机制实现的消费者,因为消息的传递是没有直接调用关系,都是依赖中间件来处理,系统侵入性不强,耦合度低。
进行流量控制,有效的削峰填谷,避免流量突刺造成系统负载过高。
消息通信,可以有点对点的通讯,也可以聊天时的通信。(py微服务框架nameko就依赖于rabbitmq)
什么消息中间件?
维基百科的解说的话则是:面向消息的系统(消息中间件)是在分布式系统中完成消息的发送和接收的基础软件。消息中间件也可以称消息队列,是指用高效可靠的消息传递机制进行与平台无关的数据交流,并基于数据通信来进行分布式系统的集成。通过提供消息传递和消息队列模型,可以在分布式环境下扩展进程的通信。
从上面可以其实有些时候说消息队列也可以说是消息中间件~
消息中间件和消息队列非要说有区别的地方的话:
消息队列是对数据处理方式的一种描述。
而消息中间件通常就是指对数据处理整个流程的所依赖一个部件一样
消息中间件:是用于对数据进行接收和存贮以及分发给消费者提供一个环境一样。
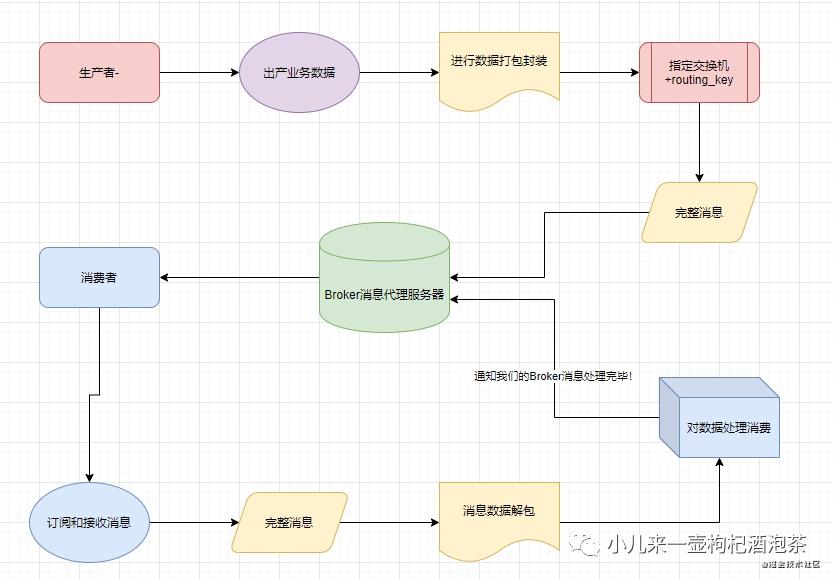
2 消息在消息队列中的流转图示
3 业界主要结构消息中间件
当前业界比较流行消息中间件几个有:
ActiveMQ(无爱)
RabbitMQ(本期的主角)
RocketMQ(有机会实践一下)
Kafka(好像也挺不错的,听说是大数据的杀手锏)
ZeroMQ 这个在py里面好像是可以的~有机会在试一试
redis 算不上是消息中间件
4:RabbitMQ主角学习
主要是它客户端支持PY! 首先在学习消息队列之前,我们应该先认识一下关于AMQP的通讯协议。之前提到过这个协议主要是一种异步通信的一些协议。
4.1 AMQP协议
来自百度百科的说明: AMQP,即Advanced Message Queuing Protocol,一个提供统一消息服务的应用层标准高级消息队列协议,是应用层协议的一个开放标准,为面向消息的中间件设计。
基于此协议的客户端与消息中间件可传递消息,并不受客户端/中间件不同产品,不同的开发语言等条件的限制。Erlang中的实现有RabbitMQ等。
AMQP协议的概念模型图:
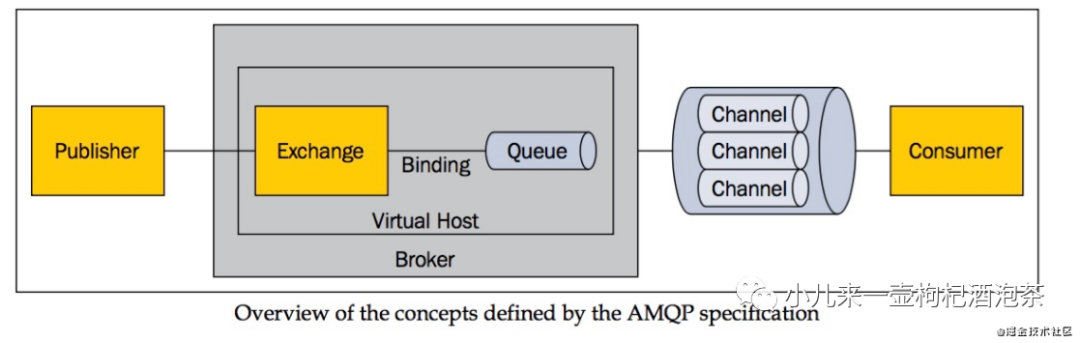
上面的图示来自网络~如有侵权!联系删除!
从上面的模型图可以看得出:
我们的 发布者--发布消息--进入到AMQP中的虚拟主机,查询需要对接的交换机Exchange,然后Exchange对应的绑定额是我们的队列queue,然后我们的消息只能存在我们的queue里面,然后等待被消费者从信道上取走我们的消息!
由此可以看得出:通常我们的AMQP消息路由有三部分组成:
队列 :消息的载体
交换器 :分发策略的定义
绑定操作:定义匹配规则,是队列和交换器的中间人。
AMQP中涉及的其他几个重要的角色:
如果你之前看过学习线程和进程中的队列相关的知识点的时候,通常会举例一个生产者和消费者的示例来说明队列的使用。而我们的AMQP也离不开这几个的概念:
消息:消息是传输的主体,通常消息包括两部分:
有效载荷(payload):要传输的具体数据内容,可以是任何内容,比如JSON串、二进制、自定义的数据协议等;
标签(label);描述了有效载荷,并且Rabbit用它来决定谁将获得消息的投递。
发布者(生产者):用于消息的创建和标签设置(在发布的时候进行标记封装打包处理)
具体的流程是:消息封装后,发送到RabbitMQ Server,MQ中的AMQP根据标签表述这条消息(一个交换器名称和可选主题标记),然后进行路由匹配后,Rabbit根据标签把消息发送给订阅的消费者。
消费者:连接到我们的消息中间件上,订阅到队列(queue),如队列中存在待消费的信息,则RabbitMQ服务器时会进行派发消息内容到消费者处,然后消费者进行消费处理。
这里结合我们的celery的来说:
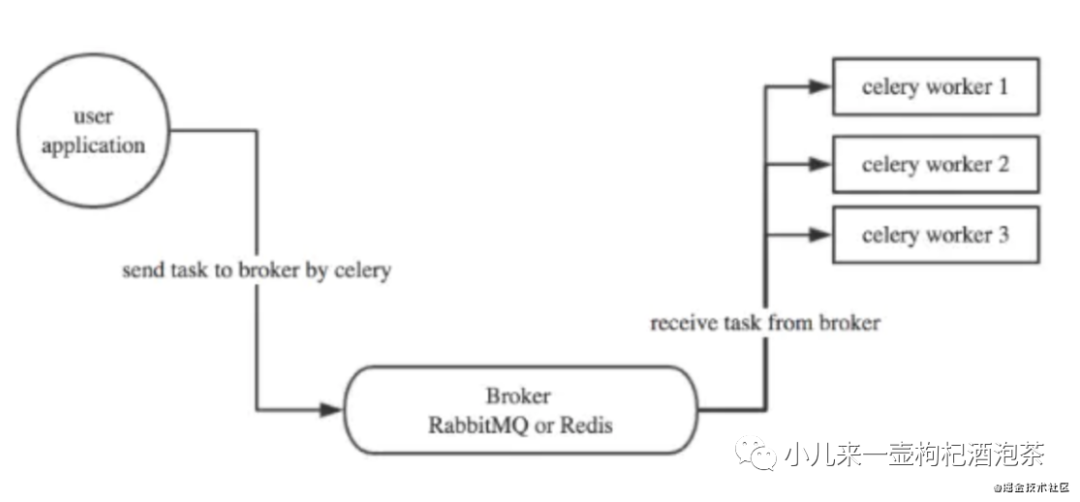
我们的RabbitMQ在上面扮演的主要是Borker的角色,对应消费启动的是一个中转的作用。
从上图可以看得出整个业务的流程是:
应用程序进行任务的task消息的派发,把任务提交到我们的Borker(生产者)
Borker消息代理者承担的task消息的存贮,然后等待别人来获取任务进行消费(消息中间件)
消费者从Borker中获取task消息进行消费(消费者)
在消费者进行任务消费的处理后,消费者会默认自动(也可以进行手动触发)通知Borker任务的处理的状态,标记任务的结果
当我们的task消息(ACK)确认后,Borker不会马上把消息从队列删除,除非是已收到了来自子消费者的确认的回执。
接下来开始正式接触RabbitMQ这个中间件。对于中间件优劣我这里不展开,比较我目前接触的也不是很多,不想翻车~哈哈
再梳理几个一些关于RabbitMQ几个词汇概念:
Product【生产者】
用于消息的生产,把消息投递到中间件上,对于的命令是:Basic.Publish
Broker【消息经纪人(代理商)】
用于消息接收和分发的应用,就是RabbitMQ的服务端就是一个应用!
Consumer【消费者】
用于消息消费处理,AMQP协议对应的命令为Basic.Consume 或者Basic. Get
Connection【连接】
用于客户端连接上我们的中间件的一个TCP连接
channel【信道】
用于减少客户机在和我们的RabbitMQ 进行Connection的时候的TCP connection 的开销,它是RabbitMQ内部基于Connectio基础上进一步封装。
Virtual Host【RabbitMQ上类似数据库中数据库名的一种】
Virtual Host 是AMQP 的基本组件组成部分之一和数据中的数据库名类似
Exchange【交换机】
消息进入队列之前的需要经过交换机,交换机根据消息的分发规则匹配查询表中的 routing key,分发消息到指定匹配的queue 中去。
Queue【队列】
消息存放的载体,消息只能被存储在队列里等待消费者去消费。
1:队列存储空间只受服务器内存和磁盘限制,它本质上是一个大的消息缓冲区。
2:多个生产者可以向同一个队列发送消息,
3:多个消费者也可以从同一个队列接收消息.
复制代码
Binding【连接exchange 和 queue】
Binding信息保存在 exchange 中的查询表中,用于 message 的匹配分发消息到不同的队列的依据。
4.2 从零记录RabbitMQ学习
纯属个人的笔记,如有翻车笔误的地方~烦请大佬指正!感激不尽!部分资料参考自网络,后续有备注出处
4.2.1 docket 快速的RabbitMQ搭建:
第一步:进行docket的加载并指定相关的端口
docker run -d --name rabbitmq --publish 5671:5671 --publish 5672:5672 --publish 4369:4369 --publish 25672:25672 --publish 15671:15671 --publish 15672:15672 rabbitmq
复制代码
第二步:进入容器配置相关的用户管理人员信息的配置(可选)
docker exec -it rabbitmq bash
# 进入容器后一样:开启WEB UI管理界面的功能:
rabbitmq-plugins enable rabbitmq_management
复制代码
第三步:用户新增和删除操作:
rabbitmqctl add_user 用户名 密码 #增加用户
abbitmqctl set_user_tags 用户名 administrator # 指定用户权限标签
guest:rabbitmqctl delete_user guest # 删除默认管理员
复制代码
4.2.2 linux 下的环境搭建
Consent7 本地安装rabbitMQ和erlang(手动下载安装包后丢到服务器再进行安装)
PS:注意下载的安装包的格式是.rpm的~
更新基本的信息系统:
yum -y update
复制代码
4.2.2.1 linux基础环境准备
以下的安装步骤手撸自【涛哥】最适合小白入门的RabbitMQ的课程-java讲解的课程!
如果之前有安装过erlang语言的,为避免版本问题,可以删除
[root@localhost ~]# yum remove erlang
Loaded plugins: fastestmirror
No Match for argument: erlang
No Packages marked for removal
[root@localhost ~]#
复制代码
安装依赖的C++编译环境
yum -y install make gcc gcc-c++ kernel-devel m4 ncurses-devel openssl-devel unixODBC unixODBC-devel httpd python-simplejson
复制代码
下载erlang和rabbitMQ的安装包
# 下载erlang
wget http://www.erlang.org/download/otp_src_20.1.tar.gz
# 下载rabbitMQ
wget https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.7.0/rabbitmq-server-generic-unix-3.7.0.tar.xz
复制代码
4.2.2.2 安装erlang
第1步:解压erlang安装包
tar -xvf otp_src_20.1.tar.gz
复制代码
第2步:进入解压文件夹
cd otp_src_20.1
复制代码
第3步:指定安装目录及安装配置(需要先安装并配置JDK)
# erlang指定安装在/usr/local/erlang目录
./configure --prefix=/usr/local/erlang --enable-smp-support --enable-threads --enable-sctp --enable-kernel-poll --enable-hipe --with-ssl --without-javac
复制代码
第4步:编译与安装
make && make install
复制代码
第5步:配置erlang环境变量
vi etc/profile
将 export PATH=$PATH:/usr/local/erlang/bin 添加到文件末尾
复制代码
第6步:重新加载profile文件
source etc/profile
复制代码
4.2.2.2 安装RabbitMQ
第1步:解压RabbitMQ安装包
PS:于下载的安装包为xz文件,先将xz解压为tar,需解压两次
先将xz解压为tar
xz -d rabbitmq-server-generic-unix-3.7.0.tar.xz
复制代码
再解压缩tar文件
tar -xvf rabbitmq-server-generic-unix-3.7.0.tar
复制代码
第2步:进入到解压的RabbitMQ的sbin目录
cd rabbitmq_server-3.7.0/sbin
复制代码
第3步 启动rabbitmq_server:
cd rabbitmq_server-3.7.0/sbin
复制代码
第4步 查看进程:
ps aux|grep rabbit
#ps a 显示现行终端机下的所有程序,包括其他用户的程序。
#ps u 以用户为主的格式来显示程序状况。
#ps x 显示所有程序,不以终端机来区分。
复制代码
第5步 启动管理界面-启动RabbitMQ的管理系统插件(需进入sbin目录):
./rabbitmq-plugins enable rabbitmq_management
复制代码
第6步 阿里云的话,注意需放行端口号:
如果没有网络指令需要先安装:yum install net-tools
查看并放行端口
netstat -tlnp
firewall-cmd --add-port=15672/tcp --permanent
firewall-cmd --add-port=5672/tcp --permanent
复制代码
或直接关闭防火墙:
CentOS7
#关闭防火墙
systemctl stop firewalld
#开机禁用
systemctl disable firewalld
#查看状态
systemctl status firewalld
复制代码
4.2.3 windos环境下单节点的 RabbitMQ搭建:
官网下载RabbitMQ(需要主要点就是版本一致问题):
.rabbitmq的下载,目前最新的版本是:3.8.17 
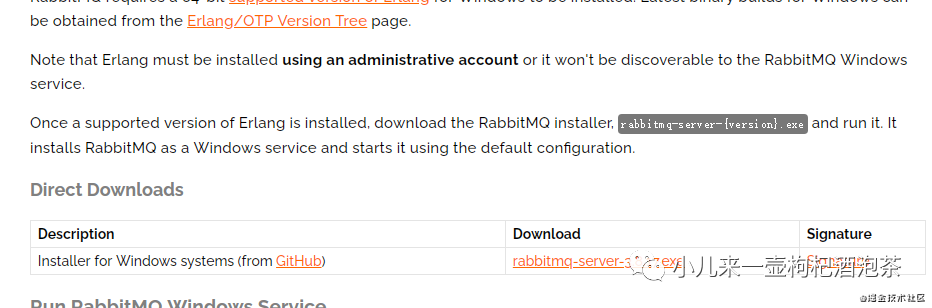
.erlang 下载 
下载地址:
https://www.rabbitmq.com/download.html
https://www.rabbitmq.com/install-windows.html
https://www.rabbitmq.com/which-erlang.html 查看对应的版本
https://www.erlang.org/downloads
复制代码
4.2.3.1 安装erlang
第一步:点击exe安装

第二步:环境变量的配置(注意我们的计算机的名称不能是中文滴) 环境配置变量细节:
在环境变量里面新建一个ERLANG_HOME的变量,值是我们的安装安装erlang的目录!
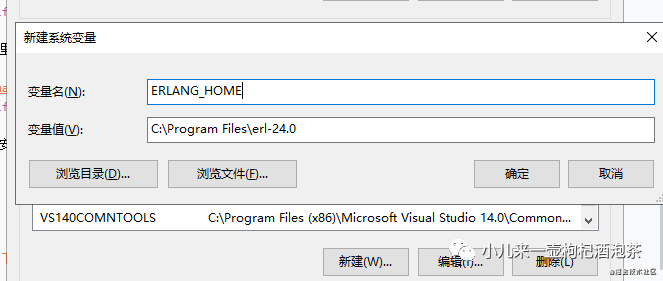
把我们的配置的环境变量添加到PATH上:
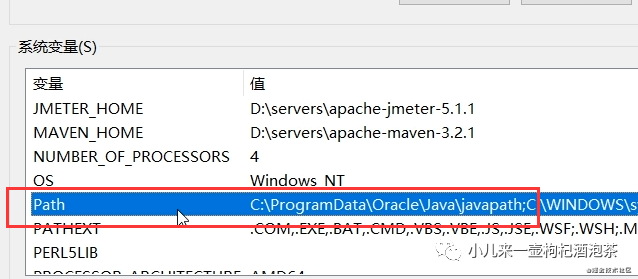
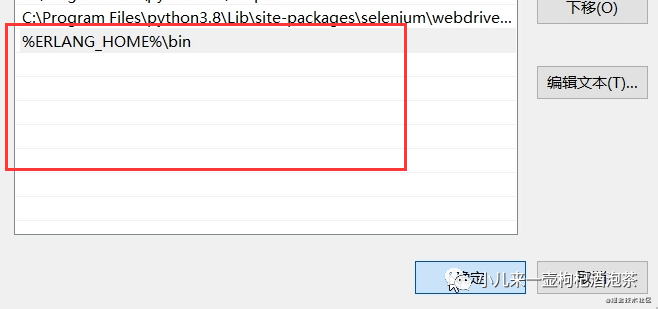
新建里添加变量:
%ERLANG_HOME%\bin
复制代码
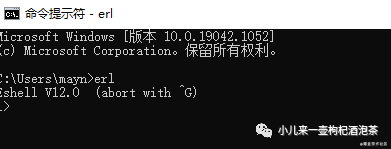
验证安装结果:
4.2.3.2 安装rabbinmq
命令行启动,然后安装管理UI界面的插件
安装插件:
C:\Program Files\RabbitMQ Server\rabbitmq_server-3.8.17\sbin>rabbitmq-plugins.bat enable rabbitmq_management
Enabling plugins on node rabbit@DESKTOP-16CKEN1:
rabbitmq_management
The following plugins have been configured:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
Applying plugin configuration to rabbit@DESKTOP-16CKEN1...
The following plugins have been enabled:
rabbitmq_management
rabbitmq_management_agent
rabbitmq_web_dispatch
started 3 plugins
复制代码
然后重启一下服务:
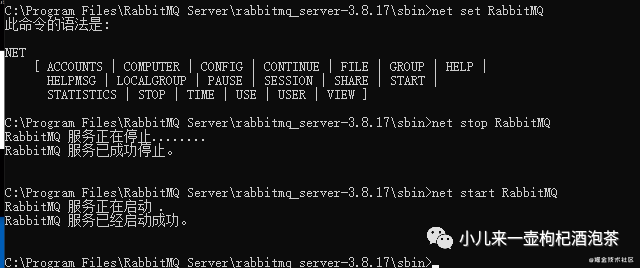
也可以直接的:
打开sbin目录,双击rabbitmq-server.bat
复制代码
相反的反过来想禁用的话:
启用web管理UI:
RabbitMQ Serverrabbitmq_server-3.8.17\sbin,输入命令rabbitmq-plugins enable rabbitmq_management
禁用web管理UI:
RabbitMQ Server\rabbitmq_server-3.8.17\sbin,输入命令 rabbitmq-plugins disable mochiweb
复制代码
启动管理界面的UI:
访问地址:http://localhost:15672/ 默认账号信息:guest guest
PS:默认生产环境肯定不能用这个用户名!即时使用你也要改密码吧!!!!不然容易被骂滴的哟!
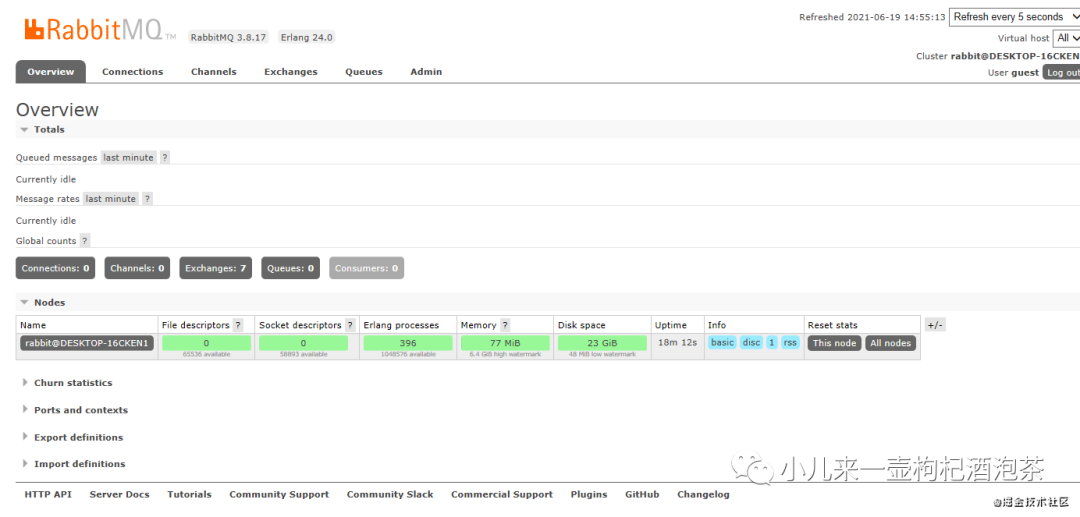
4.2.3.3 rabbinmq管理篇
用户管理包括增加用户,删除用户,查看用户列表,修改用户密码。
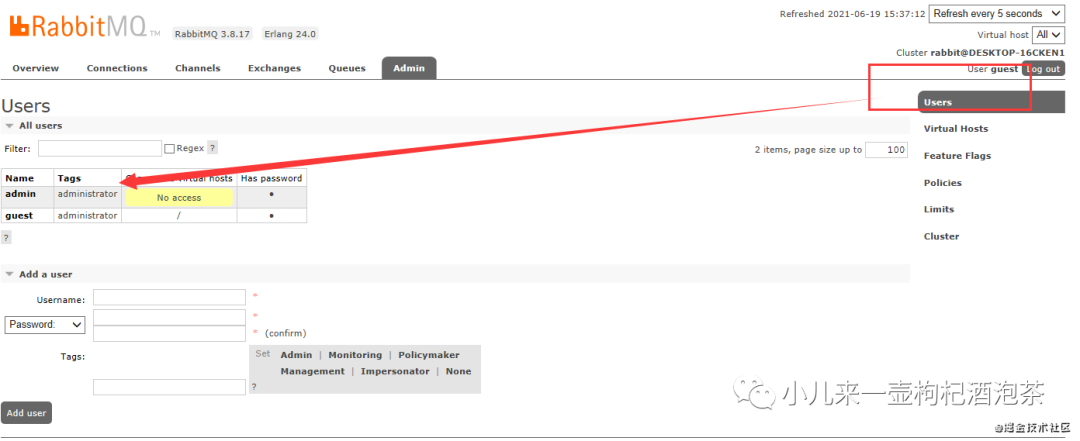
1:用户信息相关知识点:
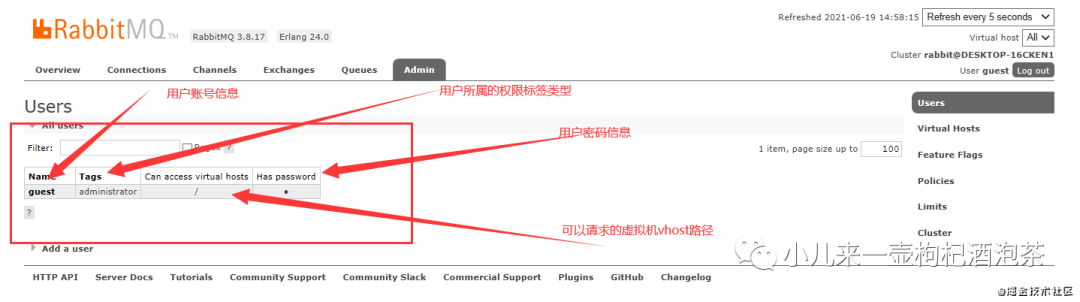
2:用户权限标签类型:
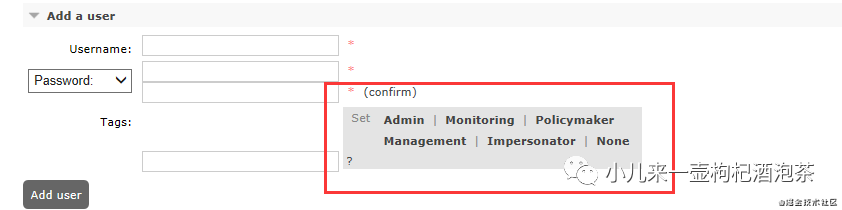
如果是设置多个角色,管理界面用,分隔,命令用空格分隔。
administrator 超级管理员的角色,拥有最高的权限,可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行相关的操作,可以完成监视所能做的一切,管理用户、vhost和权限,关闭其他用户的连接,以及管理所有vhost的策略和参数
monitoring 监控者,可以访问管理插件并查看所有连接和通道以及节点相关信息,主要是对相关的节点信息的进行监控管理和查看的权限,如进程数,内存使用情况,磁盘使用情况,队列消费情况等,
policymaker 策略制定者,可登陆管理控制台, 同时可以对policy进行管理,并管理他们有权访问的vhost的策略和参数,但是无权限查看节点信息。
management 普通管理者 仅可登陆管理控制台(启用management plugin的情况下),无法看到节点信息,也无法对策略进行管理。
impersonator 暂时未知具体的权限
none 无法登陆管理控制台,通常就是普通的生产者和消费者。
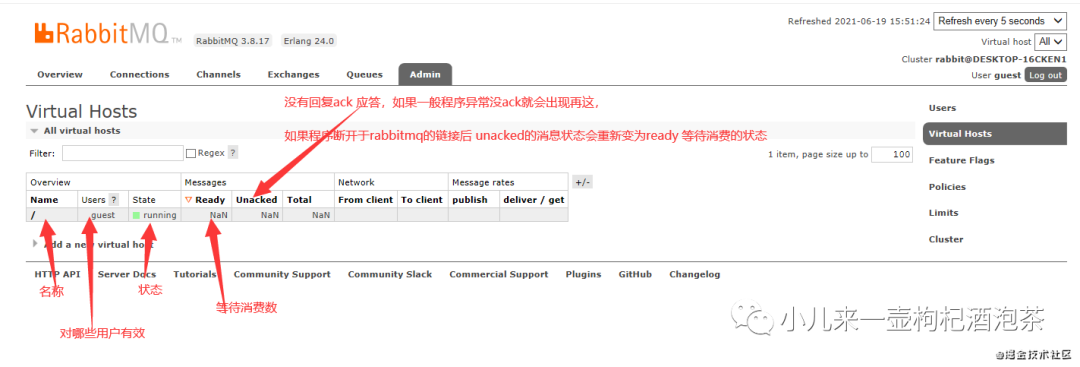
3:virtual hosts的认知:
类似reids中的数据库的ID,提供virtual hosts管理,每个vhost本质上是一个mini版的RabbitMQ服务器,可以拥有自己的connection、exchange、queue、binding以及自己的权限。
对vhost的授权管理
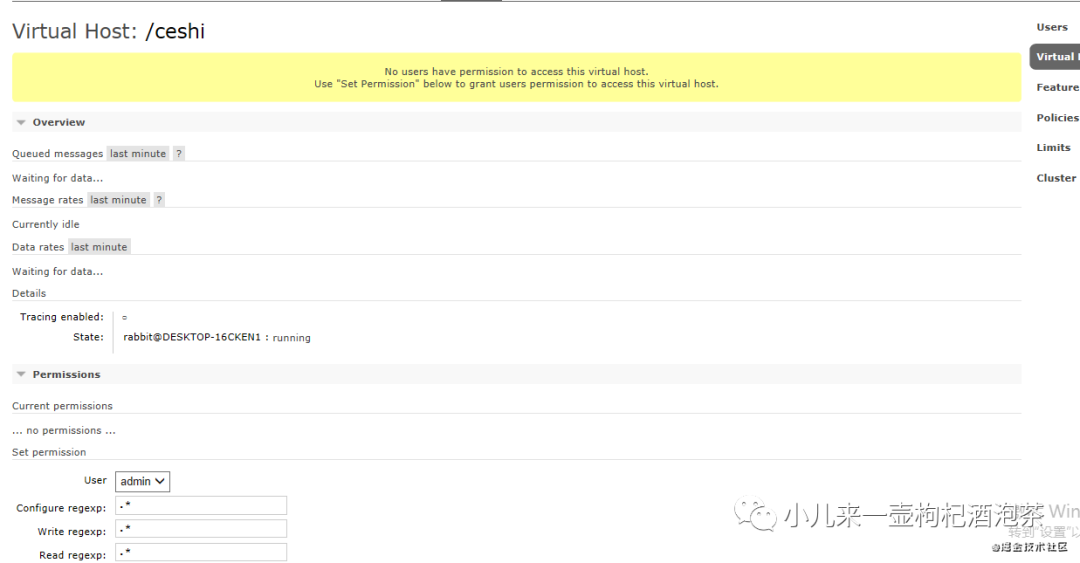
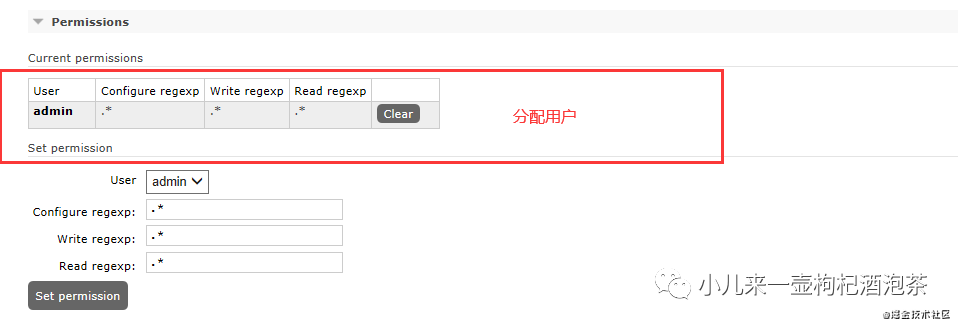

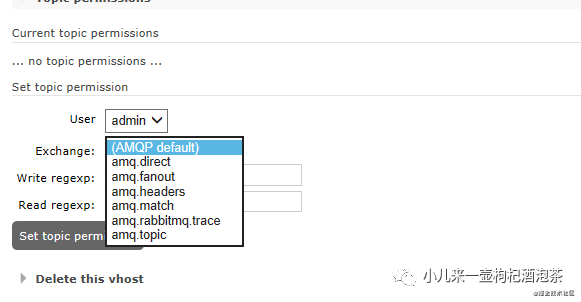
主题的模式的类型:
5 速食篇
5.1 python客户端对6种消息类型简单实践
5.1.2 客户端安装
我们的可以通过官网提供的消息类型的示例来学习,具体地址为:
首先安装一下客户端:
python -m pip install pika --upgrade
复制代码
5.1.3 几个关键方法初步了解
首先需要了解一下创建MQ关键几个函数的参数意思:
步骤1:创建连接时的登录凭证
pika.PlainCredentials(username, password, erase_on_connect)
参数:- username MQ登入账号 - password MQ登入密码 - 是否删除连接上的凭据, 默认为 False
步骤2:连接 MQ
pika.ConnectionParameters(host, port, virtual_host, credentials)
参数:- host ip - port 端口 - virtual_host, 连接的数据库一样的意思Vhost名称。默认是‘/’ - credentials 登录凭证
步骤3:阻塞式连接 MQ
pika.BlockingConnection(parameters)
参数:-parameters: 连接参数(包含主机/端口/虚拟主机/账号/密码等凭证信息)
步骤4:创建信道
pika.channel(channel_number)
参数:channel_number: 信道个数, 一般采用默认值 None
步骤5:声明队列
channel.queue_declare(callback,queue,passive,durable,exclusive,auto_delete,nowait,arguments)
参数:- callback : 当 Queue.DeclareOk 时的回调方法; 当 nowait=True 时必须为 None.
- queue=’’ : 队列名称
- passive=False : 只检查队列是否存在
- durable=False : 当 RabbitMQ 重启时,队列保持持久性
- exclusive=False : 仅仅允许当前的连接访问
- auto_delete=False : 当消费者取消或者断开连接时, 自动删除该队列
- nowait=False : 当 Queue.DeclareOk 时不需要等待
- arguments=None : 对该队列自定义键/值对
复制代码
步骤6:声明交换器
channel.exchange_declare(callback,exchange,exchange_type,passive,durable,auto_delete,internal,nowait,arguments)
参数:
- callback=None : 当 Exchange.DeclareOk 时 调用该方法, 当 nowait=True 该值必须为 None
- exchange=None: 交换器名称,保持非空,由字母、数字、连字符、下划线、句号组成
- exchange_type=‘direct’: 交换器类型
- passive=False: 执行一个声明或检查它是否存在
- durable=False: RabbitMQ 重启时保持该交换器的持久性,即不会丢失
- auto_delete=False: 没有队列绑定到该交换器时,自动删除该交换器
- internal=False: 只能由其它交换器发布-Can only be published to by other exchanges
- nowait=False: 不需要 Exchange.DeclareOk 的响应-Do not expect an Exchange.DeclareOk response
- arguments=None: 对该交换器自定义的键/值对, 默认为空
复制代码
步骤7:通过路由键将队列和交换器绑定
channel.queue_bind(callback, queue, exchange,routing_key,nowait,arguments)
参数:
callback: 当 Queue.BindOk 时的回调函数, 当 nowait=True 时必须为 None
queue: 要绑定到交换器的队列名称
exchange: 要绑定的源交换器
routing_key=None: 绑定的路由键
nowait=False: 不需要 Queue.BindOk 的响应
arguments=None: 对该绑定自定义键/值对
复制代码
步骤8:将消息发布到 RabbitMQ 交换器上
channel.basic_publish(exchange, routing_key, body, properties, mandatory, immediate)
参数:
exchange: 要发布的目标交换器
routing_key: 该交换器所绑定的路由键
body: 携带的消息主体
properties=None: 消息的属性,即文本/二进制等等
mandatory=False: 当 mandatory 参数设置为 true 时,交换机无法根据自身的路由键找到一个符合的队列,那么 RabbitMQ 会调用 Basic.Return 命令将消息返回给生产者,当 mandatory 参数设置为 false 时,出现上述情况,消息会被丢弃
immediate=False: 立即性标志
复制代码
步骤9:从队列中拿到消息开始消费
channel.basic_consume(consumer_callback, queue, no_ack, exclusive, consumer_tag, arguments)
参数:
consumer_callback: 当要消费时,调用该回调函数 consumer_callback, 函数的参数有channel, method, properties,body
queue=’’: 要消费的消息队列
no_ack=False: 自动确认已经消费成功
exclusive=False: 不允许其它的消费者消费该队列
consumer_tag=None: 指定自己的消费标记
arguments=None: 对该消费者自定义设置键值对
复制代码
步骤10:消息确认
channel.basic_ack()
参数:
delivery_tag=0 : 服务端分配的传递标识
multiple=False: 是否批量的确认回复,通常是false
复制代码
步骤11:取消消费, 该方法不会影响已经发送的消息,但是不会再发送新的消息给消费者
channel.basic_cancel(callback, consumer_tag, nowait)
参数:
callback=None : 当 Basic.CancelOk 响应时的回调函数; 当 nowait=True 时必须为 None. 当 nowait=False 时必须是可回调的函数
consumer_tag=’’: 消费标识
nowait=False : 不期望得到 Basic.CancelOk response
复制代码
步骤12:处理 I/O 事件和 basic_consume 的回调, 直到所有的消费者被取消,用于消费者端的启动
channel.start_consuming()
参数:
callback=None : 当 Basic.CancelOk 响应时的回调函数; 当 nowait=True 时必须为 None. 当 nowait=False 时必须是可回调的函数
consumer_tag=’’: 消费标识
nowait=False : 不期望得到 Basic.CancelOk response
复制代码
步骤13:拒绝单条消息
channel.basic_reject(delivery_tag, requeue=True)
参数:
delivery_tag : 传递标签
requeue=True : 是否重新放回到队列中去
示例:
channel.basic_reject(delivery_tag=method.delivery_tag, requeue=False)
复制代码
步骤14:拒绝单条或者多条消息
channel.basic_nack(delivery_tag=None, multiple=False, requeue=True)
参数:
delivery_tag=None : 传递标签
multiple=False : 是否批量,即多条消息
requeue=True: 是否重新放回到队列中去
示例:
channel.basic_nack(delivery_tag=method.delivery_tag, requeue=True)
print('将当前消息重新放入队列中')
复制代码
步骤15:删除已声明的交换器
channel.exchange_delete(callback=None,exchange=None,if_unused=False,nowait=False)
参数:
callback=None: 删除回调,nowait=True,指必须是Node
exchange=None: 交换机的名称
if_unused=False: 是否只删除哪些不可用的交换机
nowait=False: 是否异步执行删除
复制代码
步骤16:发送消息的属性
pika.BasicProperties()
参数:
content_type=None,
content_encoding=None,
headers=None,
delivery_mode=None, 声明信息持久化, 使信息持久化,需要声明queue持久化和delivery_mode=2信息持久化
priority=None,
correlation_id=None,
reply_to=None,
expiration=None,
message_id=None,
timestamp=None,
type=None,
user_id=None,
app_id=None,
cluster_id=None
复制代码
设置形式:
msg_props = pika.BasicProperties()
msg_props.content_type = 'text/plain'
复制代码
步骤17:回调函数
callback
参数:
channel: 包含channel的一切属性和方法
method: 包含 consumer_tag, delivery_tag, exchange, redelivered, routing_key
properties: basic_publish 通过 properties 传入的参数,包含信息的一些附加属性
body: basic_publish发送的消息
复制代码
步骤18:预取消息数
channel.basic_qos(prefetch_size=0, prefetch_count=0, global_qos=Fals)
参数:
prefetchSize:0 单条消息的大小限制。0 就是不限制,一般都是不限制。
prefetchCount: 设置一个固定的值,告诉 rabbitMQ 不要同时给一个消费者推送多余 N 个消息,即一旦有 N 个消息还没有 ack,则 consumer 将block 掉,直到有消息 ack。
global:truefalse 是否将上面的设置用于 channel,也是就是说上面设置的限制是用于 channel 级别的还是 consumer 的级别的。
复制代码
5.1.4 第1种:边发和边收,生产者消费者模型
消息模型:
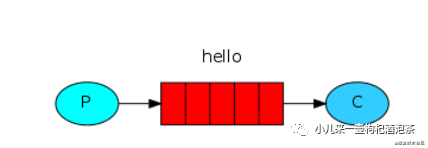
连接方式使用URLParameters的AMQP方式:
def __init__(self, conn_str='amqp://user:pwd@host:port/%2F'):
self.exchange_type = "direct"
self.connection_string = conn_str
self.connection = pika.BlockingConnection(pika.URLParameters(self.connection_string))
复制代码
发生端Send.py
import pika
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 创建信道对象
channel = connection.channel()
# 在发送之前,我们需要确保收件人队列的存在。如果我们向不存在的位置发送消息,RabbitMQ将直接删除该消息。让我们创建一个你好将消息传递到的队列:
# 并且会抛出异常信息# pika.exceptions.ChannelClosedByBroker: (404, "NOT_FOUND - no queue 'hello' in vhost '/'")
# 创建队列(声明队列)名称--这里默认使用的是空的由空字符串标识的默认交换机
channel.queue_declare(queue='hello',passive=True,exclusive=True)
# queue_declare 的几个参数说明:
# queue :队列名称
# passive :是否被动的 如果这个是True,那么如果我们的队列不存在的话,启动消费者 会直接的抛出异常,默认为false的,如果队列不存在的话,也不会报异常
# durable :消息队列是否是持久化, True开启 false关闭:关闭的话,如果重启RABBIT,所有的队列消息会丢失,
# exclusive 设置是否排他,队列是否是独占模式 ,独占模式是指当前的队列只限于当前的链接,如果连接断开,其他也无法来使用此队列
# auto_delete :是否自动删除队列中的消息,trued--》链接一旦断开则删除消息
# arguments 其他外的参数
# 开始进行发布消息的字符串为空的交换机上,然后匹配通过routing_key=hello精确的指定发送给哪个队列
import time
for i in range(1,1000):
time.sleep(1)
channel.basic_publish(exchange='', routing_key='hello',body='小钟同学你好!{}'.format(i).encode('utf-8'))
print("已经发送了消息")
# 程序退出前,关闭链接
connection.close()
print("已经发送了消息")
# 程序退出前,关闭链接
connection.close()
复制代码
运行上面的示例后,观察我们的后台,新增了待消费的消息
可能遇到的异常问题是:
问题1:
pika.exceptions.ChannelClosedByBroker: (404, "NOT_FOUND - no queue 'hello' in vhost '/'")
在虚拟机为in vhost '/'"找不对队列名称
现象:通常需要先启动消费者来创建我们的队列先,如果是生产者先启动的时候,按理应该也是可以,但是此次竟然异常!
复制代码
问题2:
pika.exceptions.ChannelClosedByBroker: (405, "RESOURCE_LOCKED - cannot obtain exclusive access to locked queue 'hello' in vhost '/'
这个很我们的设置队列的属性passive值为false和True有关
复制代码
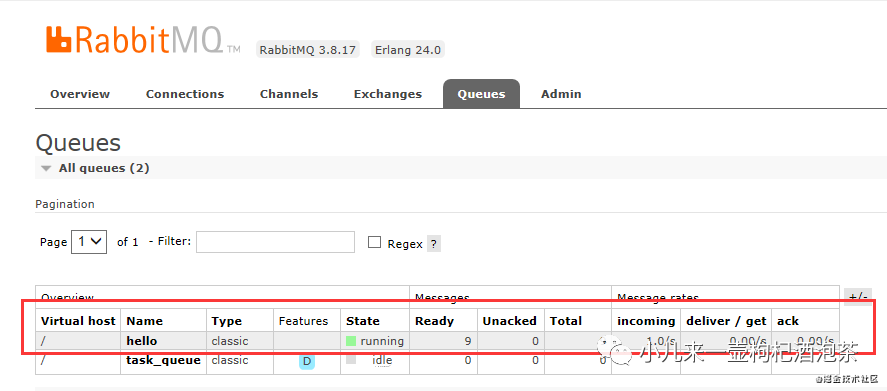 关于状态值的几个说明:
关于状态值的几个说明:
然后启动我们的消费端Receive.py:
#!/usr/bin/env python
import pika, sys, os
def main():
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest", "guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))
# 创建信道对象
channel = connection.channel()
# 创建队列(声明队列)名称--这里默认使用的是空的由空字符串标识的默认交换机
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body):
print('ch', ch)
print('properties',properties)
print(" [x] Received %r" % body.decode('utf-8'))
# 订阅我们的某个队列的发送的消息
# auto_ack 是否自动的确认
# 消息接收的处理
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=True)
# 保持的启动,一直监听
print(' [*] Waiting for messages. To exit press CTRL+C')
# 消费者会阻塞在这里,一直等待消息,队列中有消息了,就会执行消息的回调函数
channel.start_consuming()
if __name__ == '__main__':
try:
main()
except KeyboardInterrupt:
print('Interrupted')
try:
sys.exit(0)
except SystemExit:
os._exit(0)
复制代码
启动了之后,就可以开始进行相关消息的消费了!
上面消费端的示例是自动进行ack确认,但如果我们的消费端处理消息过程出现了异常的的话,这种自动ack机制会存在问题,所以可以改为手动ack的模式,修改后的代码如下:
····只贴关键的部分~
def callback(ch, method, properties, body):
print('ch', ch)
print('properties',properties)
print(" [x] Received %r" % body.decode('utf-8'))
# 手动的进行ack ,MQ收到这个ack就会删除消息,标记任务完成
ch.basic_ack(delivery_tag=method.delivery_tag)
# 订阅我们的某个队列的发送的消息
# auto_ack 是否自动的确认
# 消息接收的处理
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=False)
····
复制代码
这时候我们可以观察具体消费情况:
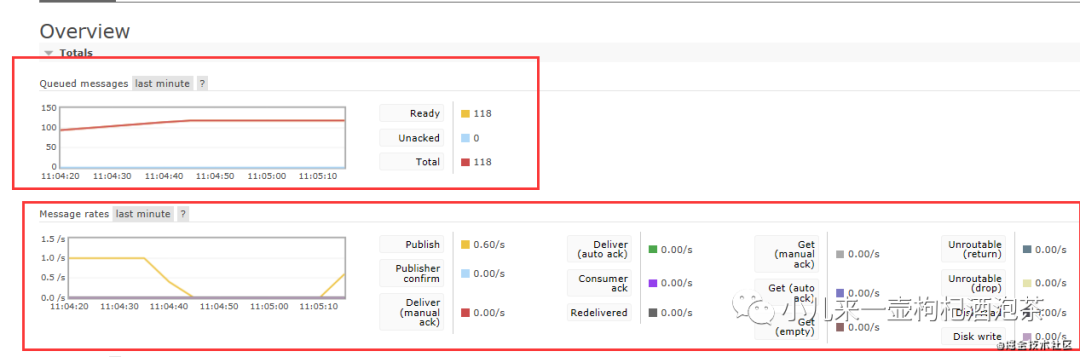
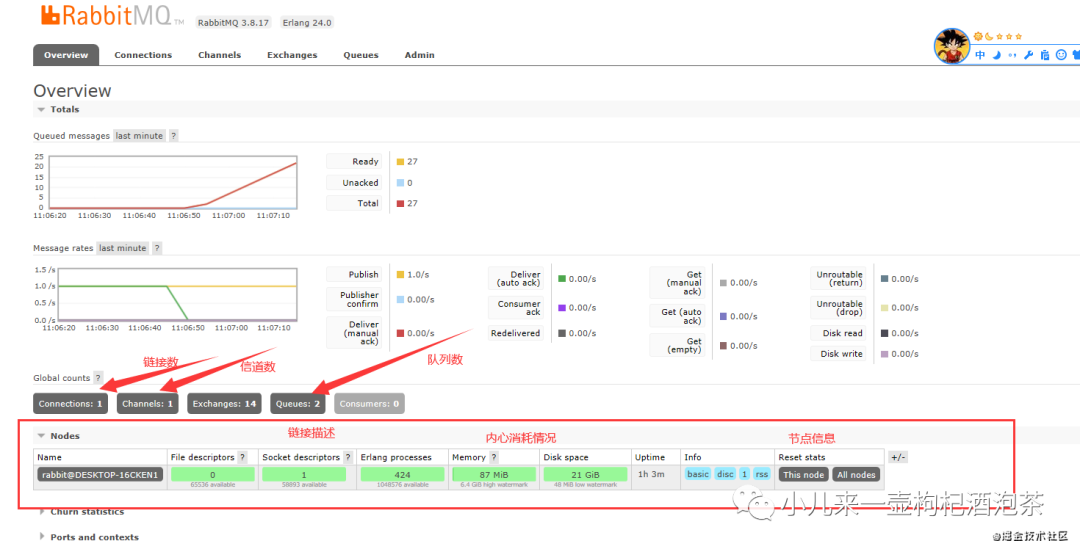
主要关注的点:
PS:RabbitMQ不允许您重新定义具有不同参数的现有队列
上面的示例中默认创建队列的时候一些参数说明,需要注意一些点有:
1:消费端是否开启自动的确认,这个也看你的业务而定,设置auto_ack为true,只要消费者接收到消息,就自动视为确认,如果,是false则需要自己收到的发送确认,通常如果你需要进行业务处理异常捕获处理的话,建议是进行手动的回复确认,因为我们的业务逻辑处理的时候,接收到不代表业务逻辑处理成功,而我们的rabitmq端接收到确认后,会从队列中删除对应消息。(纠正之前的翻车说法)
2:另外还有一种,如果你接到消息,但是不想对这个消息进行消费的话,应该怎么处理呢?这个暂时还没了解,后续再看看~
3:上面的示例没有对诸如连接管理、错误处理、连接恢复、并发和度量集合等主题进行相关的处理,后续使用的地方需要注意~
还需要考虑的有:
消息发生的可靠性,如何确认消息已发生到了我的代理服务器上,发生消息的异常回滚处理
消费端的批量ack
可以从这里去扩展了解: www.rabbitmq.com/confirms.ht…
5.1.5 第2种:Work模式
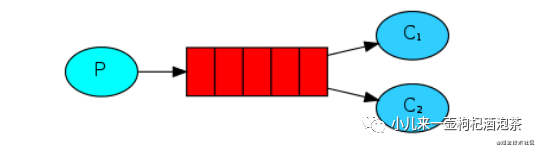
也就是说这种模式的消息下,我们消息可以被多个订阅的消费者,进行消费!但是不是消费同一个~ 但是这种模式下的,多消费者的对消息的消费方式又可以分为两种:
一种是平均分派模式(平均分配) 这种模式下的消费者获取消息的是必须等待没一个消费者完成分配的任务之后才可以继续发送下一个消息:比如:给A分配任务,可能需要耗时10秒,给B分配任务,可能只需要5秒,当B优先于A完成消息的消费的话,此时也不会马上的到新的消息去消费,必须等待A的10秒的消息处理完成后,先分给A新的10秒的任务,再分给B~
一种是能者多劳模式(指定每个消费者的预取消息消费数) 这种模式下,消费者的消费模式就是,各凭本事,能者多接任务进行消费。不需要等待!
消费模型图示:
关于平均分配模式示例:
# !/usr/bin/env python
import pika
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("guest", "guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!
channel.queue_declare(queue='task_queue', durable=True)
# 定义需要发的消息内容
message = ' '.join(sys.argv[1:]) or "Hello World!"
# 开始发布消息到我们的代理服务器上,注意这里没有对发生消息进行确认发生成功!!!
channel.basic_publish(
# 默认使用的/的交换机
exchange='',
# 默认的匹配的key
routing_key='task_queue',
# 发送的消息的内容
body=message,
# 发现的消息的类型
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
))
print(" [x] Sent %r" % message)
# 关闭链接
connection.close()
复制代码
然后定义我们的其他多个消费端,可以启动多个观察具体消费情况:
# !/usr/bin/env python
import pika
import time
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest", "guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
channel.queue_declare(queue='task_queue', durable=True)
print(' [*] 平均分配模式处理. To exit press CTRL+C')
#
def callback(ch, method, properties, body):
print(" [x] Received %r" % body.decode())
# 模拟消息消费的耗时1秒的任务
time.sleep(1)
print(" [x] Done")
# 默认开始的是需要手动的ack
ch.basic_ack(delivery_tag=method.delivery_tag)
# 暂时不设置预取消息数量
# channel.basic_qos(prefetch_count=1)
# 开始进行订阅消费
channel.basic_consume(queue='task_queue', on_message_callback=callback)
# 消费者会阻塞在这里,一直等待消息,队列中有消息了,就会执行消息的回调函数
channel.start_consuming()
复制代码
另一个消费者示例,则主要区别是
# 模拟消息消费的耗时2秒的任务
time.sleep(2)
复制代码
此时,为观察效果,我们优先启动我们的两个消费者,再启动生产者:
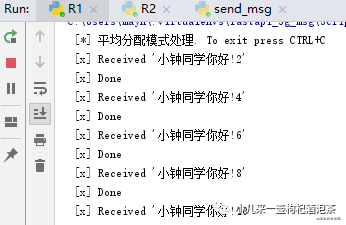
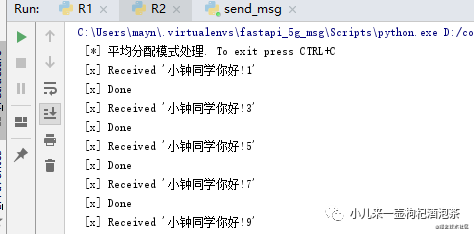
消费者两个是奇偶数的模式进行获取消息,竟然个人的处理能力不一样,但是还是需要等待!所以为优化这种模式,能者多劳!可以加上
#不设置预取消息数量
channel.basic_qos(prefetch_count=1)
# 开始进行订阅消费
channel.basic_consume(queue='task_queue', on_message_callback=callback)
# 消费者会阻塞在这里,一直等待消息,队列中有消息了,就会执行消息的回调函数
channel.start_consuming()
复制代码
此时再观察我们的消费情况:为方便观察可以先删了队列:

具体修改后的情况:
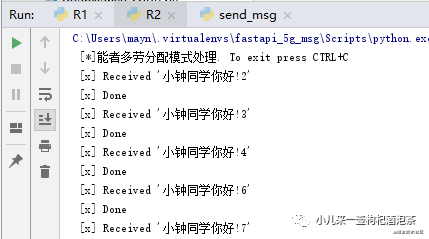
R1设置消费消息的耗时任务为需要3秒,R2为1秒,则此时下面的消费情况如下:
R1:
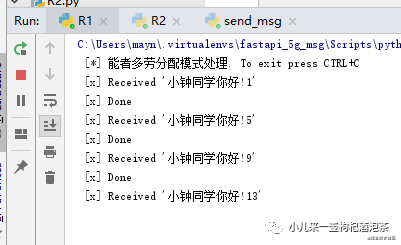
R2:
5.1.6 第3种:发布/订阅-同时向许多消费者发送信息模式
前面的两个示例,我们默认使用的都是exchange 为空字符串的交换机,且没有指定这个交换机的类型。
消息默认的轨迹都是都是经过exchange 为空字符串的的交换机,再到我们的创建的队列中
一个完整的消息传递模型应该是:
生产者只能将消息发送到交换机
交换机接收处理来自生产者的消息,另一方面,它将消息推送到队列中。
关于交换机:交换必须确切地知道如何处理接收到的消息。它是否应该附加到特定的队列中?它是否应该附加到多个队列中?或者它应该被丢弃?
对于我们定于广播模式这种模式的下,意思就是类似的广播的形式,我的一个消息可以同时的发布给所有的订阅者,所有的订阅了这个频道,都可以接受此消息的分派机会。
但是这种广播模式,队列的名称是随机的生成的,只有消费端启动了!才会去产生对应队列的名称,并且随着消费端的断开,队列也会随之删除!
广播模式的模型(只会广播消息,消息不会进行储存,过后不期!): 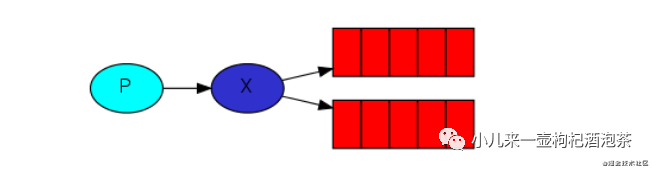
这种模型下有分几种广播模式:
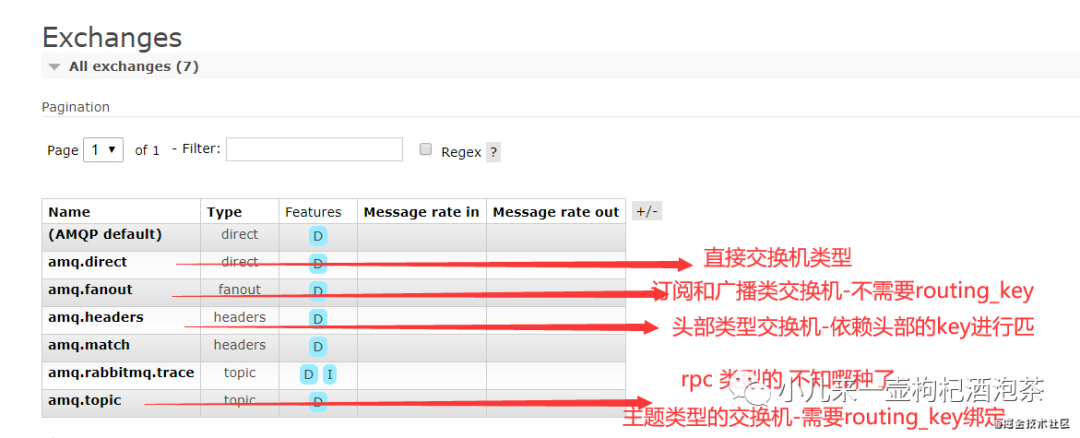
对于交换机的类型主要有几种:
direct 直接交换机类型,也可以理解是组播模式
topic 主题类型的交换机,也可以理解为规则匹配模式广播
headers 头部key传递匹配类型的交换机
fanout 纯广播模式。
关于fanout 纯广播模式的示例:
广播消息端send.py:
import pika
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 创建频道
channel = connection.channel()
# 这里是广播,不需要声明queue
channel.exchange_declare(exchange="ceshilog", # 声明广播管道
# 声明交换机类型是纯广播类型
exchange_type="fanout")
import time
for i in range(1,1000):
time.sleep(1)
channel.basic_publish(exchange="ceshilog",
routing_key="", # 此处为空,必须有
body='fanout纯广播模式-小钟同学你好!{}'.format(i).encode('utf-8'),
# 数据持久化,下面的这句无效
# properties=pika.BasicProperties(delivery_mode=2)
)
print("消息发送完成")
connection.close()
复制代码
上面的示例,我们的启动后,一直再广播数据出去,谁订阅就可以谁就可以接受!
消息订阅端r1.py:
import pika
# 建立与rabbitmq的连接
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
channel = connection.channel()
channel.exchange_declare(exchange="ceshilog", exchange_type="fanout")
# 不需要指定queue名字,启动消费端后,rabbit会随机分配一个名字
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(queue="", exclusive=True)
#这里不定义名字,通过exclusive=True生成一个名字不重复的队列
# 获取随机的queue名字
queue_name = result.method.queue
print("当前随机的队列名称是:", queue_name)
channel.queue_bind(exchange="ceshilog", queue=queue_name) # queue绑定到转发器上
def callback(ch,method,properties,body):
print("收到广播消息为:%r"%body.decode("utf8"))
# auto_ack设置为False
channel.basic_consume(queue_name,callback,True)
# 开始消费,接收消息
channel.start_consuming()
复制代码
上面的订阅端可以启动多个。
此时我们启动三个观测: 对应的三个接受广播的消费者产生的队列:
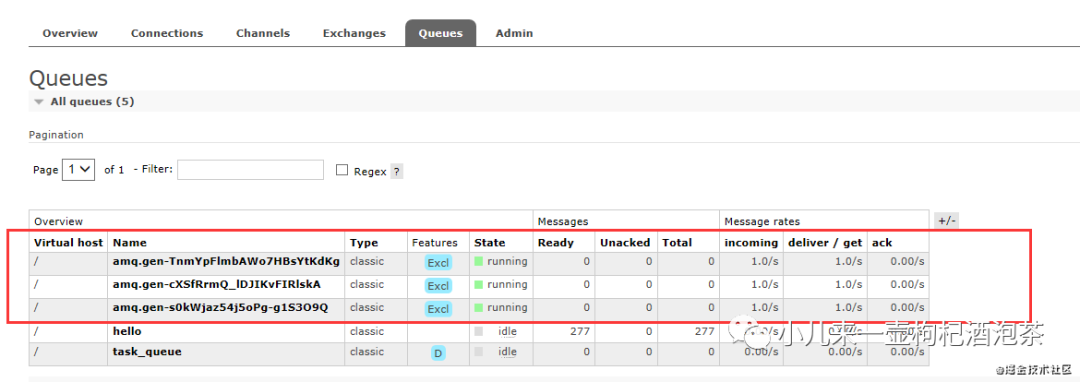 三端后端的广播消息都是一致的:
三端后端的广播消息都是一致的:
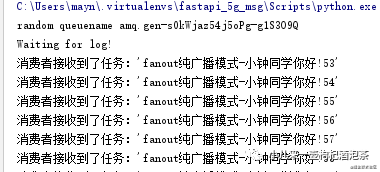
观察我们的信道,此时有四个,一个是发送三个是接收:
链接情况:
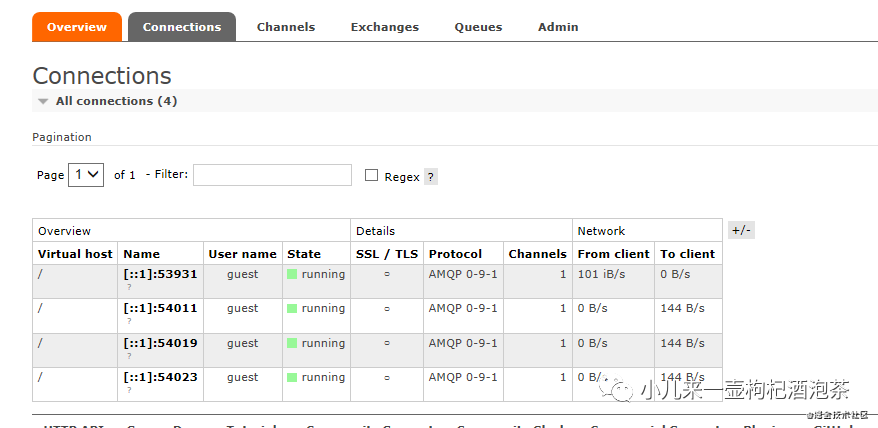
信道情况:
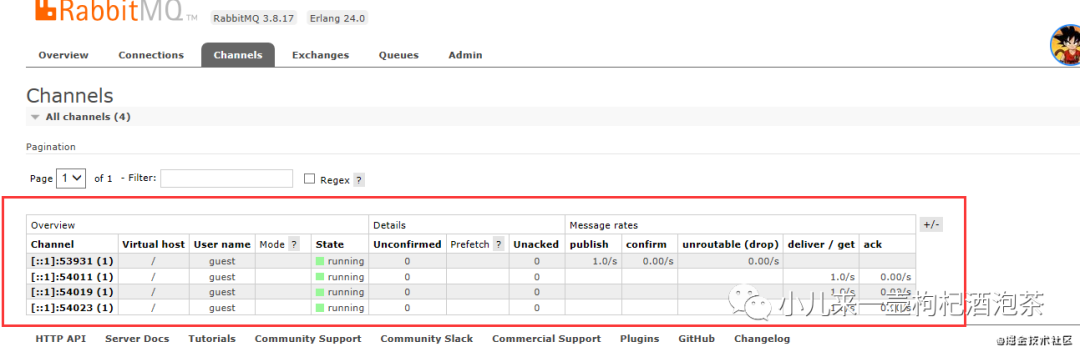
交换机的情况:
此时如果断开某个消费者后,我们的队列也会随之删除,只剩下两个~:
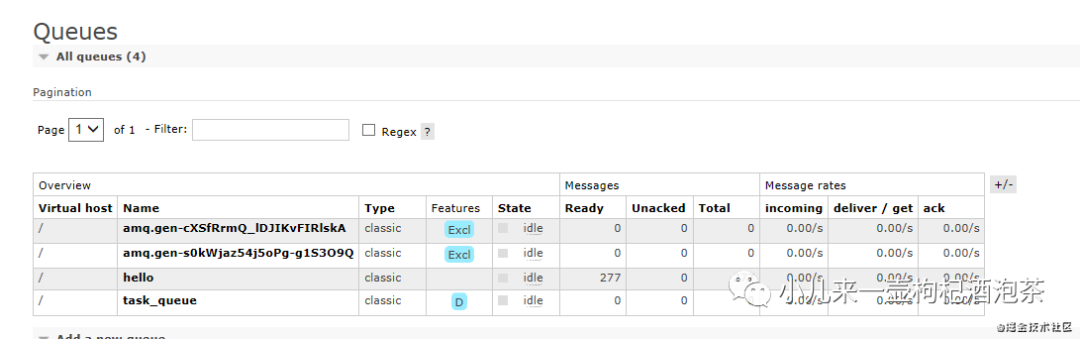
在这种消息的模式下,我们的交换机和队列之间存在一种关系,叫做绑定!因为它需要明确告诉我们的交换机应该绑定哪个队列,把消息发生哪个队列上去进行处理!但是注意的点:它的绑定不需要依赖routing_key,意思就是routing_key可以等于=‘’。
PS:可以使用 rabbitmqctl list_bindings 命令列举出所有的绑定
甚至你还可以查看当前的对于的绑定额信息:
没有启动消费者前:

启动消费者后:
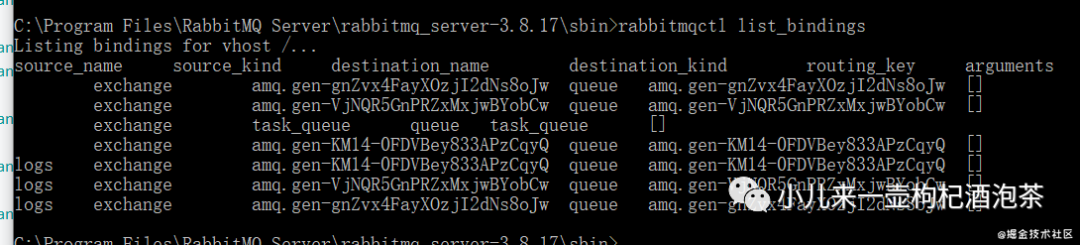
C:\Program Files\RabbitMQ Server\rabbitmq_server-3.8.17\sbin>rabbitmqctl list_bindings
Listing bindings for vhost ...
source_name source_kind destination_name destination_kind routing_key arguments
exchange amq.gen-gnZvx4FayXOzjI2dNs8oJw queue amq.gen-gnZvx4FayXOzjI2dNs8oJw []
exchange amq.gen-VjNQR5GnPRZxMxjwBYobCw queue amq.gen-VjNQR5GnPRZxMxjwBYobCw []
exchange task_queue queue task_queue []
exchange amq.gen-KM14-0FDVBey833APzCqyQ queue amq.gen-KM14-0FDVBey833APzCqyQ []
logs exchange amq.gen-KM14-0FDVBey833APzCqyQ queue amq.gen-KM14-0FDVBey833APzCqyQ []
logs exchange amq.gen-VjNQR5GnPRZxMxjwBYobCw queue amq.gen-VjNQR5GnPRZxMxjwBYobCw []

C:\Program Files\RabbitMQ Server\rabbitmq_server-3.8.17\sbin>
复制代码
5.1.7 direct组播-路由模式
direct组播-路由模式,-根据交换机rouing_key有选择地接收消息模式
根据路由的key来匹配消息的队列,这种模式下的,交换机是定位一种直接的交换机的类型,但是这种类型的交换机下,又同时的可以有扇形的交换机的特性,也即使多重绑定,就是绑定多个的匹配的routing_key,意思就是可以多个来routing_key来绑定同一个队列! 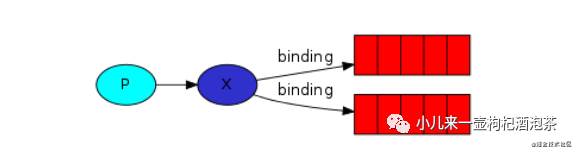
组播模式下的广播,我们对应的消费者只会去匹配属于自己的规则消息。
如发送端send.py:
import pika
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 创建频道
channel = connection.channel()
# 这里是广播,不需要声明queue
channel.exchange_declare(exchange="direct_ceshilogs", # 声明广播交换机名称
# 指定为组播类似的交换机
exchange_type="direct")
# 重要程度级别,这里默认定义为 info---手接受命令行的参数值信息,
# 多个值使用空格分开:比如 info error
severity = sys.argv[1] if len(sys.argv)>1 else 'info'
import time
for i in range(1, 1000):
time.sleep(1)
channel.basic_publish(exchange="direct_ceshilogs",
routing_key=severity, # 此处为空,必须有
body='fanout纯广播模式-小钟同学你好!{}'.format(i).encode('utf-8'),
# 数据持久化,下面的这句无效
# properties=pika.BasicProperties(delivery_mode=2)
)
print("发送的了!消息")
connection.close()
复制代码
接收端r1.py:
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import pika
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 创建频道
channel = connection.channel()
# 生产者和消费者端都要声明队列,以排除生成者未启动,消费者获取报错的问题
channel.exchange_declare(exchange="direct_ceshilogs", exchange_type="direct")
# 不指定queue名字,rabbit会随机分配一个名字
# exclusive=True会在使用此queue的消费者断开后,自动将queue删除
result = channel.queue_declare(queue="", exclusive=True)
# 获取随机的queue名字
queue_name = result.method.queue
print("随机队列的名称:", queue_name)
severities = sys.argv[1:]
# 如果启动的时候,默认的没有携带相关的参数,则默认的 我需要兼容的是三个的规routing_key的规则
if not severities:
# 提示必须指定的需要监听的规则路由key---所以需要使用命令启动行输入的方式启动监听
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1)
# 循环列表去绑定
for severity in severities:
print(severity)
channel.queue_bind(exchange='direct_ceshilogs', queue=queue_name, routing_key=severity)
def callback(ch,method,properties,body):
# 消息回调
print(" 收到广播消息为:对应的routingkey为:%r:%r" % (method.routing_key, body))
# auto_ack设置为False
channel.basic_consume(queue_name,callback,True)
# 开始消费,接收消息
channel.start_consuming()
复制代码
此时先启动启动我们的消费端,需要从命令行接收我们的设置的routing_key规则, 所以其的时候,使用命令行的方式启动:或者直接的写死代码也行:
启动一个只监听routing_key= info的消费者:
(fastapi_xxx) D:\code\python\local_python\fastapi_xx_msg\rabbitmqtest\test4>python r1.py info
随机队列的名称:amq.gen-Ruv_66fZoKBvDqgYyN52SQ
info
复制代码
启动另一个同事监听routing_key= info 和 error 的消费者:
(fastapi_xxx) D:\code\python\local_python\fastapi_xx_msg\rabbitmqtest\test4>python r1.py info error
随机队列的名称:amq.gen-5a7YDQXA4AMk-D6giXjGNw
info
error
复制代码
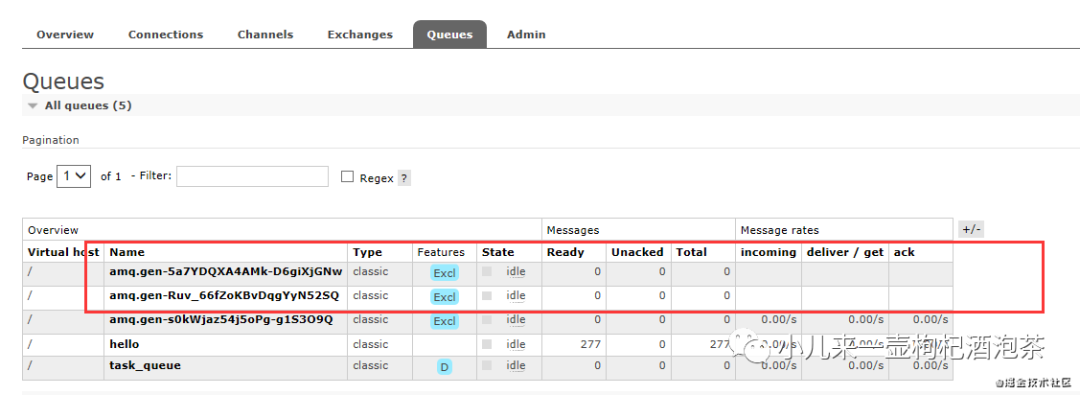
启动后对应我的队列名称如图示:
,然后我们的这个时候启动一下我们的生产者,默认的发送端启动的时候,发送的只是info的消息,观察我们的输出的情况:
两个消费者同时都处理了info的消息,类似我们的纯广播模式了!

此时停下我们的发送者,改为只发送error的消息的情况:
此时有且只有同时绑定了的info和error的消费者接收倒了关于error的消息! 
此时和我们的纯广播模式一样,如果某个客户端的退出,则对应的队列也会消失~
5.1.8 topic规则播,模糊匹配路由模式
-- topic规则播,模糊匹配路由模式,-根据交换机rouing_key通配符的形式消息模式
这种模式下,和前面的组播模式是大部分的是一样,只是这里的rouing_key有所变化了!其中的routing_key变成了一个有“.”分隔的字符串,“.”将字符串分割成几个单词, 每个单词代表一个条件;
以下是规则广播的模式模型图:
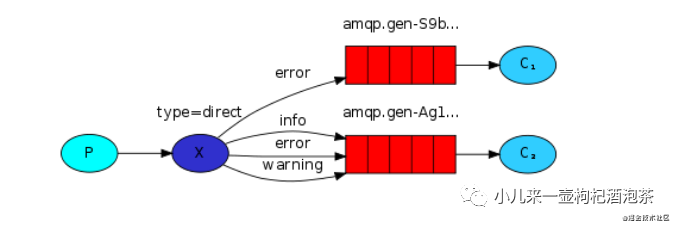
比如图示的:
我们的交换机里面定义了多个:routing_key~ 其中:
error的有单独的定义了一个队列,那么这个队列只是接收这种类型的消息
其他另一个的队列:不管是info的erroe还是warning类型的消息我都接收~
完整示例,生产消息端send.py
import pika
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("guest", "guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost', credentials=credentials))
# 创建频道
channel = connection.channel()
# 创建交换机,并指定类型
channel.exchange_declare(exchange='topic_ceshilogs', exchange_type='topic')
# 如果不存在,输入启动,需要发送的数据的规则,则默认是 xiaozhong.info
routing_key = sys.argv[1] if len(sys.argv) > 2 else 'xiaozhong.info.*'
import time
for i in range(1, 1000):
time.sleep(1)
# 向交换机发送数据, 让交换机只给能匹配anonymous.info * 的队列发消息
channel.basic_publish(exchange="topic_ceshilogs",
routing_key=routing_key, # 此处为空,必须有
body='fanout纯广播模式-小钟同学你好!{}'.format(i).encode('utf-8'),
# 数据持久化,下面的这句无效
# properties=pika.BasicProperties(delivery_mode=2)
)
print("发送的了!消息")
connection.close()
复制代码
然后对应我们的消费端:
import pika
import sys
# 创建凭证,使用rabbitmq用户名/密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 创建频道
channel = connection.channel()
# 创建交换机
channel.exchange_declare(exchange='topic_ceshilogs', exchange_type='topic')
# 创建队列
result = channel.queue_declare('', exclusive=True)
# 队列名称
queue_name = result.method.queue
print("随机生产的队列名称:",queue_name)
# 接收命令行的输入的需要匹配的路由的规则信息
binding_keys = sys.argv[1:]
# 如果没有,则提示必须输入
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1)
# 开始进行循环的绑定进行队列的绑定
for binding_key in binding_keys:
print("绑定规则是:", binding_keys)
channel.queue_bind(exchange='topic_ceshilogs', queue=queue_name, routing_key=binding_key)
print(' [*] 规则播模式的启动!. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" 规则播接收到的消息为:%r:%r" % (method.routing_key, body))
# 开始订阅消息
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
# 启动消息定义,循环监听
channel.start_consuming()
复制代码
启动我们的消费端的第1个:
python r.py "#"
复制代码
输出为:
(fastapi_5g_msg) D:\code\python\local_python\fastapi_5g_msg\rabbitmqtest\test5>python r.py "#"
随机生产的队列名称: amq.gen-cuvwaAk8jMFYY2eppAP1TQ
绑定规则是: ['#']
[*] 规则播模式的启动!. To exit press CTRL+C
复制代码
启动我们的消费端的第2个:
(fastapi_5g_msg) D:\code\python\local_python\fastapi_5g_msg\rabbitmqtest\test5>python r.py "xiaozhong.info.*"
随机生产的队列名称: amq.gen-eHx5oGWTbny1Z-7rJuCccw
绑定规则是: ['xiaozhong.info.*']
[*]糊匹配- 规则播模式的启动!. To exit press CTRL+C
复制代码
个人感觉这个模糊匹配的方式~可能使用的相对的场景比较少吧!后续有机会再深入研究!上面的两个消费者,都可以同时消费我们的生产的消息!
首先上面的 第一个接收的是 # ,所以所有的发送到这个交换机的都可以收到!
第一个接收的是xiaozhong.info.*,所有这种类似刚好吻合,也可以接收的到!
如果你定义的绑定规则是: ['xiaozhong.#']这种的那么也是可以接收到xiaozhong.xxx.xxx其他的!
5.1.9 RPC调用消息模式
-- RPC调用消息模式
关于RPC后续我们的自己梳理好关于pythyon一些使用rpc的之后再回头看看这个!这里暂且放下!
5.1.10 发送JSON格式数据
如果需要发送特点的数据类型的,可以自己定义content_type:
channel.queue_declare(queue=qname, auto_delete=False, durable=True)
prop = pika.BasicProperties(
content_type='application/json',
content_encoding='utf-8',
headers={'key': 'value'},
delivery_mode = 1,
)
channel.basic_publish(
exchange='',
routing_key=qname,
properties=prop,
body='{message: hello}'
)
复制代码
5.1.11 心跳检测
关于rabbitmq的心跳检测,通常主要适用于检测和代理服务器之间通信的存活,和我们的通常soket的心跳包类似。主要的原理也还是检测对应的socket连接上数据的收发是否正常,如果某个固定的时间段内一直没有收发数据,那么我们的需要发送一个心跳包进行检查一席啊,如果发送的心跳包一段时间内没有回复的话,那么则判断为心跳超时,此时会判定对端已经异常crash.最终会关闭tcp连接.
关于设置心跳包的检测时间间隔:
服务端配置修改主要是再rabbitmq.config进行修改配置
通过客户端进行配置heartbeat参数的配置设置
PS:如果heartbeat=0,则表示不启用heartbeat检测
class ConnectionParameters(Parameters):
"""Connection parameters object that is passed into the connection adapter
upon construction.
"""
# Protect against accidental assignment of an invalid attribute
__slots__ = ()
class _DEFAULT(object):
"""Designates default parameter value; internal use"""
def __init__( # pylint: disable=R0913,R0914
self,
host=_DEFAULT,
port=_DEFAULT,
virtual_host=_DEFAULT,
credentials=_DEFAULT,
channel_max=_DEFAULT,
frame_max=_DEFAULT,
heartbeat=_DEFAULT,
ssl_options=_DEFAULT,
connection_attempts=_DEFAULT,
retry_delay=_DEFAULT,
socket_timeout=_DEFAULT,
stack_timeout=_DEFAULT,
locale=_DEFAULT,
blocked_connection_timeout=_DEFAULT,
client_properties=_DEFAULT,
tcp_options=_DEFAULT,
**kwargs):
"""Create a new ConnectionParameters instance. See `Parameters` for
default values.
复制代码
具体配置:
connection = pika.BlockingConnection(
pika.ConnectionParameters(
host=hosts,
credentials=credential,
heartbeat=0,
))
复制代码
5.1.12 队列交换机其他操作
import pika
credentials = pika.PlainCredentials('test', 'test')
connection = pika.BlockingConnection(pika.ConnectionParameters(host='127.0.0.1', credentials=credentials))
channel = connection.channel()
channel.exchange_delete("ex1")
# 删除交换器
channel.queue_delete("aaa")
# 删除队列
connection.close()
复制代码
5.1.13 关于手动ack机制
0.x 版本
# no_ack = no_manual_ack = auto_ack;不手动应答,开启自动应答模式
channel.basic_consume(consumer_callback=ConsumerCallback, queue=MQQueueNode2Center, no_ack=False)
# 1.x 版本
channel.basic_consume(queue=MQQueueNode2Center, on_message_callback=ConsumerCallback, auto_ack=False)
复制代码
5.1.14 关于消息的Time To Live(TTL)生存时间
TTL 其实就是一个消息存在有效时间,也可以说是最大存活时间,通常单位是毫秒
RabbitMQ的TTL的设置,RabbitMQ可以针对消息也可以针对队列来设置TTL:
关于消息的设置:对于特定消息的过期时间的设置,在消息发送的时候可以进行指定,每条消息的过期时间可以不同。
关于队列的设置:RabbitMQ支持设置队列的过期时间,从消息入队列开始计算,直到超过了队列的超时时间配置,那么消息会变成死信,自动清除(没配死信队列的情况下)。
混合双打的情况设置:如果两种方式一起使用,则过期时间以两者中较小的那个数值为准。
不设置TT的情况:,不设置表示消息不会过期;如果TTL设置为0,则表示除非此时可以直接将消息投递到消费者,否则该消息会被立即丢弃。
配置TTL的时间和方式:
使用策略为队列定义消息TTL 使用命令行进行配置设置:
rabbitmqctl rabbitmqctl set_policy TTL ".*" '{"message-ttl":60000}' --apply-to queues
rabbitmqctl (Windows)
rabbitmqctl set_policy TTL ".*" "{""message-ttl"":60000}" --apply-to queues
复制代码
上面的设置将对对所有队列应用60秒的TTL配置!
还可以通过使用接口请求进行设置:
curl -i -u guest:guest -H "content-type:application/json" -XPUT
-d'{"auto_delete":false,"durable":true,"arguments":{"x-message-ttl": 60000}}'
http://localhost:15672/api/queues/{vhost}/{queuename}
复制代码
代码设置python代码:queue_declare 中设置 x-message-ttl 参数,可以控制被 publish 到 queue 中的 message 被丢弃前能够存活的时间,当某个 message 在 queue 留存的时间超过了配置的 TTL 值时,我们说该 message “已死”。
针对消息设置TTL的方式:
import pika
import sys
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
channel.queue_declare(queue='task_queue', durable=True)
# 定义需要发的消息内容
# 开始发布消息到我们的代理服务器上,注意这里没有对发生消息进行确认发生成功!!!
import time
for i in range(1,100):
time.sleep(1)
properties = pika.BasicProperties(delivery_mode=2,)
# expiration 字段以微秒为单位表示 TTL 值,6 秒的 message
properties.expiration='2000'
body = '小钟同学你好!{}'.format(i).encode('utf-8')
print(body)
channel.basic_publish(
# 默认使用的/的交换机
exchange='',
# 默认的匹配的key
routing_key='task_queue',
# 发送的消息的内容
body=body,
# 发现的消息的类型
properties=properties# pika.BasicProperties中的delivery_mode=2指明message为持久的,1 的话 表示不是持久化 2:表示持久化
)
# 关于消息持久化需要注意几个点,并非百分百的可达!主要原因有几个点:
# 1:消息可达率,和网络可通性和抖动之类有关!
# 2:还有和我们的RabbitMQ写入磁盘时候的有关
# 可持久的需要条件是:durable=True+ properties=pika.BasicProperties(delivery_mode=2,)
# 关闭链接
connection.close()
复制代码
上面的代码是一个生产者端的代码:其中最关键的代码设置是:
properties = pika.BasicProperties(delivery_mode=2,)
# expiration 字段以微秒为单位表示 TTL 值,6 秒的 message
properties.expiration='2000'
复制代码
设置每个消息的过期时间是2秒,观察我们的队列的信息,一直发的情况下,他的待消费的内容还是比较少,那是因为的已经过期了!被丢弃了!
单独对某消息的设置过期时间,和队列的持久化的特性不冲突!!!
但是对队列设置过期的时间话,那么和队列的持久化的特性就会产生冲突!!!
针对队列中所有消息设置TTL的方式:
出现的问题:
pika.exceptions.ChannelClosedByBroker: (406, "PRECONDITION_FAILED - inequivalent arg 'x-message-ttl' for queue 'task_queue' in vhost '/': received the value '2000' of type 'longstr' but current is none")
复制代码
原因是:
 我们即设置队列为需持久化,但是又设置了过期时间!所以产生的冲突!!!
我们即设置队列为需持久化,但是又设置了过期时间!所以产生的冲突!!!
修改后还是继续出现:
pika.exceptions.ChannelClosedByBroker: (406, "PRECONDITION_FAILED - inequivalent arg 'durable' for queue 'task_queue' in vhost '/': received 'false' but current is 'true'")
复制代码
这个是因为我们的一开始创建的队列,本来就有这个属性了!它是不能动态的修改这个队列的属性的!最好的的方式就是删除这个队列咯!如果还想继续用这个队列名称的话!!或重新的新建一个!还有一点:生产者和消费者对queue的声明函数里,这个durable也记得需要保持一致!!!!
删除队列后出现新的问题:
pika.exceptions.ChannelClosedByBroker: (406, 'PRECONDITION_FAILED - invalid arg \'x-message-ttl\' for queue \'task_queue\' in vhost \'/\': "expected integer, got longstr"')
复制代码
原因是:
 不能设置为字符串的类型!!!
不能设置为字符串的类型!!!
完整的针对队列设置TTL的示例代码:
# !/usr/bin/env python
import pika
import sys
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
arguments = {}
# TTL: ttl的单位是us,ttl=60000 表示 60s
arguments['x-message-ttl'] = 2000
# auto_delete=False, # 最后一个队列解绑则删除 durable
# durable 和 x-message-ttl 不能同时的存在
channel.queue_declare(queue='task_queue', durable=False,arguments=arguments,auto_delete=False)
# 定义需要发的消息内容
# 开始发布消息到我们的代理服务器上,注意这里没有对发生消息进行确认发生成功!!!
import time
for i in range(1,100):
time.sleep(1)
properties = pika.BasicProperties(delivery_mode=2,)
# expiration 字段以微秒为单位表示 TTL 值,6 秒的 message
# properties.expiration='2000'
body = '小钟同学你好!{}'.format(i).encode('utf-8')
print(body)
channel.basic_publish(
# 默认使用的/的交换机
exchange='',
# 默认的匹配的key
routing_key='task_queue',
# 发送的消息的内容
body=body,
# 发现的消息的类型
properties=properties# pika.BasicProperties中的delivery_mode=2指明message为持久的,1 的话 表示不是持久化 2:表示持久化
)
# 关于消息持久化需要注意几个点,并非百分百的可达!主要原因有几个点:
# 1:消息可达率,和网络可通性和抖动之类有关!
# 2:还有和我们的RabbitMQ写入磁盘时候的有关
# 可持久的需要条件是:durable=True+ properties=pika.BasicProperties(delivery_mode=2,)
# 关闭链接
connection.close()
复制代码
如果综合存在的话,验证一下,比如我设置队列的过期时间是1秒,消息的时间2秒:混合双打的情况设置:如果两种方式一起使用,则过期时间以两者中较小的那个数值为准。这个是可以看得到!不贴代码了!
5.1.15 死信消息和死信队列
5.1.15.1 死信消息和死信队列定义
关于死信说明的官方文档地址为: www.rabbitmq.com/ttl.html#pe…
需要了解的:Dead Letter Exchange 死信队列(DLX)队列的简称。
另外对于死信消息:通常如果我们的一个消息存在以下的情况下的话则这消息被称为死信消息:
1:消息被消费端拒绝,使用 channel.basicNack 或 channel.basicReject ,并且此时requeue 属性被设置为false
2:消息在队列的存活时间超过设置的TTL时间。
3:消息队列的消息数量已经超过最大队列长度,无法再继续新增消息到MQ中
4:一个队列中的消息的TTL对其他队列中同一条消息的TTL没有影响
对于死信消息的处理,Rabbitmq会依据是否配置死信队列的配置来决定消息的去留!如果开启了配置死信队列信息,则消息会被转移到这个 死信队列(DLX)中,如果没有配置,则此消息会被丢弃!
5.1.15.2 死信队列配置
官网文档:www.rabbitmq.com/dlx.html
可以为每一个需要使用死信业务的队列配置一个死信交换机
每个队列都可以配置专属自己的死信队列,相关消息的进入死信队列需要经过死信交换机来进程归纳处理
死信交换机也只是一个普通的交换机,只是它是用来专门处理死信的交换机
创建队列时可以给这个队列附带一个死信的交换机,在这个队列里因各自情况出现问题的作废的消息会被重新发到附带的交换机,然后让这个交换机重新路由这条消息。
具体的图示:
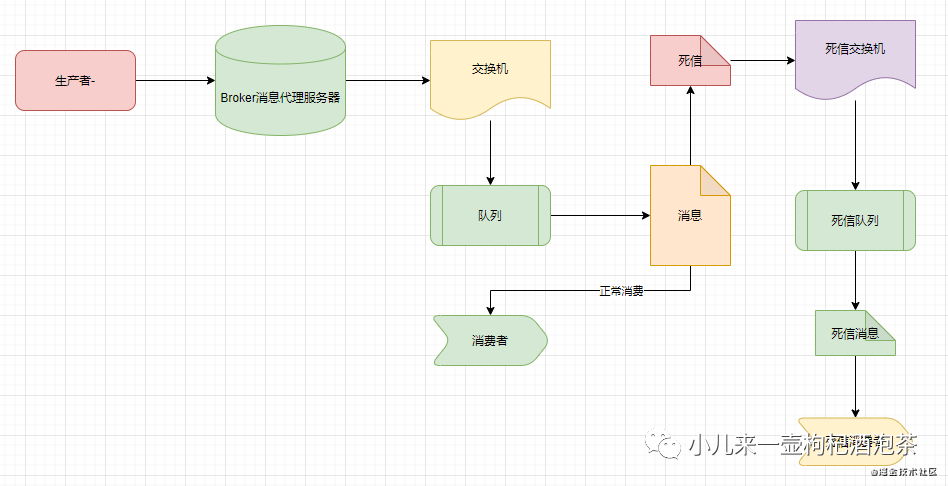
若要使用策略指定DLX,请将键“死信交换”添加到策略定义中。例如:
rabbitmqctl
rabbitmqctl set_policy DLX ".*" '{"dead-letter-exchange":"my-dlx"}' --apply-to queues
Rabbitmqctl(Windows)
rabbitmqctl set_policy DLX ".*" "{""dead-letter-exchange"":""my-dlx""}" --apply-to queues
复制代码
上面的策略将DLX队列“my-dlx”应用于所有队列。上面只是一个例子,实际上不同的队列可能会使用不同的死字设置(或者根本不使用)。
其他配置死信队里的方式有:
x-dead-letter-exchange:出现死信(dead letter)之后将死信(dead letter)重新发送到指定exchange
x-dead-letter-routing-key:出现死信(dead letter)之后将死信(dead letter)重新按照指定的routing-key发送
复制代码
PS:当指定了死信交换机后时,除了通常对声明队列的配置权限外,用户还需要对该队列具有读取权限,并对死信交换机具有写权限。权限在队列声明时进行验证。
完整的一个简单的示例:
下面的示例主要是演示里:1:设置消息的过期的时间为2s,2s之后就变为我们的死信
2:变为死信的消息,会被转移到我们的另一个死信交换机的队列上
# !/usr/bin/env python
import pika
import sys
# 创建用户登入的凭证,使用rabbitmq用户密码登录
credentials = pika.PlainCredentials("guest","guest")
# 创建连接
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost',credentials=credentials))
# 通过连接创建信道
channel = connection.channel()
# ========
# 创建异常交换器和队列,用于存放没有正常处理的消息。
channel.exchange_declare(exchange='xz-dead-letter-exchange',exchange_type='fanout',durable=True)
channel.queue_declare(queue='xz-dead-letter-queue',durable=True)
# 绑定队列到指定的交换机
channel.queue_bind(queue='xz-dead-letter-queue',exchange= 'xz-dead-letter-exchange',routing_key= 'xz-dead-letter-queue')
# =========
# 通过信道创建我们的队列 其中名称是task_queue,并且这个队列的消息是需要持久化的!PS:持久化存储存到磁盘会占空间,
# 队列不能由持久化变为普通队列,反过来也是!否则会报错!所以队列类型创建的开始必须确定的!
arguments = {}
# TTL: ttl的单位是us,ttl=60000 表示 60s
# arguments['x-message-ttl'] = 2000
# 指定死信转移到另一个交换机上具体的交换机的名称
arguments['x-dead-letter-exchange'] = 'xz-dead-letter-exchange'
# auto_delete=False, # 最后一个队列解绑则删除 durable
# durable 和 x-message-ttl 不能同时的存在
channel.queue_declare(queue='task_queue', durable=True,arguments=arguments,auto_delete=False)
# 定义需要发的消息内容
# 开始发布消息到我们的代理服务器上,注意这里没有对发生消息进行确认发生成功!!!
import time
for i in range(1,100):
time.sleep(1)
properties = pika.BasicProperties(delivery_mode=2,)
# expiration 字段以微秒为单位表示 TTL 值,6 秒的 message
properties.expiration='2000'
body = '小钟同学你好!{}'.format(i).encode('utf-8')
print(body.decode('utf-8'))
channel.basic_publish(
# 默认使用的/的交换机
exchange='',
# 默认的匹配的key
routing_key='task_queue',
# 发送的消息的内容
body=body,
# 发现的消息的类型
properties=properties# pika.BasicProperties中的delivery_mode=2指明message为持久的,1 的话 表示不是持久化 2:表示持久化
)
connection.close()
复制代码
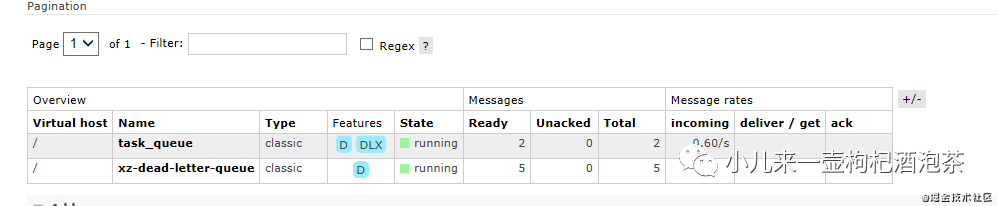
运行上面的生产者的代码后观察我们的输出:中国发出了8个消息,
小钟同学你好!1
小钟同学你好!2
小钟同学你好!3
小钟同学你好!4
小钟同学你好!5
小钟同学你好!6
小钟同学你好!7
小钟同学你好!8
复制代码
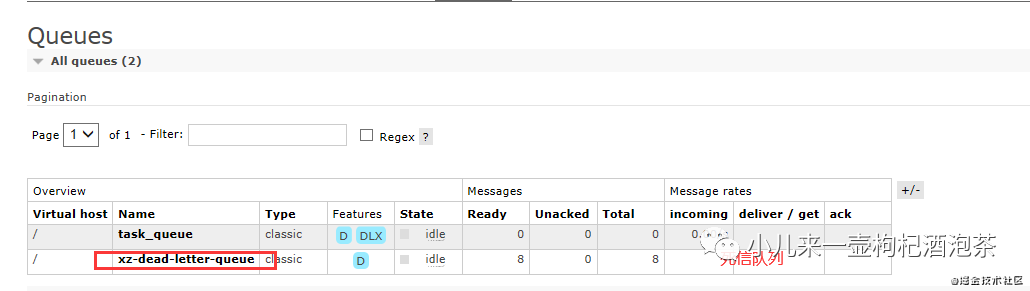
结果这个8个消息都没有人去消费的时候:最后都转移到了死信的队列里面:
关于死信队列需要注意的点(来自官网的说明):
消息在发布到死信队列后DLX目标队列后会立即从原始队列中删除。这确保没有可能出现过多的消息积累,从而耗尽代理资源,但这确实意味着,如果目标队列无法接受消息,消息可能会丢失。
5.1.15.3 死信队列里面的死信的消费
当我们的死信消费者去消费死信消息时候,需要注意点有:
我们的“死信”消息消息的properties里面的header字段信息中增加一个叫做“x-death"的数组内容,包含了以下字段内容: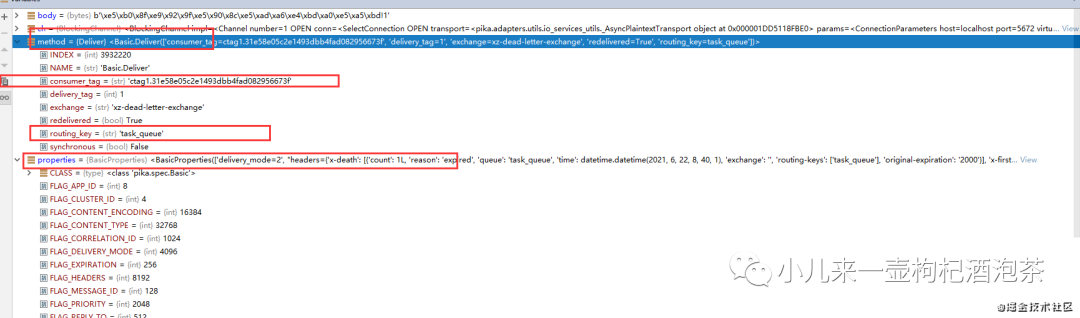
<BasicProperties(['delivery_mode=2', "headers={'x-death': [{'count': 1L, 'reason': 'expired', 'queue': 'task_queue', 'time': datetime.datetime(2021, 6, 22, 8, 40, 1), 'exchange': '', 'routing-keys': ['task_queue'], 'original-expiration': '2000'}], 'x-first-death-exchange': '', 'x-first-death-queue': 'task_queue', 'x-first-death-reason': 'expired'}"])>
复制代码
其中我们的'x-death'内容为::
{'x-death': [{'count': 1L, 'reason': 'expired', 'queue': 'task_queue', 'time': datetime.datetime(2021, 6, 22, 8, 40, 1), 'exchange': '', 'routing-keys': ['task_queue'], 'original-expiration': '2000'}], 'x-first-death-exchange': '', 'x-first-death-queue': 'task_queue', 'x-first-death-reason': 'expired'}
复制代码
具体每个字段的意思是:
queue :进入死信队列之前来自于哪个的消息队列名称
reason:这个消息变为死信的原因?expired 表示是因为过期!变为死信!
count:这个消息在这个队列中被死了多少次
time:该消息发布时间
exchange :消息已发布到哪些交换机上,PS:如果这个消息是多次变为死信的话,这个地方最后就是死信的交换机
routing-keys 消息发不来来源的路由keys
original-expiration:原消息的过期时间属性,PS:(如果消息是死信的话)每条消息ttl):。这个过期属性将从死信中删除,以防止它在被路由到的任何队列中再次过期。
x-first-death-exchange:第一次变成死死信的时候来源的交换机
x-first-death-queue:第一次变成死信的时候来源队列
x-first-death-reason:第一次变成死信的原因:expired 表示是因为过期!
其他变为死信的原因的说明:
rejected: 消息被消费者拒收且回放到消息独立
expired: 消息的设置来TTL时间到期
maxlen: 超过了队列运行的最大的值
复制代码
5.1.16 延迟队列
RabbitMQ本身没有直接支持延迟队列功能,但是通过对死信队列和过期时间的使用,其实我们可以综合起上面的两个特性来实现一个所谓的延迟队列,延迟队列的意思就是:某个消息再某个固定的时间后失效后,则进入到死信队列里面,其他死信的消费者实时的处理这些过期的消息,这个就可以起到一个延迟处理的效果!
5.1.17 客户端断线重试
主要是利用ConnectionClosedByBroker异常捕获机制进行重试!
from retry import retry
@retry(pika.exceptions.AMQPConnectionError, delay=5, jitter=(1, 3))
def consume():
connection = pika.BlockingConnection()
channel = connection.channel()
channel.basic_consume('test', on_message_callback)
try:
channel.start_consuming()
# Don't recover connections closed by server
except pika.exceptions.ConnectionClosedByBroker:
pass
consume()
复制代码
5.1.17 如何避免消息堆积?
消息堆积可能出现的几个原因有:
消息生产速度远大于消息者消费的消息速度
消费者消费能力不足
消费者无法正常的消费消息
消费者消费速度能力受限
消费者直接挂掉了
消费者出现性能瓶颈
加快消费者的消息能力!
1) 多消费者进行同时消费处理
2) 消息消费的处理可以进行异步处理,可以使用线程池的方式加快消息消费
3) 对于非必要的可丢的那种消息,设置TTL时间,加入到死信队列里面去消费
4) 转移消息到另一个队列进行处理
参考资料:
blog.csdn.net/yaomingyang… blog.csdn.net/wohu1104/ar… www.cnblogs.com/mfrank/p/11…
总结:
以上是大部门代码是来自官网提供的一些简单案例,结合自己的实践做的简单的笔记!如有笔误!欢迎批评指正!感谢各位大佬!
结尾
简单小笔记!仅供参考!
END
简书:www.jianshu.com/u/d6960089b…
掘金:juejin.cn/user/296393…
公众号:微信搜【小儿来一壶枸杞酒泡茶】
小钟同学 | 文 【原创】【欢迎一起学习交流】| QQ:308711822
