




为什么需要线程池
对比进程来说,虽然创建线程的开销比创建进程的开销小,但是也不能意味着我们可以无限的去开线程。
无限制的线程情况,有可能会引发系统性能下降,(多数情况我们滥用线程的时候,一般系统会异常的问题多多,)
线程的创建也也是需要开销
和进程池一样,主要是池化一定数量的对象,避免重复的多次的创建等问题。
使用线程池主要是为了有效地控制系统中并发线程的数量
预先创建线程/异步处理来提高响应速度。
统一调配线程资源,可以降低线程的重复创建问题,提高线程的利用率
PS:Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类.
concurrent.futures模块实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池)
线程池原理
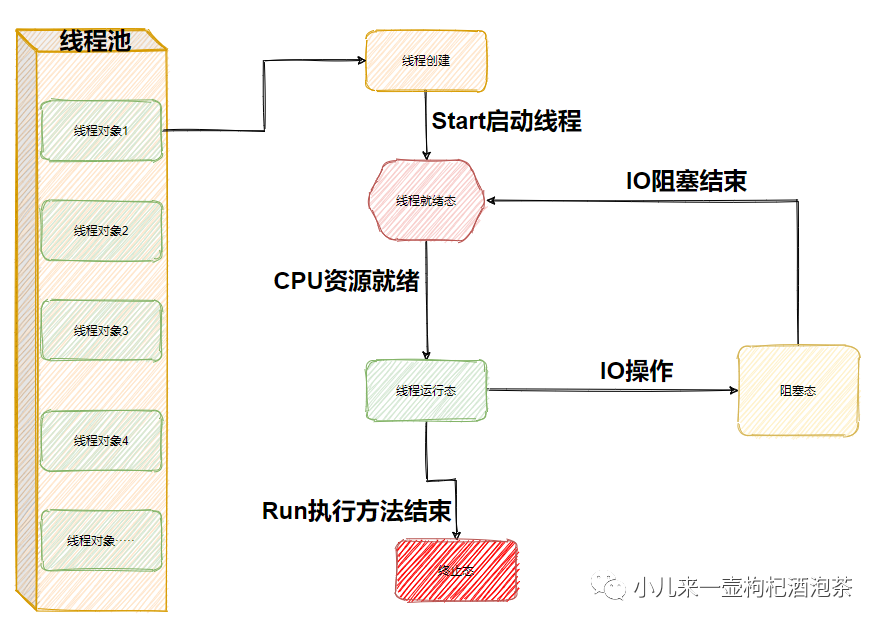
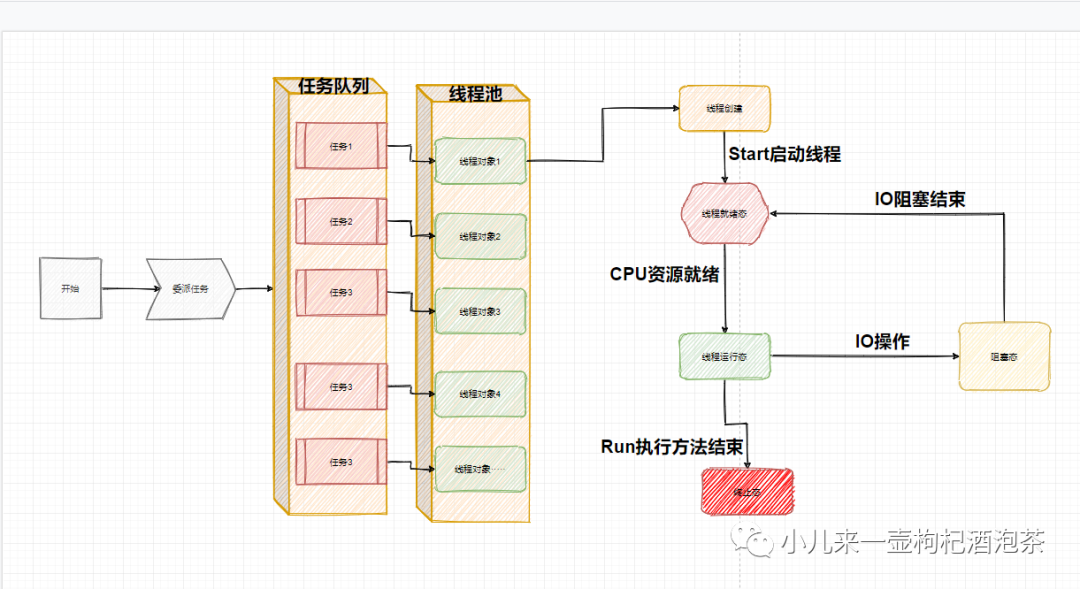
线程池的两个库
- from multiprocessing.dummy import Pool as ThreadPool
- from concurrent.futures import ThreadPoolExecutor
示例主要已cocurrent.future模块为主:
cocurrent.future模块中的future的意思是未来对象,可以把它理解为一个在未来完成的操作,这是cocurrent.future模块实现异步编程的基础。
Python3.2开始,标准库为我们提供了concurrent.futures模块,它提供了ThreadPoolExecutor和ProcessPoolExecutor两个类.
concurrent.futures模块实现了对threading和multiprocessing的进一步抽象(这里主要关注线程池)
concurrent.futures模块提供了主线程可以获取某一个线程(或者任务的)的状态,以及返回值
让线程的使用更加方便,减小了线程创建/销毁的资源损耗,无需考虑线程间的复杂同步,方便主线程与子线程的交互。
ThreadPoolExecutor下的使用
官方文档地址:
https://docs.python.org/zh-cn/3/library/concurrent.futures.html
几个方法:
submit()非阻塞方式提交线程需要执行的任务(函数名和参数)到线程池,并返回任务的句柄
done() 判断线程执行的任务是否返回,依赖于 submit()提交后返回的文件举报的对象
cancel() 取消任务(如果任务还没添加到线程池中,才可以取消)
result() 阻塞的方式获取认知执行的返回结果
可以通过result(timeout=2)设置线程超时时间,超时会引发concurrent.futures._base.TimeoutError 异常 as_completed()一次取出所有任务的结果
shutdown()当待执行的 future 对象完成执行后向执行者发送信号,它就会释放正在使用的任何资源,关闭后调用 Executor.submit() 和 Executor.map() 将会引发 RuntimeError。
shutdown()的关闭可以使用上下文的方式来简化管理with ThreadPoolExecutor(max_workers=4) as e: submit() 提交任务到线程池中。
map()exector的map方法会并发调用,返回一个由返回的值构成的生成器
exector.submit()和futures.as_completed()这个组合比exector.map()更>灵活,
submit()可以处理不同的调用函数和参数
map只能处理同一个可调用对象,且返回是一个迭代器对象
wait()阻塞主线程,直到所有task都完成,或直到满足设定的要求。
-wait方法接收3个参数
等待的任务序列 超时时间以 等待条件 等待条件return_when默认为ALL_COMPLETED,表明要等待所有的任务都结束。
示例:
import concurrent.futures
import requests
URLS = ['http://www.qq.com/',
'http://www.baidu.com/',
'http://ai.taobao.com/']
# Retrieve a single page and report the URL and contents
def load_url(url):
return requests.get(url).text
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# 提交我们的任务
future_to_url = {executor.submit(load_url, url): url for url in URLS}
#
for future in concurrent.futures.as_completed(future_to_url):
url = future_to_url[future]
try:
# 循环的获取认任务执行的结果
data = future.result()
except Exception as exc:
print('%r generated an exception: %s' % (url, exc))
else:
print('%r 页面内容省略··· %s ' % (url, data[1:20]))
输出:
'http://www.baidu.com/' 页面内容省略··· !DOCTYPE html>
<!-
'http://www.qq.com/' 页面内容省略··· !doctype html>
<htm
'http://ai.taobao.com/' 页面内容省略···
<!DOCTYPE html><ht
ThreadPoolExecutor下的map方法(更精简的取所有子线程执行结果)
类似于 python标准库中的map(func, *iterables) 函数,相似,除了以下两点:
iterables 是立即执行而不是延迟执行的;
func 是异步执行的,对 func 的多个调用可以并发执行。
import concurrent.futures
import requests
URLS = ['http://www.qq.com/',
'http://www.baidu.com/',
'http://ai.taobao.com/']
# Retrieve a single page and report the URL and contents
def load_url(url):
print()
text = requests.get(url).text
return text
# We can use a with statement to ensure threads are cleaned up promptly
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
# 提交我们的任务
# 用 map函数 更精简的取所有子线程执行结果:
for thread_exec_res in executor.map(load_url, URLS):
print("内容", thread_exec_res[1:20])
输出:
内容 !doctype html>
<htm
内容 !DOCTYPE html>
<!-
内容
<!DOCTYPE html><ht
个人其他博客地址
简书:https://www.jianshu.com/u/d6960089b087
掘金:https://juejin.cn/user/2963939079225608
小钟同学 | 文 【原创】| QQ:308711822
1:本文相关描述主要是个人的认知和见解,如有不当之处,还望各位大佬指正。 2:关于文章内容,有部分内容参考自互联网整理,如有链接会声明标注;如没有及时标注备注的链接的,如有侵权请联系,我会立即删除处理哟。
