




之前几个梳理主要是基于进程的方式进行并发,那上一个小节也聊过关于如果是基于CPython 的解释器的问题,一个时刻只有一个线程可以执行Python代码。
如果:io的相关操作是不会占用cpu,CPU主要是负责计算,而计算肯定是占cpu滴,如想让你的应用更好的利用多核计算机的计算性能,推荐你使用 multiprocessing 或者 concurrent.futures.ProcessPoolExecuto
如果:你想同时运行多个I/O绑定任务,线程仍然是一个合适的模型。
线程前置知识点的补充
关于线程一些需要了解
线程是CPU调度的基本单位
线程是和CPU核绑定的,多CPU多核中,各个线程可以占用不同的CPU。(线程可以分配到不同的CPU上执行)
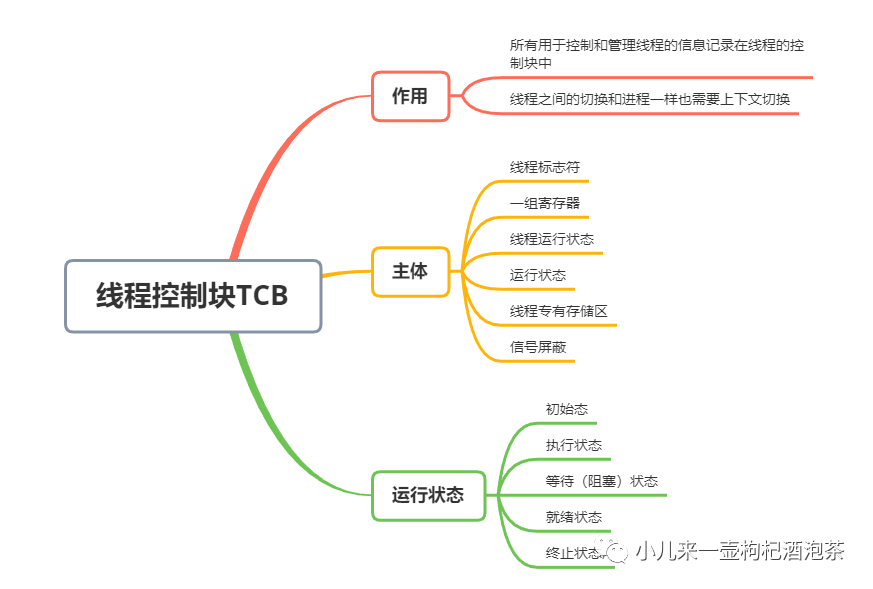
线程都有一个线程ID,和线程控制块(TCB)
线程也和进程一样,有状态转换:如小就绪、阻塞、运行等
线程几乎不拥有系统资源
同一个进程的不同线程共享进程资源,因共享地址空间,同一个进程中的线程间通信不需要系统干预
同一进程中的线程的切换,不会引发进程状态切换。
但是不同的进程中的线程切换,会引起进程切换。(跨进程之前的跨线程通信)
线程有各自的调用栈和线程本地存储
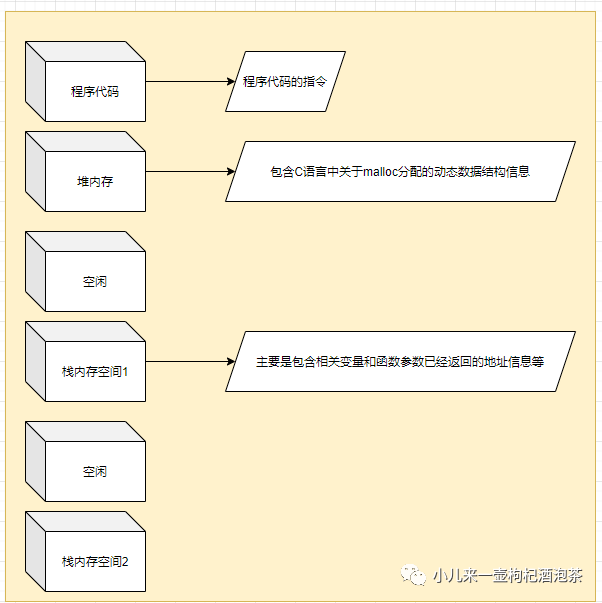
线程和进程的关系
同一进程中的多条线程将共享该进程中的全部系统资源(如虚拟地址空间,文件描述符和信号处理)
但同一进程中的多个线程有:
各自的调用栈(call stack), 自己的寄存器环境(register context) 自己的线程本地存储(thread-local storage)
一个进程可以有很多线程,每条线程可以并行执行不同的任务。
进程和线程的区别:
(自己理解的一种对比)
| 对比点 | 多进程 | 多线程 | 说明 |
|---|---|---|---|
| 操作系统层 | 进程是CPU分配资源的基本单位 | 线程是CPU调度的基本单位 | 概念不同 |
| 数据共享 | 复杂(跨进程) | 简单(同进程内) | 共享机制优劣看情况而定 |
| 数据同步(数据通信) | 差不多一样 | 差不多一样 | 都有LOCK和Rlock和Semaphore等 |
| CPU调度 | 慢(进程的上下文和线程上下文) | 快(仅线程的上下文) | 看场景评估 |
| 状态切换 | 不同的进程中的线程切换,会引起进程切换 | 同一进程中的线程的切换,不会引发进程状态切换 | 看场景评估 |
| 内存和CPU | 进程副本占用内存多,上下文切换复杂,CPU利用率低 | 同一个进程内占用内存少,切换简单,CPU利用率高 | 线程占优势(看场景使用) |
| 创建、销毁、切换 | 编程简单,调试简单(数据独享) | 编程复杂,调试复杂(数据共享) | (看场景评估使用) |
| 允许可靠性 | 进程间独立空间,互不影响 | 同一个空间内,线程的异常会引发进程异常 | (看场景评估使用) |
| 分布式 | 适用于多核、多机,扩展到多台机器简单 | 受GIL影响,多核下,一般仅使用IO等任务 | (看场景评估使用) |
辅助说明:
1、进程是资源的集合 线程是执行的指令集 2、线程启动速度快,进程启动速度慢(需要拷贝创建的资源更多)。 3、多进程之间一些变量数据不共享(除非需要相关共享数据)。同一个进程下的线程共享同一份数据。某进程内的线程在其它进程不可见。 4、创建新的线程很简单,创建新的进程需要对他的父进程进行一次克隆。 5、一个线程可以管理操作同一进程内的其他线程,而进程只能操作子进程。 6、IPC(Inter-Process Communication,进程间通信)进程间的通信,需要其他代理机制(进程同步和互斥手段等)来实现,而同一个进程内的线程则可以直接相互通信。 7、同一个进程内,对线程的修改,可能会引发其他线程的修改,但是对于父进程的修改不会影响到子进程。 8、调度和切换上:【线程上下文切换】比【进程上下文切换】快。
回顾:如何解决GIL中的multiprocess库介绍
如果无并发需求,忽略即可 分析需求,如相关的IO密集型任务,使用多线程也是可以提升到一定效率滴。 再不行使用协程(用户态线程)-(单进程单线程模式) 通过编写C语言扩展与Python交互,在C语言层面绕过GIL实现多核利用。 再不行就搬出来multiprocess(多进程)替代Thread可供选择。
multiprocess库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷。
它完整的复制了一套thread所提供的接口方便迁移。 每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢,通过多进程的方式绕过GIL。
上面提到关于multiprocess库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷,它完整的复制了一套thread所提供的接口方便迁移,
所以其实可以看出我们使用线程的时候,多数方法和我们的使用多进程的方式是一样的,和进程一样有:
守护线程 有线程锁 有线程池 有线程通信 有线程队列通信 还有一个类似隔离的独立空间的本地线程ThredLoacl 线程安全和不安全等问题
线程安全:多线程竞争同一个资源保证数据一致性和完整性的一个过程,通常一般是采取加锁机制,进行相关数据临界点的互斥
线程安全一般是:多线程环境下对一些【全局变量及静态变量】引起的同时具有【写操作权限】的时候会出现数据不一致或数据污染的情况,此时会了避免此类情况的发生,一般采取就是加锁的机制。
如果一般的单纯只是具体【读】操作的权限的,通常这个这个【全局变量及静态变量】是线程安全的。
所以线程不安全一般是强调多线程下对【全局变量及静态变量】等资源的写操作权限的情况下引发问题异常。
总结:真正会引导数据冲突的,其实不是读操作,而是写操作。(所以通常再分析代码的时候,可以看是否存在写操作,且写的操作是否会被拆分成多个字节码进行一个资源的写操作)
并发之下多线程的过程
在多线程环境中,Python程序的运行过程是:
运行,编译,然后一边解释,一边执行 执行过程的细节是: 1)获取GIL,线程获取到锁,可以获取到锁的线程开始运行,其他线程互斥等待获取到锁 2)获取到锁的线程,运行到指定数量的字节码指令,或者线程主动让出控制,如遇到IO操作或调用sleep(0)的时候,把线程状态切换为休眠状态 3)让出GIL锁,进行解锁GIL 4)其他线程可以抢夺GIL锁再次重复以上所有步骤
线程安全中的原子操作和原语(来自百度百科)
什么是原子操作(来自百度百科):
定义和概念
"原子操作(atomic operation)是不需要synchronized",这是多线程编程的老生常谈了。所谓原子操作是指不会被线程调度机制打断的操作;这种操作一旦开始,就一直运行到结束,中间不会有任何 context switch (切 [1] 换到另一个线程)。
原子操作可以是一个步骤,也可以是多个操作步骤,但是其顺序不可以被打乱,也不可以被切割而只执行其中的一部分。
将整个操作视作一个整体是原子性的核心特征。
原子性不可能由软件单独保证--必须需要硬件的支持,因此是和架构相关的。
在多进程(线程)的操作系统中不能被其它进程(线程)打断的操作就叫原子操作。
原子操作的回滚复位:
当该次操作无法完成时,会回滚到初始状态,原子操作是不可拆分的,(类似数据库的事务处理机制)。
文件的原子操作是指操作文件时的不能被打断的操作。
什么是原语(来自百度百科)
定义和概念
计算机进程的控制通常由原语完成。
所谓原语,一般是指由若干条指令组成的程序段,用来实现某个特定功能,在执行过程中不可被中断。
在操作系统中,某些被进程调用的操作,如队列操作、对信号量的操作、检查启动外设操作等,一旦开始执行,就不能被中断,否则就会出现操作错误,造成系统混乱。所以,这些操作都要用原语来实现 原语是操作系统核心(不是由进程,而是由一组程序模块组成)的一个组成部分,并且常驻内存,通常在管态下执行。
原语一旦开始执行,就要连续执行完,不允许中断 [1] 。
python分析操作是否原子操作的方法
由于对汇编不是很了解,此部分的内容主要是整理一下别人提供的思路,作为补充。————————————————
以下文字关于原子操作分析的版权声明:文章为CSDN博主「王燕璇」的原创文章,遵循CC 4.0 BY->SA版权协议,转载请附上原文出处链接及声明。原文链接:https://blog.csdn.net/weixin_28925387/article/details/111902381
GIL保证字节码级别的原子性和线程安全性,因此当个字节码执行一定是安全的,执行结果一定是一致的。
而有些操作,底层需要通过【多个字节码】来完成,这样的操作就不是原子的,因此不是线程安全的。
关于dis.dis的模块使用:
参考官网文档:https://docs.python.org/zh-cn/3/library/dis.html
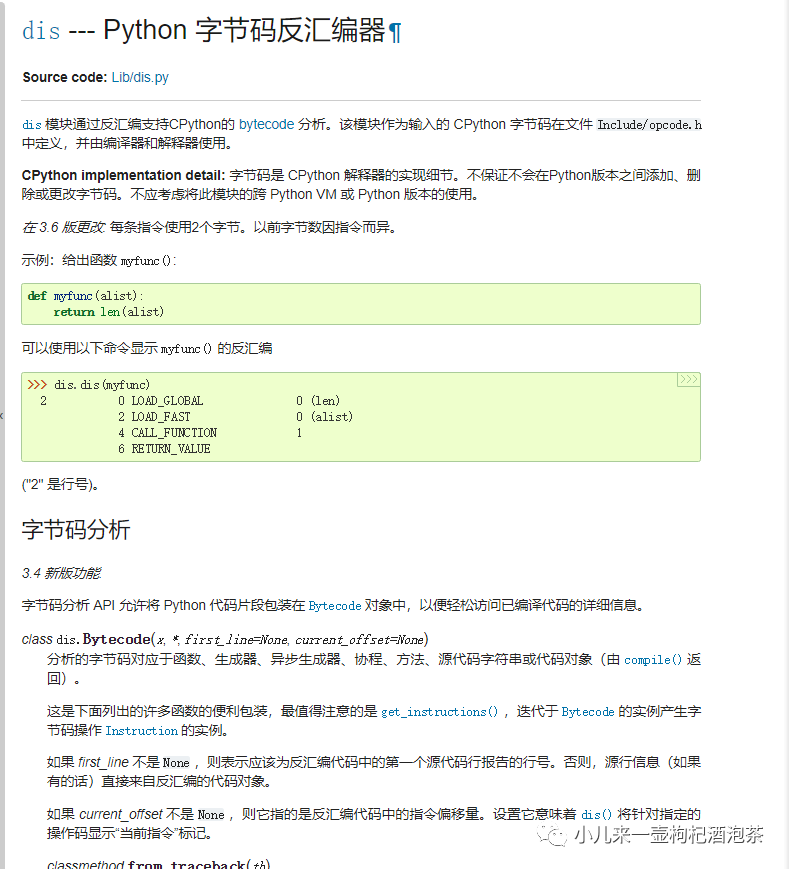
举个例子,a+=1 。
import dis
dis.dis(compile('a+=1', '', 'exec'))
反编译这个语句,发现它由4个字节码组成:查看输出结果:
1 0 LOAD_NAME 0 (a)
2 LOAD_CONST 0 (1)
4 INPLACE_ADD
6 STORE_NAME 0 (a)
8 LOAD_CONST 1 (None)
10 RETURN_VALUE
这个简单的语句,背后需要 4 个字节码协作完成:LOAD_NAME 将 a 当前的值加载进运行栈;
LOAD_CONST 将常量 1 加载到运行栈;
INPLACE_ADD 对栈上两个操作数进行加法运算;
STORE_NAME 将计算结果保存;
如果你学过汇编的话,你会发现Python字节码跟汇编指令非常像!GIL保证当个字节码的执行不会受到其他线程的任何干扰,但是任何字节码间都可能发生线程切换。
假设两个线程同时自增变量a,a当前值为0; 线程A执行到第3步,自增结果1已算出,但未保存; 这时线程B得到调度开始执行,同样算出结果1并抢先保存了; A回过头来将结果1保存,B的结果被覆盖了,最终a的值是1。 然而,两个线程对a自增,它的值讲道理应该是2!这就是并发操作产生的竞争态,解决方法是用一个锁将这几个字节码作为原子操作保护起来。
理解字节码执行:
参考通俗易懂:说 Python 里的线程安全、原子操作 作者:王一白 链接:https://juejin.cn/post/6844904159120998408
每一条字节码指令都是一个整体,无法拆分开, 但是如果我们的一行代码被分成多条字节码指令的时候,如果此时存在线程切换,那么会可能只执行了一条字节码指令, 此时若这行代码里有被多个线程共享的变量或资源时, 并且拆分的多条指令里有对于这个共享变量的写操作,就会发生数据的冲突,导致数据的不准确
总结:印证线程安全的概念
线程安全:多线程竞争同一个资源保证数据一致性和完整性的一个过程,通常一般是采取加锁机制,进行相关数据临界点的互斥
线程安全一般是:多线程环境下对一些【全局变量及静态变量】引起的同时具有【写操作权限】的时候会出现数据不一致或数据污染的情况,此时会了避免此类情况的发生,一般采取就是加锁的机制。
如果一般的单纯只是具体【读】操作的权限的,通常这个这个【全局变量及静态变量】是线程安全的。
所以线程不安全一般是强调多线程下对【全局变量及静态变量】等资源的写操作权限的情况下引发问题异常。
总结:真正会引导数据冲突的,其实不是读操作,而是写操作。(所以通常再分析代码的时候,可以看是否存在写操作,且写的操作是否会被拆分成多个字节码进行一个资源的写操作)
线程介绍:
早期的实现线程thread模块(已不推荐使用了),建议直接使用threading模块(推荐使用)。
线程相关的方法简介(官网文档)
threading.main_thread()
返回主 Thread 对象。一般情况下,主线程是Python解释器开始时创建的线程。
threading.active_count()
返回当前存活的 Thread 对象的数量。返回值与 enumerate() 所返回的列表长度一致。
threading.enumerate()
以列表形式返回当前所有存活的 Thread 对象。该列表包含守护线程,current_thread() 创建的虚拟线程对象和主线程。它不包含已终结的线程和尚未开始的线程。
threading.current_thread()
返回当前对应调用者的控制线程的 Thread 对象。如果调用者的控制线程不是利用 threading 创建,会返回一个功能受限的虚拟线程对象。
threading.get_ident()
返回当前线程的 “线程标识符”。它是一个非零的整数。它的值没有直接含义,主要是用作 magic cookie,比如作为含有线程相关数据的字典的索引。线程标识符可能会在线程退出,新线程创建时被复用。
可以关注几个方法点:
threading.settrace(func)
为所有 threading 模块开始的线程设置追踪函数。在每个线程的 run() 方法被调用前,func 会被传递给 sys.settrace() 。
threading.setprofile(func)¶
为所有 threading 模块开始的线程设置性能测试函数。在每个线程的 run() 方法被调用前,func 会被传递给 sys.setprofile() 。
threading.stack_size([size])
返回创建线程时用的堆栈大小
threading.TIMEOUT_MAX (3.2 新版功能.)
阻塞函数( Lock.acquire(), RLock.acquire(), Condition.wait(), ...)中形参 timeout 允许的最大值。传入超过这个值的 timeout 会抛出 OverflowError 异常。
threading.local
一个代表线程本地数据的类
线程对象的创建和几个方法
线程的创建:
class threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
参数:
group 应该为 None;为了日后扩展 ThreadGroup 类实现而保留。基本上暂时用不到 target 是用于 run() 方法调用的可调用对象。默认是 None,表示不需要调用任何方法。 name 是线程名称。默认情况下,由 "Thread-N" 格式构成一个唯一的名称,其中 N 是小的十进制数。 args 是用于调用目标函数的参数元组。默认是 ()。 kwargs 是用于调用目标函数的关键字参数字典。默认是 {}。 daemon (在 3.3 版更改: 加入 daemon 参数。)如果不是 None,daemon 参数将显式地设置该线程是否为守护模式。如果是 None (默认值),线程将继承当前线程的守护模式属性。
如果子类型重载了构造函数,它一定要确保在做任何事前,先发起调用基类构造器(Thread.init())。
线程对象几个方法:
start() 开始线程活动。 run() 代表线程活动的方法。 is_alive()返回线程是否存活。 is_alive()返回线程是否存活。 join(timeout=None) 等待至线程中止。这个会阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
不加join的话,主线程和子线程完全是并行的,加了join主线程得等这个子线程执行完毕,才能继续往下走。如果需要获取程序运作总时间,一般需要使用这种方式,不然主进程和子线程并行的时候,获取统计获取具体的时间。
getName(): 返回线程名。 setName(xxx): 设置线程名。 daemon 一个表示这个线程是(True)否(False)守护线程的布尔值。一定要在调用 start() 前设置好,不然会抛出 RuntimeError 。
关于join 这会阻塞调用这个方法的线程,直到被调用 join() 的线程终结 -- 不管是正常终结还是抛出未处理异常 -- 或者直到发生超时,超时选项是可选的。
当 timeout 参数存在而且不是 None 时,它应该是一个用于指定操作超时的以秒为>单位的浮点数(或者分数)。因为 join() 总是返回 None ,所以你一定要在 join() 后调用 is_alive()才能判断是否发生超时 -- 如果线程仍然存活,则 join() 超时。
当 timeout 参数不存在或者是 None ,这个操作会阻塞直到线程终结。
一个线程可以被 join() 很多次。
如果尝试加入当前线程会导致死锁, join() 会引起 RuntimeError 异常。如果尝试 join() 一个尚未开始的线程,也会抛出相同的异常。
多线程示例实践
1:最简多线程示例:
使用方法的方式:
import threading, time
def my_run(msg):
print("子线程的名称:", threading.current_thread().getName())
print("开始任务", msg)
time.sleep(2)
print("任务结束,", msg)
t1 = threading.Thread(name='线程1', target=my_run, args=("我是你大爷!",))
t2 = threading.Thread(name='线程2', target=my_run, args=("我是你大大的少爷!",))
print("当前每个进程都会有一个主线程,名字是:", threading.main_thread().getName())
start_time = time.time()
t1.start()
t2.start()
# 不加join的话,主线程和子线程完全是并行的,加了join主线程得等这个子线程执行完毕,才能继续往下走。这样才能得到这个程序真正的运行时间。
t1.join()
# 不加join的话,主线程和子线程完全是并行的,加了join主线程得等这个子线程执行完毕,才能继续往下走。这样才能得到这个程序真正的运行时间。
t2.join()
print('运行总耗时:', time.time() - start_time)
输出结果:
当前每个进程都会有一个主线程,名字是:MainThread
子线程的名称: 线程1
开始任务 我是你大爷!
子线程的名称: 线程2
开始任务 我是你大大的少爷!
任务结束, 我是你大爷!
任务结束, 我是你大大的少爷!
运行总耗时:2.0076282024383545
使用面向对象的方式:
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
文件名称 : 线程1
文件功能描述 : 功能描述
创建人 : 小钟同学
-------------------------------------------------
-------------------------------------------------
"""
import threading,time
class TestThread(threading.Thread):
def __init__(self,msg,sleep_time):
super(TestThread, self).__init__()
self.msg=msg
self.sleeptime=sleep_time
print("获取所属的主线程的名称:", threading.current_thread().getName())
# 需要执行的任务,调用start之后,程序会处于等待操作系统进行调度,到时间的是,会自己调用run
def run(self):
print("子线程的名称:", threading.current_thread().getName())
print("开始任务",self.msg)
time.sleep(2)
print("任务结束,",self.msg)
t1=TestThread("线程1",'我是你大爷!')
t2=TestThread("线程2",'我是你大大的少爷!')
print("当前每个进程都会有一个主线程,名字是:",threading.main_thread().getName())
start_time=time.time()
t1.start()
t2.start()
# 不加join的话,主线程和子线程完全是并行的,加了join主线程得等这个子线程执行完毕,才能继续往下走。这样才能得到这个程序真正的运行时间。
t1.join()
# 不加join的话,主线程和子线程完全是并行的,加了join主线程得等这个子线程执行完毕,才能继续往下走。这样才能得到这个程序真正的运行时间。
t2.join()
print('运行总耗时:',time.time()-start_time)
输出结果:
获取所属的主线程的名称:MainThread
获取所属的主线程的名称:MainThread
当前每个进程都会有一个主线程,名字是:MainThread
子线程的名称:Thread-1
开始任务 线程1
子线程的名称:Thread-2
开始任务 线程2
任务结束, 线程1
任务结束, 线程2
运行总耗时:2.0106277465820312
个人其他博客地址
简书:https://www.jianshu.com/u/d6960089b087
掘金:https://juejin.cn/user/2963939079225608
小钟同学 | 文 【原创】| QQ:308711822
1:本文相关描述主要是个人的认知和见解,如有不当之处,还望各位大佬指正。 2:关于文章内容,有部分内容参考自互联网整理,如有链接会声明标注;如没有及时标注备注的链接的,如有侵权请联系,我会立即删除处理哟。
