




并行计算的主要场景:
多核CPU——计算密集型任务(如计算圆周率、对视频进行高清解码,图片的处理等)。需要消耗的是CPU运算处理,会持续地将CPU占满,多CPU来分担任务,进行并行计算,可以提高任务执行效率,计算速度也会加快。
PS:实际的项目使用工作当中,通常我们的工作进程对应cpu数,有多少个CPU就开启几个进程即可,不应无限的开启多个进程,无限的启动多个进程实际上没有什么用,
多核CPU——I/O密集型任务。同单核CPU——I/O密集型任务。
单核CPU——计算密集型任务。此时如果一个任务已经把CPU资源100%消耗了,再并行也无济于事,因为只有一个!所以不需要并行。
单核CPU——I/O密集型任务。I/O密集型任务在如磁盘访问、屏幕、键盘输入输出,网络IO(包含数据库的请求处理还有其他网络请求处理),由于IO处理时CPU会处于空闲状态,此时CPU的利用率并不高,此时使用多进程方式,计算效率提升不大,因消耗的不是CPU,而是IO相关处理上。(此时可以使用多线程的方式进行处理IO)
1 多进程-独占的虚拟地址空间
进程拥有自己独占的虚拟地址空间、可执行代码、上下文空间、进程ID、环境变量等。(操作系统对主存一种抽象概念,每个进程只能访问自己的地址空间)
示例说明:
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
文件名称 : 多进程1
文件功能描述 : 功能描述
创建人 : 小钟同学
创建时间 : 2021/5/6
-------------------------------------------------
修改描述-2021/5/6:
-------------------------------------------------
"""
from multiprocessing import Process
import time
# 外部全局的
x = 100
def fun():
# 子进程内的变量
global x
x = 0
print('子进程内的:x:%s, X对应的内存地址是:%s' % (x, id(x)))
def globalfun():
# 外部主进程的
global x
return x
if __name__ == '__main__':
p = Process(target=fun)
p.start()
time.sleep(2)
print('主进程内的x:%s, X对应的内存地址是:%s' % (globalfun(), id(globalfun())))
输出:
子进程内的:x:0, X对应的内存地址是:140733187416880
主进程内的x:100, X对应的内存地址是:140733187420080
2 多进程-共享同一个文件系统
多个进程可以同时对同一个文件进行操作处理:
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
文件名称 : 进程2
文件功能描述 : 功能描述
创建人 : 小钟同学
创建时间 : 2021/5/6
-------------------------------------------------
修改描述-2021/5/6:
-------------------------------------------------
"""
from multiprocessing import Process
def talk(filename,msg):
with open(filename,'a',encoding='utf-8') as fr:
fr.write(msg)
if __name__ == '__main__':
for i in range(30):
p = Process(target=talk,args=('ProcessWrite.txt','我是进程,编号为:%s\n'%str(i)))
p.start()
查看文件内容信息:
我是进程,编号为:1
我是进程,编号为:2
我是进程,编号为:3
我是进程,编号为:0
我是进程,编号为:4
我是进程,编号为:5
我是进程,编号为:6
我是进程,编号为:8
我是进程,编号为:7
我是进程,编号为:9
我是进程,编号为:10
我是进程,编号为:11
我是进程,编号为:12
我是进程,编号为:13
我是进程,编号为:14
我是进程,编号为:15
我是进程,编号为:16
我是进程,编号为:18
我是进程,编号为:17
我是进程,编号为:19
我是进程,编号为:20
我是进程,编号为:21
我是进程,编号为:23
我是进程,编号为:26
我是进程,编号为:24
我是进程,编号为:25
我是进程,编号为:27
我是进程,编号为:28
我是进程,编号为:29
PS:上是示例说明多个进程之间其实是共享同一套文件系统,多个进程彼此之间并发执行,所以我们的内容打印不会按顺序执行,CUP调度进程是乱序的!
3 多进程-进程锁(多进程同步)
如多进程之间需要进行相关的同步执行,就是当多个进程需要访问共享资源的时候,使用进程Lock可以用来避免访问的冲突,保证按一定的顺序执行。
PS:同步-是指多个进程修改同一块数据(访问临界资源)时,锁策略机制可以让多个进程下同一时间只能有一个任务可以进行修改,即串行的修改。串行虽然速度上会处于劣势,但是数据安全可以得到保障,保持数据的一致性。
Lock属于互斥锁(同步原语),就是一把钥匙配备一把锁,同时只允许锁住某一个数据,其它进程在想获得锁就会被禁止。
PS:除非另有说明,否则 multiprocessing.Lock 用于进程或者线程的概念和行为都和 threading.Lock 一致。
互斥锁的通常的情况是:有且只有一把锁的分配。
Lock:一个Lock对象有两个方法acquire和release来控制共享数据的读写权限。
acquire(block=True, timeout=None):尝试获取一个锁,如果block为true,则会在获得锁之后会阻止其它进程再次获取锁的操作。 release():释放锁
PS:关于所的 release():释放锁此函数仅支持linux下的调用。如果在windows下进行调用释放或出现
:OSError: [WinError 6] 句柄无效。

上面的解决方案是,运行python的话,此时不要在pycharm里右键运行,而是开启在dos下面进行执行:python xxx.py 运行!
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
文件名称 : 进程2
文件功能描述 : 功能描述
创建人 : 小钟同学
创建时间 : 2021/5/6
-------------------------------------------------
修改描述-2021/5/6:
-------------------------------------------------
"""
import multiprocessing
lock=multiprocessing.Lock()
def printnum(lock,num):
with lock:
print("num=",num)
if __name__=="__main__":
p1=multiprocessing.Process(target=printnum,args=(lock,1))
p1.start()
或者:
import multiprocessing
lock=multiprocessing.Lock()
def printnum(lock,num):
lock.acquire()
print("num=",num)
lock.release()
if __name__=="__main__":
p1=multiprocessing.Process(target=printnum,args=(lock,1))
p1.start()
多进程-共享变量Value类
参考来自:https://www.jb51.net/article/165430.htm
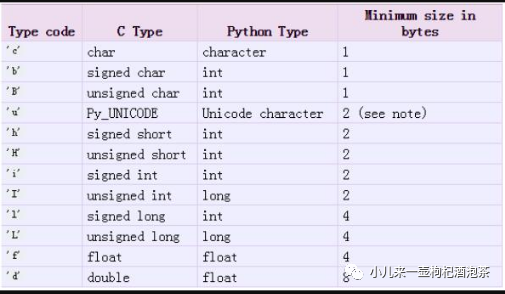
如果共享的是字符串,则在上表是找不到映射关系的,就是没有code可用。所以我们需要使用原始的ctype类型
例如
from ctypes import c_char_p
ss = Value(c_char_p, 'ss')
取钱存钱示例(共享变量的示例):
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
文件名称 : jince3
文件功能描述 : 功能描述
创建人 : 小钟同学
创建时间 : 2021/5/7
-------------------------------------------------
修改描述-2021/5/7:
-------------------------------------------------
"""
from multiprocessing import Process, Lock, Value
import time
# 银行取钱,本金5元,每次取1元,取5次
def get_money(num, lock):
with lock:
for i in range(5):
num.value -= 1
print('取钱:',num.value)
time.sleep(0.01)
# 银行存钱,本金5元,每次存1元,存5次
def put_money(num, lock):
with lock:
for i in range(5):
num.value += 1
print('存钱:',num.value)
time.sleep(0.01)
if __name__ == '__main__':
# 共享变量的数据num表示5块钱
num = Value('i', 5)
lockobj = Lock()
# 字典的方式进程传参
ps_get = Process(target=get_money, args=(num, lockobj))
ps_get.start()
# 字典的方式进程传参
ps_put = Process(target=put_money, args=(num, lockobj))
ps_put.start()
# 主进程等待子进程的退出才退出
ps_get.join()
ps_put.join()
print('最终:',num.value)
输出结果:
取钱:4
取钱:3
取钱:2
取钱:1
取钱: 0
存钱:1
存钱:2
存钱:3
存钱:4
存钱:5
最终: 5
多个进程之下,保证的数据的一致性!
补充Lock和Rlock的区别:
以下说明参考自python官网


说明:
Lock:Lock被称为①原始锁
原始锁处于 "锁定" 或者 "非锁定" 两种状态之一。它被创建时为非锁定状态。它有两个基本方法,
acquire() release()
当状态为非锁定时, acquire() 将状态改为锁定并立即返回。当状态是锁定时, acquire() 将阻塞至其他线程调用 release() 将其改为非锁定状态,然后 acquire() 调用重置其为锁定状态并返回。
release() 只在锁定状态下调用;它将状态改为非锁定并立即返回。如果尝试释放一个非锁定的锁,则会引发 RuntimeError 异常。
PS:锁支持上下文管理协议,即支持with语句。
RLock:RLock被称为重入锁,
若要锁定锁,线程或进程调用其 acquire() 方法;一旦线程或进程拥有了锁,方法将返回。 若要解锁,线程或进程调用 release() 方法。 acquire()/release() 对可以嵌套,重入锁必须由获取它的线程释放。 一旦线程或进程获得了重入锁,同一个线程或进程再次获取它将不阻塞。只有最终 release() (最外面一对的 release() )将锁解开,才能让其他线程继续处理 acquire() 阻塞。 线程或进程必须在每次获取它时释放一次。
两者使用的方法大部分还是相同的,主要区别:
-名称:一个叫原始锁,一个叫重入锁
Lock在锁定时不属于特定线程,(Lock可以在一个线程中上锁,在另一个线程中解锁) RLock只有当前线程或进程才能释放本线程或进程上的锁(解铃还须系铃人):
PS:RLock通常主要用于解决递归调用的场景的时候,需要申请锁的情况。
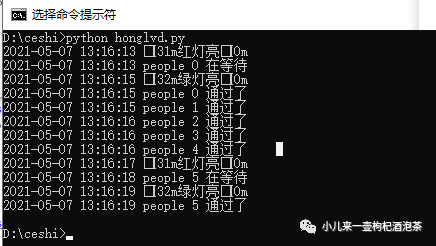
3 多进程-进程锁(控制分配锁数量Semaphore)
参考资料:https://blog.csdn.net/qq_35883464/article/details/85112762
信号量:是在进程同步过程中一个比较重要的角色。可以控制临界资源的数量,保证各个进程之间的互斥和同步
信号量 multiprocess.Semaphore
信号量 意义:一套资源、代码同一时间只能被n个人访问、n个进程执行 Semaphore:分配支持固定数据的共享连接的锁的数量主要用于控制对公共资源或者临界区域访问量的场景,
示例说明:一个ktv包间最多容纳4个,来了5个人。使用Semaphore来控制进出数量。
首先只能同时允许4个人进入包间
第5个人只有等先进入的4个人中有人出来时才可以进入
# 共享变量:multiprocessing模块提供了Array、Manager、Value类,能够实现进程间共享数字变量/字符串变量/列表/字典/实例对象。
import time, random
from multiprocessing import Process, Semaphore
def ktv(i, sem):
with sem:
print('客人编号:%s 开始走进ktv' %i)
time.sleep(random.randint(1, 5))
print('客人编号:%s 离开了ktv' %i)
if __name__ == "__main__":
# 一共有几把钥匙,最多有4把钥匙可以分配给四个人
sem = Semaphore(4)
for i in range(5):
p = Process(target=kt
输出结果:
人编号:0 开始走进ktv
客人编号:1 开始走进ktv
客人编号:2 开始走进ktv
客人编号:3 开始走进ktv
客人编号:1 离开了ktv
客人编号:4 开始走进ktv
客人编号:3 离开了ktv
客人编号:2 离开了ktv
客人编号:0 离开了ktv
客人编号:4 离开了ktv
[root@web-1 youbaoapi_test]#
4 多进程执行多任务
因为多个进程实际上是为了使用多核的优势,让任务的并行的进程处理,所有我们在并发编程处理的时候,需要注意对进程的数量进行合理的控制创建。
PS:实际的项目使用工作当中,通常我们的工作进程对应cpu数,有多少个CPU就开启几个进程即可,不应无限的开启多个进程,无限的启动多个进程实际上没有什么用,
示例说明(IO任务):
#!/usr/bin/evn python
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
文件名称 : 多进程1
文件功能描述 : 功能描述
创建人 : 小钟同学
创建时间 : 2021/5/6
-------------------------------------------------
修改描述-2021/5/6:
-------------------------------------------------
"""
from multiprocessing import Process
import os
import time
def TaskProcess_1():
start = time.time()
time.sleep(1)
print("子进程id:%s, 开始时间%s, 运行时间%s:"%(os.getpid(), start, time.time()-start))
return "任务1"
def TaskProcess_2():
start = time.time()
time.sleep(2)
print("子进程id:%s, 开始时间%f, 运行时间%s:" % (os.getpid(), start, time.time() - start))
return "任务2"
def TaskProcess_3():
start = time.time()
time.sleep(3)
print("子进程id:%s, 开始时间%s, 执行运行时间%s:" % (os.getpid(), start, time.time() - start))
return "任务3"
if __name__ == '__main__':
start = time.time()
ps_1 = Process(target=TaskProcess_1, args=())
ps_1.start()
ps_2 = Process(target=TaskProcess_2, args=())
ps_2.start()
ps_3 = Process(target=TaskProcess_2, args=())
ps_3.start()
ps_1.join()
ps_2.join()
ps_3.join()
print('主进程运行时间:%s'%(time.time()-start))
执行结果:
子进程id:20920, 开始时间1620293303.794074, 运行时间1.0028386116027832:
子进程id:43980, 开始时间1620293303.810032, 运行时间2.007758855819702:
子进程id:40400, 开始时间1620293303.825014, 运行时间2.0087337493896484:
主进程运行时间:2.2810275554656982
示例说明2(socket)
from socket import *
from multiprocessing import Process
import random
def dealClient(conn, addr):
while True:
data = conn.recv(1024)
if len(data):
try:
print('收到的数据', data.decode('gbk'), "来自", addr)
except:
# 使用网络调试助手发送的数据--- 发送的是ASCII客户端的形式
print('收到的数据', data.decode('utf-8'), "来自", addr)
backdata= ["你大爷的!",'你没的!',"什么东东!"]
# print(type(data))
# print(str.encode(b)) # 默认 encoding="utf-8"
conn.send(random.choice(backdata).encode('gbk'))
else:
# 如果数据长度为0 说明客户端断开连接,此时跳出循环关闭套接字
print('客户端%s下线了......' % (str(addr)))
break
conn.close()
def main():
tcpSocket = socket(AF_INET, SOCK_STREAM)
# 设置套接字可以地址重用
tcpSocket.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
serverAddr = ('127.0.0.1', 8000)
tcpSocket.bind(serverAddr)
tcpSocket.listen(100)
# 设置监听队列长度,在linux中这个值没有太大意义,kernel有自己的值
# 为了防止服务端异常退出,因此使用try...finally,确保创建的套接字可以正常关闭
try:
while True:
# 在主进程中不断接收新的连接请求
conn, addr = tcpSocket.accept()
print("接收来自客户端:", addr, '的数据')
# 创建子进程处理已经建立好的连接,tcpSocket依旧去监听是否有新的请求。
p1 = Process(target=dealClient, args=(conn, addr))
p1.start()
conn.close()
# 创建子进程后,父进程也同样拥有newSocekt,但是子进程使用accept()返回的新套接字发送数据,因此父进程要把newSocket关闭
except:
pass
finally:
tcpSocket.close()
if __name__ == '__main__':
main()
PS:此示例仅供思路(不能无限创建进程来处理任务!)
个人其他博客地址
简书:https://www.jianshu.com/u/d6960089b087
掘金:https://juejin.cn/user/2963939079225608
小钟同学 | 文 【原创】| QQ:308711822
1:本文相关描述主要是个人的认知和见解,如有不当之处,还望各位大佬指正。 2:关于文章内容,有部分内容参考自互联网,如有链接会声明标注;如没有及时标注备注的链接的,如有侵权请联系,我会立即删除处理哟。
